FOX Business reporter Eleanor Terrett reported a wide range of expectations regarding spot Ethereum ETF approvals on Jan. 23. Notably, Terrett suggested that the U.S. Securities and Exchange Commission (SEC) is opposed to approving a spot Ethereum ETF. She said: “Another source tells me the line at the SEC at this very moment is a […]
The IRS on Jan. 22 reminded all taxpayers to answer a question about digital assets and report all digital asset-related income. The question asks taxpayers: “At any time during 2023, did you: (a) receive (as a reward, award or payment for property or services); or (b) sell, exchange, or otherwise dispose of a digital asset […]
Global crypto-users rose by 34%, hitting 580 million, with Bitcoin and Ethereum users growing massively
This is a sign of growing mainstream crypto-acceptance and resilience amidst market chall
An overly-enthusiastic application of science and data visualization to a question we’ve all been asking
An especially sweet box plot. Image by author.
(Oh, I am the only one who’s been asking this question…? Hm. Well, if you have a minute, please enjoy this exploratory data analysis — featuring experimental design, statistics, and interactive visualization — applied a bit too earnestly to resolve an international debate.)
1. Introduction
1.1 Background and motivation
Chocolate is enjoyed around the world. From ancient practices harvesting organic cacao in the Amazon basin, to chocolatiers sculpting edible art in the mountains of Switzerland, and enormous factories in Hershey, Pennsylvania churning out 70 million kisses per day, the nuanced forms and flavors of chocolate have been integrated into many cultures and their customs. While quality can greatly vary across chocolate products, a well-known, shelf-stable, easily shareable form of chocolate are M&Ms. Readily found by convenience store check-out counters and in hotel vending machines, the brightly colored pellets are a popular treat whose packaging is re-branded to fit nearly any commercializable American holiday.
While living in Denmark in 2022, I heard a concerning claim: M&Ms manufactured in Europe taste different, and arguably “better,” than M&Ms produced in the United States. While I recognized that fancy European chocolate is indeed quite tasty and often superior to American chocolate, it was unclear to me if the same claim should hold for M&Ms. I learned that many Europeans perceive an “unpleasant” or “tangy” taste in American chocolate, which is largely attributed to butyric acid, a compound resulting from differences in how milk is treated before incorporation into milk chocolate.
But honestly, how much of a difference could this make for M&Ms? M&Ms!? I imagined M&Ms would retain a relatively processed/mass-produced/cheap candy flavor wherever they were manufactured. As the lone American visiting a diverse lab of international scientists pursuing cutting-edge research in biosustainability, I was inspired to break out my data science toolbox and investigate this M&M flavor phenomenon.
1.2 Previous work
To quote a European woman, who shall remain anonymous, after she tasted an American M&M while traveling in New York:
“They taste so gross. Like vomit. I don’t understand how people can eat this. I threw the rest of the bag away.”
Vomit? Really? In my experience, children raised in the United States had no qualms about eating M&Ms. Growing up, I was accustomed to bowls of M&Ms strategically placed in high traffic areas around my house to provide readily available sugar. Clearly American M&Ms are edible. But are they significantly different and/or inferior to their European equivalent?
In response to the anonymous European woman’s scathing report, myself and two other Americans visiting Denmark sampled M&Ms purchased locally in the Lyngby Storcenter Føtex. We hoped to experience the incredible improvement in M&M flavor that was apparently hidden from us throughout our youths. But curiously, we detected no obvious flavor improvements.
Unfortunately, neither preliminary study was able to conduct a side-by-side taste test with proper controls and randomized M&M sampling. Thus, we turn to science.
1.3 Study Goals
This study seeks to remedy the previous lack of thoroughness and investigate the following questions:
Is there a global consensus that European M&Ms are in fact better than American M&Ms?
Can Europeans actually detect a difference between M&Ms purchased in the US vs in Europe when they don’t know which one they are eating? Or is this a grand, coordinated lie amongst Europeans to make Americans feel embarrassed?
Are Americans actually taste-blind to American vs European M&Ms? Or can they taste a difference but simply don’t describe this difference as “an improvement” in flavor?
Can these alleged taste differences be perceived by citizens of other continents? If so, do they find one flavor obviously superior?
2. Methods
2.1 Experimental design and data collection
Participants were recruited by luring — er, inviting them to a social gathering (with the promise of free food) that was conveniently co-located with the testing site. Once a participant agreed to pause socializing and join the study, they were positioned at a testing station with a trained experimenter who guided them through the following steps:
Participants sat at a table and received two cups: 1 empty and 1 full of water. With one cup in each hand, the participant was asked to close their eyes, and keep them closed through the remainder of the experiment.
The experimenter randomly extracted one M&M with a spoon, delivered it to the participant’s empty cup, and the participant was asked to eat the M&M (eyes still closed).
After eating each M&M, the experimenter collected the taste response by asking the participant to report if they thought the M&M tasted: Especially Good, Especially Bad, or Normal.
Each participant received a total of 10 M&Ms (5 European, 5 American), one at a time, in a random sequence determined by random.org.
Between eating each M&M, the participant was asked to take a sip of water to help “cleanse their palate.”
Data collected: for each participant, the experimenter recorded the participant’s continent of origin (if this was ambiguous, the participant was asked to list the continent on which they have the strongest memories of eating candy as a child). For each of the 10 M&Ms delivered, the experimenter recorded the M&M origin (“Denmark” or “USA”), the M&M color, and the participant’s taste response. Experimenters were also encouraged to jot down any amusing phrases uttered by the participant during the test, recorded under notes (data available here).
2.2 Sourcing materials and recruiting participants
Two bags of M&Ms were purchased for this study. The American-sourced M&Ms (“USA M&M”) were acquired at the SFO airport and delivered by the author’s parents, who visited her in Denmark. The European-sourced M&Ms (“Denmark M&M”) were purchased at a local Føtex grocery store in Lyngby, a little north of Copenhagen.
Experiments were conducted at two main time points. The first 14 participants were tested in Lyngby, Denmark in August 2022. They mostly consisted of friends and housemates the author met at the Novo Nordisk Foundation Center for Biosustainability at the Technical University of Denmark (DTU) who came to a “going away party” into which the experimental procedure was inserted. A few additional friends and family who visited Denmark were also tested during their travels (e.g. on the train).
The remaining 37 participants were tested in Seattle, WA, USA in October 2022, primarily during a “TGIF happy hour” hosted by graduate students in the computer science PhD program at the University of Washington. This second batch mostly consisted of students and staff of the Paul. G. Allen School of Computer Science & Engineering (UW CSE) who responded to the weekly Friday summoning to the Allen Center atrium for free snacks and drinks.
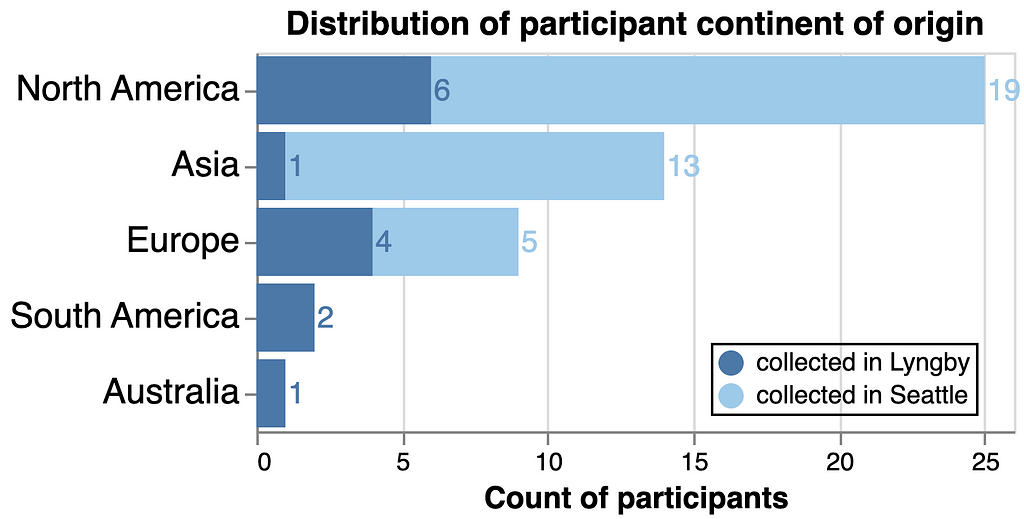
Figure 1. Distribution of participants recruited to the study. In the first sampling event in Lyngby, participants primarily hailed from North America and Europe, and a few additionally came from Asia, South America, or Australia. Our second sampling event in Seattle greatly increased participants, primarily from North America and Asia, and a few more from Europe. Neither event recruited participants from Africa. Figure made with Altair.
