

Utilizing Sigma rules for anomaly detection in cybersecurity logs: A study on performance optimization
One of the roles of the Canadian Centre for Cyber Security (CCCS) is to detect anomalies and issue mitigations as quickly as possible.
While putting our Sigma rule detections into production, we made an interesting observation in our Spark streaming application. Running a single large SQL statement expressing 1000 Sigma detection rules was slower than running five separate queries, each applying 200 Sigma rules. This was surprising, as running five queries forces Spark to read the source data five times rather than once. For further details, please refer to our series of articles:
Anomaly Detection using Sigma Rules (Part 1): Leveraging Spark SQL Streaming
Given the vast amount of telemetry data and detection rules we need to execute, every gain in performance yields significant cost savings. Therefore, we decided to investigate this peculiar observation, aiming to explain it and potentially discover additional opportunities to improve performance. We learned a few things along the way and wanted to share them with the broader community.
Introduction
Our hunch was that we were reaching a limit in Spark’s code generation. So, a little background on this topic is required. In 2014, Spark introduced code generation to evaluate expressions of the form (id > 1 and id > 2) and (id < 1000 or (id + id) = 12). This article from Databricks explains it very well: Exciting Performance Improvements on the Horizon for Spark SQL
Two years later, Spark introduced Whole-Stage Code Generation. This optimization merges multiple operators together into a single Java function. Like expression code generation, Whole-Stage Code Generation eliminates virtual function calls and leverages CPU registers for intermediate data. However, rather than being at the expression level, it is applied at the operator level. Operators are the nodes in an execution plan. To find out more, read Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop
To summarize these articles, let’s generate the plan for this simple query:
explain codegen
select
id,
(id > 1 and id > 2) and (id < 1000 or (id + id) = 12) as test
from
range(0, 10000, 1, 32)
In this simple query, we are using two operators: Range to generate rows and Select to perform a projection. We see these operators in the query’s physical plan. Notice the asterisk (*) beside the nodes and their associated [codegen id : 1]. This indicates that these two operators were merged into a single Java function using Whole-Stage Code Generation.
|== Physical Plan ==
* Project (2)
+- * Range (1)
(1) Range [codegen id : 1]
Output [1]: [id#36167L]
Arguments: Range (0, 10000, step=1, splits=Some(32))
(2) Project [codegen id : 1]
Output [2]: [id#36167L, (((id#36167L > 1) AND (id#36167L > 2)) AND ((id#36167L < 1000) OR ((id#36167L + id#36167L) = 12))) AS test#36161]
Input [1]: [id#36167L]
The generated code clearly shows the two operators being merged.
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage1(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=1
/* 006 */ final class GeneratedIteratorForCodegenStage1 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private boolean range_initRange_0;
/* 010 */ private long range_nextIndex_0;
/* 011 */ private TaskContext range_taskContext_0;
/* 012 */ private InputMetrics range_inputMetrics_0;
/* 013 */ private long range_batchEnd_0;
/* 014 */ private long range_numElementsTodo_0;
/* 015 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[] range_mutableStateArray_0 = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[3];
/* 016 */
/* 017 */ public GeneratedIteratorForCodegenStage1(Object[] references) {
/* 018 */ this.references = references;
/* 019 */ }
/* 020 */
