
Why static workload is insufficient and what I learned by comparing HNSWLIB and DiskANN using streaming workload

Vector databases are built for high-dimensional vector retrieval. Today, many vectors are embeddings generated by deep neural nets like GPTs and CLIP to represent data points such as pieces of text, images, or audio tracks. Embeddings are used in many applications like search engines, recommendation systems, and chatbots. You can index embeddings in a vector database, which uses an Approximate Nearest Neighbor (ANN) index to supports fast retrieval of top neighbors by a distance function like Cosine or Euclidian. Latency is 2 to 10 milliseconds for a 1 million vectors index, and scales sub-linearly (i.e., O(log n)) with respect to index size.
In this post, I point to several problems with the way we currently evaluate ANN indexes and suggest a new type of evaluation. This post focuses on ANN indexes for embedding vectors, an area that is getting a lot of attention recently: vector database startups like Pinecone, Zilliz, Qdrant, and Weaviate offer embedding indexing and retrieval as their core service.
1. Static workload benchmark is insufficient.
The standard way to evaluate ANN indexes is to use a static workload benchmark, which consists of a fixed dataset and a fixed query set.

A static workload benchmark first builds the ANN index from the fixed dataset, and then runs the fixed query set several times with different parameter settings and measures the highest achievable query throughput at each minimum accuracy level. After performing the same procedure for each ANN index, the benchmark generates a plot like the one below:
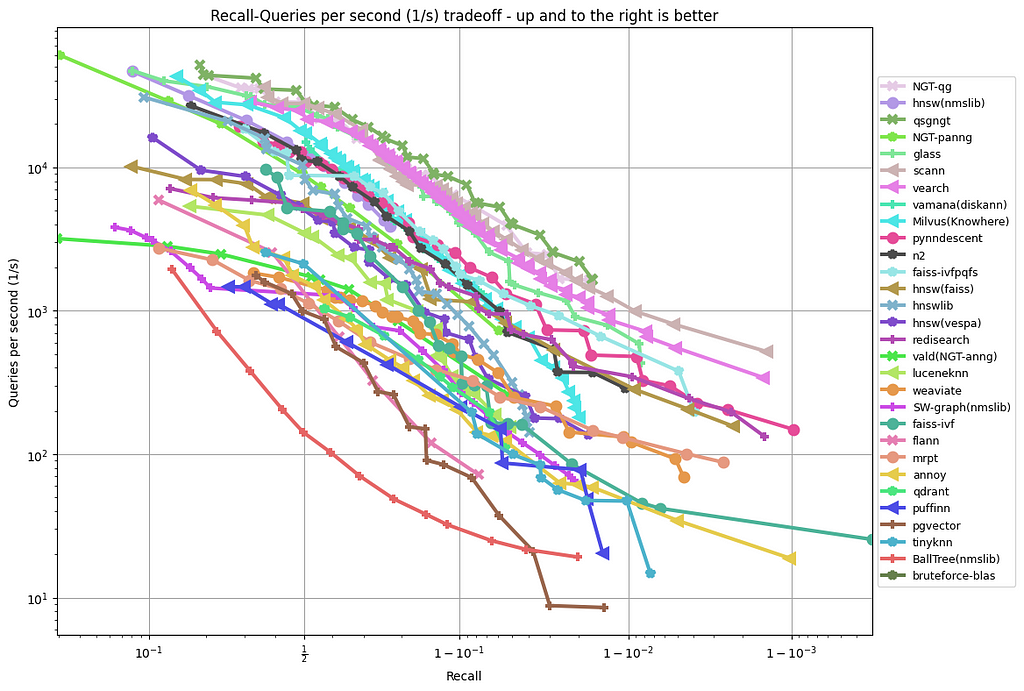
The plot above compares different ANN indexes using a static workload called glove-100-angular, which contains embeddings of words.
This evaluation approach was popularized by the ann-benchmarks project which started 5 years ago. Many vector databases are now measuring their performance using this approach in their tech blogs. See the Qdrant benchmark and Timescale benchmark.
Static workload benchmark has been useful because the result is easy to understand and allows us to compare the accuracy and query performance trade-off across different indexing algorithms using a same plot.
Except it is not nearly a complete evaluation of ANN indexes, and you should not choose ANN index for your project based only on this. It overly stresses on recall accuracy and query performance while skipping other important aspects like indexing performance and memory usage.
Indexing performance should be reflected.
Indexing throughput measures how fast the ANN index can accept new data points. Similar to query throughput, it is typically inversely correlated to recall accuracy. For example, the plot below shows the relationship between indexing throughput and recall of HNSWLIB and DiskANN Vamana indexes.

