

.jpg){kind=link}
{kind=link}
{kind=link}
On Laplace’s brilliant solution to inverse probability and his discovery of the Central Limit Theorem
In the late 1600s, Jacob Bernoulli pondered over an interesting question: How do you estimate the probability of an event whose sample space is not fully accessible? How, for instance, do you estimate the chance of being hit in the head by a bolt from the sky during your lifetime? Or if you prefer a less dramatic setting, how do estimate the real proportion of black tickets in an urn filled with an unknown quantity of black and white tickets? The experimental setting was unmistakably binomial: a certain number of independent trials with only one of two possible outcomes in each trial. Jacob Bernoulli’s meditations on this binomial experiment led him to discover the Weak Law of Large Numbers. That was around 1689.
In 1733, forty years after Bernoulli’s discovery of the WLLN, a brilliant self-exiled Frenchman living a hand-to-mouth existence in England by the name Abraham De Moivre figured out how to accurately compute the probabilities expressed in Bernoulli’s binomial thought experiment. De Moivre’s technique, called De Moivre’s theorem (covered here), became one of the most influential discoveries of the 18th and 19th century mathematical thought.
And if that wasn’t enough, De Moivre also unintentionally introduced the world to the Normal distribution. But missing from De Moivre’s blockbuster accomplishments was any thought given to the following question:
How do you estimate the real (unknown) fraction of black tickets given only the observed fraction of black tickets in a single random sample?
It was the very question that Bernoulli had implicitly asked. In the language of probability, how how do you estimate P(p|X_bar_n), where p is the probability density of the real proportion of black tickets in the ticket-filled urn, and X_bar_n is the number of black tickets that you have actually counted in a random sample of size n. This probability is called inverse probability.
It’s worth taking a step back to appreciate how remarkable this concept is. The act of drawing a random sample and counting the number of black tickets in it spawns an infinite number of probable realities. Couched within each reality is a different candidate for the real proportion of black tickets — a real numbered quantity. Attached to this proportion is a probability density. This density is described by a Probability Density Function (PDF) which takes the observed fraction of black tickets as a parameter. If you know the PDF’s formula, you can plug in the observed fraction of black tickets and know the probability density (or what’s more practical, a range of possible values — a confidence interval) for the real fraction of black tickets in the urn.
The mere act of observing the fraction of black tickets in a single random sample immediately makes a small subset of the infinite set of possible universes much more probable.
In 1689, Bernoulli made no reference to inverse probability, leave alone its Many Worlds interpretations. It would be another century before two men — a Presbyterian preacher in England, and one of the greatest minds in France — would independently show how to calculate inverse probability. And it would be yet another century following their discoveries that the Many Worlds Interpretation of quantum mechanics itself would meet the pages of a scientific publication.
Incidentally, the English clergyman was Thomas Bayes (of the Bayes theorem fame) whose achievement deserves its own article. And the Frenchman — the hero of our article — was Pierre-Simon Marquis de Laplace. Laplace would not only crack open the problem of inverse probability but also use it as a powerful catalyst to discover the Central Limit Theorem.

Pierre-Simon Laplace was born in 1749 in a France that was very different from the kingdom from which his fellow countryman Abraham De Moivre had fled 60 years ago. De Moivre escaped from a country defined by the larger than life presence of Louis XIV and his unsparing hold over religious life. Laplace was to grow up during the more accommodating, almost laid-back reign of Louis XIV’s great-grandson, Louis XV.

{kind=link}
Unfortunately, and in sharp contrast to his great-grandfather’s era, Louis XV’s reign from 1715 to 1774 saw a precipitous weakening of the French Monarchy’s power. There was a great up-swell of resentment among the heaving masses of the French kingdom, a trend that was to fester and boil until it finally erupted into the French Revolution of 1789 and spilled over into a toxic purge of human life called the Reign of Terror.

{kind=link}
{kind=link}
{kind=link}
It was against this backdrop that Laplace grew up and somehow managed to do all the dozens of important things that people do like go to school, have a career, start a family, put kids through school, and become a grandparent. Oh, and in Laplace’s case, also make several ground breaking discoveries in physics, chemistry and math.
But Laplace wasn’t immune to the events unfolding around him. Indeed there was hardly a French scientist or philosopher who was spared the anguish of the revolution and the ensuing Reign of Terror, or the uncertainties bred by Napoleon Bonaparte’s eventual rise (twice over) as emperor and his subsequent fall (again twice over). Several of Laplace’s fellow scientists and friends, many of them France’s brightest minds — Antoine Lavoisier (1743–1794), Jean Sylvain Bailly (1736–1793), and Marquis de Condorcet (1743–1794) to name just a few—had succumbed to the excesses of this period.

