

Frugal RLHF with multi-adapter PPO on Amazon SageMaker
Note: All images, unless otherwise noted, are by the author.
What is this about and why is it important?
Over the last 2 years, research and practice have delivered plenty of proof that preference alignment (PA) is a game changer for boosting Large Language Models (LLMs) performance, especially (but not exclusively) for models directly exposed to humans. PA uses (human) feedback to align model behavior to what is preferred in the environment a model is actually living in, instead of relying solely on proxy datasets like other fine-tuning approaches do (as I explain in detailed in this blog post on fine-tuning variations). This improvement in model performance, as perceived by human users, has been a key factor in making LLMs and other Foundation Models (FMs) more accessible and popular, contributing significantly to the current excitement around Generative AI.
Over time various approaches to PA have been proposed by research and quickly adapted by some practitioners. Amongst them, RLHF is (as of Autumn 2024) by far the most popular and proven approach.
However, due to challenges around implementation complexity, compute requirements or training orchestration, so far the adaptation of PA approaches like RLHF in practice is limited to mainly high-skill profile individuals and organizations like FM producers. Also, most practical examples and tutorials I found showcasing how to master an approach like RLHF are limited or incomplete.
This blog post provides you with a comprehensive introduction into RLHF, discusses challenges around the implementation, and suggests RLHF with multi-adapter PPO, a light-weight implementation approach tackling some key ones of these challenges.
Next, we present an end-to-end (E2E) implementation of this approach in a Jupyter notebook, covering data collection, preparation, model training, and deployment. We leverage HuggingFace frameworks and Amazon SageMaker to provide a user-friendly interface for implementation, orchestration, and compute resources. The blog post then guides you through the key sections of this notebook, explaining implementation details and the rationale behind each step. This hands-on approach allows readers to understand the practical aspects of the process and easily replicate the results.
The principles of RLHF
Reinforcement learning from human feedback was one of the major hidden technical backbones of the early Generative AI hype, giving the breakthrough achieved with great large decoder models like Anthropic Claude or OpenAI’s GPT models an additional boost into the direction of user alignment.
The great success of PA for FMs perfectly aligns with the concept of user-centric product development, a core and well-established principle of agile product development. Iteratively incorporating feedback from actual target users has proven highly effective in developing outstanding products. This approach allows developers to continually refine and improve their offerings based on real-world user preferences and needs, ultimately leading to more successful and user-friendly products.
Other fine-tuning approaches like continued pre-training (CPT) or supervised fine-tuning (SFT) don’t cover this aspect since:
- the datasets used for these approaches are (labelled or unlabelled) proxies for what we think our users like or need (i.e. knowledge or information, language style, acronyms or task-specific behaviour like instruction-following, chattiness or others), crafted by a few in charge of model training or fine-tuning data.
- the algorithm(s), training objective(s) and loss function(s) used for these approaches (i.e. causal language modeling) are using next-token prediction as proxy for higher level metrics (e.g. accuracy, perplexity, …).
Therefore, PA is undoubtedly a technique we should employ when aiming to create an exceptional experience for our users. This approach can significantly enhance the quality, safety and relevance of AI-generated responses, leading to more satisfying interactions and improved overall user satisfaction.
How does RLHF work?
Note: This section is an adapted version of the RLHF section in my blog post about different fine-tuning variations. For a comprehensive overview about fine-tuning you might want to check it out as well.
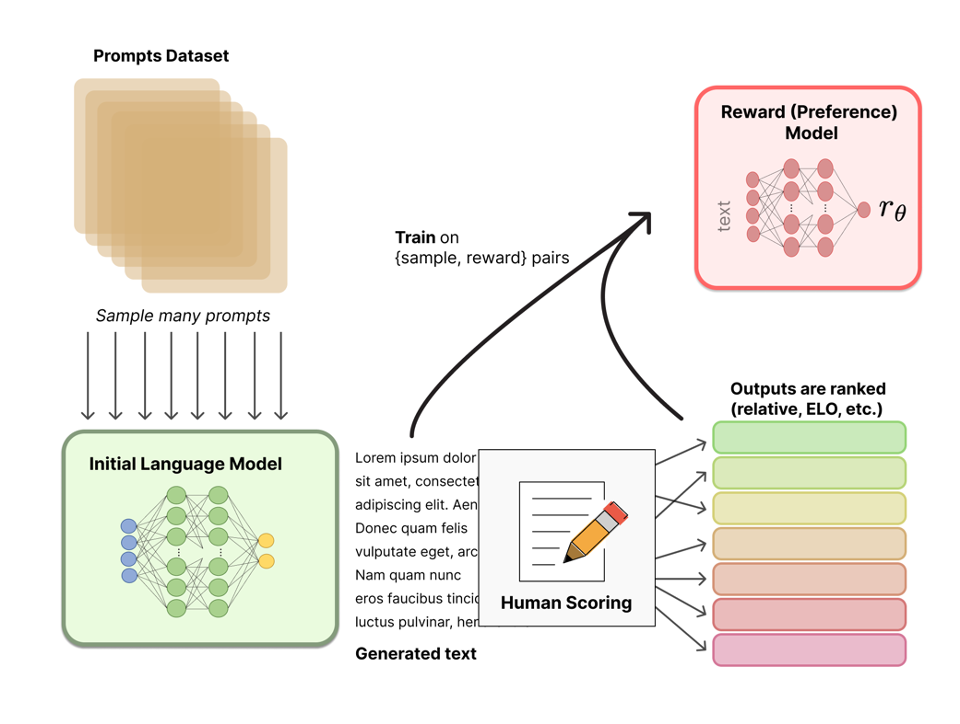
RLHF works in a two-step process and is illustrated in Figures 13 and 14:
Step 1 (Figure 1): First, a reward model needs to be trained for later usage in the actual RL-powered training approach. Therefore, a prompt dataset aligned with the objective (e.g. chat/instruct model or domain-specific task objective) to optimize is being fed to the model to be fine-tuned, while requesting not only one but two or more inference results. These results will be presented to human labelers for scoring (1st, 2nd, 3rd, …) based on the optimization objective. There are also a few open-sourced preference ranking datasets, among them “Anthropic/hh-rlhf” (we will use this dataset in the practical part of this blog) which is tailored towards red-teaming and the objectives of honesty and harmlessness. After normalizing and converting the scores into reward values, a reward model is trained using individual sample-reward pairs, where each sample is a single model response. The reward model architecture is usually similar to the model to be fine-tuned, adapted with a small head eventually projecting the latent space into a reward value instead of a probability distribution over tokens. However, the ideal sizing of this model in parameters is still subject to research, and different approaches have been chosen by model providers in the past. In the practical part of this blog, for the reward model we will use the same model architecture compared to the model to be fine-tuned.