/* 021 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 022 */ partitionIndex = index;
/* 023 */ this.inputs = inputs;
/* 024 */
/* 025 */ range_taskContext_0 = TaskContext.get();
/* 026 */ range_inputMetrics_0 = range_taskContext_0.taskMetrics().inputMetrics();
/* 027 */ range_mutableStateArray_0[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 028 */ range_mutableStateArray_0[1] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 029 */ range_mutableStateArray_0[2] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(2, 0);
/* 030 */
/* 031 */ }
/* 032 */
/* 033 */ private void project_doConsume_0(long project_expr_0_0) throws java.io.IOException {
/* 034 */ // common sub-expressions
/* 035 */
/* 036 */ boolean project_value_4 = false;
/* 037 */ project_value_4 = project_expr_0_0 > 1L;
/* 038 */ boolean project_value_3 = false;
/* 039 */
/* 040 */ if (project_value_4) {
/* 041 */ boolean project_value_7 = false;
/* 042 */ project_value_7 = project_expr_0_0 > 2L;
/* 043 */ project_value_3 = project_value_7;
/* 044 */ }
/* 045 */ boolean project_value_2 = false;
/* 046 */
/* 047 */ if (project_value_3) {
/* 048 */ boolean project_value_11 = false;
/* 049 */ project_value_11 = project_expr_0_0 < 1000L;
/* 050 */ boolean project_value_10 = true;
/* 051 */
/* 052 */ if (!project_value_11) {
/* 053 */ long project_value_15 = -1L;
/* 054 */
/* 055 */ project_value_15 = project_expr_0_0 + project_expr_0_0;
/* 056 */
/* 057 */ boolean project_value_14 = false;
/* 058 */ project_value_14 = project_value_15 == 12L;
/* 059 */ project_value_10 = project_value_14;
/* 060 */ }
/* 061 */ project_value_2 = project_value_10;
/* 062 */ }
/* 063 */ range_mutableStateArray_0[2].reset();
/* 064 */
/* 065 */ range_mutableStateArray_0[2].write(0, project_expr_0_0);
/* 066 */
/* 067 */ range_mutableStateArray_0[2].write(1, project_value_2);
/* 068 */ append((range_mutableStateArray_0[2].getRow()));
/* 069 */
/* 070 */ }
/* 071 */
/* 072 */ private void initRange(int idx) {
/* 073 */ java.math.BigInteger index = java.math.BigInteger.valueOf(idx);
/* 074 */ java.math.BigInteger numSlice = java.math.BigInteger.valueOf(32L);
/* 075 */ java.math.BigInteger numElement = java.math.BigInteger.valueOf(10000L);
/* 076 */ java.math.BigInteger step = java.math.BigInteger.valueOf(1L);
/* 077 */ java.math.BigInteger start = java.math.BigInteger.valueOf(0L);
/* 078 */ long partitionEnd;
/* 079 */
/* 080 */ java.math.BigInteger st = index.multiply(numElement).divide(numSlice).multiply(step).add(start);
/* 081 */ if (st.compareTo(java.math.BigInteger.valueOf(Long.MAX_VALUE)) > 0) {
/* 082 */ range_nextIndex_0 = Long.MAX_VALUE;
/* 083 */ } else if (st.compareTo(java.math.BigInteger.valueOf(Long.MIN_VALUE)) < 0) {
/* 084 */ range_nextIndex_0 = Long.MIN_VALUE;
/* 085 */ } else {
/* 086 */ range_nextIndex_0 = st.longValue();
/* 087 */ }
/* 088 */ range_batchEnd_0 = range_nextIndex_0;
/* 089 */
/* 090 */ java.math.BigInteger end = index.add(java.math.BigInteger.ONE).multiply(numElement).divide(numSlice)
/* 091 */ .multiply(step).add(start);
/* 092 */ if (end.compareTo(java.math.BigInteger.valueOf(Long.MAX_VALUE)) > 0) {
/* 093 */ partitionEnd = Long.MAX_VALUE;
/* 094 */ } else if (end.compareTo(java.math.BigInteger.valueOf(Long.MIN_VALUE)) < 0) {
/* 095 */ partitionEnd = Long.MIN_VALUE;
/* 096 */ } else {
/* 097 */ partitionEnd = end.longValue();
/* 098 */ }
/* 099 */
/* 100 */ java.math.BigInteger startToEnd = java.math.BigInteger.valueOf(partitionEnd).subtract(
/* 101 */ java.math.BigInteger.valueOf(range_nextIndex_0));
/* 102 */ range_numElementsTodo_0 = startToEnd.divide(step).longValue();
/* 103 */ if (range_numElementsTodo_0 < 0) {
/* 104 */ range_numElementsTodo_0 = 0;
/* 105 */ } else if (startToEnd.remainder(step).compareTo(java.math.BigInteger.valueOf(0L)) != 0) {
