Profiling CUDA Using Nsight Systems: A Numba Example
Learn about profiling by inspecting concurrent and parallel Numba CUDA code in Nsight Systems
Introduction
Optimization is a crucial part of writing high performance code, no matter if you are writing a web server or computational fluid dynamics simulation software. Profiling allows you to make informed decisions regarding your code. In a sense, optimization without profiling is like flying blind: mostly fine for seasoned professionals with expert knowledge and fine-tuned intuition, but a recipe for disaster for almost everyone else.

In This Tutorial
Following my initial series CUDA by Numba Examples (see parts 1, 2, 3, and 4), we will study a comparison between unoptimized, single-stream code and a slightly better version which uses stream concurrency and other optimizations. We will learn, from the ground-up, how to use NVIDIA Nsight Systems to profile and analyze CUDA code. All the code in this tutorial can also be found in the repo cako/profiling-cuda-nsight-systems.
Nsight Systems
NVIDIA recommends as best practice to follow the APOD framework (Assess, Parallelize, Optimize, Deploy). There are a variety of proprietary, open-source, free, and commercial software for different types of assessments and profiling. Veteran Python users may be familiar with basic profilers such as cProfile, line_profiler, memory_profiler (unfortunately, unmaintaned as of 2024) and more advanced tools like PyInstrument and Memray. These profilers target specific aspects of the “host” such as CPU and RAM usage.
However, profiling “device” (e.g., GPU) code — and its interactions with the host — requires specialized tools provided by the device vendor. For NVIDIA GPUs, Nsight Systems, Nsight Compute, Nsight Graphics are available for profiling different aspects of computation. In this tutorial we will focus on using Nsight Systems, which is a system-wide profiler. We will use it to profile Python code which interacts with the GPU via Numba CUDA.
To get started, you will need Nsight Systems CLI and GUI. The CLI can be installed separately and will be used to profile the code in a GPGPU-capable system. The full version includes both CLI and GUI. Note that both versions could be installed in a system without a GPU. Grab the version(s) you need from the NVIDIA website.
To make it easier to visualize code sections in the GUI, NVIDIA also provides the Python pip and conda-installable library nvtx which we will use to annotate sections of our code. More on this later.
Setting Everything Up: A Simple Example
In this section we will set our development and profiling environment up. Below are two very simple Python scripts: kernels.py and run_v1.py. The former will contain all CUDA kernels, and the latter will serve as the entry point to run the example. In this example we are following the “reduce” pattern introduced in article CUDA by Numba Examples Part 3: Streams and Events to compute the sum of an array.
#%%writefile kernels.py
import numba
from numba import cuda
THREADS_PER_BLOCK = 256
BLOCKS_PER_GRID = 32 * 40
@cuda.jit
def partial_reduce(array, partial_reduction):
i_start = cuda.grid(1)
threads_per_grid = cuda.blockDim.x * cuda.gridDim.x
s_thread = numba.float32(0.0)
for i_arr in range(i_start, array.size, threads_per_grid):
s_thread += array[i_arr]
s_block = cuda.shared.array((THREADS_PER_BLOCK,), numba.float32)
tid = cuda.threadIdx.x
s_block[tid] = s_thread
cuda.syncthreads()
i = cuda.blockDim.x // 2
while i > 0:
if tid < i:
s_block[tid] += s_block[tid + i]
cuda.syncthreads()
i //= 2
if tid == 0:
partial_reduction[cuda.blockIdx.x] = s_block[0]
@cuda.jit
def single_thread_sum(partial_reduction, sum):
sum[0] = numba.float32(0.0)
for element in partial_reduction:
sum[0] += element
@cuda.jit
def divide_by(array, val_array):
i_start = cuda.grid(1)
threads_per_grid = cuda.gridsize(1)
for i in range(i_start, array.size, threads_per_grid):
array[i] /= val_array[0]
#%%writefile run_v1.py
import argparse
import warnings
import numpy as np
from numba import cuda
from numba.core.errors import NumbaPerformanceWarning
from kernels import (
BLOCKS_PER_GRID,
THREADS_PER_BLOCK,
divide_by,
partial_reduce,
single_thread_sum,
)
# Ignore NumbaPerformanceWarning
warnings.simplefilter("ignore", category=NumbaPerformanceWarning)
def run(size):
# Define host array
a = np.ones(size, dtype=np.float32)
print(f"Old sum: {a.sum():.3f}")