It’s perhaps a testimony to Laplace’s astuteness and his keen judgement of the changing power equations of his times that he managed to keep himself and his family safe through what was arguably one of the most tumultuous periods in French history. Indeed, during the very times in which so many of his friends lost their livelihoods, their reputations, their freedoms, their loved ones, and even quite literally their heads, Laplace saw his career blossom, his stature as a scientist grow, and his importance to the French Republic rise.
For four prodigious decades spanning 1772 to 1812, Laplace immersed himself in a number of different problems on probability. Two key themes of his work were inverse probability and later on, the Central Limit Theorem. By 1774, Laplace had solved the problem of inverse probability. And true to the nature of the work done in his era, he spent the next several years perfecting his technique.
Laplace’s solution for inverse probability: the setting, the motivation, and the approach
Recollect the problem framed by Jacob Bernoulli in 1689. There is an urn containing an unknown number of black and white colored tickets. The true proportion p of black tickets in the urn is unknown. Thus, p is also the unknown ‘true’ probability of coming across a black ticket in a single random draw. Suppose you draw n tickets at random from the urn.
Let the discrete random variable X_bar_n denote the number of black tickets in your random sample. Thus, the observed proportion of black tickets in the sample is X_bar_n/n. X_bar_n follows the binomial probability distribution with parameters n and p, i.e. X_bar_n ~ Binomial(n,p).
Now let’s apply this theoretical setting of a ticket-filled urn to a real world scenario studied by Laplace. From the census data of Paris, Laplace found out that from 1745 to 1770, there were 251527 boys and 241945 girls born in Paris. Remember, the census data is often not accurate. At best, it’s a reasonable proxy for the actual population values. Hence the numbers that Laplace retrieved can be thought of as a rather large random sample.
The sample size n is 251527 + 241945 = 493472.
Let p be the real proportion of boys in the population of Paris. p is unknown.
Let X_bar_n represent the number of boys in the sample. Thus, X_bar_n = 251527.
The observed fraction of boys in the sample is:
X_bar_n/n = 251527/(251527 + 241945) = 0.50971.
X_bar_n is a binomial random variable.
Notation-wise, X_bar_n ~ Binomial(n=493472, p)
The binomial probability P(X_bar_n=251527 | n=493472, p) is given by the following well-known Probability Mass Function (PMF):

In the above formula, remember that the real fraction of boys ‘p’ in Paris’s population is unknown.
You may have noticed the enormous factorials in the formula of this binomial probability. Even if you assume that p is known, these factorials make it impossible to compute this binomial probability. A good thirty years before Laplace was even born, and a half century before he set his sights on the topic of probability, it was the approximation of this forward binomial probability for a known ‘p’ that Laplace’s fellow Frenchman, Abraham De Moivre, toiled upon — a toil that De Moivre committed himself to with such intense focus that he seems to have completely ignored the limited practical use of this probability.
You see, to calculate the forward binomial probability P(X_bar_n | n, p) conditioned upon n, and p, if you must obviously know the sample size n, and the real fraction p. The real fraction ‘p’ is found in prolific abundance in end-of-the-chapter problems in Statistics textbooks. But outside of such well-behaved neighborhoods, ‘p’ makes itself scare. In the real world, you would almost never know the true p for any phenomena. And therefore, in any practical setting, the computation of the forward binomial probability is of limited use to the practicing statistician.
Instead, what would be really useful is to treat the real, known, p as a continuous random variable, and to estimate its probability distribution conditioned upon a particular observed ratio X_bar_n/n. For exampl, recollect that in case of the Paris census data, X_bar_n/n = 251527/493472 = 0.50971.
Thus, we’d want to know the following probability:
P(p | n=493472, X_bar_n=251527)
Notice how this probability is the exact inverse of the ‘forward’ binomial probability:
P(X_bar_n=251527 | n=493472, p)
A half century after De Moivre was done with his life’s work on the subject, it was P(p | n, X_bar_n=x) — the inverse probability — that was the only probability in Laplace’s crosshairs.
Notice also that in the probability P(p | n, X_bar_n=x), p is a real number defined over the closed interval [0,1]. There are infinite possible values of p in [0,1]. So for any given p, P(p) must be necessarily zero. Thus, P(p=p_i | n, X_bar_n=x) is the Probability Density Function (PDF). A single point on this function will give you the probability density corresponding to some value of ‘p’.
In a practical setting, what you’d want to estimate is not a particular value of p but the probability of p (conditioned upon X_bar_n, and n) lying between two specified bounds p_low and p_high. In the language of Statistics, what you are seeking (and what Laplace sought) is not a point estimate, but an interval estimate of p.
Mathematically speaking, you’d want to calculate the following:

In his quest for a solution to this probability, Laplace worked through hundreds of pages of mind-numbingly tedious derivations and hand-calculations. Much of this work appears in his memoirs and books published from 1770 through 1812. They can be a real treat to go through if you are the sort of person who rejoices at the prospect of looking at mathematical symbols in volume. For the rest of us, the essence of Laplace’s approach toward inverse probability can be summed up in his ingenious use of the following equation:
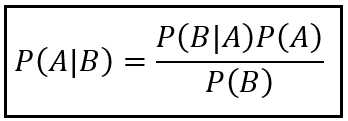
The above equation — generally known as Bayes’s theorem or Bayes’s rule — lets you calculate the probability P(A | B) in terms of its inverse P(B | A). For the problem Laplace was working upon, it can be used as follows:

I’ve omitted n and x for brevity. Laplace didn’t so much use the above equation directly as much as he arrived at it using a particular method of apportioning probabilities to different causes that he describes in detail his work.
In France, at least a decade before Laplace was to work upon the problem of inverse probability, a Presbyterian minister in England named Thomas Bayes (1701–1761) had already all but solved the problem. But Bayes’ approach toward inverse probability was remarkably different than Laplace’s. Besides, Bayes failed to publish his work in his lifetime.