/* 106 */ range_numElementsTodo_0++;
/* 107 */ }
/* 108 */ }
/* 109 */
/* 110 */ protected void processNext() throws java.io.IOException {
/* 111 */ // initialize Range
/* 112 */ if (!range_initRange_0) {
/* 113 */ range_initRange_0 = true;
/* 114 */ initRange(partitionIndex);
/* 115 */ }
/* 116 */
/* 117 */ while (true) {
/* 118 */ if (range_nextIndex_0 == range_batchEnd_0) {
/* 119 */ long range_nextBatchTodo_0;
/* 120 */ if (range_numElementsTodo_0 > 1000L) {
/* 121 */ range_nextBatchTodo_0 = 1000L;
/* 122 */ range_numElementsTodo_0 -= 1000L;
/* 123 */ } else {
/* 124 */ range_nextBatchTodo_0 = range_numElementsTodo_0;
/* 125 */ range_numElementsTodo_0 = 0;
/* 126 */ if (range_nextBatchTodo_0 == 0) break;
/* 127 */ }
/* 128 */ range_batchEnd_0 += range_nextBatchTodo_0 * 1L;
/* 129 */ }
/* 130 */
/* 131 */ int range_localEnd_0 = (int)((range_batchEnd_0 - range_nextIndex_0) / 1L);
/* 132 */ for (int range_localIdx_0 = 0; range_localIdx_0 < range_localEnd_0; range_localIdx_0++) {
/* 133 */ long range_value_0 = ((long)range_localIdx_0 * 1L) + range_nextIndex_0;
/* 134 */
/* 135 */ project_doConsume_0(range_value_0);
/* 136 */
/* 137 */ if (shouldStop()) {
/* 138 */ range_nextIndex_0 = range_value_0 + 1L;
/* 139 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(range_localIdx_0 + 1);
/* 140 */ range_inputMetrics_0.incRecordsRead(range_localIdx_0 + 1);
/* 141 */ return;
/* 142 */ }
/* 143 */
/* 144 */ }
/* 145 */ range_nextIndex_0 = range_batchEnd_0;
/* 146 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(range_localEnd_0);
/* 147 */ range_inputMetrics_0.incRecordsRead(range_localEnd_0);
/* 148 */ range_taskContext_0.killTaskIfInterrupted();
/* 149 */ }
/* 150 */ }
/* 151 */
/* 152 */ }
The project_doConsume_0 function contains the code to evaluate (id > 1 and id > 2) and (id < 1000 or (id + id) = 12). Notice how this code is generated to evaluate this specific expression. This is an illustration of expression code generation.
The whole class is an operator with a processNext method. This generated operator performs both the Projection and the Range operations. Inside the while loop at line 117, we see the code to produce rows and a specific call (not a virtual function) to project_doConsume_0. This illustrates what Whole-Stage Code Generation does.
Breaking Down the Performance
Now that we have a better understanding of Spark’s code generation, let’s try to explain why breaking a query doing 1000 Sigma rules into smaller ones performs better. Let’s consider a SQL statement that evaluates two Sigma rules. These rules are straightforward: Rule1 matches events with an Imagepath ending in ‘schtask.exe’, and Rule2 matches an Imagepath starting with ‘d:’.
select /* #3 */
Imagepath,
CommandLine,
PID,
map_keys(map_filter(results_map, (k,v) -> v = TRUE)) as matching_rules
from (
select /* #2 */
*,
map('rule1', rule1, 'rule2', rule2) as results_map
from (
select /* #1 */
*,
(lower_Imagepath like '%schtasks.exe') as rule1,
(lower_Imagepath like 'd:%') as rule2
from (
select
lower(PID) as lower_PID,
lower(CommandLine) as lower_CommandLine,
lower(Imagepath) as lower_Imagepath,
*
from (
select
uuid() as PID,
uuid() as CommandLine,
uuid() as Imagepath,
id
from
range(0, 10000, 1, 32)
)
)
)
)
The select labeled #1 performs the detections and stores the results in new columns named rule1 and rule2. Select #2 regroups these columns under a single results_map, and finally select #3 transforms the map into an array of matching rules. It uses map_filter to keep only the entries of rules that actually matched, and then map_keys is used to convert the map entries into a list of matching rule names.
Let’s print out the Spark execution plan for this query:
== Physical Plan ==
Project (4)
+- * Project (3)
+- * Project (2)
+- * Range (1)
...