# Array copy to device and array creation on the device.
dev_a = cuda.to_device(a)
dev_a_reduce = cuda.device_array((BLOCKS_PER_GRID,), dtype=dev_a.dtype)
dev_a_sum = cuda.device_array((1,), dtype=dev_a.dtype)
# Launching kernels to normalize array
partial_reduce[BLOCKS_PER_GRID, THREADS_PER_BLOCK](dev_a, dev_a_reduce)
single_thread_sum[1, 1](dev_a_reduce, dev_a_sum)
divide_by[BLOCKS_PER_GRID, THREADS_PER_BLOCK](dev_a, dev_a_sum)
# Array copy to host
dev_a.copy_to_host(a)
cuda.synchronize()
print(f"New sum: {a.sum():.3f}")
def main():
parser = argparse.ArgumentParser(description="Simple Example v1")
parser.add_argument(
"-n",
"--array-size",
type=int,
default=100_000_000,
metavar="N",
help="Array size",
)
args = parser.parse_args()
run(size=args.array_size)
if __name__ == "__main__":
main()
This is a simple script that can just be run with:
$ python run_v1.py
Old sum: 100000000.000
New sum: 1.000
We also run this code through our profiler, which just entails calling nsys with some options before the call to our script:
$ nsys profile
--trace cuda,osrt,nvtx
--gpu-metrics-device=all
--cuda-memory-usage true
--force-overwrite true
--output profile_run_v1
python run_v1.py
GPU 0: General Metrics for NVIDIA TU10x (any frequency)
Old sum: 100000000.000
New sum: 1.000
Generating '/tmp/nsys-report-fb78.qdstrm'
[1/1] [========================100%] profile_run_v1.nsys-rep
Generated:
/content/profile_run_v1.nsys-rep
You can consult the Nsight CLI docs for all the available options to the nsys CLI. For this tutorial we will always use the ones above. Let’s dissect this command:
- profile puts nsys in profile mode. There are many other modes like export and launch.
- –trace cuda,osrt,nvtx ensures we “listen” to all CUDA calls (cuda), OS runtime library calls (osrt) and nvtx annotations (none in this example). There are many more trace options such as cublas, cudnn, mpi,dx11 and several others. Check the docs for all options.
- –gpu-metrics-device=all records GPU metrics for all GPUs, including Tensor Core usage.
- –cuda-memory-usage tracks GPU memory usage of kernels. It may significantly slow down execution and requires –trace=cuda. We use it because our scripts our pretty fast anyways.
Navigating the Nsight Systems GUI
If the command exited successfully, we will have a profile_run_v1.nsys-rep in the current folder. We will open this file by launching the Nsight Systems GUI, File > Open. The initial view is slightly confusing. So we will start by decluttering: resize the Events View port to the bottom, and minimize CPU, GPU and Processes under the Timeline View port. Now expand only Processes > python > CUDA HW. See Figures 1a and 1b.
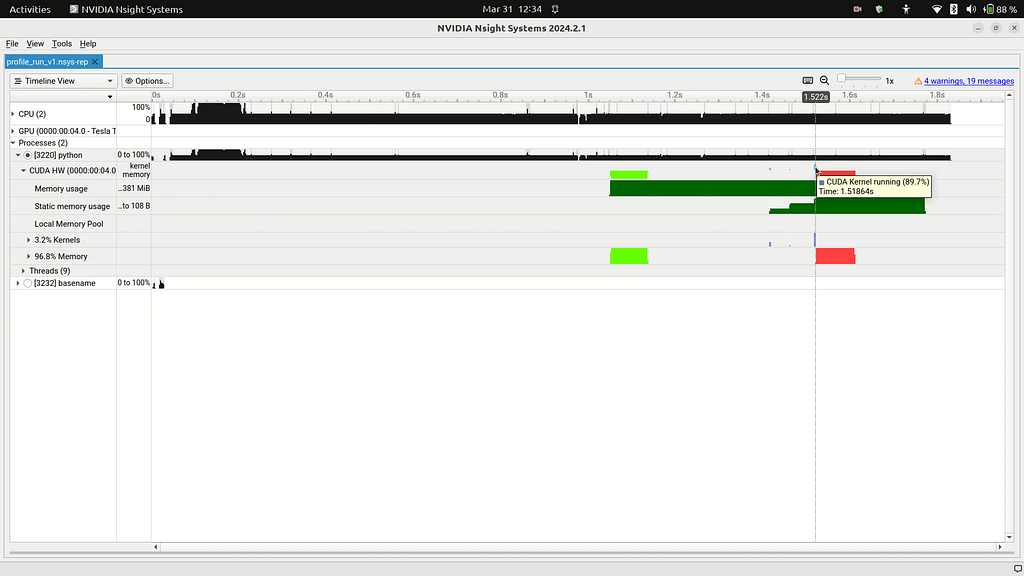
First up, let’s find our kernels. On the CUDA HW line, you will find green and red blobs, and very small slivers of light blue (see Figure 1b). If you hover over those you will see tooltips saying, “CUDA Memory operations in progress” for red and green, and “CUDA Kernel Running (89.7%)” for the light blues. These are going to be the bread and butter of our profiling. On this line, we will be able to tell when and how memory is being transferred (red and green) and when and how our kernels are running (light blue).