This plot is similar to the previous Recall-QPS plot, but from this plot you can see that higher recall is also a tradeoff of index performance. However, if I am interested in both indexing and query performance, this plot is still insufficient because it does not show the margin of which the recall-performance tradeoff is being made, as the static benchmark segregates indexing and querying workloads.
Many ANN indexes support bulk indexing API which can be much more optimized than point indexing (i.e., add vectors one at a time) and can create a more accurate index. For example, cluster-based ANN indexes build clusters of all vectors in batch. The static workload benchmark separates indexing and query workloads, so it encourages bulk indexing which may not be realistic.
One more issue related to indexing is product quantization (PQ). Many ANN indexes use PQ or other forms of vector compression to speed up compute. The static workload benchmark allows ANN indexes to build optimized compression codebook before the query phase starts, but such optimal codebook may not be achievable in practice.
Memory usage matters.
Most of the popular ANN indexes are in-memory, meaning their main data structure stays in volatile storage (DRAM) from which queries are served. Therefore, it is important to measure memory efficiency and its tradeoff with performance and recall accuracy. For example, in this research paper, the authors measured the memory usage of HNSW with 1 billion points to be 490 GB, while NSG is 303 GB, but on the recall and query performance side HNSW only slightly dominates NSG. This kind of trade-off should be front-and-center when it comes to benchmarking ANN indexes.
Still, it is difficult get a realistic picture of memory efficiency with only static benchmark for several reasons. For one, the ANN index algorithm can create a read-optimized index that is very compact at the expensive of subsequent indexing performance. For another, the workload only captures pure indexing or pure query but not a mix of both, which is more likely to happen in a real scenario like Q&A engine or chatbot when new data arrives constantly.
Data distribution shifts over time.
In static benchmark, the data and query sets are unchanged. This is not realistic as data and queries are driven by end users’ interest which changes over time. If the data and query sets are always fixed, then the best index is a cache that memorizes every query result. Recently, research in ANN indexes (e.g., FreshDiskANN) have started to measure out-of-distribution query performance — it is a right step forward.
What about deletes?
Delete API has become standard for ANN indexes, but no static benchmark is measuring this. Being able to handle deletes is important as the emerging AI-related application scenarios like chatbot are using ANN index as an operational storage that resembles online transaction processing (OLTP) databases, as data is constantly being added and modified.
2. Streaming workload tells you a lot more.
If an ANN index supports the following APIs:
- Insert(ID, vector)
- Query(vector)
- Delete(ID)
and if the usage scenario is anything but static data and queries (like, every scenario?), then a streaming workload benchmark can give you more insight into the characteristics of ANN indexes and how well they perform for your specific usage scenario.
A streaming workload benchmark consists of two streams: a data stream that corresponds to a sequence of Insert and Delete API calls, and a query stream for a sequence of Query API calls. It can be realized using an actual streaming system like Kafka, or more simply using a runbook with sequences of pointers to a data set and a query set similar to those used by a static benchmark.