Step 2 (Figure 2): Our new reward model is now used for training the actual model. Therefore, another set of prompts is fed through the model to be tuned (grey box in illustration), resulting in one response each. Subsequently, these responses are fed into the reward model for retrieval of the individual reward. Then, Proximal Policy Optimization (PPO), a policy-based RL algorithm, is used to gradually adjust the model’s weights in order to maximize the reward allocated to the model’s answers. As opposed to Causal Language Modeling (CLM — you can find a detailed explanation here), instead of gradient descent, this approach leverages gradient ascent (or gradient descent over 1 — reward) since we are now trying to maximize an objective (reward). For increased algorithmic stability to prevent too heavy drifts in model behavior during training, which can be caused by RL-based approaches like PPO, a prediction shift penalty is being added to the reward term, penalizing answers diverging too much from the initial language model’s predicted probability distribution on the same input prompt.
Challenges with RLHF
The way how RLHF is working poses some core challenges to implementing and running it at scale, amongst them the following:
– Cost of training the reward model: Picking the right model architecture and size for the reward model is still current state of research. These models are usually transformer models similar to the model to be fine-tuned, equipped with a modified head delivering reward scores instead of a vocabular probability distribution. This means, that independent from the actual choice, most reward models are in the billions of parameters. Full parameter training of such a reward model is data and compute expensive.
– Cost of training cluster: With the reward model (for the reward values), the base model (for the KL prediction shift penalty) and the model actually being fine-tuned three models need to be hosted in parallel in the training cluster. This leads to massive compute requirements usually only being satisfied by a multi-node cluster of multi-GPU instances (in the cloud), leading to hardware and operational cost.
– Orchestration of training cluster: The RLHF algorithm requires a combination of inference- and training-related operations in every training loop. This needs to be orchestrated in a multi-node multi-GPU cluster while keeping communication overhead minimal for optimal training throughput.
– Training/inference cost in highly specialized setups: PA shines through aligning model performance towards a user group or target domain. Since most professional use cases are characterized by specialized domains with heterogenous user groups, this leads to an interesting tradeoff: Optimizing for performance will lead in training and hosting many specialized models excelling in performance. However, optimizing for resource consumption (i.e. cost) will lead to overgeneralization of models and decreasing performance.
RLHF with multi-adapter PPO
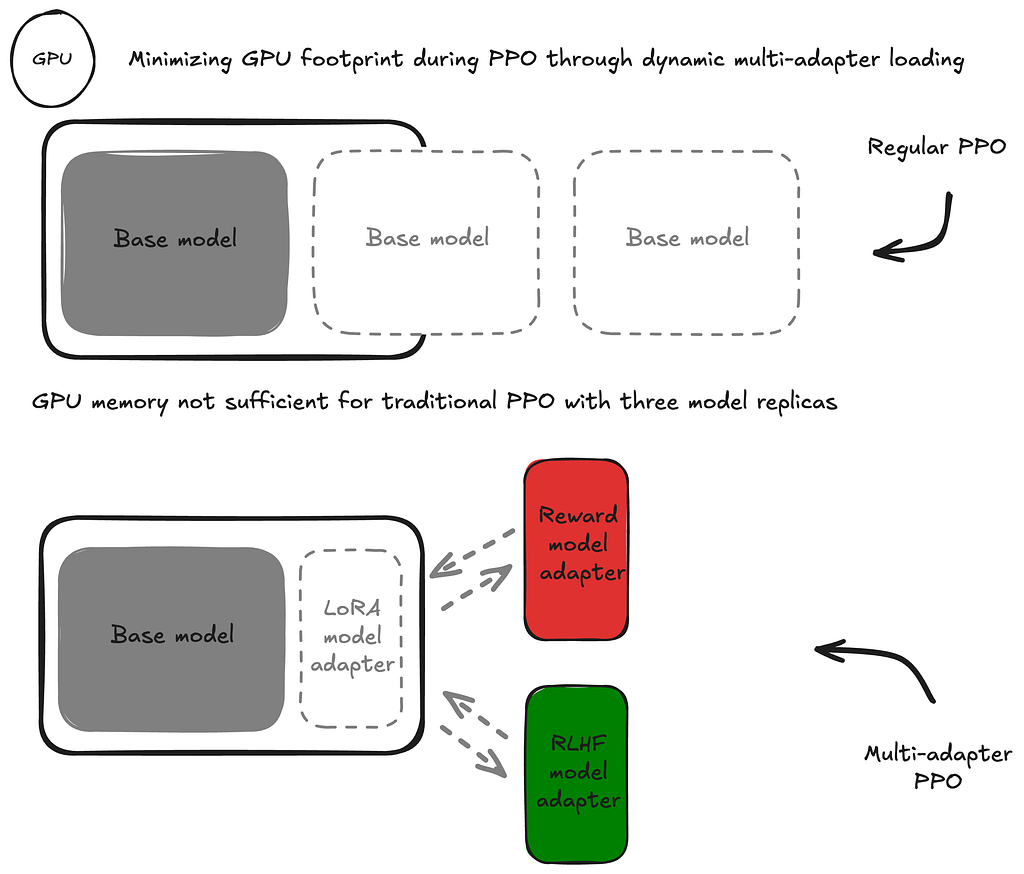
Multi-adapter PPO is a particularly GPU-frugal approach to the second step of the RLHF training process. Instead of using full-parameter fine-tuning, it leverages parameter-efficient fine-tuning (PEFT) techniques to reduce the infrastructure and orchestration footprint drastically. Instead of hosting three distinct models (model being fine-tuned, reward model, reference model for KL prediction shift penalty) in parallel in the training cluster this approach leverages Low Rank Adaptation (LoRA) adapters during the fine-tuning which are dynamically loaded and unloaded into the accelerators of the training cluster.

While this approach’s goal is ultimately a resource and orchestration frugal approach to the second step of RLHF, it has implications on the first step:
- Reward model choice: A reward model with the same model architecture as the model to be fine-tuned is picked and equipped with a reward classification head.
- Reward model training approach: As illustrated in figure 4(2), instead of full-parameter reward model training, a reward model LoRA adapter is being trained, leading to a much leaner training footprint.
Similarly to the this, the RLHF fine-tuning of the model being performed in the second step is not done in a full-parameter fine-tuning manner. Instead, a LoRA adapter is trained. As depicted in figure 4, during a training iteration, first the RLHF model adapter is being loaded to generate model responses to the prompts of the current training batch (4a). Then, the reward model adapter is loaded to calculate the corresponding raw reward values (4b). To complete the reward term, the input prompt is fed through the base model for calculation of the KL prediction shift penalty. Therefor, all adapters need to be unloaded (4c, 4d). Finally, the RLHF model adapter is loaded again to perform the weight updates for this iteration step (4e).
