Since starting its journey in May 2024, the MoonBag presale has inspired crypto enthusiasts. Its mission to the moon, symbolically associated with riches, has inspired crypto enthusiasts. During these three months, users who entered the presale in the initial stages have been sitting comfortably with massive return, anticipating the MoonBag’s launch later this year. The […]
A highly coveted CryptoPunk non-fungible token (NFT) has been sold at an astonishing 80% discount, highlighting the current challenges within the NFT market.
VICA (Virtual Intelligent Chat Assistant) is GovTech’s Virtual Assistant platform that leverages Artificial Intelligence (AI) to allow users to create, train and deploy chatbots on their websites. At the time of writing, VICA supports over 100 chatbots and handles over 700,000 user queries in a month.
Behind the scenes, VICA’s NLP engine makes use of various technologies and frameworks ranging from traditional intent-matching systems to generative AI frameworks like Retrieval Augmented Generation (RAG). By keeping up to date with state-of-the-art technologies, our engine is constantly evolving, ensuring that every citizen’s query gets matched to the best possible answer.
Beyond simple Question-And-Answer (Q&A) capabilities, VICA aims to supercharge chatbots through conversational transactions. Our goal is to say goodbye to the robotic and awkward form-like experience within a chatbot, and say hello to personalized conversations with human-like assistance.
This article is the first in a two part article series to share more about the generative AI solutions we have built in VICA. In this article, we will focus on how LLM agents can help improve the transaction process in chatbots through using LangChain’s Agent Framework.
Sample transaction chatbot conversation, Image by Authors
Transaction-based chatbots are conversational agents designed to facilitate and execute specific transactions for users. These chatbots go beyond simple Q&A interactions that occur by allowing users to perform tasks such as booking, purchasing, or form submission directly within the chatbot interface.
In order to perform transactions, the chatbots have to be customized on the backend to handle additional user flows and make API calls.
With the rise of Large Language Models (LLMs), it has opened new avenues for simplifying and enhancing the development of these features for chatbots. LLMs can greatly improve a chatbot’s ability to comprehend and respond to a wide range of queries, helping to manage complex transactions more effectively.
Even though intent-matching chatbot systems already exist to guide users through predefined flows for transactions, LLMs offer significant advantages by maintaining context over multi-turn interactions and handling a wide range of inputs and language variations. Previously, interactions often felt awkward and stilted, as users were required to select options from premade cards or type specific phrases in order to trigger a transaction flow. For example, a slight variation from “Can I make a payment?” to “Let me pay, please” could prevent the transaction flow from triggering. In contrast, LLMs can adapt to various communication styles allowing them to interpret user input that doesn’t fit neatly into predefined intents.
Recognizing this potential, our team decided to leverage LLMs for transaction processing, enabling users to enter transaction flows more naturally and flexibly by breaking down and understanding their intentions. Given that LangChain offers a framework for implementing agentic workflows, we chose to utilize their agent framework to create an intelligent system to process transactions.
In this article, we will also share two use cases we developed that utilize LLM Agents, namely The Department of Statistics (DOS) Statistic Table Builder, and the Natural Conversation Facility Booking chatbot.
All about LangChain
Before we cover how we made use of LLM Agents to perform transactions, we will first share on what is LangChain and why we opted to experiment with this framework.
What is LangChain?
LangChain is an open-source Python framework designed to assist developers in building AI powered applications leveraging LLMs.
Why use LangChain?
The framework helps to simplify the development process by providing abstractions and templates that enable rapid application building, saving time and reducing the need for our development team to code everything from scratch. This allows for us to focus on higher-level functionality and business logic rather than low-level coding details. An example of this is how LangChain helps to streamline third party integration with popular service providers like MongoDB, OpenAI, and AWS, facilitating quicker prototyping and reducing the complexity of integrating various services. These abstractions not only accelerate development but also improve collaboration by providing a consistent structure, allowing our team to efficiently build, test, and deploy AI applications.
What is LangChain’s Agent Framework?
One of the main features of using Langchain is their agent framework. The framework allows for management of intelligent agents that interact with LLMs and other tools to perform complex tasks.
The 3 main components of the framework are
Agents
Agents act as a reasoning engine as they decide the appropriate actions to take and the order to take these actions. They make use of an LLM to make the decisions for them. An agent has an AgentExecutor that calls the agent and executes the tools the agent chooses. It also takes the output of the action and passes it to the agent until the final outcome is reached.