{kind=link}
At any rate, using the following equation as the starting point, and using modern notation, I’ll explain the essence of Laplace’s line of attack on inverse probability.
There are three probabilities to be computed on the R.H.S. of the above equation:
- P(X_bar_n=x | p),
- P(p), and
- P(X_bar_n=x).
Let’s look at them one by one:
P(X_bar_n=x | p)
This is the easiest of the three to calculate. It is the forward binomial probability that can be computed using the well-known formula for the probability distribution of a binomial random variable:
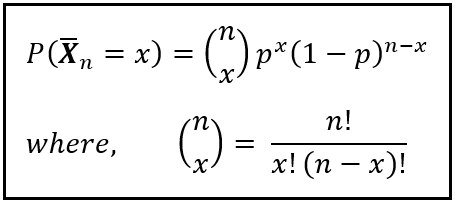
P(p)
P(p) is the probability density function of the unconditional prior probability. To arrive at P(p), Laplace employed what is known as the principle of insufficient reason which says the following:
If nothing specific or special is known or can be assumed about the probability distribution of a random variable, one should assume that it is uniformly distributed over the range of all possible values i.e. the support space of the variable.
The support for p is [0, 1]. By the above principle, we should consider p to be uniformly distributed over the [0, 1] interval. That is, p ~ Uniform(0,1). Therefore, for any i, P(p=p_i) = 1/(1–0) = 1. That is, a constant.
P(X_bar_n = x)
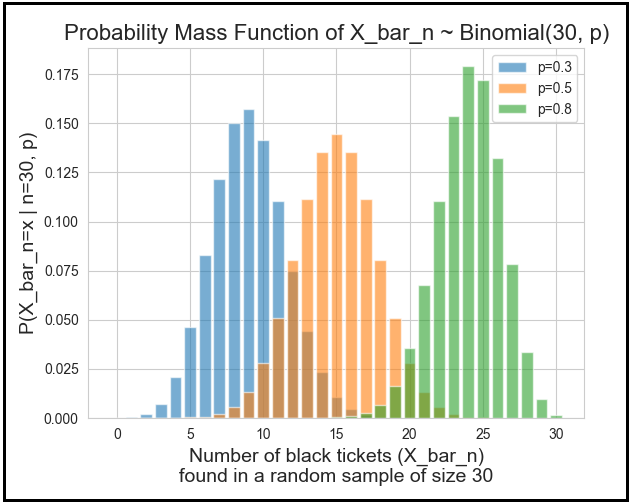
P(X_bar_n = x) is the marginal probability of X_bar_n=x. It is the probability of X_bar_n taking the value x assuming that p takes each one of the possible values in the range [0,1]. Thus, P(X_bar_n = x) is the following infinite sum:
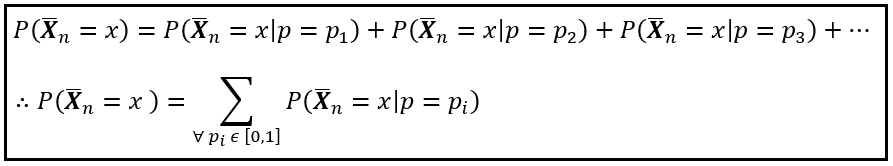
The summation runs over all p_i in the interval [0, 1]. Since p is continuous over [0,1], we can convert the discrete summation into a smooth integration over [0,1]. While we are at it, we’ll also plug in the formula for the binomial probability P(X_bar_n=x | n,p):

Let’s put back all three terms into Bayes’s formula. And yes, I am going to call it Bayes’s formula. Even though Laplace’s approach to inverse probability was starkly different from Bayes’s, history suggests that Bayes got the idea in his head first. So there.
At any rate, here’s what we get from substituting P(X_bar_n=x|p), P(p), and P(X_bar_n = x) with their corresponding formulae or value:

Since x is a known quantity (x is the value of the observed sample mean X_bar_n), the R.H.S. is, in essence, a function of p that is normalized by the definite integral in the denominator. To compute the definite integral in the denominator we use a technique that makes use of a rather interesting and useful function called the Beta function. For any two positive numbers a and b, the Beta function B(a, b) is defined as follows:
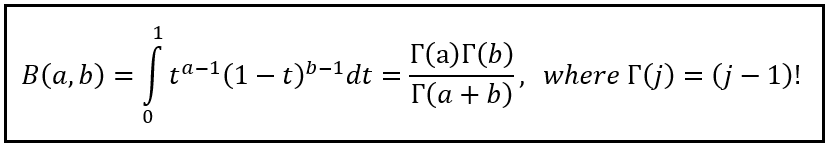
The symbol Γ is the Greek alphabet capital gamma. Γ(j) is the gamma function which in its general form is the extension of the Factorial function to complex numbers. In our case, we’ll stick to positive integers for which Γ(j) is defined simply as (j — 1)! Notice how the gamma function lets you calculate the continuous integral on the L.H.S. using a set of three discrete factorials (a — 1)!, (b — 1)!, and (a + b — 1)!
Before we move ahead, let’s recall that our aim is to calculate the definite integral in the denominator on the R.H.S. of the following equation:
In the Beta function, if you set a = x + 1 and b = n — x + 1, you will transform Beta(a, b) into the definite integral of interest as follows:
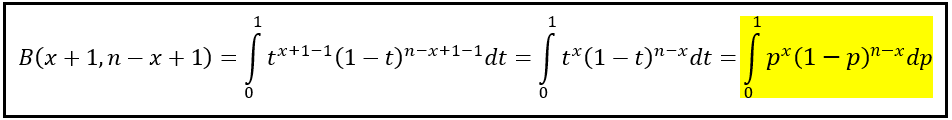
In summary, using the Beta function Laplace’s formula for inverse probability can be expressed as follows:

Today, most statistics libraries contain routines to compute B(x+1, n — x+1). So you will never ever have to put yourself through the sort of misery that Laplace or De Moivre, or for that matter Jacob Bernoulli had to put themselves through to arrive at their results.
Now let’s get back to the census example.
Recall that the recorded number of male births in Paris was 251527, and the sample size was 251527 + 241945 = 493472.
x = 251527, and n = 493472
If you plug in x and n in the above formula and use your favorite library to calculate the probability density P(p | X_bar_n = x, n) for different values of p in the interval [0, 1], you’ll get the following plot. I used Python and scipy, specifically scipy.stats.binom and scipy.special.betainc.
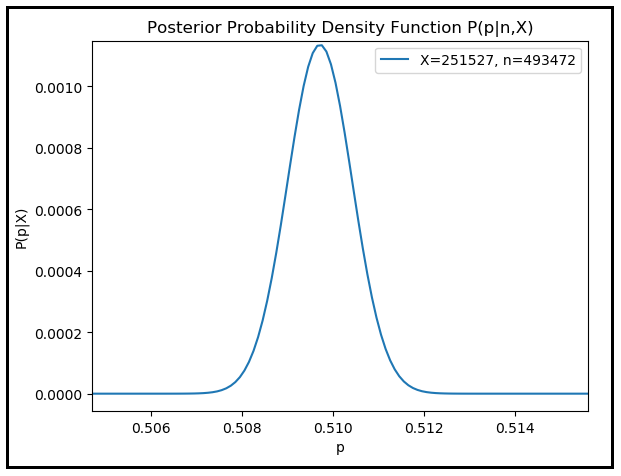
As expected, the posterior probability density peaks when p is 251527/493472 = 0.50971 corresponding to the observed count of 251527 male births.
Here finally we have the means to answer the question Jacob Bernoulli posed more than three centuries ago:
How do you estimate the real (unknown) fraction (of black tickets) given only the observed fraction of (black tickets) in a single random sample?
In other words:
What is the real probability (density) p conditioned upon the sample value X_bar_n = x?
Or in general terms:
What is the probability (density) of the population mean (or sum) given a single observed sample mean (or sum)?
As mentioned earlier, since p is continuous over [0, 1], what’s really useful to us is the probability of the real ratio p lying between two specified bounds p_low and p_high, i.e. the following probability:

The above probability can be split into two cumulative probabilities:
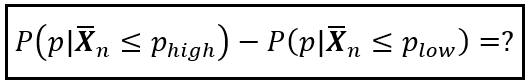
Laplace asked the following question:
What is the probability that the true ratio of boys to total births in Paris was greater than 50%? i.e. what is the value of P(p | X_bar_n > 0.5)?
P(p | X_bar_n > 0.5) = 1 — P(p | X_bar_n ≤ 0.5).
P(p | X_bar_n ≤ 0.5) can be calculated as follows:

To calculate P(p|X_bar_n ≤ 0.5), we need to use a modified version of the formula for inverse probability which uses the incomplete Beta function B(x; a, b) as follows:
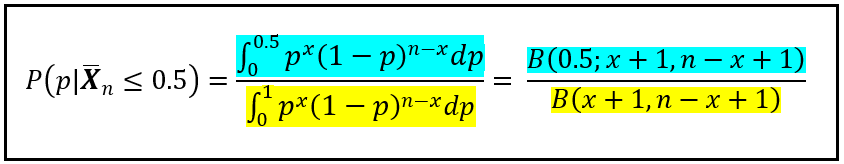
As before, we set a = x + 1 and b = n — x + 1. Unlike B(a,b) which can be computed a ratio of gamma functions, the incomplete Beta function B(x; a, b) has no closed form. But stats packages such asscipy.special.betainc will happily calculate its value for you using numerical techniques.
As before, we set x = 251527 boys, and sample size n = 493472 total births.
And we calculate a and b as follows:
a = (x + 1) = 251528 and b = (n — x + 1) = 241946
And using a stats package we calculate:
B(0.5, a,b) = B(0.5, 251527 + 1, 493472 — 251528 + 1), and
B(a, 5) = B(251527 + 1, 493472–251528 + 1).