This approach to RLHF reduces the memory footprint as well as orchestration complexity significantly.
Running RLHF with multi-adapter PPO with HuggingFace and Amazon SageMaker
In what follows we will go through a notebook showcasing RLHF with multi-adapter PPO in an E2E fashion. Thereby we use HuggingFace and Amazon SageMaker for an especially user-friendly interface towards the implementation, orchestration and compute layers. The entire notebook can be found here.
Scenario
The pace model producers nowadays are releasing new models is impressive. Hence, I want to keep the scenario we are looking into as generic as possible.
While most of the models published these days have already gone through multiple fine-tuning steps like SFT or even PA, since these models are general purpose ones they where certainly not performed tailored to your target users or target domain. This means that even though we are using a pre-aligned model (e.g. an instruction fine-tuned model), for optimising model performance in your domain further alignment steps are required.
For this blog we will assume the model should be optimised towards maximising the helpfulness while carrying out user-facing single- and multi-turn conversations in a Q&A style in the scientific domain. Thus, we will start from a general-purpose instruct / Q&A pre-trained FM.
Model
Despite of being generic we need to choose a model for our endeavour. For this blog we will be working with Meta Llama3.1–8b-instruct. This model is the smallest fashion of a new collection of multilingual pre-trained and instruction-tuned decoder models Meta released in Summer 2024. More details can be found in the documentation in the Meta homepage and in the model card provided by HuggingFace.

Prerequisites
We start our notebook walkthrough with some prerequisite preparation steps.
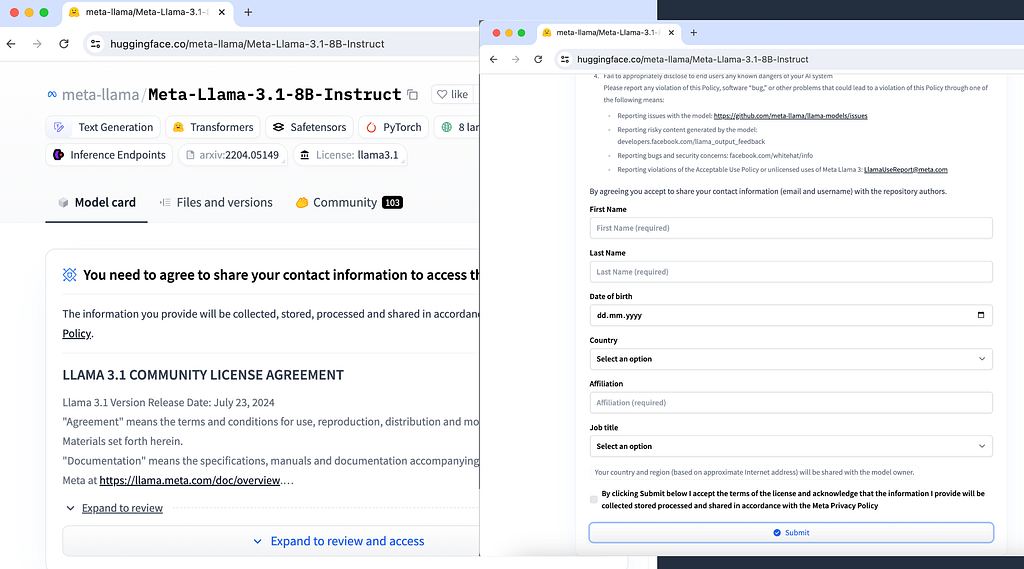
We will be retrieving the model’s weights from the HuggingFace model hub. To be able to do so we need to accept Meta‘s licensing agreement and provide some information. This can be submitted directly through the HuggingFace model hub.
Further, for storage of the adapter weights of both the reward model as well as the preference-aligned model we will be using private model repositories on the HuggingFace model hub. This requires a HuggingFace account. Once logged into the HuggingFace platform we need to create two model repositories. For this click on the account icon on the top right of the HuggingFace landing page and pick “+ New Model” in the menu.
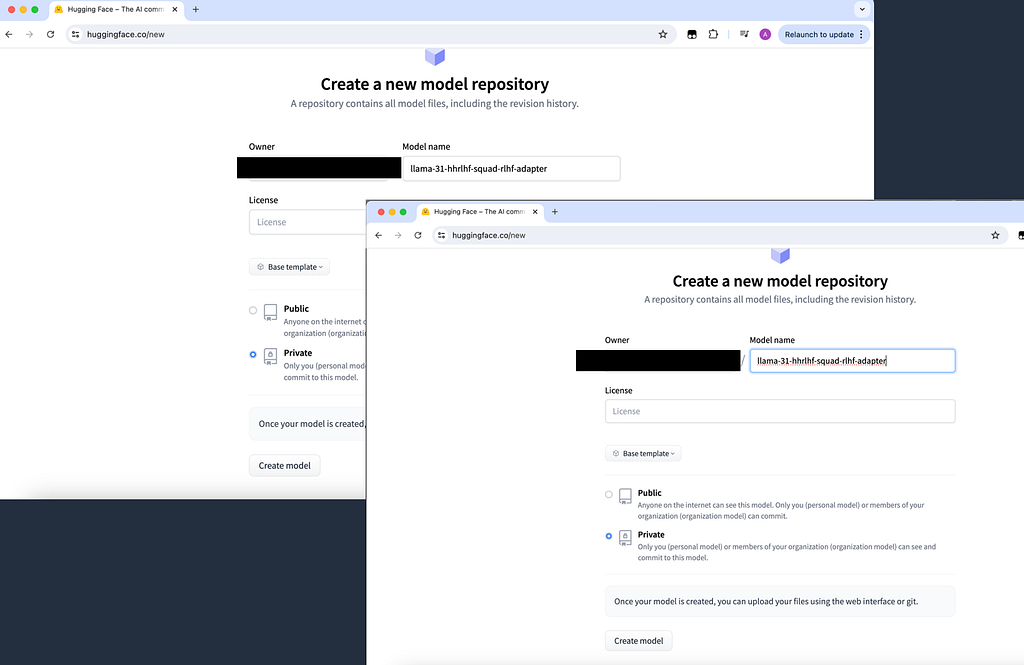
We can then create two private model repositories. Feel free to stick to my naming convention or pick a name of choice. If you name your repositories differently make sure to also adjust the code in the notebook.
Once created, we can see the model repositories in our HuggingFace profile.
