

Phi-3 and the Beginning of Highly Performant iPhone LLMs
This blog post will go into the findings of the Phi-3 paper, as well as some of the implications of models like Phi-3 being released
Readers of my prior work may remember when I covered “Textbooks are all you need”, a paper by Microsoft showing how quality data can have an outsize impact on model performance. The findings there directly refuted the belief that models had to be enormous to be capable. The researchers behind that paper have continued their work and published something I find incredibly exciting.
The title of this paper explains perhaps the biggest finding: “Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone”.
Let’s dive into what the authors changed from the Phi-2 model, how they trained it, and how it works on your iPhone.
Key Terminology
There are a few key concepts to know before we dive into the architecture. If you know these already, feel free to skip to the next section.
A model’s parameters refer to the number of weights and biases that the model learns during training. If you have 1 billion parameters, then you have 1 billion weights and biases that determine the model’s performance. The more parameters you have the more complex your neural network can be. A head refers to the number of key, value, and query vectors the self-attention mechanism in a Transformer has. Layers refers to the number of neural segments that exist within the neural network of the Transformer, with hidden dimensions being the number of neurons within a typical hidden layer.
Tokenizer is the software piece that will convert your input text into an embedding that the transformer will then work with. Vocabulary size refers to the number of unique tokens that the model is trained on. The block structure of a transformer is how we refer to the combination of layers, heads, activation functions, tokenizer and layer normalizations that would be chosen for a specific model.

Multi-Head Checkpoints”
Grouped-Query Attention (GQA) is a way that we optimize multi-head attention to reduce the computational overhead during training and inference. As you can see from the image below, GQA takes the middle-ground approach — rather than pairing 1 value and 1 key to 1 query, we take a 1:1:M approach, with the many being smaller than the entire body of queries. This is done to still get the training cost benefits from Multi-Query Attention (MQA), while minimizing the performance degradation that we see follow that.
Phi 3 Architecture
Let’s begin with the architecture behind this model. The researchers released 3 different decoder only models, phi-3-mini, phi-3-small, and phi-3-medium, with different hyperparameters for each.
- phi-3-mini
– 3.8 billion parameters
– 32 heads
– 32 layers
– 3072 hidden dimensions
– 4k token default context length
– 32064 vocabulary size
– weights stored as bfloat16
– trained on 3.3 Trillion Tokens - phi-3-small
– 7 billion parameters
– 32 heads
– 32 layers
– 4096 hidden dimensions
– 8k token default context length
– 100352 vocabulary size
– weights stored as bfloat16
– trained on 4.8 Trillion Tokens - phi-3-medium
– 14 billion parameters
– 40 heads
– 40 layers
– 3072 hidden dimensions
– trained on 4.8 Trillion Tokens
Going into some of the differences here, the phi-3-mini model was trained using typical mutli-head attention. While not called out in the paper, my suspicion is that because the model is roughly half the size of the other two, the training costs associated with multi-head were not objectionable. Naturally when they scaled up for phi-3-small, they went with grouped query attention, with 4 queries connected to 1 key.
Moreover, they kept phi-3-mini’s block structure as close to the LLaMa-2 structure as they could. The goal here was to allow the open-source community to continue their research on LLaMa-2 with Phi-3. This makes sense as a way to further understand the power of that block structure.
However, phi-3-small did NOT use LLaMa’s block structure, opting to use the tiktoken tokenizer, with alternate layers of dense attention and a new blocksparse attention. Additionally, they added in 10% multilingual data to the training dataset for these models.
Training and Data Optimal Mixes
Similar to Phi-2, the researchers invested majorly in quality data. They used the similar “educational value” paradigm they had used before when generating data to train the model on, opting to use significantly more data than last time. They created their data in 2 phases.
Phase-1 involved finding web data that they found was of high “educational value” to the user. The goal here is to give general knowledge to the model. Phase-2 then takes a subset of the Phase-1 data and generates data that would teach the model how to logically reason or attain specific skills.
The challenge here was to ensure the mix of data from each corpus was appropriate for the scale of the model being trained (ie phi-3-small vs phi-3-mini). This is the idea behind a “data optimal” regime, where the data you are giving to the LLM to train with gives it the best ability for its block structure. Put differently, if you think that data is a key distinguisher for training a good LLM, then finding the right combination of skills to show the model via your data can be just as key as finding good data. The researchers highlighted that they wanted the model to have stronger reasoning than knowledge abilities, resulting in their choosing more data from the Phase-2 corpus than from the Phase-1.
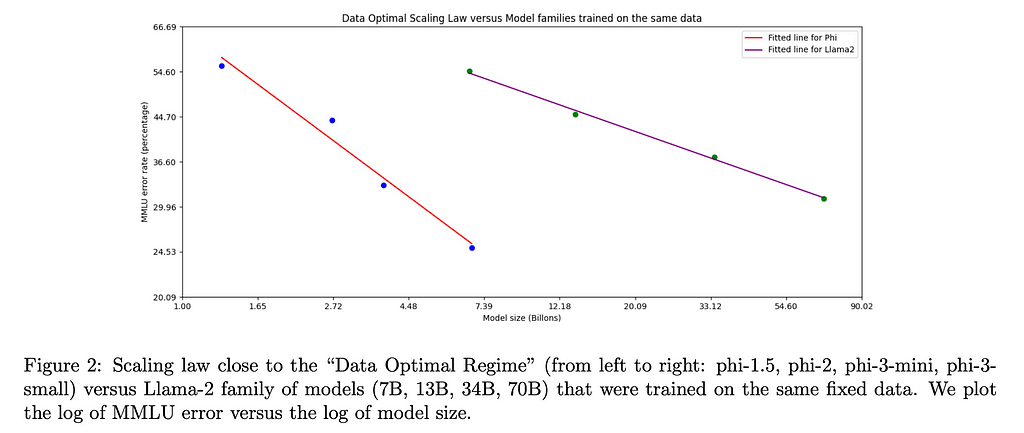
Interestingly, when they were training phi-3-medium with roughly the same data mixture as they trained phi-3-small, they noticed that the improvements from 7B parameters to 14B were far more limited than from 3.8B to 7B. The authors suspect this is not a limitation of the block structure, but instead of the data mixture they used to train phi-3-medium.
Post-Training
The team used both Supervised Fine Tuning (SFT) and Direct Preference Optimization (DPO) to improve the model post-training. Those interested in a deep dive on DPO can check out my blog post here. Supervised Fine Tuning is a type of transfer learning where we use a custom dataset to improve the LLM’s capabilities on that dataset. The authors used SFT to improve the model’s ability across diverse domains like math, coding, reasoning, and safety. They then used DPO for their chat optimization to guide it away from responses they wanted to avoid and towards ideal responses.
It’s in this stage that the authors expanded the context window of phi-3-mini from 4k tokens to 128k tokens. The methodology they used to do this is called Long Rope. The authors claim that the performance is consistent between the 2 context types, which is a big deal given the enormous increase in context length. If there is sufficient interest, I will do a separate blog post on the findings within that paper.
Quantization for Phone Usage
Even though these models are small, to get these models to run on your phone still requires some further minimization. Typically the weights for a LLM is stored as float; for example, Phi-3’s original weights were bfloat16, meaning each weight takes up 16 bits in memory. While 16 bits may seem trivial, when you take into account there are on the order of 10⁹ parameters in the model, you realize how quickly each additional bit adds up.
To get around this, the authors condensed the weights from 16 bits to 4 bits. The basic idea is to reduce the number of bits required to store each number. For a conceptual example, the number 2.71828 could be condensed to 2.72. While this is a lossy operation, it still captures a good portion of the information while taking significantly less storage.