P(p|X_bar_n ≤ 0.5) turns out to be vanishingly small.
Thus, P(p|X_bar_n > 0.5) = 1 — P(p|X_bar_n ≤ 0.5) is basically 1.0.
Laplace concluded that the true ratio of male births to total births in Paris during 1745 to 1770 was definitely greater than 50%. It was an arrestingly important piece of inference that may well have influenced public policy in 18th century France.
Isn’t inverse probability just smashingly awesome!
Before moving ahead, let’s review what Laplace’s work on inverse probability gave us.
If X_bar_n ~ Binomial(n,p), Laplace gave us a way to calculate the probability density distribution P(p | X_bar_n = x) of the unknown population mean p given a single observation about the sample mean X_bar_n/n as follows:
That also paved a direct path to calculating the probability of the unknown mean lying in a closed interval [p_low, p_high] of our choosing:

Laplace described his work on inverse probability in his mémoires published from 1774 through 1781. By 1781, the calculation of inverse probability, a topic that had bedeviled mathematicians for more than a century was firm solved, albeit for binomial random variables.
Non-binomial samples and the discovery of the Central Limit Theorem
No exposition on Laplace’s work on probability will be complete without at least touching upon his work on the Central Limit Theorem.
Laplace’s work on inverse probability was directly applicable to binomial random variables. Surely his fertile mind must have perceived the need to generalize his results to non-binomial samples.
Specifically, and in modern notation, suppose X_1, X_2,…,X_n are n i.i.d. random variables that form a random sample of size n. Let X_bar_n be their sum. This time, we’ll assume that X_bar_n has some unknown probability distribution. Let μ be the mean and σ² be the variance of the population from which the random sample is drawn. As in the case of the binomial setting, both μ and σ² are unknown. With all that in context, the problem statement is as follows:
Find a closed interval [μ_low, μ_high] such that μ will lie in this interval with a specified level of certainty (1 — α) where 0 ≤ α ≤ 1. In modern terms, (1 — α) is the confidence level and [μ_low, μ_high] (1 — α)100% confidence interval for the unknown mean μ.
In equation terms, what you want to have are the values μ_low and μ_high such that:

We’ll apply the following two crucial operations on the above equation:
- We’ll split the inequality on the L.H.S. into a difference of two probabilities P(μ|X_bar_n ≤ μ_high) and P(μ|X_bar_n ≤ μ_low), and
- On the R.H.S., we’ll express (1 — α) as: (1 — α/2) — (α/2).