Let’s dig in a little bit more on our kernels. You should see three very small blue slivers, each representing a kernel call. We will zoom into the region by clicking and dragging the mouse from just before the start of the first kernel call to just after the end of the last one, and then pressing Shift + Z. See Figure 2.
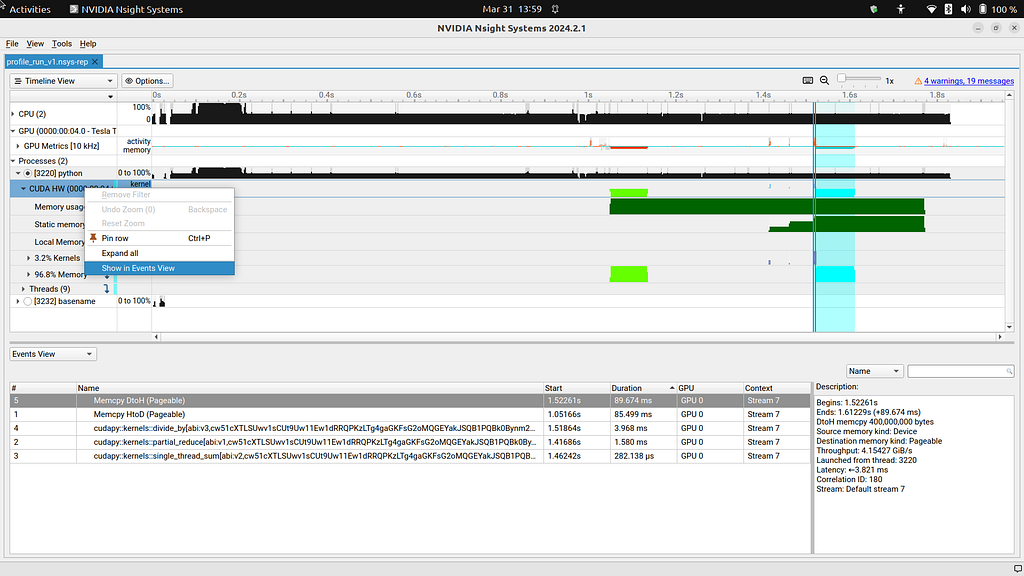
Now that we have found our kernels, let’s see some metrics. We open the GPU > GPU Metrics tabs for that. In this panel, can find “Warp Occupancy” (beige) for compute kernels. One way to optimize CUDA code is to ensure that the warp occupancy is as close to 100% as possible for as long as possible. This means that our GPU is not idling. We notice that this is happening for the first and last kernels but not the middle kernel. That is expected as the middle kernel launches a single thread. One final thing to note in this section is the GPU > GPU Metrics > SMs Active > Tensor Active / FP16 Active line. This line will show whether the tensor cores are being used. In this case you should verify that they are not.
Now let’s briefly look at the Events View. Right click Processes > python > CUDA HW and click “Show in Events View”. Then sort the events by descending duration. In Figure 3, we see that the slowest events are two pageable memory transfers. We have seen in CUDA by Numba Examples Part 3: Streams and Events that pageable memory transfers can be suboptimal, and we should prefer page-locked or “pinned” memory transfers. If we have slow memory transfers due to use of pageable memory, the Events View can be a great location to identify where these slow transfers can be found. Pro tip: you can isolate memory transfers by right clicking Processes > python > CUDA HW > XX% Memory instead.