While this study set out to analyze global trends, unfortunately data was only collected from 51 participants the author was able to lure to the study sites and is not well-balanced nor representative of the 6 inhabited continents of Earth (Figure 1). We hope to improve our recruitment tactics in future work. For now, our analytical power with this dataset is limited to response trends for individuals from North America, Europe, and Asia, highly biased by subcommunities the author happened to engage with in late 2022.
2.3 Risks
While we did not acquire formal approval for experimentation with human test subjects, there were minor risks associated with this experiment: participants were warned that they may be subjected to increased levels of sugar and possible “unpleasant flavors” as a result of participating in this study. No other risks were anticipated.
After the experiment however, we unfortunately observed several cases of deflated pride when a participant learned their taste response was skewed more positively towards the M&M type they were not expecting. This pride deflation seemed most severe among European participants who learned their own or their fiancé’s preference skewed towards USA M&Ms, though this was not quantitatively measured and cannot be confirmed beyond anecdotal evidence.
3. Results & Discussion
3.1 Overall response to “USA M&Ms” vs “Denmark M&Ms”
In our first analysis, we count the total number of “Bad”, “Normal”, and “Good” taste responses and report the percentage of each response received by each M&M type. M&Ms from Denmark more frequently received “Good” responses than USA M&Ms but also more frequently received “Bad” responses. M&Ms from the USA were most frequently reported to taste “Normal” (Figure 2). This may result from the elevated number of participants hailing from North America, where the USA M&M is the default and thus more “Normal,” while the Denmark M&M was more often perceived as better or worse than the baseline.
Now let’s break out some statistics, such as a chi-squared (X2) test to compare our observed distributions of categorical taste responses. Using the scipy.stats chi2_contingency function, we built contingency tables of the observed counts of “Good,” “Normal,” and “Bad” responses to each M&M type. Using the X2 test to evaluate the null hypothesis that there is no difference between the two M&Ms, we found the p-value for the test statistic to be 0.0185, which is significant at the common p-value cut off of 0.05, but not at 0.01. So a solid “maybe,” depending on whether you’d like this result to be significant or not.
The X2 test helps evaluate if there is a difference in categorical responses, but next, we want to determine a relative taste ranking between the two M&M types. To do this, we converted taste responses to a quantitative distribution and calculated a taste score. Briefly, “Bad” = 1, “Normal” = 2, “Good” = 3. For each participant, we averaged the taste scores across the 5 M&Ms they tasted of each type, maintaining separate taste scores for each M&M type.
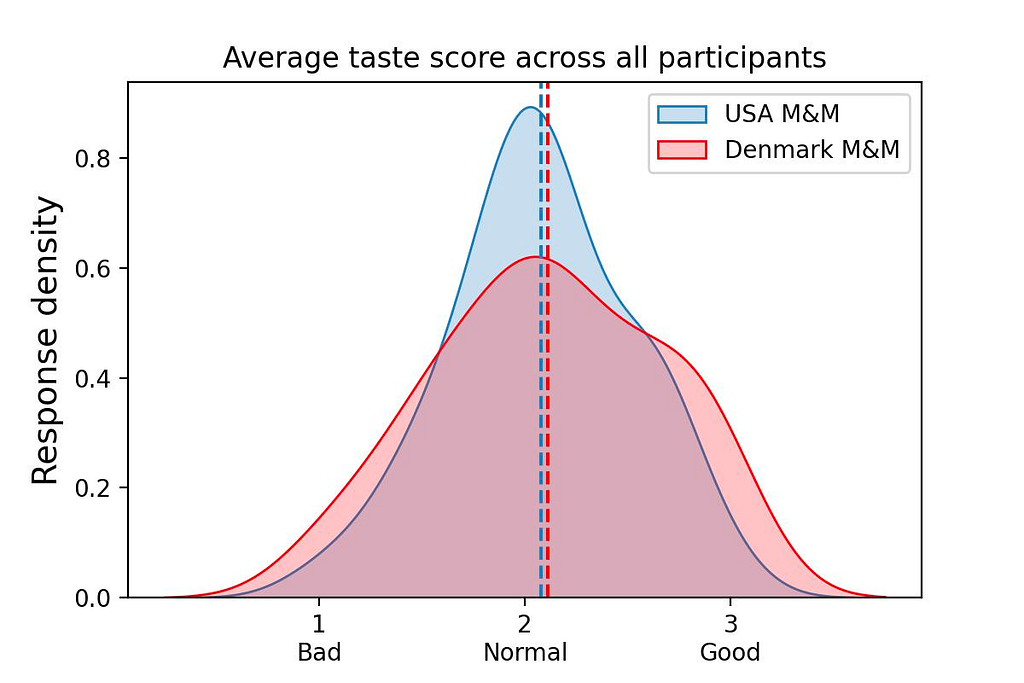
Figure 3. Quantitative taste score distributions across the whole dataset. Kernel density estimation of the average taste score calculated for each participant for each M&M type. Figure made with Seaborn.
With the average taste score for each M&M type in hand, we turn to scipy.stats ttest_ind (“T-test”) to evaluate if the means of the USA and Denmark M&M taste scores are different (the null hypothesis being that the means are identical). If the means are significantly different, it would provide evidence that one M&M is perceived as significantly tastier than the other.
We found the average taste scores for USA M&Ms and Denmark M&Ms to be quite close (Figure 3), and not significantly different (T-test: p = 0.721). Thus, across all participants, we do not observe a difference between the perceived taste of the two M&M types (or if you enjoy parsing triple negatives: “we cannotreject the null hypothesis that there is not a difference”).
But does this change if we separate participants by continent of origin?
3.2 Continent-specific responses to “USA M&Ms” vs “Denmark M&Ms”
We repeated the above X2 and T-test analyses after grouping participants by their continents of origin. The Australia and South America groups were combined as a minimal attempt to preserve data privacy. Due to the relatively small sample size of even the combined Australia/South America group (n=3), we will refrain from analyzing trends for this group but include the data in several figures for completeness and enjoyment of the participants who may eventually read this.
3.2.1 Categorical response analysis — by continent
In Figure 4, we display both the taste response counts (upper panel, note the interactive legend) and the response percentages (lower panel) for each continent group. Both North America and Asia follow a similar trend to the whole population dataset: participants report Denmark M&Ms as “Good” more frequently than USA M&Ms, but also report Denmark M&Ms as “Bad” more frequently. USA M&Ms were most frequently reported as “Normal” (Figure 4).
On the contrary, European participants report USA M&Ms as “Bad” nearly 50% of the time and “Good” only 18% of the time, which is the most negative and least positive response pattern, respectively (when excluding the under-sampled Australia/South America group).
This appeared striking in bar chart form, however only North America had a significant X2 p-value (p = 0.0058) when evaluating each continent’s difference in taste response profile between the two M&M types. The European p-value is perhaps “approaching significance” in some circles, but we’re about to accumulate several more hypothesis tests and should be mindful of multiple hypothesis testing (Table 1). A false positive result here would be devastating.
When comparing the taste response profiles between two continents for the same M&M type, there are a couple interesting notes. First, we observed no major taste discrepancies between all pairs of continents when evaluating Denmark M&Ms — the world seems generally consistent in their range of feelings about M&Ms sourced from Europe (right column X2 p-values, Table 2). To visualize this comparison more easily, we reorganize the bars in Figure 4 to group them by M&M type (Figure 5).
However, when comparing continents to each other in response to USA M&Ms, we see larger discrepancies. We found one pairing to be significantly different: European and North American participants evaluated USA M&Ms very differently (p = 0.000007) (Table 2). It seems very unlikely that this observed difference is by random chance (left column, Table 2).