Next, we pair up the blue term on the L.H.S. with the blue term on the R.H.S., and ditto for the yellow terms. Doing us yields the formulae for P(μ|X_bar_n ≤ μ_high) and P(μ|X_bar_n ≤ μ_low) as follows:
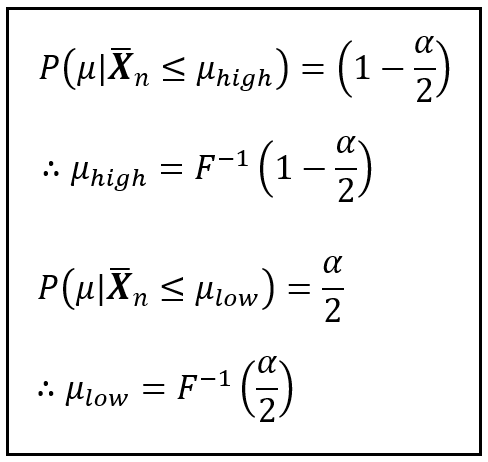
In the above formulae, F(x) is the notation for the Cumulative Distribution function (CDF) of X.
F(.) to the power ( — 1) is the inverse CDF (not to be confused with inverse probability). The meaning of inverse CDF is quite simple. Suppose P(X=x) is the Probability Density Function (PDF) of a continuous random variable X. If X is discrete, P(X=x) is the Probability Mass Function (PMF) of X. Then P(X ≤ x) = F(X=x) is the Cumulative Density Function (CDF) of X. F(X=x) returns the area under the curve of the PDF (or PMF) from negative ∞ to x. The inverse CDF is literally the inverse of F(X=x). The inverse CDF takes as a parameter the area under the curve of the PDF or PMF of X from negative ∞ to x, and it returns the x corresponding to this area. That’s all there is to the inverse CDF.
Let’s illustrate the use of the inverse CDF when X has a log-normal distribution. X is log-normally distributed if ln(X) is normally distributed. Let’s assume that ln(X) is normally distributed with a mean of 0 and variance of 0.5². Then the log-normal PDF of X looks like this:
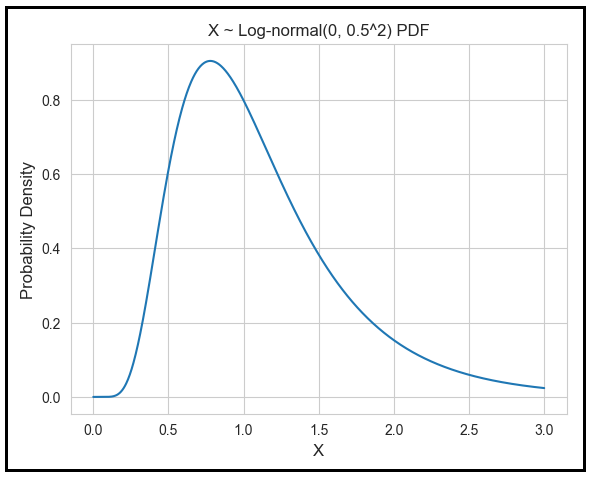
Let μ be the mean of X. Suppose you wish to find [μ_low, μ_high] such that the there is a 95% chance that the mean of X will lie in this interval. We set α = 0.05.
P(μ_low ≤ μ ≤ μ_high) = (1 — 0.05).
P(μ_low ≤ μ ≤ u_high) = (1–0.05) can be split into two terms as follows:
P(μ ≤ μ_high) — P(μ ≤ μ_low) = (1 — 0.025) — (0.025)
You’d want to find a μ_low and a μ_high such that:
P(μ ≤ μ_low) = F(μ_low) = 0.025, and
P(μ ≤ μ_high) = F(μ_high) = (1 — 0.025)
That is, you’d want to find a μ_low such that the area under the PDF of X from negative ∞ to μ_low is 0.025. This area is the blue region in the figure below. Since we know the PDF of X, we can find the corresponding μ_low using any Statistics package. μ_low is 0.38. And you’d also want to find a μ_high such that the area under the curve of the PDF of X from negative ∞ to μ_high is (1–0.025). This area is the blue region in the figure below and the corresponding μ_high is 2.66.

Thus, if X is log-normally distributed with parameters 0 and 0.05², there is a 95% chance that the mean of X will lie in the interval [0.38, 2.66].
In the above example, we could easily find the inverse CDFs for 0.025 and (1–0.025) because we knew the CDF of X. We knew the CDF of X because we assumed a certain PDF for X. We assumed that X was log-normally distributed.
And here we come to a crucial point. In real life, never will you know the probability distribution of X. Sometimes you can guess what distribution family X belongs to such as Poisson, Normal, Exponential, Negative Binomial etc. and you can approximate the PDF or PMF by estimating the parameters (i.e. usually the mean, and variance) of the distribution family. But if you don’t know the distribution and you cannot make a reasonable guess, you are truly stuck. And this is exactly when the Central Limit Theorem will come to your rescue.
The Central Limit Theorem says that if X happens to be the mean of your random sample, then the standardized X (I’ll explain what that is in a minute) converges in distribution to the standard normal random variable N(0, 1). The standard normal variable N(0, 1) is a random variable that has a normal distribution with a mean of 0 and a variance of 1. Convergence in distribution means that the CDF of the standardized X will become identical to the CDF of N(0, 1) as the sample size approaches infinity.
The CDF of N(0, 1) is usually represented by the symbol Φ, spelled as “Phi”.
If μ and σ² are respectively the unknown mean and variance of the population from which you drew the random sample, then the standardized X is the following random variable Z:

The complete statement of the Central Limit Theorem expressed in modern notation is as follows:
Let X_1, X_2, X_3,…,X_n be n independent, and identically distributed random variables which together form a random sample of size n. Let μ and σ² be the unknown mean and variance of the underlying population from which this random sample is drawn. We assume that the population is infinitely large or at least “extremely large”. Let X_bar_n be the sample mean. As the sample size n approaches infinity, the standardized X_bar_n converges in distribution to N(0, 1). The following figure illustrates the behavior of the CLT using mathematical notation:

At some point during the 3 decades that followed his 1774 paper on inverse probability, Laplace went to work on the Central Limit Theorem. During Laplace’s era, the CLT wasn’t called by that name. Neither did Laplace’s treatment of it resemble the modern form in which it’s expressed. But the ideas and insights into the CLT’s behavior shine out of Laplace’s work with the same brilliant clarity as in its modern form.
Laplace published his work on the CLT first in a mémoir in 1810. But his treatment of CLT in the 1812 edition of his book Théorie analytique des probabilités (Analytic theory of probabilities) is widely considered as the definitive source on the topic.
In his 1812 book Théorie analytique and in what may be the custom of his times or simply a way to keep up the charm offensive, Laplace made an overtly obsequious dedication of his work to Napoleon Bonaparte — the then reigning emperor of France:
To Napoleon-the-great
…
…
Signed:
The very humble and very obedient servant and faithful subject
LAPLACE

But in 1812–1813, Napoleon was either busy invading Russia or reeling from the aftermath of his misjudged fiasco. At any rate, Laplace’s landmark achievement along with its full-throated dedication may have slipped the great Emperor’s attention.