In this section we learned how to profile a Python program which uses CUDA, and how to visualize basic information of this program in the Nsight Systems GUI. We also noticed that in this simple program, we are using pageable instead of pinned memory, that one of our kernels is not occupying all warps, that the GPU is idle for quite some time between kernels being run and that we are not using tensor cores.
Annotating with NVTX
In this section we will learn how to improve our profiling experience by annotation sections in Nsight Systems with NVTX. NVTX allows us to mark different regions of the code. It can mark ranges and instantaneous events. For a deeper look, check the docs. Below we create run_v2.py, which, in addition to annotating run_v1.py, also changes this line:
a = np.ones(size, dtype=np.float32)
to these:
a = cuda.pinned_array(size, dtype=np.float32)
a[...] = 1.0
Therefore, in addition to the annotations, we are now using a pinned memory. If you want to learn more about the different types of memories that CUDA supports, see the CUDA C++ Programming Guide. It is of relevance that this is not the only way to pin an array in Numba. A previously created Numpy array can also be created with a context, as explained in the Numba documentation.
#%%writefile run_v2.py
import argparse
import warnings
import numpy as np
import nvtx
from numba import cuda
from numba.core.errors import NumbaPerformanceWarning
from kernels import (
BLOCKS_PER_GRID,
THREADS_PER_BLOCK,
divide_by,
partial_reduce,
single_thread_sum,
)
# Ignore NumbaPerformanceWarning
warnings.simplefilter("ignore", category=NumbaPerformanceWarning)
def run(size):
with nvtx.annotate("Compilation", color="red"):
dev_a = cuda.device_array((BLOCKS_PER_GRID,), dtype=np.float32)
dev_a_reduce = cuda.device_array((BLOCKS_PER_GRID,), dtype=dev_a.dtype)
dev_a_sum = cuda.device_array((1,), dtype=dev_a.dtype)
partial_reduce[BLOCKS_PER_GRID, THREADS_PER_BLOCK](dev_a, dev_a_reduce)
single_thread_sum[1, 1](dev_a_reduce, dev_a_sum)
divide_by[BLOCKS_PER_GRID, THREADS_PER_BLOCK](dev_a, dev_a_sum)
# Define host array
a = cuda.pinned_array(size, dtype=np.float32)
a[...] = 1.0
print(f"Old sum: {a.sum():.3f}")
# Array copy to device and array creation on the device.
with nvtx.annotate("H2D Memory", color="yellow"):
dev_a = cuda.to_device(a)
dev_a_reduce = cuda.device_array((BLOCKS_PER_GRID,), dtype=dev_a.dtype)
dev_a_sum = cuda.device_array((1,), dtype=dev_a.dtype)
# Launching kernels to normalize array
with nvtx.annotate("Kernels", color="green"):
partial_reduce[BLOCKS_PER_GRID, THREADS_PER_BLOCK](dev_a, dev_a_reduce)
single_thread_sum[1, 1](dev_a_reduce, dev_a_sum)
divide_by[BLOCKS_PER_GRID, THREADS_PER_BLOCK](dev_a, dev_a_sum)
# Array copy to host
with nvtx.annotate("D2H Memory", color="orange"):
dev_a.copy_to_host(a)
cuda.synchronize()
print(f"New sum: {a.sum():.3f}")
def main():
parser = argparse.ArgumentParser(description="Simple Example v2")
parser.add_argument(
"-n",
"--array-size",
type=int,
default=100_000_000,
metavar="N",
help="Array size",
)
args = parser.parse_args()
run(size=args.array_size)
if __name__ == "__main__":
main()
Comparing the two files, you can see it’s as simple as wrapping some GPU kernel calls with
with nvtx.annotate("Region Title", color="red"):
...
Pro tip: you can also annotate functions by placing the @nvtx.annotate decorator above their definition, automatically annotate everything by calling your script with python -m nvtx run_v2.py, or apply the autoannotator selectively in you code by enabling or disabling nvtx.Profile(). See the docs!
Let’s run this new script and open the results in Nsight Systems.