3.2.2 Quantitative response analysis — by continent
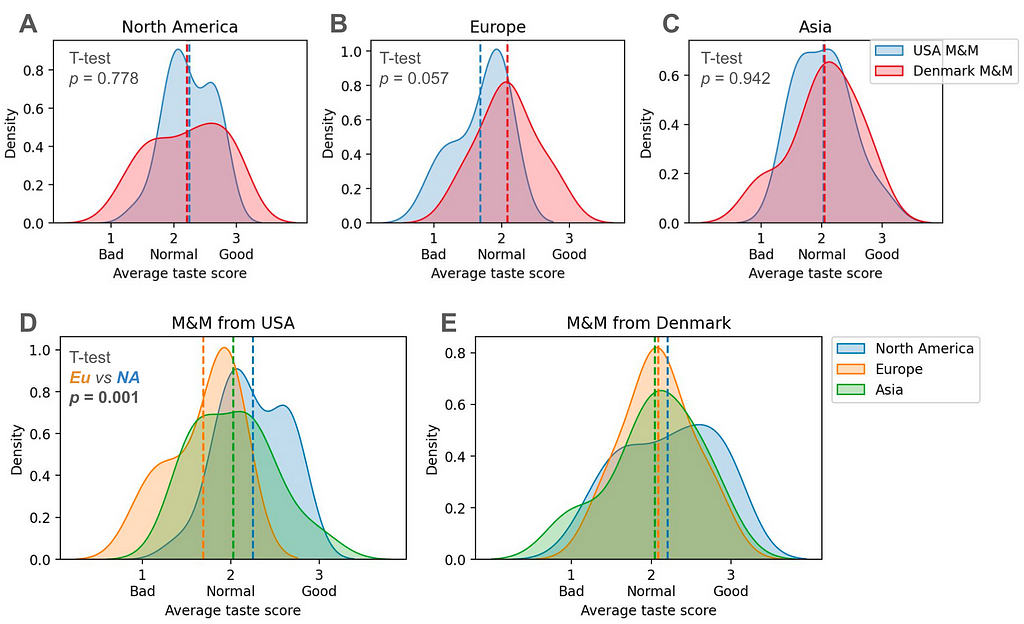
We again convert the categorical profiles to quantitative distributions to assess continents’ relative preference of M&M types. For North America, we see that the taste score means of the two M&M types are actually quite similar, but there is a higher density around “Normal” scores for USA M&Ms (Figure 6A). The European distributions maintain a bit more of a separation in their means (though not quite significantly so), with USA M&Ms scoring lower (Figure 6B). The taste score distributions of Asian participants is most similar (Figure 6C).
Reorienting to compare the quantitative means between continents’ taste scores for the same M&M type, only the comparison between North American and European participants on USA M&Ms is significantly different based on a T-test (p = 0.001) (Figure 6D), though now we really are in danger of multiple hypothesis testing! Be cautious if you are taking this analysis at all seriously.
Figure 6. Quantitative taste score distributions by continent. Kernel density estimation of the average taste score calculated for each each continent for each M&M type. A. Comparison of North America responses to each M&M. B. Comparison of Europe responses to each M&M. C. Comparison of Asia responses to each M&M. D. Comparison of continents for USA M&Ms. E. Comparison of continents for Denmark M&Ms. Figure made with Seaborn.
At this point, I feel myself considering that maybe Europeans are not just making this up. I’m not saying it’s as dramatic as some of them claim, but perhaps a difference does indeed exist… To some degree, North American participants also perceive a difference, but the evaluation of Europe-sourced M&Ms is not consistently positive or negative.
3.3 M&M taste alignment chart
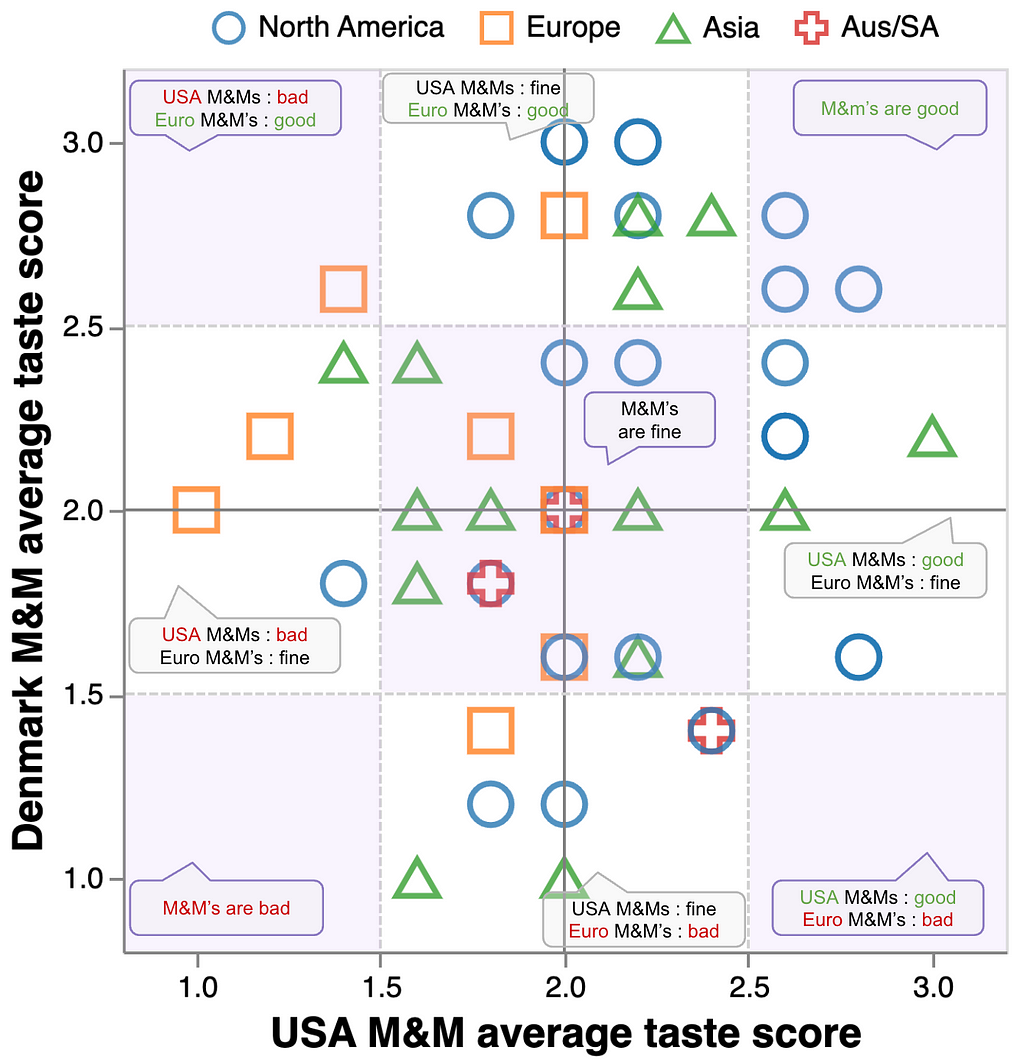
In our analyses thus far, we did not account for the baseline differences in M&M appreciation between participants. For example, say Person 1 scored all Denmark M&Ms as “Good” and all USA M&Ms as “Normal”, while Person 2 scored all Denmark M&Ms as “Normal” and all USA M&Ms as “Bad.” They would have the same relative preference for Denmark M&Ms over USA M&Ms, but Person 2 perhaps just does not enjoy M&Ms as much as Person 1, and the relative preference signal is muddled by averaging the raw scores.
Figure 7. M&M enjoyment alignment chart. The x-axis represents a participant’s average taste score for USA M&Ms; the y-axis is a participant’s average taste score for Denmark M&Ms. Figure made with Altair.
Notably, the upper right quadrant where both M&M types are perceived as “Good” to “Normal” is mostly occupied by North American participants and a few Asian participants. All European participants land in the left half of the figure where USA M&Ms are “Normal” to “Bad”, but Europeans are somewhat split between the upper and lower halves, where perceptions of Denmark M&Ms range from “Good” to “Bad.”
An interactive version of Figure 7 is provided below for the reader to explore the counts of various M&M alignment regions.