The above diagram illustrates the streaming workload benchmark used in the NeurIPS 23′ Big ANN Benchmarks. Specifically, each step in the runbook corresponds to a batch of vectors, so the operations can be executed in parallel. This approach has the following benefits:
- Flexibility: workload patterns and data distribution shifts can be modelled as different streaming workloads which then get compiled to different runbooks.
- Realistic: indexing and query are interleaved so the ANN index must accommodate future insertions. Besides, the memory profile more accurately reflects real workload.
- Simple analysis: performance can be described using overall throughput rather than indexing vs. query throughputs, so the tradeoff between recall and performance can be visualized easily.
- Completeness: insert and delete operations are also evaluated.
In this blog post, I deep dive into (4) above and show you a new insight I discovered using a streaming workload benchmark.
Compare recall stability: HNSW vs. Vamana
When running a streaming workload benchmark, an important metric we collect is the recall of each query operation. We can compare different index setups (parameters, algorithms, etc.) by looking at their recall stability over time, and decide which index is suitable for a given usage scenario.
I measured the recall stability of DiskANN’s Vamana and various HNSW implementations under the streaming workload defined by the final runbook in the NeurIPS 23′ Big ANN Benchmarks.
Some background on Vamana and HNSW: they are both graph ANN indexes, and they are particularly good at handling embeddings. In a graph ANN index, each vector is a node, and query is executed as graph traversal. Directed edges are selectively constructed to limit memory usage while guaranteeing fast traversal from any node to any node. During in-place delete, for each in-coming neighbor node of a deleted node, graph ANN indexes perform edge repair to maintain the directed graph structure.
The first HNSW implementation we use is one based on HNSWLIB, with added Delete API implemented using a repair algorithm called repairConnectionsForUpdate, which is already part of HNSWLIB’s source code. The idea is to perform a “re-insert” of the node to be repaired and update its out-going neighbors at all levels. The figure blow shows the recall over time for both Vamana and HNSW.

Note that I set Vamana’s maximum degree parameter to 40 (R = 40) and HNSW’s base layer’s maximum degree also to 40 (M = 20, M0 = 40). So, they should use more-or-less the same memory.
It is clear from this plot that deletes have an adverse effect on recall, as recall monotonically decreases during consecutive deletes. In comparison, HNSW is much more affected by deletes than Vamana.
The second HNSW implementation we use replaces HNSWLIB’s edge repair algorithm with Vamana’s, which is quite different. The idea behind Vamana’s edge repair algorithm is to connect each in-coming neighbor of a deleted node to the out-going neighbors of the deleted node, while applying a pruning step to maintain a maximum degree constraint. In this case, we use HNSW’s original pruning algorithm. It is implemented by HNSWLIB in a function called getNeighborsByHeuristic2.

With all parameters staying the same, changing HNSWLIB’s edge repair algorithm to Vamana’s immediately improved HNSW’s recall stability.
Let’s go an extra mile and change the HNSW’s edge pruning algorithm to Vamana’s. Now the HNSW index is nearly the same as Vamana’s, except that it has multiple layers. We call this index “Multi-layer Vamana”.

You can see HNSW’s recall is now slightly higher than Vamana’s while using a similar amount of memory. I haven’t found this is observation in any research paper anywhere. Moreover, while performance is not in the figure, I noticed significant slowdown when switching to Vamana’s pruning algorithm.
In conclusion, by using the streaming workload benchmark, I was able to discover something new about different edge repair and pruning algorithms. A logical next step would be to look into the performance implications of these algorithms, and I can do this using the streaming workload benchmark.
3. Conclusion
To summarize, in this blog post, I pointed out that static workload benchmarks are insufficient for realistic evaluation of ANN indexes, and I described streaming workload benchmark which I think is a better replacement. I also used a specific streaming workload to uncover a new comparison between HNSW and Vamana indexes. Kudos to the team behind the NeurIPS 23′ Big ANN Benchmarks! They have open sourced the streaming workload I used in this blog post.
We need a TPC-C and TPC-H for vector databases.
There is still a lot of work to be done in benchmarking. ANN index is the core feature of vector databases, and they have raised over 350 million dollars. Yet many of them are still measuring performance using an outdated approach that no longer reflect actual usage scenarios. Database systems underwent a similar stage in the 90s and early 2000s. Then, standard benchmarks like TPC-C and TPC-H were developed and are still used today. We should have something like this for vector databases.
Please Use Streaming Workload to Benchmark Vector Databases was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Please Use Streaming Workload to Benchmark Vector Databases
Go Here to Read this Fast! Please Use Streaming Workload to Benchmark Vector Databases