$ nsys profile
--trace cuda,osrt,nvtx
--gpu-metrics-device=all
--cuda-memory-usage true
--force-overwrite true
--output profile_run_v2
python run_v2.py
GPU 0: General Metrics for NVIDIA TU10x (any frequency)
Old sum: 100000000.000
New sum: 1.000
Generating '/tmp/nsys-report-69ab.qdstrm'
[1/1] [========================100%] profile_run_v2.nsys-rep
Generated:
/content/profile_run_v2.nsys-rep
Again, we start by minimizing everything, leaving only Processes > python > CUDA HW open. See Figure 4. Notice that we now have a new line, NVTX. On this line in the timeline window we should see different colored blocks corresponding to the annotation regions that we created in the code. These are Compilation, H2D Memory, Kernels and D2H Memory. Some of these my be too small to read, but will be legible if you zoom into the region.
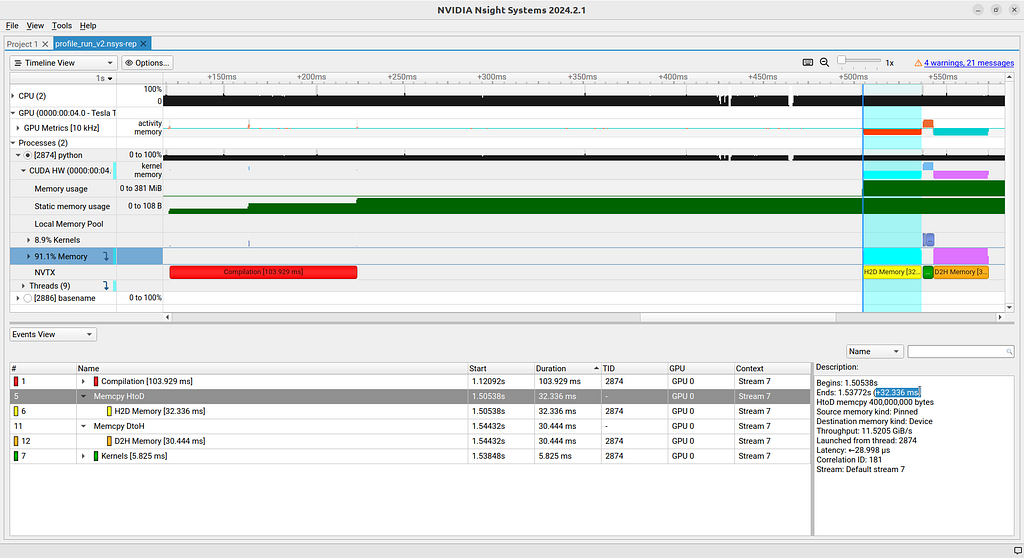
The profiler confirms that this memory is pinned, ensuring that our code is truly using pinned memory. In addition, H2D Memory and D2H Memory are now taking less than half of the time that they were taking before. Generally we can expect better performance using pinned memory or prefetched mapped arrays (not supported by Numba).
Stream Concurrency
Now we will investigate whether we can improve this code by introducing streams. The idea is that while memory transfers are occurring, the GPU can start processing the data. This allows a level of concurrency, which hopefully will ensure that we are occupying our warps as fully as possible.

In the code below we will split the processing of our array into roughly equal parts. Each part will run in a separate stream, including transferring data and computing the sum of the array. Then, we synchronize all streams and sum their partial sums. At this point we can then launch normalization kernels for each stream independently.
We want to answer a few questions:
- Will the code below truly create concurrency? Could we be introducing a bug?
- Is it faster than the code which uses a single stream?
- Is the warp occupancy better?
#%%writefile run_v3_bug.py
import argparse
import warnings
from math import ceil
import numpy as np
import nvtx
from numba import cuda
from numba.core.errors import NumbaPerformanceWarning
from kernels import (
BLOCKS_PER_GRID,
THREADS_PER_BLOCK,
divide_by,
partial_reduce,
single_thread_sum,
)
# Ignore NumbaPerformanceWarning
warnings.simplefilter("ignore", category=NumbaPerformanceWarning)
def run(size, nstreams):
with nvtx.annotate("Compilation", color="red"):
dev_a = cuda.device_array((BLOCKS_PER_GRID,), dtype=np.float32)
dev_a_reduce = cuda.device_array((BLOCKS_PER_GRID,), dtype=dev_a.dtype)
dev_a_sum = cuda.device_array((1,), dtype=dev_a.dtype)
partial_reduce[BLOCKS_PER_GRID, THREADS_PER_BLOCK](dev_a, dev_a_reduce)
single_thread_sum[1, 1](dev_a_reduce, dev_a_sum)
divide_by[BLOCKS_PER_GRID, THREADS_PER_BLOCK](dev_a, dev_a_sum)
# Define host array
a = cuda.pinned_array(size, dtype=np.float32)
a[...] = 1.0
# Define regions for streams
step = ceil(size / nstreams)
starts = [i * step for i in range(nstreams)]
ends = [min(s + step, size) for s in starts]
print(f"Old sum: {a.sum():.3f}")
# Create streams
streams = [cuda.stream()] * nstreams
cpu_sums = [cuda.pinned_array(1, dtype=np.float32) for _ in range(nstreams)]
devs_a = []
with cuda.defer_cleanup():
for i, (stream, start, end) in enumerate(zip(streams, starts, ends)):