To authenticate against the HuggingFace model hub when pulling or pushing models we need to create an access token, which we will use later in the notebook. For this click on the account icon on the top right of the HuggingFace landing page and pick „Settings“ in the menu.
In the settings we select the menu item “Access Tokens” and then “+ Create new token.”
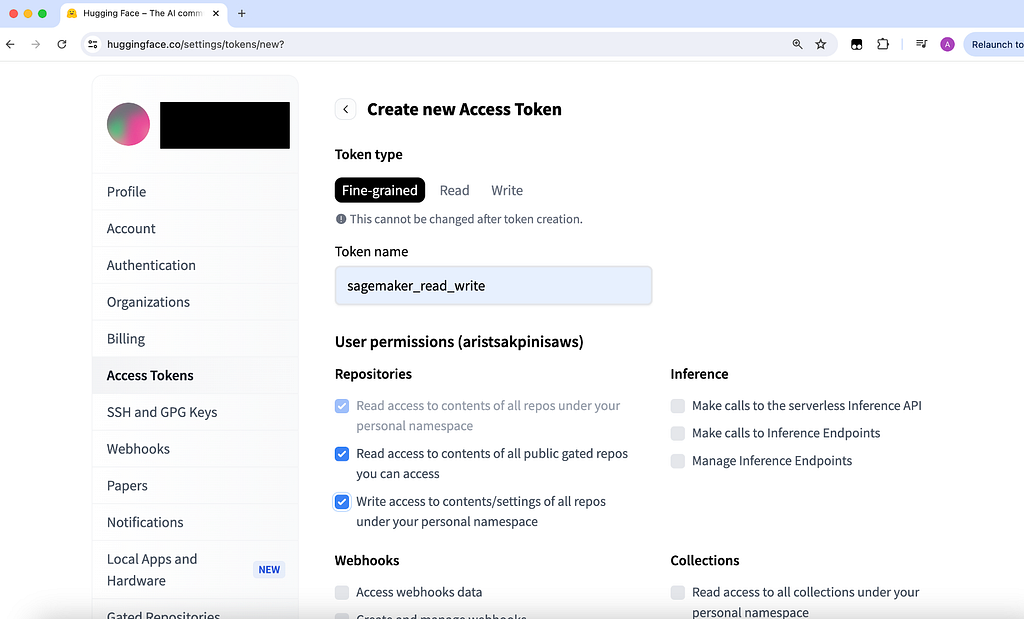
According to the principle of least privileges we want to create a token with fine-grained permission configurability. For our purpose read and write access to repositories is sufficient — this is why we check all three boxes in this section. Then we scroll down and create the token.
Once created the access token appears in plain text. Since the token will only be displayed once it makes sense to store it in encrypted format for example in a password manager.
Datasets
Now that we are finished with the prerequisites we can move on to the datasets we will be using for our endeavor.

For training our reward model we will be using the Anthropic/hh-rlhf dataset, which is distributed under MIT license. This is a handcrafted preference dataset Anthropic has open-sourced. It consists of chosen and rejected model completions to one and the same prompt input. Further, it comes in different fashions, targeting alignment areas like harmlessness, helpfulness and more. For our demonstration we will use the ”helpful” subset to preference align our Llama model towards helpful answers.
For the actual PA step with PPO and the previously trained reward model we need an additional dataset representing the target domain of our model. Since we are fine-tuning an instruct model towards helpfulness we need a set of instruction-style prompts. The Stanford Question&Answering dataset (SQuAD), distributed under the CC BY-SA 4.0 license, provides us with question — context — answer pairs across a broad range of different areas of expertise. For our experiment we will aim for single-turn open Question&Answering. Hence we will use only the “question” feature of the dataset.
Code repository
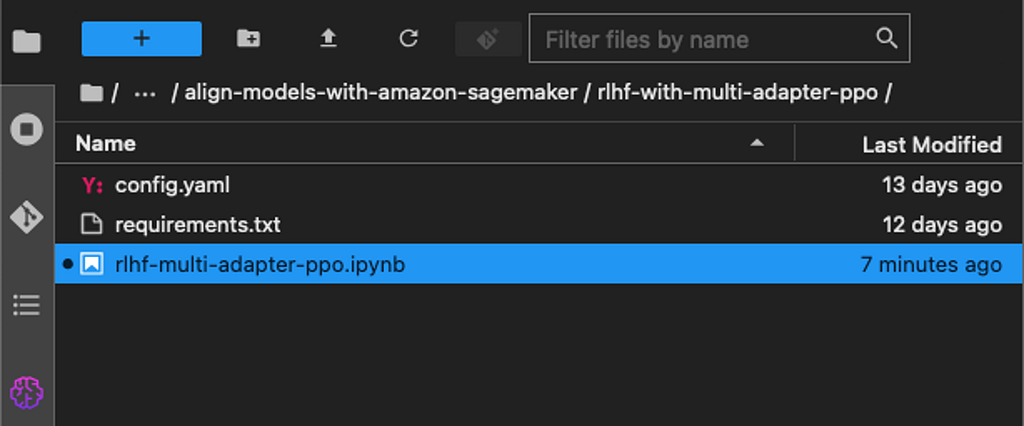
After having looked into the datasets we will use let‘s take a look into the directory structure and the files we will use in this demonstration. The directory consists of 3 files: config.yaml, a configuration file for running SageMaker jobs through the remote decorator and requirements.txt for extending the dependencies installed in the training container. Finally, there is the rlhf-multi-adapter-ppo.ipynb notebook containing the code for our E2E PA.
The previously mentioned config.yaml file holds important configurations for the training jobs triggered by the remote decorator, e.g. training instance type or training image.
Notebook
Now, let’s open the rlhf-multi-adapter-ppo.ipynb notebook. First, we install and import the required dependencies.
Data preprocessing reward model training dataset
As previously discussed, we will be using the Anthropic/hh-rlhf dataset for training our reward model. Therefore, we need to convert the raw dataset into the above specified structure, where “input_ids” and “attention_mask” are the outputs of input tokenization. This format is specified as interface definition by the HuggingFace trl RewardTrainer class and makes the accepted and rejected answers easily accessible during reward model training.
DatasetDict({
train: Dataset({
features: ['input_ids_chosen', 'attention_mask_chosen', 'input_ids_rejected', 'attention_mask_rejected'],
num_rows: ...
})
test: Dataset({
features: ['input_ids_chosen', 'attention_mask_chosen', 'input_ids_rejected', 'attention_mask_rejected'],
num_rows: ...
})
})
We login to the HuggingFace hub. Then, we retrieve the “helpful-base” of the „Anthropic/hh-rlhf“ dataset. The raw dataset structure looks as follows, we also take a look into an example dataset item.