3.4 Participant taste response ratio
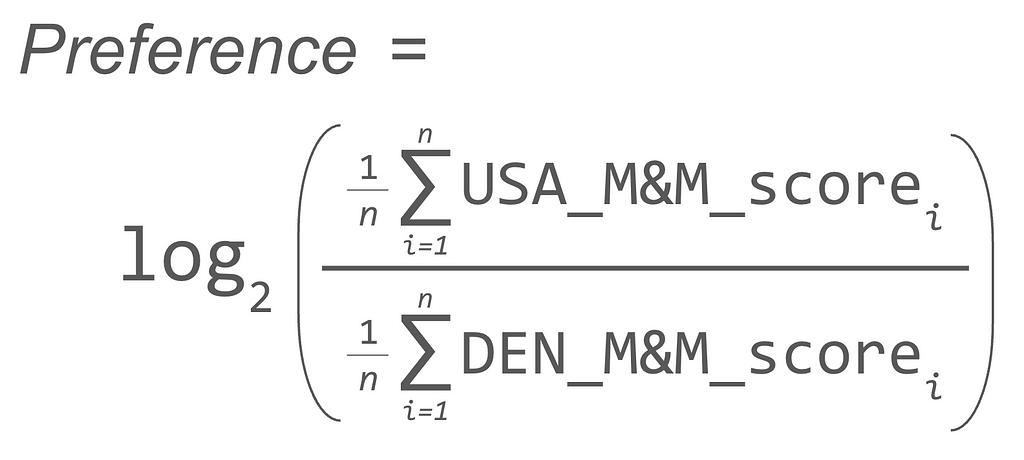
Next, to factor out baseline M&M enjoyment and focus on participants’ relative preference between the two M&M types, we took the log ratio of each person’s USA M&M taste score average divided by their Denmark M&M taste score average.
Equation 1: Equation to calculate each participant’s overall M&M preference ratio.
As such, positive scores indicate a preference towards USA M&Ms while negative scores indicate a preference towards Denmark M&Ms.
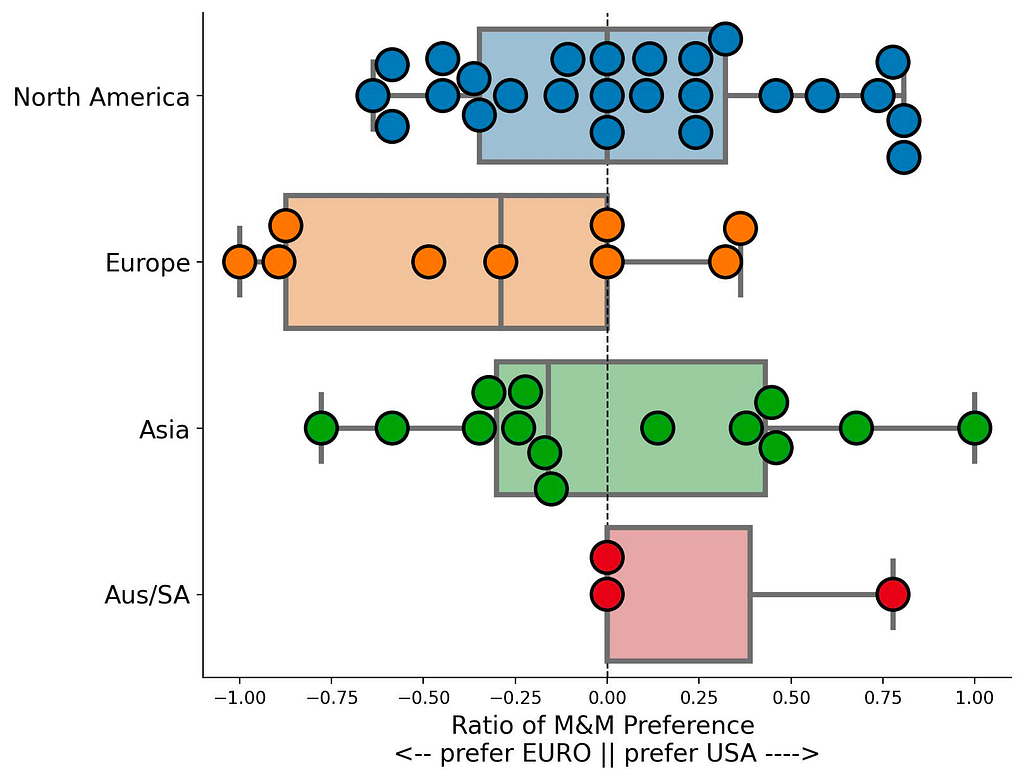
On average, European participants had the strongest preference towards Denmark M&Ms, with Asians also exhibiting a slight preference towards Denmark M&Ms (Figure 8). To the two Europeans who exhibited deflated pride upon learning their slight preference towards USA M&Ms, fear not: you did not think USA M&Ms were “Good,” but simply ranked them as less bad than Denmark M&Ms (see participant_id 4 and 17 in the interactive version of Figure 7). If you assert that M&Ms are a bad American invention not worth replicating and return to consuming artisanal European chocolate, your honor can likely be restored.
Figure 8. Distribution of participant M&M preference ratios by continent. Preference ratios are calculated as in Equation 1. Positive numbers indicate a relative preference for USA M&Ms, while negative indicate a relative preference for Denmark M&Ms. Figure made with Seaborn.
North American participants are pretty split in their preference ratios: some fall quite neutrally around 0, others strongly prefer the familiar USA M&M, while a handful moderately prefer Denmark M&Ms. Anecdotally, North Americans who learned their preference skewed towards European M&Ms displayed signals of inflated pride, as if their results signaled posh refinement.
Overall, a T-test comparing the distributions of M&M preference ratios shows a possibly significant difference in the means between European and North American participants (p = 0.049), but come on, this is like the 20th p-value I’ve reported — this one is probably too close to call.
3.5 Taste inconsistency and “Perfect Classifiers”
For each participant, we assessed their taste score consistency by averaging the standard deviations of their responses to each M&M type, and plotting that against their preference ratio (Figure 9).
Most participants were somewhat inconsistent in their ratings, ranking the same M&M type differently across the 5 samples. This would be expected if the taste difference between European-sourced and American-sourced M&Ms is not actually all that perceptible. Most inconsistent were participants who gave the same M&M type “Good”, “Normal”, and “Bad” responses (e.g., points high on the y-axis, with wider standard deviations of taste scores), indicating lower taste perception abilities.
Intriguingly, four participants — one from each continent group — were perfectly consistent: they reported the same taste response for each of the 5 M&Ms from each M&M type, resulting in an average standard deviation of 0.0 (bottom of Figure 9). Excluding the one of the four who simply rated all 10 M&Ms as “Normal”, the other three appeared to be “Perfect Classifiers” — either rating all M&Ms of one type “Good” and the other “Normal”, or rating all M&Ms of one type “Normal” and the other “Bad.” Perhaps these folks are “super tasters.”
3.6 M&M color
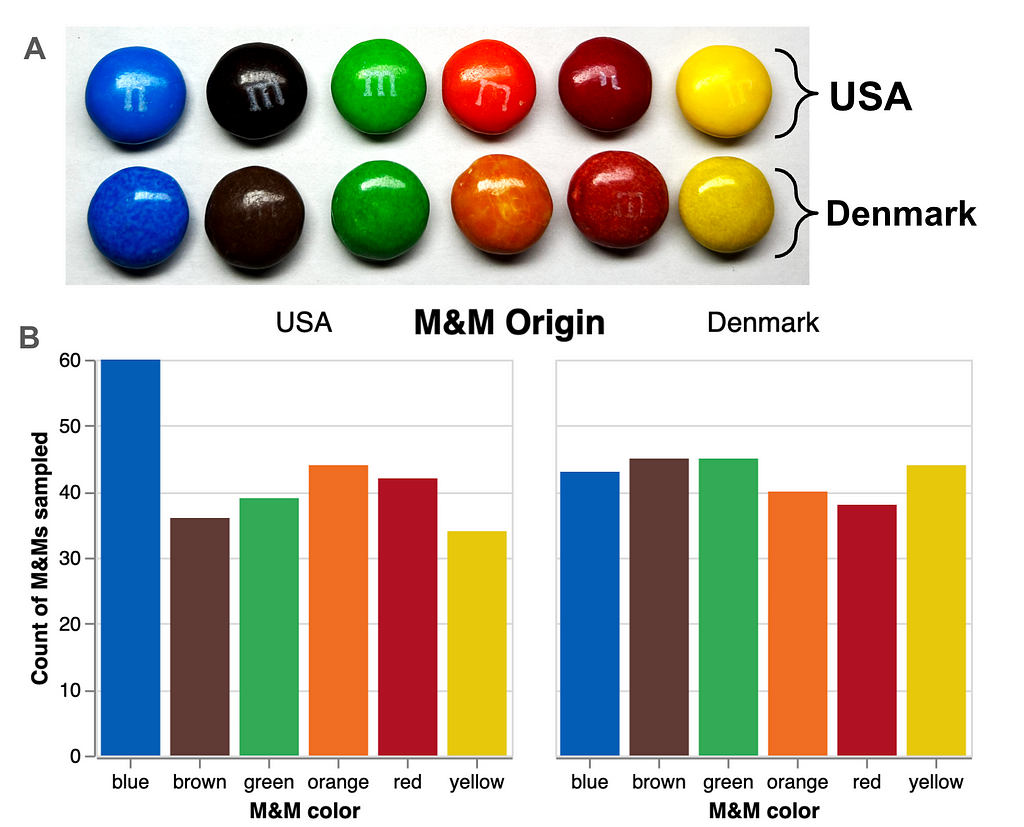
Another possible explanation for the inconsistency in individual taste responses is that there exists a perceptible taste difference based on the M&M color. Visually, the USA M&Ms were noticeably more smooth and vibrant than the Denmark M&Ms, which were somewhat more “splotchy” in appearance (Figure 10A). M&M color was recorded during the experiment, and although balanced sampling was not formally built into the experimental design, colors seemed to be sampled roughly evenly, with the exception of Blue USA M&Ms, which were oversampled (Figure 10B).