cpu_sums[i][...] = np.nan
# Array copy to device and array creation on the device.
with nvtx.annotate(f"H2D Memory Stream {i}", color="yellow"):
dev_a = cuda.to_device(a[start:end], stream=stream)
dev_a_reduce = cuda.device_array(
(BLOCKS_PER_GRID,), dtype=dev_a.dtype, stream=stream
)
dev_a_sum = cuda.device_array((1,), dtype=dev_a.dtype, stream=stream)
devs_a.append(dev_a)
# Launching kernels to sum array
with nvtx.annotate(f"Sum Kernels Stream {i}", color="green"):
for _ in range(50): # Make it spend more time in compute
partial_reduce[BLOCKS_PER_GRID, THREADS_PER_BLOCK, stream](
dev_a, dev_a_reduce
)
single_thread_sum[1, 1, stream](dev_a_reduce, dev_a_sum)
with nvtx.annotate(f"D2H Memory Stream {i}", color="orange"):
dev_a_sum.copy_to_host(cpu_sums[i], stream=stream)
# Ensure all streams are caught up
cuda.synchronize()
# Aggregate all 1D arrays into a single 1D array
a_sum_all = sum(cpu_sums)
# Send it to the GPU
with cuda.pinned(a_sum_all):
with nvtx.annotate("D2H Memory Default Stream", color="orange"):
dev_a_sum_all = cuda.to_device(a_sum_all)
# Normalize via streams
for i, (stream, start, end, dev_a) in enumerate(
zip(streams, starts, ends, devs_a)
):
with nvtx.annotate(f"Divide Kernel Stream {i}", color="green"):
divide_by[BLOCKS_PER_GRID, THREADS_PER_BLOCK, stream](
dev_a, dev_a_sum_all
)
# Array copy to host
with nvtx.annotate(f"D2H Memory Stream {i}", color="orange"):
dev_a.copy_to_host(a[start:end], stream=stream)
cuda.synchronize()
print(f"New sum: {a.sum():.3f}")
def main():
parser = argparse.ArgumentParser(description="Simple Example v3")
parser.add_argument(
"-n",
"--array-size",
type=int,
default=100_000_000,
metavar="N",
help="Array size",
)
parser.add_argument(
"-s",
"--streams",
type=int,
default=4,
metavar="N",
help="Array size",
)
args = parser.parse_args()
run(size=args.array_size, nstreams=args.streams)
if __name__ == "__main__":
main()
Let’s run the code and collect results.
$ nsys profile
--trace cuda,osrt,nvtx
--gpu-metrics-device=all
--cuda-memory-usage true
--force-overwrite true
--output profile_run_v3_bug_4streams
python run_v3_bug.py -s 4
GPU 0: General Metrics for NVIDIA TU10x (any frequency)
Old sum: 100000000.000
New sum: 1.000
Generating '/tmp/nsys-report-a666.qdstrm'
[1/1] [========================100%] profile_run_v3_bug_4streams.nsys-rep
Generated:
/content/profile_run_v3_bug_4streams.nsys-rep
The program ran and yielded the correct answer. But when we open the profiling file (see Figure 6), we notice that there are two streams instead of 4! And one is basically completely idle! What’s going on here?