Next, we parse the conversations into an array seperated by conversation turn and role.
def extract_dialogue(input_text):
# Split the input by lines and initialize variables
lines = input_text.strip().split("nn")
dialogue_list = []
# Iterate through each line and extract the dialogue
for line in lines:
# Check if the line starts with "Human" or "Assistant" and split accordingly
if line.startswith("Human:"):
role = "user"
content = line.replace("Human: ", "").strip()
elif line.startswith("Assistant:"):
role = "assistant"
content = line.replace("Assistant: ", "").strip()
else:
# If the line doesn't start with "Human" or "Assistant", it's part of the previous message's content
# Append it to the last message's content
dialogue_list[-1]["content"] += "nn" + line.strip()
continue
# Append the extracted dialogue piece to the list
dialogue_list.append({"role": role, "content": content})
return dialogue_list
def process(row):
row["chosen"] = extract_dialogue(row["chosen"])
row["rejected"] = extract_dialogue(row["rejected"])
row["prompt"] = row["chosen"][0]["content"]
return row
ds_processed = ds.map(
process,
load_from_cache_file=False,
)
Based on it’s pre-training process, every model has a specific set of syntax and special tokens prompts should be optimized towards — this is the essence of prompt engineering and needs to be considered when fine-tuning. For the Meta Llama models this can be found in the llama-recipes GitHub repository. To follow these prompting guidelines for an ideal result we are encoding our dataset accordingly.
# Adjusting to llama prompt template format: https://github.com/meta-llama/llama-recipes
system_prompt = "Please answer the user's question to the best of your knowledge. If you don't know the answer respond that you don't know."
def encode_dialogue_turn(message):
return f'<|start_header_id|>{message.get("role")}<|end_header_id|>{message.get("content")}<|eot_id|>'
def encode_dialogue(dialogue):
if system_prompt:
return f'<|begin_of_text|><|start_header_id|>system<|end_header_id|>{system_prompt}<|eot_id|>{functools.reduce(lambda a, b: a + encode_dialogue_turn(b), dialogue, "")}'
else:
return f'<|begin_of_text|>{functools.reduce(lambda a, b: a + encode_dialogue_turn(b), dialogue, "")}'
def encode_row(item):
return {"chosen": encode_dialogue(item["chosen"]), "rejected": encode_dialogue(item["rejected"]), "prompt": item["prompt"]}
def encode_dataset(dataset):
return list(map(encode_row, dataset))
encoded_dataset = ds_processed.map(encode_row)
Then we are tokenizing the “chosen” and “rejected” columns. Subsequently we remove the plain text columns as we don’t need them any more. The dataset is now in the format we were aiming for.
# Tokenize and stack into target format
def preprocess_function(examples):
new_examples = {
"input_ids_chosen": [],
"attention_mask_chosen": [],
"input_ids_rejected": [],
"attention_mask_rejected": [],
}
for chosen, rejected in zip(examples["chosen"], examples["rejected"]):
tokenized_chosen = tokenizer(chosen)
tokenized_rejected = tokenizer(rejected)
new_examples["input_ids_chosen"].append(tokenized_chosen["input_ids"])
new_examples["attention_mask_chosen"].append(tokenized_chosen["attention_mask"])
new_examples["input_ids_rejected"].append(tokenized_rejected["input_ids"])
new_examples["attention_mask_rejected"].append(tokenized_rejected["attention_mask"])
return new_examples
tokenized_dataset_hhrlhf = encoded_dataset.map(
preprocess_function,
batched=True,
).remove_columns(["chosen", "rejected", "prompt"])
Finally, we are uploading the dataset to Amazon S3. Please adjust the bucket path to a path pointing to a bucket in your account.
Data preprocessing PPO dataset
As previously discussed, we will be using the Stanford Question&Answering Dataset (SQuAD) for the actual PA step with PPO. Therefore we need to convert the raw dataset into a pre-define structure, where “input_ids“ is the vectorized format of the “query“” a padded version of a question.
DatasetDict({
train: Dataset({
features: ['input_ids', 'query'],
num_rows: ...
})
test: Dataset({
features: ['input_ids', 'query'],
num_rows: ...
})
})
This time we are not pulling the datasets from the HuggingFace hub — instead we are cloning them from a GitHub repository.
Next, we parse the conversations into an array separated by conversation turn and role. Then we are encoding our dataset according to the Meta Llama prompting guidelines for an ideal result.
def extract_questions(dataset):
ret_questions = []
for topic in dataset:
paragraphs = topic['paragraphs']
for paragraph in paragraphs:
qas = paragraph['qas']
for qa in qas:
ret_questions.append([{
"role": "system", "content": f'Instruction: Please answer the user's question to the best of your knowledge. If you don't know the answer respond that you don't know.',
}, {
"role": "user", "content": qa['question'],
}])
return ret_questions
# Adjusting to llama prompt template format: https://github.com/meta-llama/llama-recipes
def encode_dialogue_turn(message):
message = message
return f'<|start_header_id|>{message.get("role")}<|end_header_id|>{message.get("content")}<|eot_id|>'
def encode_dialogue(dialogue):
return {'input': f'<|begin_of_text|>{functools.reduce(lambda a, b: a + encode_dialogue_turn(b), dialogue, "")}'}
def encode_dataset(dataset):
#print(dataset)
return list(map(encode_dialogue, dataset))
encoded_train = encode_dataset(extract_questions(d_train['data']))
encoded_test = encode_dataset(extract_questions(d_test['data']))
We are padding our training examples to a maximum of 2048 tokens to reduce our training memory footprint. This can be adjusted to up to a model’s maximum context window. The threshold should be a good compromise between adhering to prompt length required by a specific use case or domain and keeping the training memory footprint small. Note, that larger input token sizes might require scaling out your compute infrastructure.
# Restrict training context size (due to memory limitations, can be adjusted)
input_min_text_length = 1
input_max_text_length = 2048
def create_and_prepare_dataset(tokenizer, dataset):
input_size = LengthSampler(input_min_text_length, input_max_text_length)
def tokenize(example):
text_size = input_size()
example["input_ids"] = tokenizer.encode(example["input"])[:text_size]
example["query"] = tokenizer.decode(example["input_ids"])
return example
dataset = dataset.map(tokenize, batched=False)
dataset.set_format("torch")
return dataset
tokenized_dataset_squad = create_and_prepare_dataset(tokenizer, dataset_dict).remove_columns(["input"])
Finally, we are uploading the dataset to s3. Please adjust the bucket path to a path pointing to a bucket in your account.
Reward model training
For the training of the reward model we are defining two helper functions: One function counting the trainable parameters of a model to showcase how LoRA impacts the trainable parameters and another function to identify all linear modules in a model since they will be targeted by LoRA.