The authors ran the quantized piece on an iPhone with the A16 chip and found it could generate up to 12 tokens per second. For comparison, an M1 MacBook running LLaMa-2 Quantized 4 bit runs at roughly 107 tokens per second. The fastest token generation I’ve seen (Groq) generated tokens at a rate of 853.35 Tokens per second. Given this is just the beginning, it’s remarkable how fast we are able to see tokens generated on an iPhone with this model. It seems likely the speed of inference will only increase.
Pairing Phi-3 with Search
One limitation with a small model is it has fewer places it can store information within its network. As a result, we see that Phi-3 does not perform as well as models like LLaMa-2 on tasks that require wide scopes of knowledge.
The authors suggest that by pairing Phi-3 with a search engine the model’s abilities will significantly improve. If this is the case, that makes me think Retrieval Augmented Generation (RAG) is likely here to stay, becoming a critical part of helping small models be just as performant as larger ones.

Conclusion
In closing, we are seeing the beginning of highly performant smaller models. While training these models still relies to a large degree on performant hardware, inferencing them is increasingly becoming democratized. This introduces a few interesting phenomena.
First, models that can run locally can be almost fully private, allowing users to give these LLMs data that they otherwise may not feel comfortable sending over the internet. This opens the door to more use cases.
Second, these models will drive mobile hardware to be even more performant. As a consequence, I would expect to see more Systems on Chips (SoC) on high-end smartphones, especially SoCs with shared memory between CPUs and GPUs to maximize the speed of inference. Moreover, the importance of having quality interfaces with this hardware will be paramount. Libraries like MLX for Apple Silicon will likely be required for any new hardware entrants in the consumer hardware space.
Third, as this paper shows that high quality data can in many ways outcompete more network complexity in an LLM, the race to not just find but generate high quality data will only increase.
It is an exciting time to be building.
[1] Abdin, M., et al. “Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone” (2024), arXiv
[2] Ding, Y., et al. “LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens” (2024), arXiv
[3] Gerganov, G., et al. “Performance of llama.cpp on Apple Silicon M-series” (2023), GitHub
[4] Ainslie, J., et al. “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints” (2023), arXiv
Phi-3 and the Beginning of Highly Performant iPhone Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Phi-3 and the Beginning of Highly Performant iPhone Models
Go Here to Read this Fast! Phi-3 and the Beginning of Highly Performant iPhone Models