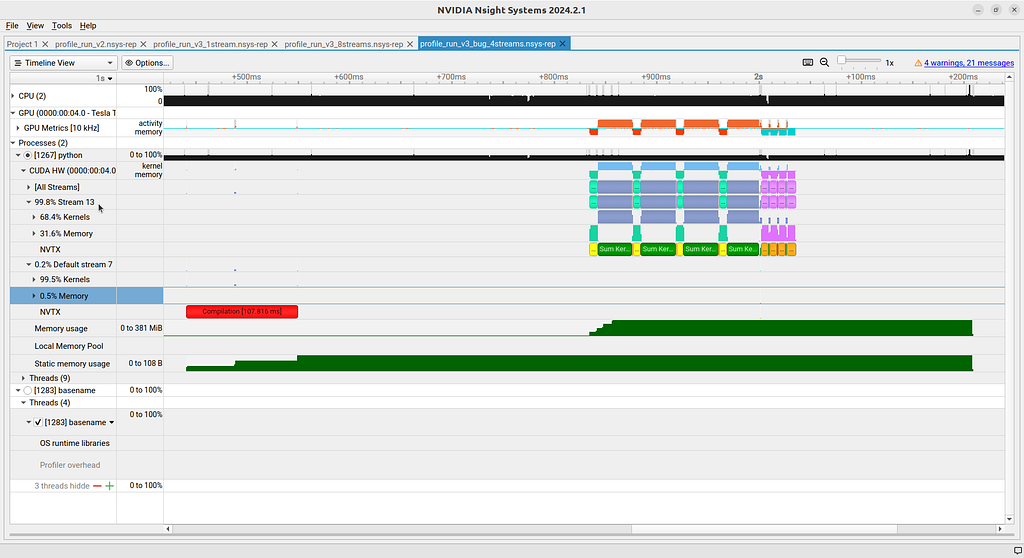
There is a bug in the creation of the streams. By doing
streams = [cuda.stream()] * nstreams
we are actually creating a single stream and repeating it nstreams times. So why are we seeing two streams instead of one? The fact that one is not doing much computation should be an indicator that there is a stream that we are not using. This stream is the default stream, which we are not using at all in out code since all GPU interactions are given a stream, the stream we created.
We can fix this bug with:
streams = [cuda.stream() for _ in range(nstreams)]
# Ensure they are all different
assert all(s1.handle != s2.handle for s1, s2 in zip(streams[:-1], streams[1:]))
The code above will also ensure they are really different streams, so it would have caught the bug had we had it in the code. It does so by checking the stream pointer value.
Now we can run the fixed code with 1 stream and 8 streams for comparison. See Figures 7 and 8, respectively.
$ nsys profile
--trace cuda,osrt,nvtx
--gpu-metrics-device=all
--cuda-memory-usage true
--force-overwrite true
--output profile_run_v3_1stream
python run_v3.py -s 1
GPU 0: General Metrics for NVIDIA TU10x (any frequency)
Old sum: 100000000.000
New sum: 1.000
Generating '/tmp/nsys-report-de65.qdstrm'
[1/1] [========================100%] profile_run_v3_1stream.nsys-rep
Generated:
/content/profile_run_v3_1stream.nsys-rep
$ nsys profile
--trace cuda,osrt,nvtx
--gpu-metrics-device=all
--cuda-memory-usage true
--force-overwrite true
--output profile_run_v3_8streams
python run_v3.py -s 8
GPU 0: General Metrics for NVIDIA TU10x (any frequency)
Old sum: 100000000.000
New sum: 1.000
Generating '/tmp/nsys-report-1fb7.qdstrm'
[1/1] [========================100%] profile_run_v3_8streams.nsys-rep
Generated:
/content/profile_run_v3_8streams.nsys-rep
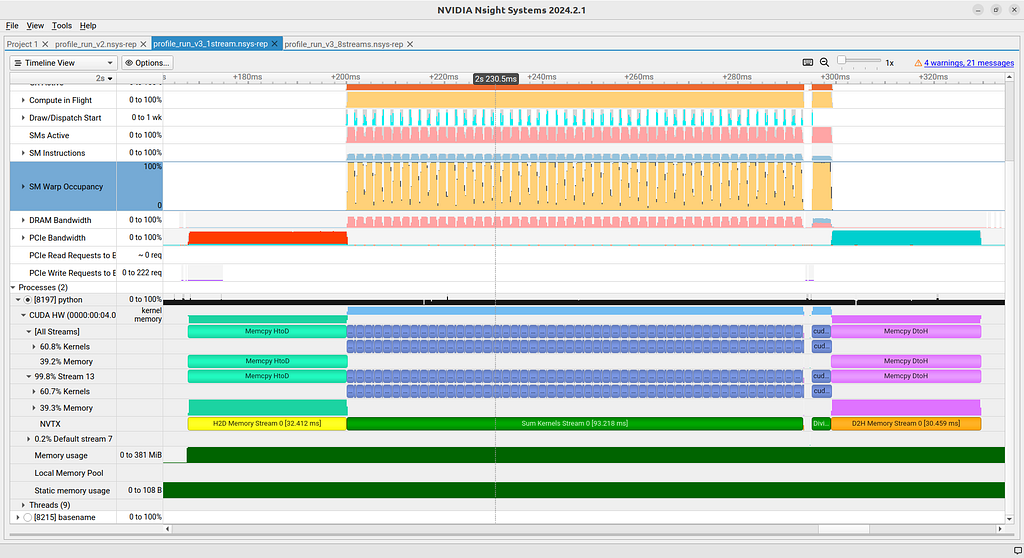
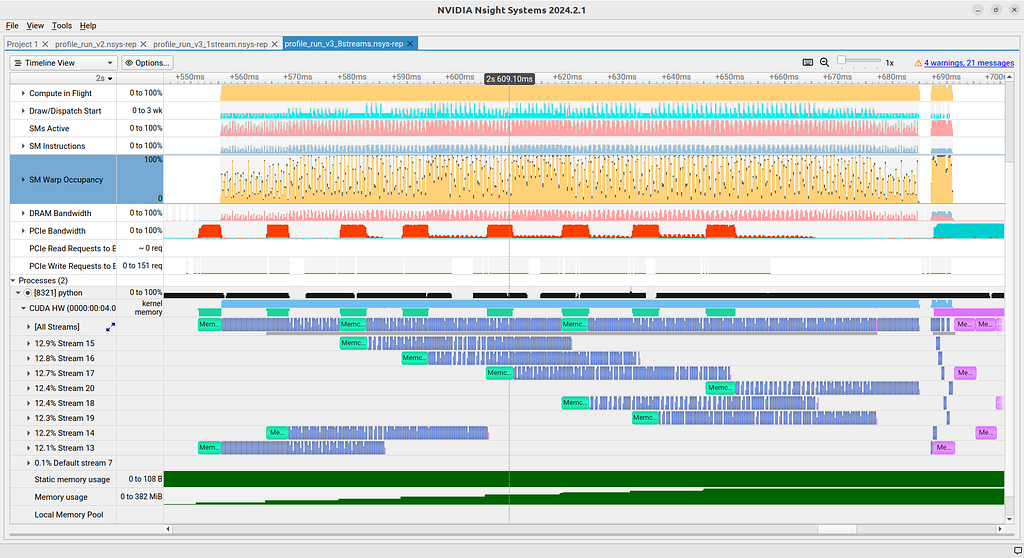
Again, both give correct results. By opening the one with 8 streams we see that yes, the bug has been fixed (Figure 7). Indeed, we now see 9 streams (8 created + default). In addition, we see that they are working at the same time! So we have achieved concurrency!