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
def find_all_linear_names(hf_model):
lora_module_names = set()
for name, module in hf_model.named_modules():
if isinstance(module, bnb.nn.Linear4bit):
names = name.split(".")
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if "lm_head" in lora_module_names: # needed for 16-bit
lora_module_names.remove("lm_head")
return list(lora_module_names)
The training fuction “train_fn“ is decorated with the remote decorator. This allows us to execute it as SageMaker training job. In the decorator we define a couple of parameters alongside the ones specified in the config.yaml. These parameters can be overwritten by the actual function call when triggering the training job.
In the training function we first set a seed for determinism. Then we initialize an Accelerator object for handling distributed training. This object will orchestrate our distributed training in a data parallel manner across 4 ranks (note nproc_per_node=4 in decorator parameters) on a ml.g5.12xlarge instance (note InstanceType: ml.g5.12xlarge in config.yaml).
We then log into the HuggingFace hub and load and configure the tokenizer.
# Start training with remote decorator (https://docs.aws.amazon.com/sagemaker/latest/dg/train-remote-decorator.html). Additional job config is being pulled in from config.yaml.
@remote(keep_alive_period_in_seconds=0, volume_size=100, job_name_prefix=f"train-{model_id.split('/')[-1].replace('.', '-')}-reward", use_torchrun=True, nproc_per_node=4)
def train_fn(
model_name,
train_ds,
test_ds=None,
lora_r=8,
lora_alpha=32,
lora_dropout=0.1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
gradient_accumulation_steps=1,
learning_rate=2e-4,
num_train_epochs=1,
fsdp="",
fsdp_config=None,
chunk_size=10000,
gradient_checkpointing=False,
merge_weights=False,
seed=42,
token=None,
model_hub_repo_id=None,
range_train=None,
range_eval=None
):
set_seed(seed)
# Initialize Accelerator object handling distributed training
accelerator = Accelerator()
# Login to HuggingFace
if token is not None:
login(token=token)
# Load tokenizer. Padding side is "left" because focus needs to be on completion
tokenizer = AutoTokenizer.from_pretrained(model_name, padding_side = "left")
# Set tokenizer's pad Token
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
In the next step we are loading the training data from S3 and load them into a HuggingFace DatasetDict object. Since this is a demonstration we want to be able training with only a subset of the data to save time and resources. For this we can configure the range of dataset items to be used.
# Load data from S3
s3 = s3fs.S3FileSystem()
dataset = load_from_disk(train_ds)
# Allow for partial dataset training
if range_train:
train_dataset = dataset["train"].select(range(range_train))
else:
train_dataset = dataset["train"]
if range_eval:
eval_dataset = dataset["test"].select(range(range_eval))
else:
eval_dataset = dataset["test"]
We are using the HuggingFace bitsandbytes library for quantization. In this configuration, bitsandbytes will replace all linear layers of the model with NF4 layers and the computation as well as storage data type to bfloat16. Then, the model is being loaded from HuggingFace hub in this quantization configuration using the flash attention 2 attention implementation for the attention heads for further improved memory usage and computational efficiency. We also print out all trainable parameters of the model in this state. Then, the model is prepared for quantized training.
# Specify quantization config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
quant_storage_dtype=torch.bfloat16
)
# Load model with classification head for reward
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
#num_labels=1,
trust_remote_code=True,
quantization_config=bnb_config,
attn_implementation="flash_attention_2",
use_cache=False if gradient_checkpointing else True,
cache_dir="/tmp/.cache"
)
# Pre-LoRA trainable paremeters
print_trainable_parameters(model)
# Set model pad token id
model.config.pad_token_id = tokenizer.pad_token_id
# Prepare model for quantized training
model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=gradient_checkpointing)
Next, we discover all linear layers of the model to pass them into a LoraConfig which specifies some LoRA hyperparameters. Please note, that unlike for traditional LLM training the task_type is not “CAUSAL_LM” but ”SEQ_CLS” since we are training a reward model and not a text completion model. The configuration is applied to the model and the training parameters are printed out again. Please note the difference in trainable and total parameters.
# Get lora target modules
modules = find_all_linear_names(model)
print(f"Found {len(modules)} modules to quantize: {modules}")
# Specify LoRA config
config = LoraConfig(
r=lora_r,
lora_alpha=lora_alpha,
target_modules=modules,
lora_dropout=lora_dropout,
bias="none",
task_type="SEQ_CLS"
)
# Make sure to not train for CLM
if config.task_type != "SEQ_CLS":
warnings.warn(
"You are using a `task_type` that is different than `SEQ_CLS` for PEFT. This will lead to silent bugs"
" Make sure to pass --lora_task_type SEQ_CLS when using this script."
)
# Create PeftModel
model = get_peft_model(model, config)
# Post-LoRA trainable paremeters
print_trainable_parameters(model)
We define the RewardConfig holding important training hyperparameters like training batch size, training epochs, learning rate and more. We also define a max_length=512. This will be the maximum length of prompt+response pairs being used for reward adapter training and will be enforced through left-side padding to preserve the last conversation turn which marks the key difference between chosen and rejected sample. Again, this can be adjusted to up to a model’s maximum context window while finding a good compromise between adhering to prompt length required by a specific use case or domain and keeping the training memory footprint small.
Further, we initialize the RewardTraining object orchestrating the training with this configuration and further training inputs like model, tokenizer and datasets. Then we kick off the training. Once the training has finished we push the reward model adapter weights to the reward model model repository we have created in the beginning.
# Specify training config
reward_config = RewardConfig(
per_device_train_batch_size=per_device_train_batch_size,
per_device_eval_batch_size=per_device_eval_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
gradient_checkpointing=gradient_checkpointing,
logging_strategy="steps",
logging_steps=100,
log_on_each_node=False,
num_train_epochs=num_train_epochs,
learning_rate=learning_rate,
bf16=True,
ddp_find_unused_parameters=False,
fsdp=fsdp,
fsdp_config=fsdp_config,
save_strategy="no",
output_dir="outputs",
max_length=512,
remove_unused_columns=False,
gradient_checkpointing_kwargs = {"use_reentrant": False}
)
# Initialize RewardTrainer object handling training
trainer = RewardTrainer(
model=model,
tokenizer=tokenizer,
args=reward_config,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
trainer.train()
trainer.model.save_pretrained("/opt/ml/model", safe_serialization=True)
if model_hub_repo_id is not None:
trainer.model.push_to_hub(repo_id=model_hub_repo_id)
with accelerator.main_process_first():
tokenizer.save_pretrained("/opt/ml/model")
We can now kickoff the training itself. Therefor we call the training function which kicks off an ephemeral training job in Amazon SageMaker. For this we need to pass some parameters to the training function, e.g. the model id, training dataset path and some hyperparameters. Note that the hyperparameters used for this demonstration can be adjusted as per requirement. For this demonstration we work with 100 training and 10 evaluation examples to keep the resource and time footprint low. For a real-world use case a full dataset training should be considered. Once the training has started the training logs are streamed to the notebook.