Figure 10. M&M colors. A. Photo of each M&M color of each type. It’s perhaps a bit hard to perceive on screen in my unprofessionally lit photo, but with the naked eye, USA M&Ms seemed to be brighter and more uniformly colored while Denmark M&Ms have a duller and more mottled color. Is it just me, or can you already hear the Europeans saying “They are brighter because of all those extra chemicals you put in your food that we ban here!” B. Distribution of M&Ms of each color sampled over the course of the experiment. The Blue USA M&Ms were not intentionally oversampled — they must be especially bright/tempting to experimenters. Figure made with Altair.
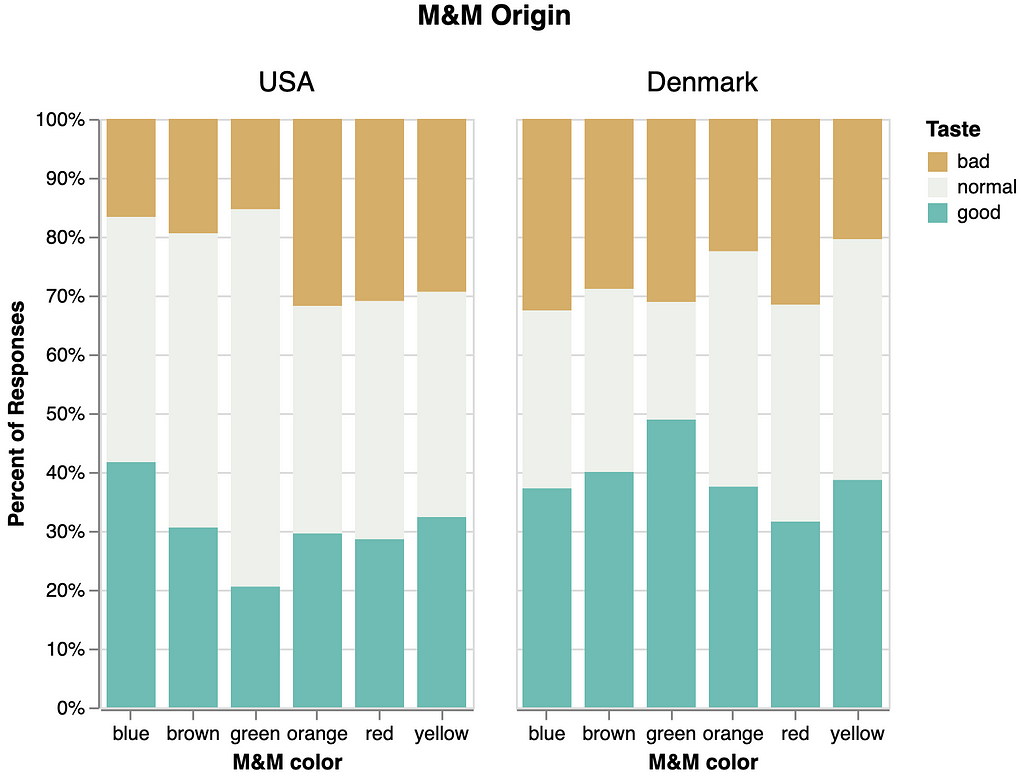
We briefly visualized possible differences in taste responses based on color (Figure 11), however we do not believe there are enough data to support firm conclusions. After all, on average each participant would likely only taste 5 of the 6 M&M colors once, and 1 color not at all. We leave further M&M color investigations to future work.
Figure 11. Taste response profiles for M&Ms of each color and type. Profiles are reported as percentages of “Bad”, “Normal”, and “Good” responses, though not all M&Ms were sampled exactly evenly. Figure made with Altair.
3.7 Colorful commentary
We assured each participant that there was no “right “answer” in this experiment and that all feelings are valid. While some participants took this to heart and occasionally spent over a minute deeply savoring each M&M and evaluating it as if they were a sommelier, many participants seemed to view the experiment as a competition (which occasionally led to deflated or inflated pride). Experimenters wrote down quotes and notes in conjunction with M&M responses, some of which were a bit “colorful.” We provide a hastily rendered word cloud for each M&M type for entertainment purposes (Figure 12) though we caution against reading too far into them without diligent sentiment analysis.
Figure 11. A simple word cloud generated from the notes column of each M&M type. Fair warning — these have not been properly analyzed for sentiment and some inappropriate language was recorded. Figure made with WordCloud.
4. Conclusion
Overall, there does not appear to be a “global consensus” that European M&Ms are better than American M&Ms. However, European participants tended to more strongly express negative reactions to USA M&Ms while North American participants seemed relatively split on whether they preferred M&Ms sourced from the USA vs from Europe. The preference trends of Asian participants often fell somewhere between the North Americans and Europeans.
Therefore, I’ll admit that it’s probable that Europeans are not engaged in a grand coordinated lie about M&Ms. The skew of most European participants towards Denmark M&Ms is compelling, especially since I was the experimenter who personally collected much of the taste response data. If they found a way to cheat, it was done well enough to exceed my own passive perception such that I didn’t notice. However, based on this study, it would appear that a strongly negative “vomit flavor” is not universally perceived and does not become apparent to non-Europeans when tasting both M&Ms types side by side.
We hope this study has been illuminating! We would look forward to extensions of this work with improved participant sampling, additional M&M types sourced from other continents, and deeper investigations into possible taste differences due to color.
Thank you to everyone who participated and ate M&Ms in the name of science!
Article by Erin H. Wilson, Ph.D.[1,2,3] who decided the time between defending her dissertation and starting her next job would be best spent on this highly valuable analysis. Hopefully it is clear that this article is intended to be comedic— I do not actually harbor any negative feelings towards Europeans who don’t like American M&Ms, but enjoyed the chance to be sassy and poke fun at our lively debates with overly-enthusiastic data analysis.
Shout out to Matt, Galen, Ameya, and Gian-Marco for assisting in data collection!
[1] Former Ph.D. student in the Paul G. Allen School of Computer Science and Engineering at the University of Washington
[2] Former visiting Ph.D. student at the Novo Nordisk Foundation Center for Biosustainability at the Technical University of Denmark
In a rapidly changing world, humans are required to quickly adapt to a new environment. Neural networks show why this is easier said than done. Our article uses a perceptron to demonstrate why unlearning and relearning can be costlier than learning from scratch.
Introduction
One of the positive side effects of artificial intelligence (AI) is that it can help us to better understand our own human intelligence. Ironically, AI is also one of the technologies seriously challenging our cognitive abilities. Together with other innovations, it transforms modern society at a breathtaking speed. In his book “Think Again”, Adam Grant points out that in a volatile environment rethinking and unlearning may be more important than thinking and learning [1].
Especially for aging societies this can be a challenge. In Germany, there is a saying “Was Hänschen nicht lernt, lernt Hans nimmermehr.” English equivalents are: “A tree must be bent while it is young”, or less charmingly: “You can’t teach an old dog new tricks.” In essence, all these sayings suggest that younger people learn more easily than older persons. But is this really true, and if so, what are the reasons behind it?