(4) Project
Output [4]: [Imagepath#2, CommandLine#1, PID#0, map_keys(map_filter(map(rule1, EndsWith(lower_Imagepath#5, schtasks.exe), rule2, StartsWith(lower_Imagepath#5, d:)), lambdafunction(lambda v#12, lambda k#11, lambda v#12, false))) AS matching_rules#9]
Input [4]: [lower_Imagepath#5, PID#0, CommandLine#1, Imagepath#2]
Notice that node Project (4) is not code generated. Node 4 has a lambda function, does it prevent whole stage code generation? More on this later.
This query is not quite what we want. We would like to produce a table of events with a column indicating the rule that was matched. Something like this:
+--------------------+--------------------+--------------------+--------------+
| Imagepath| CommandLine| PID| matched_rule|
+--------------------+--------------------+--------------------+--------------+
|09401675-dc09-4d0...|6b8759ee-b55a-486...|44dbd1ec-b4e0-488...| rule1|
|e2b4a0fd-7b88-417...|46dd084d-f5b0-4d7...|60111cf8-069e-4b8...| rule1|
|1843ee7a-a908-400...|d1105cec-05ef-4ee...|6046509a-191d-432...| rule2|
+--------------------+--------------------+--------------------+--------------+
That’s easy enough. We just need to explode the matching_rules column.
select
Imagepath,
CommandLine,
PID,
matched_rule
from (
select
*,
explode(matching_rules) as matched_rule
from (
/* original statement */
)
)
This produces two additional operators: Generate (6) and Project (7). However, there is also a new Filter (3).
== Physical Plan ==
* Project (7)
+- * Generate (6)
+- Project (5)
+- * Project (4)
+- Filter (3)
+- * Project (2)
+- * Range (1)
...
(3) Filter
Input [3]: [PID#34, CommandLine#35, Imagepath#36]
Condition : (size(map_keys(map_filter(map(rule1, EndsWith(lower(Imagepath#36),
schtasks.exe), rule2, StartsWith(lower(Imagepath#36), d:)),
lambdafunction(lambda v#47, lambda k#46, lambda v#47, false))), true) > 0)
...
(6) Generate [codegen id : 3]
Input [4]: [PID#34, CommandLine#35, Imagepath#36, matching_rules#43]
Arguments: explode(matching_rules#43), [PID#34, CommandLine#35, Imagepath#36], false, [matched_rule#48]
(7) Project [codegen id : 3]
Output [4]: [Imagepath#36, CommandLine#35, PID#34, matched_rule#48]
Input [4]: [PID#34, CommandLine#35, Imagepath#36, matched_rule#48]
The explode function generates rows for every element in the array. When the array is empty, explode does not produce any rows, effectively filtering out rows where the array is empty.
Spark has an optimization rule that detects the explode function and produces this additional condition. The filter is an attempt by Spark to short-circuit processing as much as possible. The source code for this rule, named org.apache.spark.sql.catalyst.optimizer.InferFiltersFromGenerate, explains it like this:
Infers filters from Generate, such that rows that would have been removed by this Generate can be removed earlier — before joins and in data sources.
For more details on how Spark optimizes execution plans please refer to David Vrba’s article Mastering Query Plans in Spark 3.0
Another question arises: do we benefit from this additional filter? Notice this additional filter is not whole-stage code generated either, presumably because of the lambda function. Let’s try to express the same query but without using a lambda function.
Instead, we can put the rule results in a map, explode the map, and filter out the rows, thereby bypassing the need for map_filter.
select
Imagepath,
CommandLine,
PID,
matched_rule
from (
select
*
from (
select
*,
explode(results_map) as (matched_rule, matched_result)
from (
/* original statement */
)
)
where
matched_result = TRUE
)
The select #3 operation explodes the map into two new columns. The matched_rule column will hold the key, representing the rule name, while the matched_result column will contain the result of the detection test. To filter the rows, we simply keep only those with a positive matched_result.
The physical plan indicates that all nodes are whole-stage code generated into a single Java function, which is promising.
== Physical Plan ==
* Project (8)
+- * Filter (7)
+- * Generate (6)
+- * Project (5)
+- * Project (4)
+- * Filter (3)
+- * Project (2)
+- * Range (1)
Let’s conduct some tests to compare the performance of the query using map_filter and the one using explode then filter.