# Start training job
train_fn(
model_id,
train_ds=dataset_path_hhrlhf,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
gradient_accumulation_steps=2,
gradient_checkpointing=True,
num_train_epochs=1,
token=hf_token,
model_hub_repo_id=model_hub_repo_id,
range_train=100,
range_eval=10
)
Multi-adapter PPO
For the actual PA step with PPO we are reusing function counting the trainable parameters of a model to showcase how LoRA impacts the trainable parameters. Sililarily to the reward model training step, the training fuction “train_fn“ is decorated with the remote decorator allowing us to execute it as SageMaker training job.
In the training function we first set a seed for determinism. Then we initialize an Accelerator object for handling distributed training. As with the reward adapter training, this object will handle our distributed training in a data parallel manner across 4 ranks on a ml.g5.12xlarge instance.
We then log into the HuggingFace hub and load and configure the tokenizer. In the next step we are loading the training data from S3 and load them into a HuggingFace DatasetDict object. Since this is a demonstration we want to be able training with only a subset of the data to save time and resources. For this we can configure the range of dataset items to be used.
# Start training with remote decorator (https://docs.aws.amazon.com/sagemaker/latest/dg/train-remote-decorator.html). Additional job config is being pulled in from config.yaml.
@remote(keep_alive_period_in_seconds=0, volume_size=100, job_name_prefix=f"train-{model_id.split('/')[-1].replace('.', '-')}-multi-adapter-ppo", use_torchrun=True, nproc_per_node=4)
def train_fn(
model_name,
train_ds,
rm_adapter,
log_with=None,
use_safetensors=None,
use_score_scaling=False,
use_score_norm=False,
score_clip=None,
seed=42,
token=None,
model_hub_repo_id=None,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
gradient_accumulation_steps=2,
gradient_checkpointing=True,
num_train_epochs=1,
merge_weights=True,
range_train=None,
):
set_seed(seed)
# Initialize Accelerator object handling distributed training
accelerator = Accelerator()
# Login to HuggingFace
if token is not None:
login(token=token)
# Load tokenizer. Padding side is "left" because focus needs to be on completion
tokenizer = AutoTokenizer.from_pretrained(model_name, padding_side = "left")
# Set tokenizer's pad Token
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
# Load data from S3
s3 = s3fs.S3FileSystem()
dataset = load_from_disk(train_ds)
# Allow for partial dataset training
if range_train:
train_dataset = dataset["train"].select(range(range_train))
else:
train_dataset = dataset["train"]
Next, we define a LoraConfig which specifies the LoRA hyperparameters. Please note, that this time the task_type is “CAUSAL_LM” since we are aiming to fine-tune a text completion model.
# Specify LoRA config
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
We are using the HuggingFace bitsandbytes library for quantization. In this configuration, bitsandbytes will replace all linear layers of the model with NF4 layers and the computation to bfloat16.
# Specify quantization config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_use_double_quant=True, bnb_4bit_compute_dtype=torch.bfloat16
)
Then, the model is being loaded from HuggingFace hub in this quantization using both the specified LoraConfig and BitsAndBytesConfig. Note that this model is not wrapped into a simple AutoModelForCausalLM class, instead we are using a AutoModelForCausalLMWithValueHead class taking our reward model adapter as input. This is a model class purposely built for multi-adapter PPO, orchestrating adapter loading and plugins during the actual training loop we will discuss subsequently.For the sake of completeness we also print out all trainable parameters of the model in this state.
# Load model
model = AutoModelForCausalLMWithValueHead.from_pretrained(
model_name,
#device_map='auto',
peft_config=lora_config,
quantization_config=bnb_config,
reward_adapter=rm_adapter,
use_safetensors=use_safetensors,
#attn_implementation="flash_attention_2",
)
# Set model pad token id
model.config.pad_token_id = tokenizer.pad_token_id
if gradient_checkpointing:
model.gradient_checkpointing_enable()
# Trainable paremeters
print_trainable_parameters(model)
We define the PPOConfig holding important training hyperparameters like training batch size, learning rate and more. Further, we initialize the PPOTrainer object orchestrating the training with this configuration and further training inputs like model, tokenizer and datasets. Note, that the ref_model for the computation of the KL divergence is not specified. As previously discussed, in this configuration the PPOTrainer uses a reference model with the same architecture as the model to be optimized with shared layers. Further, the inference parameters for inference to retrieve the text completion based on the query from the training dataset are defined.
# Specify PPO training config
config = PPOConfig(
model_name,
log_with=None,
learning_rate=1e-5,
batch_size=per_device_train_batch_size,
mini_batch_size=1,
gradient_accumulation_steps=gradient_accumulation_steps,
optimize_cuda_cache=True,
seed=42,
use_score_scaling=False,
use_score_norm=False,
score_clip=None,
)
# Initialize PPOTrainer object handling training
ppo_trainer = PPOTrainer(
config,
model,
ref_model=None,
tokenizer=tokenizer,
dataset=train_dataset,
data_collator=collator,
)
# Specifying inference params
generation_kwargs = {
"top_k": 0.0,
"top_p": 0.9,
"do_sample": True,
"pad_token_id": tokenizer.pad_token_id,
"max_new_tokens": 32,
}
Then we execute the actual multi-adapter PPO training loop as follows on a batch of training data: First, the LoRA adapters we are RLHF fine-tuning are applied for inference to retrieve a text completion based on the query from the training dataset. The response is decoded into plain text and combined with the query. Then, the reward adapters are applied to compute the reward of the the query — completion pair in tokenized form. Subsequently, the reward value is used alongside the question and response tensors for the optimization step. Note, that in the background the Kullback–Leibler-divergence (KL-divergence) between the inference logits of the fine-tuned model and base model (prediction shift penalty) is computed and included as additional reward signal integrated term used during the optimization step. Since this is based on the same input prompt, the KL-divergence acts as a measure of how these two probability distributions and hence the models themselves differ from each other over training time. This divergence is subtracted from the reward term, penalizing divergence from the base model to assure algorithmic stability and linguistic consistency. Finally, the adapters we are RLHF fine-tuning are applied again for the back propagation.