Obviously, the brain structure of young people is different to that of older persons from a physiological standpoint. At an individual level, however, these differences vary considerably [2]. According to Creasy and Rapoport, the “overall functions [of the brain] can be maintained at high and effective levels“ even in an older age [3]. Aside from physiology, motivation and emotion seem to play vital roles in the learning process [4][5]. A study by Kim and Marriam at a retirement institution shows that cognitive interest and social interaction are strong learning motivators [6].
Our article discusses the question from the perspective of mathematics and computer science. Inspired by Hinton and Sejnowski [7], we conduct an experiment with an artificial neural network (ANN). Our test shows why retraining can be harder than training from scratch in a changing environment. The reason is that a network must first unlearn previously learned concepts before it can adapt to new training data. Assuming that AI has similarities with human intelligence, we can draw some interesting conclusions from this insight.
Artificial neural networks
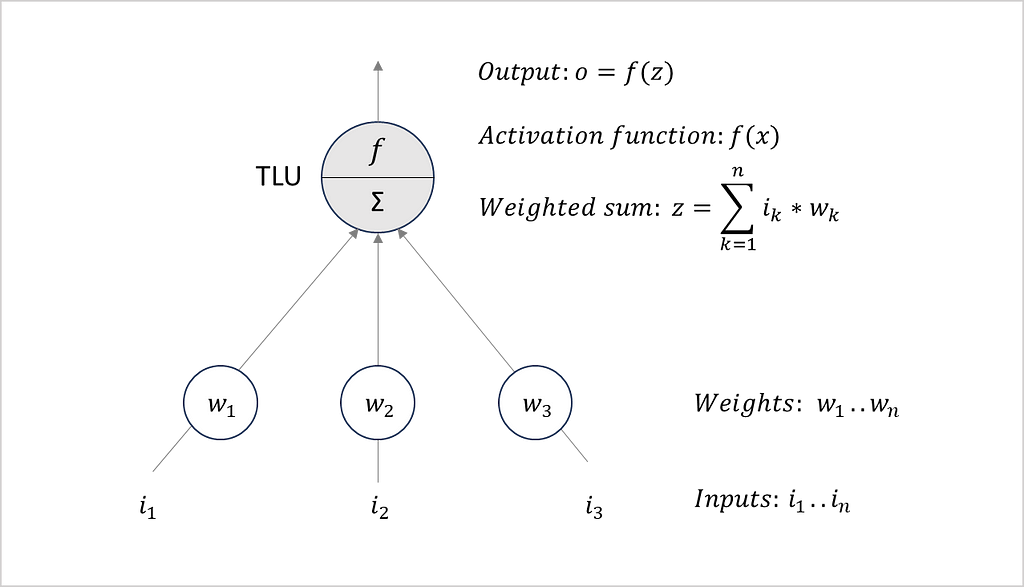
Artificial neural networks resemble the structure and behavior of the nerve cells of our brain, known as neurons. Typically, an ANN consists of input cells that receive signals from the outside world. By processing these signals, the network is able to make a decision in response to the received input. A perceptron is a simple variant of an ANN [8]. It was introduced in 1958 by Rosenblatt [9]. Figure 1 outlines the basic structure of a perceptron. In recent decades, more advanced types of ANNs have been developed. Yet for our experiment, a perceptron is well suited as it is easy to explain and interpret.
Figure 1: Structure of a single-layer perceptron. Own representation based on [8, p. 284].
Figure 1 shows the architecture of a single-layer perceptron. As input, the network receives n numbers (i₁..iₙ). Together with learned weights (w₁..wₙ), the inputs are transmitted to a threshold logic unit (TLU). This TLU calculates a weighted sum (z) by multiplying the inputs (i) and the weights (w). In the next step, an activation function (f) determines the output (o) based on the weighted sum (z). Finally, the output (o) allows the network to make a decision as a response to the received input. Rosenblatt has shown that this simple form of ANN can solve a variety of problems.
Perceptrons can use different activation functions to determine their output (o). Common functions are the binary step function and the sign function, presented in Figure 2. As the name indicates, the binary function generates a binary output {0,1} that can be used to make yes/no decisions. For this purpose, the binary function checks whether the weighted sum (z) of a given input is less or equal to zero. If this is the case, the output (o) is zero, otherwise one. In comparison, the sign function distinguishes between three different output values {-1,0,+1}.
Figure 2: Examples of activation functions. Own representation based on [8, p. 285].
To train a perceptron based on a given dataset, we need to provide a sample that includes input signals (features) linked to the desired output (target). During the training process, an algorithm repeatedly processes the input to learn the best fitting weights to generate the output. The number of iterations required for training is a measure of the learning effort. For our experiment, we train a perceptron to decide whether a customer will buy a certain mobile phone. The source code is available on GitHub [10]. For the implementation, we used Python v3.10 and scikit-learn v1.2.2.
Learning customer preferences
Our experiment is inspired by a well-known case of (failed) relearning. Let us imagine we work for a mobile phone manufacturer in the year 2000. Our goal is to train a perceptron that learns whether customers will buy a certain phone model. In 2000, touchscreens are still an immature technology. Therefore, clients prefer devices with a keypad instead. Moreover, customers pay attention to the price and opt for low-priced models compared to more expensive phones. Features like these made the Nokia 3310 the world’s best-selling mobile phone in 2000 [11].
Figure 3: Nokia 3310, Image by LucaLuca, CC BY-SA 3.0, Wikimedia Commons
For the training of the perceptron, we use the hypothetical dataset shown in Table 1. Each row represents a specific phone model and the columns “keypad”, “touch” and “low_price” its features. For the sake of simplicity, we use binary variables. Whether a customer will buy a device is defined in the column “sale.” As described above, clients will buy phones with keypads and a low price (keypad=1 and low_price=1). In contrast, they will reject high-priced models (low_price=0) and phones with touchscreens (touch=1).
Table 1: Hypothetical phone sales dataset from 2000
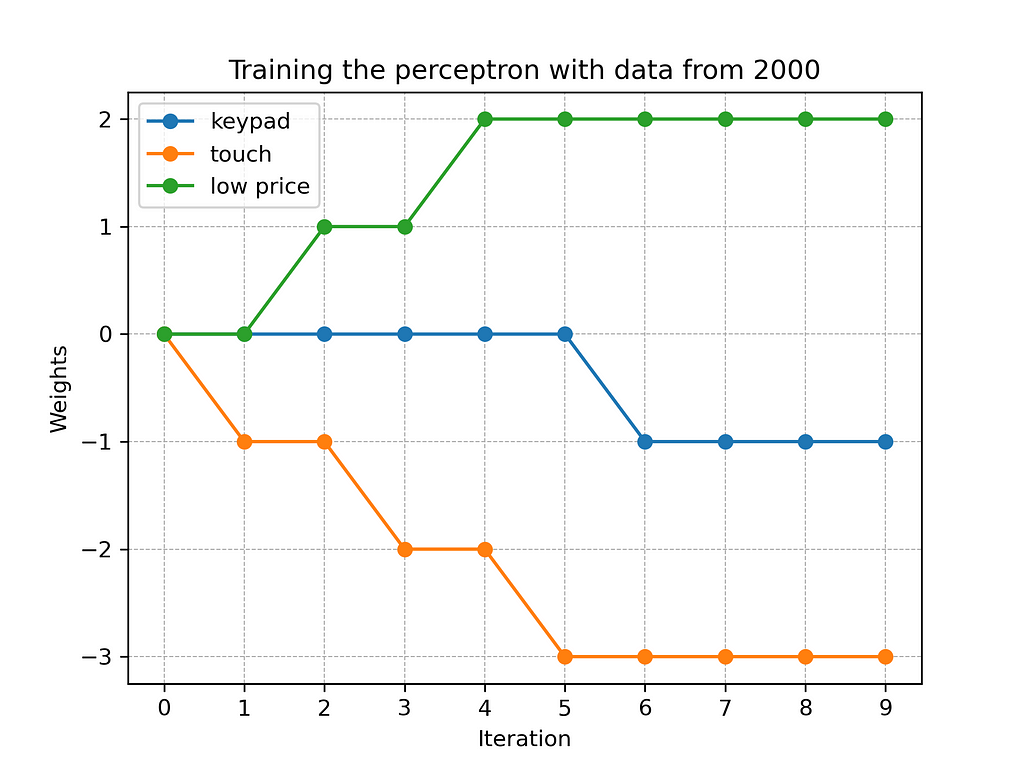
In order to train the perceptron, we feed the above dataset several times. In terms of scikit-learn, we repeatedly call the function partial_fit (source code see here). In each iteration, an algorithm tries to gradually adjust the weights of the network to minimize the error in predicting the variable “sale.” Figure 4 illustrates the training process over the first ten iterations.