{kind=link}
By April 1814, Napoleon was packing his suitcase for an exile to Elba. Meanwhile in Paris, Laplace (or what is more likely, his publisher) wisely decided to publish the 1814 edition of Théorie analytique des probabilités minus the dedication to the great, now deposed, Emperor.
Let’s revisit our problem of finding an interval [μ_low, μ_high] such that there is a (1 — α)100% chance that the unknown population mean μ will lie in this interval. In other words, we want to calculate the (1 — α)100% confidence interval for the population mean. Remember that we have stopped assuming any particular distributional shape for the PDF of μ.
Without Laplace’s discovery of the Central Limit Theorem, this problem would have been difficult to solve and any solution to it, susceptible to all kinds of errors of approximation. But the CLT sweeps away all the difficulty, making the solution as easy as a walk in the park.
Let’s see how to do it. Here’s our problem statement. For a specified α, we wish to find a μ_low, and μ_high such that the following probability holds true:

Without loss of generality (and isn’t that a terrifically useful phrase), let’s recast our problem statement to use the standardized sample mean Z_n. We would be seeking two bounds on Z_n, namely z_low and z_high such that the following probability holds true:
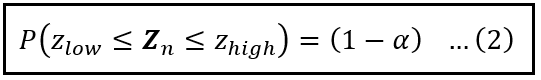
As before, we’ll split Eq. (2) as follows:

As per the CLT, as n becomes very large, the CDF of Z_n approaches that of N(0, 1). Hence the probabilities on the L.H.S. can be replaced by the CDF of N(0,1) as follows:

Setting Φ(z_high) = (1 — α)/2 and Φ(z_low) = α/2 gives us a way to calculate z_high and z_low using the inverses of Φ(z_high) and Φ(z_low) as follows:
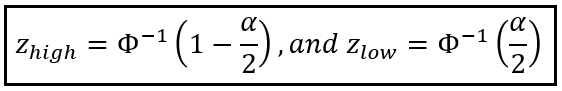
Since the standard normal distribution is symmetrical around the Y-axis, z_low is simply the negative of z_high. Thus:

The figure below illustrates the symmetry of the situation when α = 0.05, α/2 = 0.025, and (1 — α/2) = 0.975:

Let’s substitute z_low and z_high in Eq. (2) with the corresponding formulae expressed in terms of Φ and α:

We know that Z_n is the standardized X_bar_n. So let’s substitute Z_n with the standardized X_bar_n:
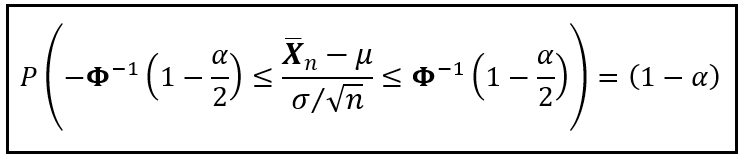
Some simplification in the central term will help us isolate the unknown mean μ as follows:

Which gives us the following formulae for μ_low and μ_high:

To use these formulae you need to know the confidence level α, the sample size n, the sample mean X_bar_n, and the population standard deviation σ. You would know the first three quantities. But you would not know σ. However, it can be shown that the sample standard deviation S (after the degrees-of-freedom correction) is a consistent, unbiased estimator of the population standard deviation σ. Hence, you may use S in place of σ and still get a consistent, unbiased estimate for μ_low and μ_high:

Let’s use these formulae in an example.
Suppose you wish to estimate the average speed of your broadband connection. To do so, you take speed readings at 25 different random times of the day in a 24 hour period and you get the following values in Mbps:

The sample mean X_bar_n = 398.81598 Mbps.
The sample variance S² is:
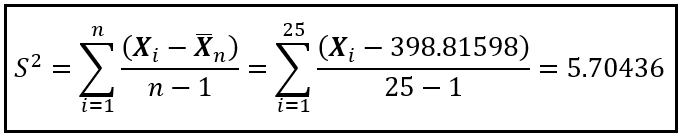
Since X_1 through X_n (the 25 speed test readings) are i.i.d. random variables, the Weak Law of Large Numbers governs the behavior of the sample mean X_bar_n. Specifically:
The sample mean X_bar_n = 398.81598 Mbps is a consistent, unbiased estimator of the unknown population mean μ.
But how accurate an estimate of μ is the observed X_bar_n? You can test its accuracy by computing a 95% confidence interval for μ given the observed X_bar_n = 398.81598 Mbps.
To do that, you set α = 0.05. The inverse of Φ(1–0.05/2) is 1.96. You know that X_bar_n = 398.81598, S = 2.38838, and n = 25. So you have everything you need to calculate μ_low, μ_high as follows:

Your calculations are telling you that there is a 95% chance that the real mean broadband speed will lie in the interval [397.87974 Mbps, 399.75222 Mbps] conditioned upon your observed sample mean of 398.81598 Mbps.
Epilogue
In 1812 (or 1810 depending on your viewpoint), with his discovery of the Central Limit Theorem, Laplace plugged in the final missing piece that was deluding generations of scientists since Jacob Bernoulli’s quantification of the Weak Law Of Large numbers in 1689. In the decades following Bernoulli’s discovery of the WLLN, Abraham De Moivre showed how to approximate the factorial and in the process, introduced the world to the normal curve. Laplace was well aware of De Moivre’s work and he built extensively upon it in his own work on both inverse probability and the Central Limit Theorem.
With his work on inverse probability and the CLT, what Laplace gave us was the mathematical apparatus as well as a mechanism to calculate the posterior probability of the population mean (or sum) given a single observation of the sample mean (or sum).
The subsequent decades, especially the period 1850 to 1940, saw an explosion of interest in the CLT with so many researchers coming up with proofs, extensions, and applications for the CLT, that it would take many volumes to do justice to their contributions. Indeed, many tomes have been written on the subject! In the 1800s, Siméon Denis Poisson (1781–1840) and Augustin-Louis Cauchy (1789–1857) devised proofs for the CLT in restricted settings. In 1887, the Russian mathematician Pafnuty Lvovich Chebyshev (1821–1894) used moment generating functions (what he called “Bieneyme’s method of moments” to give due credit of the technique to his French mathematician friend, the reticent and brilliant Irénée-Jules Bienaymé”) to attempt a proof of the CLT. Chebyshev’s proof was incomplete but it extricated the CLT out of the narrow alleyway of a binomial thought experiment and made it applicable to a broad set of random variables. Around the turn of the 19th century, Chebyshev’s students Andrey Andreyevich Markov (1856–1922) and later on Aleksandr Mikhailovich Lyapunov (1857–1918) provided the first set of rigorous proofs for the CLT. Lyapunov also extended the CLT’s applicability to random variables that are not necessarily identically distributed, and so did the Finnish mathematician Jarl Waldemar Lindeberg (1876–1932) in what came to be known as the the Lypunov CLT and the Lindeberg CLT. In the 20th century, CLT’s applicability was further extended to dependent random variables which immediately made it applicable to inference in time series regression models which work upon correlated observations.
It’s hard to find a pair of discoveries in Statistics that are as fundamental, as intertwined with each other, as heavily researched, and with as rich a historical backdrop as the Law of Large Numbers and the Central Limit Theorem. And as with many great discoveries, it’s also easy to forget that the forms of the LLN and the CLT that we use today with such effortless ease are the evolutionary outcome of countless hours of toil from dozens of scientists across literally several centuries.
So next time you apply the LLN or the CLT to a problem, think of the rich history of thought you are carrying forward into your work. You just might look at your solution with a whole new level of admiration.
References and Copyrights
Books and Papers
Bernoulli, J(akob)., On the Law of Large Numbers, Part Four of Ars Conjectandi (English translation), translated by Oscar Sheynin, Berlin: NG Verlag, (2005) [1713], ISBN 978–3–938417–14–0, PDF download
Seneta, E. A Tricentenary history of the Law of Large Numbers. Bernoulli 19 (4) 1088–1121, September 2013. https://doi.org/10.3150/12-BEJSP12 PDF Download
Fischer, H., A History of the Central Limit Theorem. From Classical to Modern Probability Theory, Springer Science & Business Media, Oct-2010
Shafer, G., The significance of Jacob Bernoulli’s Ars Conjectandi for the philosophy of probability today, Journal of Econometrics, Volume 75, Issue 1, pp. 15–32, 1996, ISSN 0304–4076, https://doi.org/10.1016/0304-4076(95)01766-6.
Polasek, W., The Bernoullis and the origin of probability theory: Looking back after 300 years. Reson 5, pp. 26–42, 2000, https://doi.org/10.1007/BF02837935 PDF download
Stigler, S. M., The History of Statistics: The Measurement of Uncertainty Before 1900, Harvard University Press, Sept-1986
Barnard, G. A., and Bayes, T., Studies in the History of Probability and Statistics: IX. Thomas Bayes’s Essay Towards Solving a Problem in the Doctrine of Chances. Biometrika 45, no. 3/4, pp. 293–315, 1958, https://doi.org/10.2307/2333180. PDF download
Images and Videos
All images and videos in this article are copyright Sachin Date under CC-BY-NC-SA, unless a different source and copyright are mentioned underneath the image or video.
Thanks for reading! If you liked this article, please follow me to receive more content on statistics and statistical modeling.
Pierre-Simon Laplace, Inverse Probability, and the Central Limit Theorem was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Pierre-Simon Laplace, Inverse Probability, and the Central Limit Theorem
Go Here to Read this Fast! Pierre-Simon Laplace, Inverse Probability, and the Central Limit Theorem