Unfortunately, if we dig a bit deeper we notice that the concurrent code is not necessarily faster. On my machine the critical section of both versions, from start of memory transfer to the last GPU-CPU copy takes around 160 ms.
A likely culprit is the warp occupancy. We notice that the warp occupancy is significantly better in the single-stream version. The gains we are getting in this example in compute are likely being lost by not occupying our GPU as efficiently. This is likely related to the structure of the code which (artificially) calls way too many kernels. In addition, if all threads are filled by a single stream, there is no gain in concurrency, since other streams have to be idle until resources free up.
This example is important because it shows that our preconceived notions of performance are just hypotheses. They need to be verified.
At this point of APOD, we have assessed, parallelized (both through threads and concurrency) and so the next step would be to deploy. We also noticed a slight performance regression with concurrency, so for this example, a single-stream version would likely be the one deployed. In production, the next step would be to follow the next piece of code which is best suited for parallelization and restarting APOD.
Conclusion
In this article we saw how to set up, use and interpret results from profiling Python code in NVIDIA Nsight Systems. C and C++ code can be analyzed very similarly, and indeed most of the material out there uses C and C++ examples.
We also show how profiling can allow us to catch bugs and performance test our programs, ensuring that the features we introduce truly are improving performance, and if they are not, why.
Profiling CUDA using Nsight Systems: A Numba Example was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Profiling CUDA using Nsight Systems: A Numba Example
Go Here to Read this Fast! Profiling CUDA using Nsight Systems: A Numba Example