Then we kick off the training. Once the training has finished we push the preference-alignged model adapter weights to the rlhf model model repository we have created in the beginning.
step = 0
for _epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
question_tensors = batch["input_ids"]
# Inference through model being fine-tuned
response_tensors = ppo_trainer.generate(
question_tensors,
return_prompt=False,
**generation_kwargs,
)
# Decode response
batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)
# Concat query and response
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
# Tokenize query - response pair
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt").to(ppo_trainer.accelerator.device)
# Compute reward score
raw_rewards = ppo_trainer.accelerator.unwrap_model(ppo_trainer.model).compute_reward_score(**inputs)
rewards = [raw_rewards[i, -1, 1] for i in range(len(raw_rewards))] # take last token
# Run PPO step
stats = ppo_trainer.step(question_tensors, response_tensors, rewards)
ppo_trainer.log_stats(stats, batch, rewards)
step = step + 1
if accelerator.is_main_process:
ppo_trainer.save_pretrained("/opt/ml/model", safe_serialization=True)
if model_hub_repo_id is not None:
ppo_trainer.push_to_hub(repo_id=model_hub_repo_id)
tokenizer.push_to_hub(repo_id=model_hub_repo_id)
with accelerator.main_process_first():
tokenizer.save_pretrained("/opt/ml/model")
We can now kickoff the training itself. Therefore we call the training function which kicks off an ephemeral training job in Amazon SageMaker. For this we need to pass some parameters to the training function, e.g. the model id, training dataset path, reward model path and some hyperparameters. Note that the hyperparameters used for this demonstration can be adjusted as per requirement. For this demonstration we work with 100 training examples to keep the resource and time footprint low. For a real-world use case a full dataset training should be considered. Once the training has started the training logs are streamed to the notebook.
train_fn(
model_id,
train_ds=dataset_path_squad,
rm_adapter=rm_adapter,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
num_train_epochs=1,
token=hf_token,
model_hub_repo_id=model_hub_repo_id,
range_train=100
)
Deployment
Finally, we want to test the tuned model. Therefore we will deploy it to a SageMaker endpoint. We start with importing required dependencies as well as setting up the SageMaker session and IAM.
For the deployment we are using the SageMaker — Huggingface integration with the TGI containers. We define the instance type, image as well as model-related parameters like the base model, LoRA adapter, quantization and others.
# sagemaker config
instance_type = "ml.g5.4xlarge"
number_of_gpu = 1
health_check_timeout = 300
# TGI config
config = {
'HF_MODEL_ID': "meta-llama/Meta-Llama-3.1-8B-Instruct",
'LORA_ADAPTERS': "**HF_REPO_ID**",
'SM_NUM_GPUS': json.dumps(1), # Number of GPU used per replica
'MAX_INPUT_LENGTH': json.dumps(1024), # Max length of input text
'MAX_TOTAL_TOKENS': json.dumps(2048), # Max length of the generation (including input text),
'QUANTIZE': "bitsandbytes", # comment in to quantize
'HUGGING_FACE_HUB_TOKEN': hf_token
}
image_uri = get_huggingface_llm_image_uri(
"huggingface",
version="2.0"
)
# create HuggingFaceModel
llm_model = HuggingFaceModel(
role=role,
image_uri=image_uri,
env=config
)
Then we deploy the model. Once the model has been deployed we can test the model inference with a prompt of our choice. Note that we are using the encode_dialogue function defined during data preprocessing to optimize the prompt for the Llama model.
# Deploy model to an endpoint
# https://sagemaker.readthedocs.io/en/stable/api/inference/model.html#sagemaker.model.Model.deploy
llm = llm_model.deploy(
endpoint_name=f'llama-31-8b-instruct-rlhf-{datetime.now().strftime("%Y%m%d%H%M%S")}', # alternatively "llama-2-13b-hf-nyc-finetuned"
initial_instance_count=1,
instance_type=instance_type,
container_startup_health_check_timeout=health_check_timeout, # 10 minutes to be able to load the model
)
parameters = {
"top_p": 0.8,
"temperature": 0.1,
"return_full_text": True,
"stop": [],
}
encoded_message = encode_dialogue([{'content': 'Who won the FIFA World cup 2014 in Brazil?', 'role': 'user'}])
response = llm.predict({"inputs": encoded_message['input'], **parameters})
Cleanup
Finally, we cleanup the deployed endpoint and model entity to be responsible in resource usage.
# Delete model and endpoint
llm.delete_model()
llm.delete_endpoint()
Cost
Both reward model adapter training and multi-adapter PPO training were executed on an ml.g5.12xlarge instance using a dataset of 100 randomly sampled rows from the respective training datasets. The average training time was approximately 400 seconds for each step. As of November 2024, this instance type is priced at $7.09/hour in the us-east-1 region.
Consequently, the end-to-end training cost for this RLHF implementation with multi-adapter PPO amounts to less than ($7.09 * 400s)/(3600s * 100) ~ $0.0079 per individual training sample for each of the two training steps. This translates to less than $0.015 per 1000 training tokens for the reward model training and less than $0.0039 per 1000 training tokens for the multi-adapter PPO step.
For inference, the model is hosted on an ml.g5.4xlarge instance. As of November 2024, this instance type is priced at $2.03/hour in the us-east-1 region.
Conclusion
In this blog post, we explored RLHF with multi-adapter PPO, a frugal approach to preference alignment for large language models. We covered the following key points:
- The importance of preference alignment in boosting LLM performance and its role in the democratization of AI.
- The principles of RLHF and its two-step process involving reward model training and PPO-based fine-tuning.
- Challenges associated with implementing RLHF, including computational resources and orchestration complexity.
- The multi-adapter PPO approach as a solution to reduce infrastructure and orchestration footprint.
- A detailed, end-to-end implementation using HuggingFace frameworks and Amazon SageMaker, covering data preprocessing, reward model training, multi-adapter PPO training, and model deployment.
This frugal approach to RLHF makes preference alignment more accessible to a broader range of practitioners, potentially accelerating the development and deployment of aligned AI systems.
By reducing computational requirements and simplifying the implementation process, multi-adapter PPO opens up new possibilities for fine-tuning language models to specific domains or user preferences.
As the field of AI continues to evolve, techniques like this will play a crucial role in creating more efficient, effective, and aligned language models. I’d like to encourage readers to experiment with this approach, adapt it to their specific use cases, and share their success stories in building responsible and user-centric LLMs.
If you’re interested in learning more about LLM pre-training and alignment, I recommend checking out the AWS SkillBuilder course I recently published with my esteemed colleagues Anastasia and Gili.
Preference Alignment for Everyone! was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Preference Alignment for Everyone!
Go Here to Read this Fast! Preference Alignment for Everyone!