Figure 4: Training the phone sales perceptron with data from 2000
As the above diagram shows, the weights of the perceptron are gradually optimized to fit the dataset. In the sixth iteration, the network learns the best fitting weights, subsequently the numbers remain stable. Figure 5 visualizes the perceptron after the learning process.
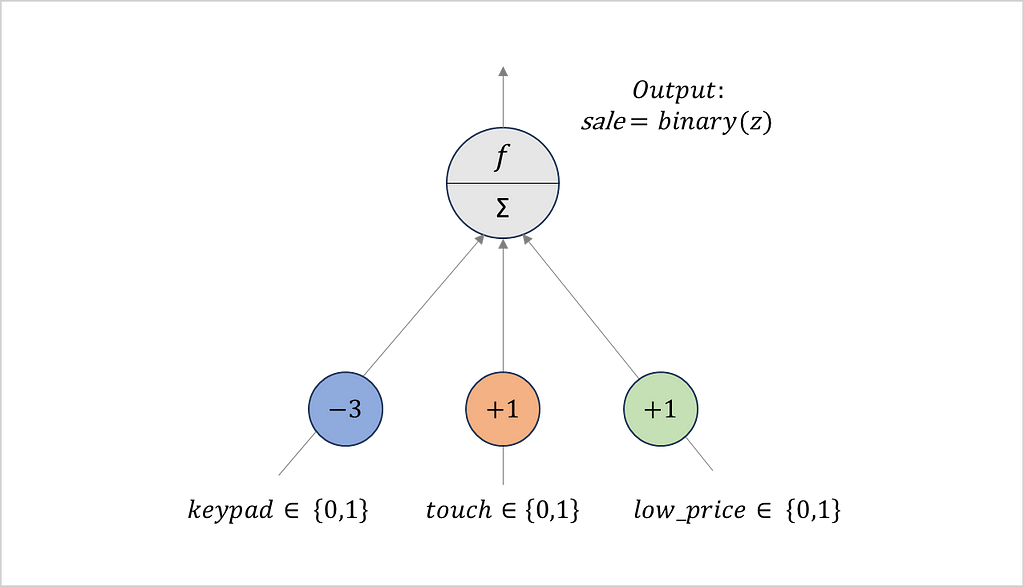
Figure 5: Phone sales perceptron trained with data from 2000
Let us consider some examples based on the trained perceptron. A low-priced phone with a keypad leads to a weighted sum of z=-1*1–3*0+2*1=1. Applying the binary step function generates the output sale=1. Consequently, the network predicts clients to buy the phone. In contrast, a high-priced device with a keypad leads to the weighted sum z=-1*1–3*0+2*0=1=-1. This time, the network predicts customers to reject the device. The same is true, for a phone having a touchscreen. (In our experiment, we ignore the case where a device has neither a keypad nor a touchscreen, as customers have to operate it somehow.)
Retraining with changed preferences
Let us now imagine that customer preferences have changed over time. In 2007, technological progress has made touchscreens much more user-friendly. As a result, clients now prefer touchscreens instead of keypads. Customers are also willing to pay higher prices as mobile phones have become status symbols. These new preferences are reflected in the hypothetical dataset shown in Table 2.
Table 2: Hypothetical phone sales dataset from 2007
According to Table 2, clients will buy a phone with a touchscreen (touch=1) and do not pay attention to the price. Instead, they refuse to buy devices with keypads. In reality, Apple entered the mobile phone market in 2007 with its iPhone. Providing a high-quality touchscreen, it challenged established brands. By 2014, the iPhone eventually became the best-selling mobile phone, pushing Nokia out of the market [11].
Figure 6: iPhone 1st generation, Carl Berkeley — CC BY-SA 2.0, Wikimedia Commons
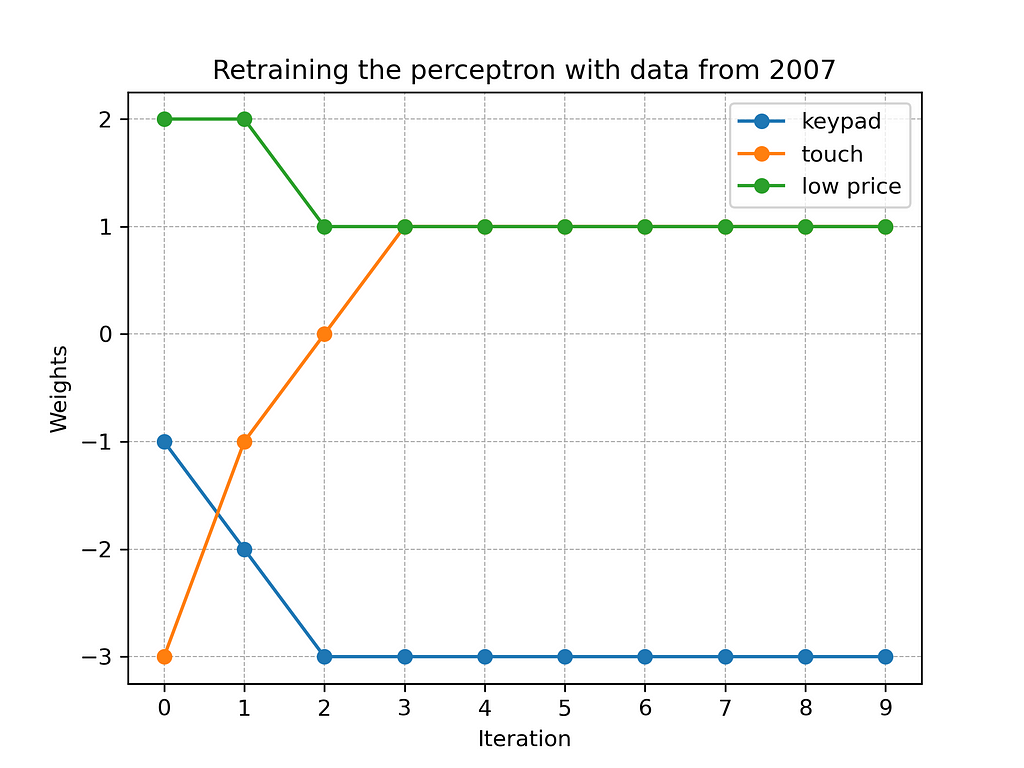
In order to adjust the previously trained perceptron to the new customer preferences, we have to retrain it with the 2007 dataset. Figure 7 illustrates the retraining process over the first ten iterations.