We ran these tests on a machine with 4 CPUs. We generated 1 million rows, each with 100 rules, and each rule evaluating 5 expressions. These tests were run 5 times.
On average
- map_filter took 42.6 seconds
- explode_then_filter took 51.2 seconds
So, map_filter is slightly faster even though it’s not using whole-stage code generation.
However, in our production query, we execute many more Sigma rules — a total of 1000 rules. This includes 29 regex expressions, 529 equals, 115 starts-with, 2352 ends-with, and 5838 contains expressions. Let’s test our query again, but this time with a slight increase in the number of expressions, using 7 instead of 5 per rule. Upon doing this, we encountered an error in our logs:
Caused by: org.codehaus.commons.compiler.InternalCompilerException: Code grows beyond 64 KB
We tried increasing spark.sql.codegen.maxFields and spark.sql.codegen.hugeMethodLimit, but fundamentally, Java classes have a function size limit of 64 KB. Additionally, the JVM JIT compiler limits itself to compiling functions smaller than 8 KB.
However, the query still runs fine because Spark falls back to the Volcano execution model for certain parts of the plan. WholeStageCodeGen is just an optimization after all.
Running the same test as before but with 7 expressions per rule rather than 5, explode_then_filter is much faster than map_filter.
- map_filter took 68.3 seconds
- explode_then_filter took 15.8 seconds
Increasing the number of expressions causes parts of the explode_then_filter to no longer be whole-stage code generated. In particular, the Filter operator introduced by the rule org.apache.spark.sql.catalyst.optimizer.InferFiltersFromGenerate is too big to be incorporated into whole-stage code generation. Let’s see what happens if we exclude the InferFiltersFromGenerate rule:
spark.sql("SET spark.sql.optimizer.excludedRules=org.apache.spark.sql.catalyst.optimizer.InferFiltersFromGenerate")
As expected, the physical plan of both queries no longer has an additional Filter operator.
== Physical Plan ==
* Project (6)
+- * Generate (5)
+- Project (4)
+- * Project (3)
+- * Project (2)
+- * Range (1)
== Physical Plan ==
* Project (7)
+- * Filter (6)
+- * Generate (5)
+- * Project (4)
+- * Project (3)
+- * Project (2)
+- * Range (1)
Removing the rule indeed had a significant impact on performance:
- map_filter took 22.49 seconds
- explode_then_filter took 4.08 seconds
Both queries benefited greatly from removing the rule. Given the improved performance, we decided to increase the number of Sigma rules to 500 and the complexity to 21 expressions:
Results:
- map_filter took 195.0 seconds
- explode_then_filter took 25.09 seconds
Despite the increased complexity, both queries still deliver pretty good performance, with explode_then_filter significantly outperforming map_filter.
It’s interesting to explore the different aspects of code generation employed by Spark. While we may not currently benefit from whole-stage code generation, we can still gain advantages from expression generation.
Expression generation doesn’t face the same limitations as whole-stage code generation. Very large expression trees can be broken into smaller ones, and Spark’s spark.sql.codegen.methodSplitThreshold controls how these are broken up. Although we experimented with this property, we didn’t observe significant improvements. The default setting seems satisfactory.
Spark provides a debugging property named spark.sql.codegen.factoryMode, which can be set to FALLBACK, CODEGEN_ONLY, or NO_CODEGEN. We can turn off expression code generation by setting spark.sql.codegen.factoryMode=NO_CODEGEN, which results in a drastic performance degradation:
With 500 rules and 21 expressions:
- map_filter took 1581 seconds
- explode_then_filter took 122.31 seconds.
Even though not all operators participate in whole-stage code generation, we still observe significant benefits from expression code generation.
The Results

With our best case of 25.1 seconds to evaluate 10,500 expressions on 1 million rows, we achieve a very respectable rate of 104 million expressions per second per CPU.
The takeaway from this study is that when evaluating a large number of expressions, we benefit from converting our queries that use map_filter to ones using an explode then filter approach. Additionally, the org.apache.spark.sql.catalyst.optimizer.InferFiltersFromGenerate rule does not seem beneficial in our use case, so we should exclude that rule from our queries.
Does it Explain our Initial Observations?
Implementing these lessons learned in our production jobs yielded significant benefits. However, even after these optimizations, splitting the large query into multiple smaller ones continued to provide advantages. Upon further investigation, we discovered that this was not solely due to code generation but rather a simpler explanation.