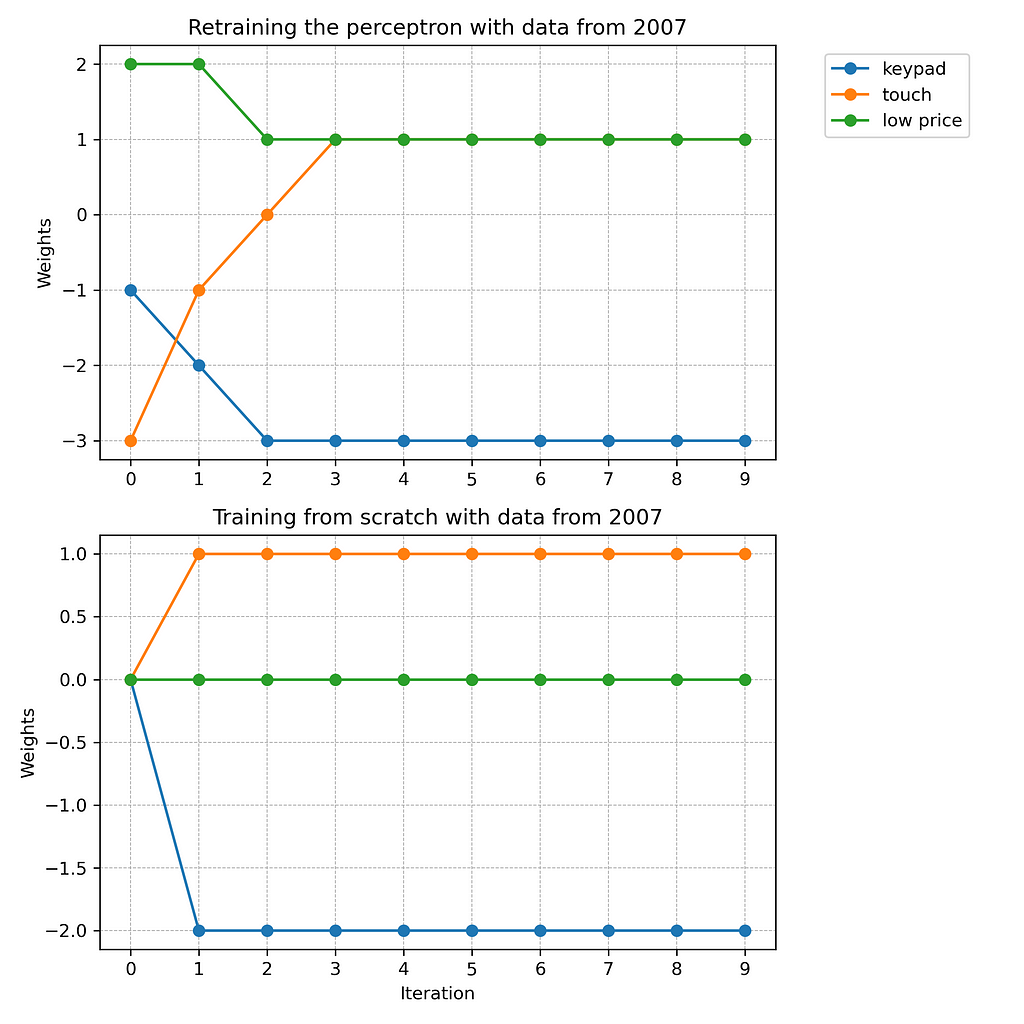
Figure 7: Retraining the phones sales perceptron with data from 2007
As Figure 7 shows, the retraining requires three iterations. Then, the best fitting weights are found and the network has learned the new customer preferences of 2007. Figure 8 illustrates the network after relearning.
Figure 8: Phone sales perceptron after retraining with data from 2007
Let us consider some examples based on the retrained perceptron. A phone with a touchscreen (touch=1) and a low price (low_price=1) now leads to the weighted sum z=-3*0+1*1+1*1=2. Accordingly, the network predicts customers to buy a phone with these features. The same applies to a device having a touchscreen (touch=1) and a high price (low_price=0). In contrast, the network now predicts that customers will reject devices with keypads.
From Figure 7, we can see that the retraining with the 2007 data requires three iterations. But what if we train a new perceptron from scratch instead? Figure 8 compares the retraining of the old network with training a completely new perceptron on basis of the 2007 dataset.
Figure 9: Retraining vs training from scratch with data from 2007
In our example, training a new perceptron from scratch is much more efficient than retraining the old network. According to Figure 9, training requires only one iteration, while retraining takes three times as many steps. Reason for this is that the old perceptron must first unlearn previously learned weights from the year 2000. Only then is it able to adjust to the new training data from 2007. Consider, for example, the weight of the feature “touch.” The old network must adjust it from -3 to +1. Instead, the new perceptron can start from scratch and increase the weight directly from 0 to +1. As a result, the new network learns faster and arrives at a slightly different setting.
Discussion of results
Our experiment shows from a mathematical perspective why retraining an ANN can be more costly than training a new network from scratch. When data has changed, old weights must be unlearned before new weights can be learned. If we assume that this also applies to the structure of the human brain, we can transfer this insight to some real-world problems.
In his book “The Innovator’s Dilemma”, Christensen studies why companies that once were innovators in their sector failed to adapt to new technologies [12]. He underpins his research with examples from the hard disk and the excavator market. In several cases, market leaders struggled to adjust to radical changes and were outperformed by market entrants. According to Christensen, new companies entering a market could adapt faster and more successfully to the transformed environment. As primary causes for this he identifies economic factors. Our experiment suggests that there may also be mathematical reasons. From an ANN perspective, market entrants have the advantage of learning from scratch, while established providers must first unlearn their traditional views. Especially in the case of disruptive innovations, this can be a major drawback for incumbent firms.
Radical change is not only a challenge for businesses, but also for society as a whole. In their book “The Second Machine Age”, Brynjolfsson and McAfee point out that disruptive technologies can trigger painful social adjustment processes [13]. The authors compare the digital age of our time with the industrial revolution of the 18th and 19th centuries. Back then, radical innovations like the steam engine and electricity led to a deep transformation of society. Movements such as the Luddites tried to resist this evolution by force. Their struggle to adapt may not only be a matter of will, but also of ability. As we have seen above, unlearning and relearning can require a considerable effort compared to learning from scratch.
Conclusion
Clearly, our experiment builds on a simplified model of reality. Biological neural networks are more complicated than perceptrons. The same is true for customer preferences in the mobile phone market. Nokia’s rise and fall has many reasons aside from the features included in our dataset. As we have only discussed one specific scenario, another interesting research question is in which cases retraining is actually harder than training. Authors like Hinton and Sejnowski [7] as well as Chen et. al [14] offer a differentiated view of the topic. Hopefully our article provides a starting point to these more technical publications.
Acknowledging the limitations of our work, we can draw some key lessons from it. When people fail to adapt to a changing environment, it is not necessarily due to a lack of intellect or motivation. We should keep this in mind when it comes to the digital transformation. Unlike digital natives, the older generation must first unlearn “analog” concepts. This requires effort and time. Putting too much pressure on them can lead to an attitude of denial, which translates into conspiracy theories and calls for strong leaders to stop progress. Instead, we should develop concepts for successful unlearning and relearning. Teaching technology is at least as important as developing it. Otherwise, we leave the society behind that we aim to support.
About the authors
Christian Koch is an Enterprise Lead Architect at BWI GmbH and Lecturer at the Nuremberg Institute of Technology Georg Simon Ohm.
Markus Stadi is a Senior Cloud Data Engineer at Dehn SE working in the field of Data Engineering, Data Science and Data Analytics for many years.
References
Grant, A. (2023). Think again: The power of knowing what you don’t know. Penguin.
Reuter-Lorenz, P. A., & Lustig, C. (2005). Brain aging: reorganizing discoveries about the aging mind. Current opinion in neurobiology, 15(2), 245–251.
Creasey, H., & Rapoport, S. I. (1985). The aging human brain. Annals of Neurology: Official Journal of the American Neurological Association and the Child Neurology Society, 17(1), 2–10.
Welford AT. Motivation, Capacity, Learning and Age. The International Journal of Aging and Human Development. 1976;7(3):189–199.
Carstensen, L. L., Mikels, J. A., & Mather, M. (2006). Aging and the intersection of cognition, motivation, and emotion. In Handbook of the psychology of aging (pp. 343–362). Academic Press.
Kim, A., & Merriam, S. B. (2004). Motivations for learning among older adults in a learning in retirement institute. Educational gerontology, 30(6), 441–455.
Hinton, G. E., & Sejnowski, T. J. (1986). Learning and relearning in Boltzmann machines. Parallel distributed processing: Explorations in the microstructure of cognition, 1(282–317), 2.
Géron, A. (2022). Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow. O’Reilly Media, Inc.
Rosenblatt, F. (1958). The perceptron: a probabilistic model for information storage and organization in the brain. Psychological review, 65(6), 386.
Christensen, C. M. (2013). The innovator’s dilemma: when new technologies cause great firms to fail. Harvard Business Review Press.
Brynjolfsson, E., & McAfee, A. (2014). The second machine age: Work, progress, and prosperity in a time of brilliant technologies. WW Norton & Company.
Chen, M., Zhang, Z., Wang, T., Backes, M., Humbert, M., & Zhang, Y. (2022, November). Graph unlearning. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security (pp. 499–513).
The endless pursuit of satisfying shareholders has led Netflix to delete its cheapest ads-free tier, leaving users to choose between spending more money or more time with ads.
Netflix
Netflix stopped letting new users sign up for the “Basic” ads-free tier in the Summer of 2023, just before its ad tier launched. It left existing customers alone at the time, but that will change in 2024.
According toThe Verge, Netflix made the announcement while reporting its earnings. The ads-free Basic tier would be phased out entirely, starting with the UK and Canada in Q2 2024, with the US and other countries to follow.
The University of Texas At San Antonio has seen a 31% increase in students enrolled in AI, cybersecurity, data science, and related degree programs since 2019.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.