Spark streaming operates by running a micro-batch to completion and then checkpoints its progress before starting a new micro-batch.
During each micro-batch, Spark has to complete all its tasks, typically 200. However, not all tasks are created equal. Spark employs a round-robin strategy to distribute rows among these tasks. So, on occasion, some tasks can contain events with large attributes, for example, a very large command line, causing certain tasks to finish quickly while others take much longer. For example here the distribution of a micro-batch task execution time. The median task time is 14 seconds. However, the worst straggler is 1.6 minutes!
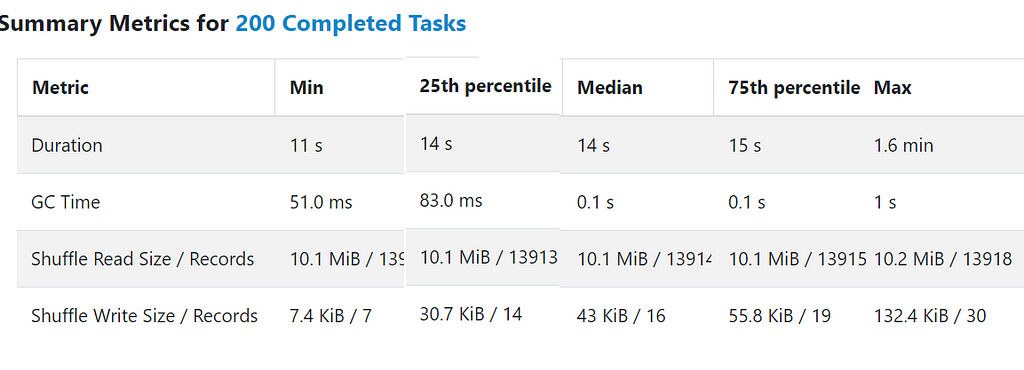
This indeed sheds light on a different phenomenon. The fact that Spark waits on a few straggler tasks during each micro-batch leaves many CPUs idle, which explains why splitting the large query into multiple smaller ones resulted in faster overall performance.
This picture shows 5 smaller queries running in parallel inside the same Spark application. Batch3 is waiting on a straggler task while the other queries keep progressing.
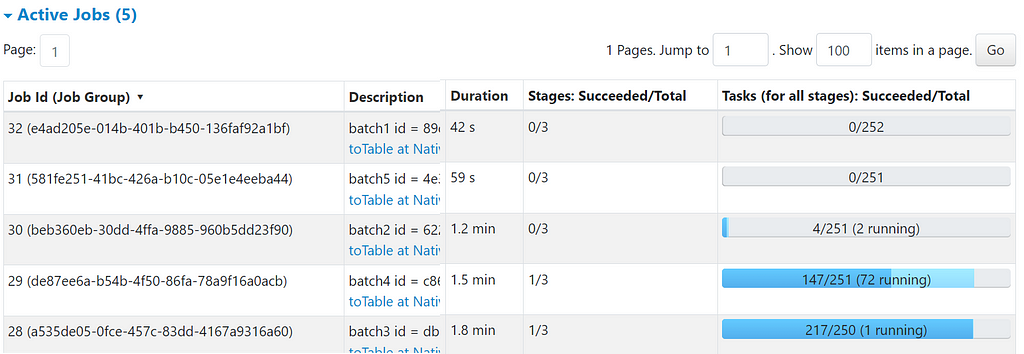
During these periods of waiting, Spark can utilize the idle CPUs to tackle other queries, thereby maximizing resource utilization and overall throughput.
Conclusion
In this article, we provided an overview of Spark’s code generation process and discussed how built-in optimizations may not always yield desirable results. Additionally, we demonstrated that refactoring a query from using lambda functions to one utilizing a simple explode operation resulted in performance improvements. Finally, we concluded that while splitting a large statement did lead to performance boosts, the primary factor driving these gains was the execution topology rather than the queries themselves.
Performance Insights from Sigma Rule Detections in Spark Streaming was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Performance Insights from Sigma Rule Detections in Spark Streaming
Go Here to Read this Fast! Performance Insights from Sigma Rule Detections in Spark Streaming