Tools
Tools are interfaces that the agent can make use of. In order to create a tool, a name and description needs to be provided. The description and name of the tool are important as it will be added into the agent prompt. This means that the agent will decide the tool to use based on the name and description provided.
Chains
A chain refer to sequences of calls. The chain can be coded out steps or just a call to an LLM or a tool. Chains can be customized or be used off-the-shelf based on what LangChain provides. A simple example of a chain is LLMChain, a chain that run queries against LLMs.
LangChain in production
How did we use LangChain in VICA?
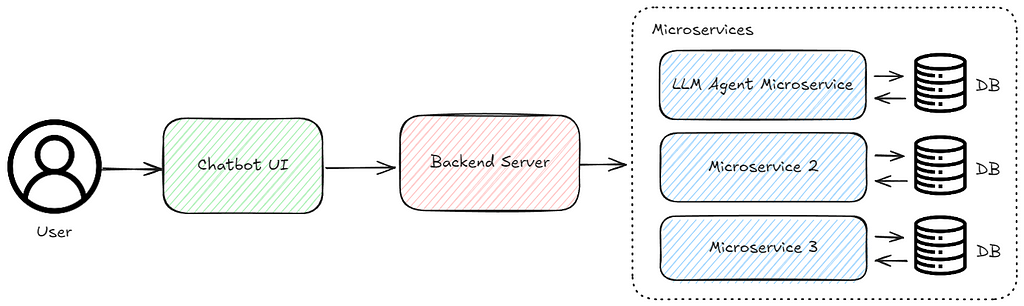
Sample high level microservice architecture diagram, Image by Authors
In VICA, we set up a microservice for LangChain invoked through REST API. This helps to facilitate integration by allowing different components of VICA to communicate with LangChain independently. As a result, we can efficiently build our LLM agent without being affected by changes or development in other components of the system.
LangChain as a framework is pretty extensive when it comes to the LLM space, covering retrieval methods, agents and LLM evaluation. Here are the components we made use of when developing our LLM Agent.
ReAct Agent
In VICA, we made use of a single agent system. The agent makes use of ReAct logic to determine the sequence of actions to take (Yao et al., 2022). This prompt engineering technique will help generate the following:
Thought (Reasoning taken before choosing the action)
Action (Action to take, often a tool)
Action Input (Input to the action)
Observation (Observation from the tool output)
Final Answer (Generative final answer that the agent returns)
> Entering new AgentExecutor chain… The user wants to know the weather today Action: Weather Tool Action Input: "Weather today" Observation: Answer: "31 Degrees Celsius, Sunny" Thought: I now know the final answer. Final Answer: The weather today is sunny at 31 degrees celsius. > Finished chain.
In the above example, the agent was able to understand the user’s intention prior to choosing the tool to use. There was also verbal reasoning being generated that helps the model plan the sequence of action to take. If the observation is insufficient to answer the question given, the agent can cycle to a different action in order to get closer to the final answer.
In VICA, we edited the agent prompt to better suit our use case. The base prompt provided by LangChain (link here) is generally sufficient for most common use cases, serving as an effective starting point. However, it can be modified to enhance performance and ensure greater relevance to specific applications. This can be done by using a custom prompt before passing it as a parameter to the create_react_agent (might be different based on your version of LangChain).
To determine if our custom prompt was an improvement, we employed an iterative prompt engineering approach: Write, Evaluate and Refine (more details here). This process ensured that the prompt generalized effectively across a broad range of test cases. Additionally, we used the base prompt provided by LangChain as a benchmark to evaluate our custom prompts, enabling us to assess their performance with varying additional context across various transaction scenarios.
Custom Tools & Chains (Prompt Chaining)
For the two custom chatbot features in this article, we made use of custom tools that our Agent can make use of to perform transactions. Our custom tools make use of prompt chaining to breakdown and understand a user’s request before deciding what to do in the particular tool.
Prompt chaining is a technique where multiple prompts are used in sequence to handle complex tasks or queries. It involves starting with an initial prompt and using its output as input for subsequent prompts, allowing for iterative refinement and contextual continuity. This method enhances the handling of intricate queries, improves accuracy, and maintains coherence by progressively narrowing down the focus.
For each transaction use case, we broke the process into multiple steps, allowing us to give clearer instructions to the LLM at each stage. This method improves accuracy by making tasks more specific and manageable. We also can inject localized context into the prompts, which clarifies the objectives and enhances the LLM’s understanding. Based on the LLM’s reasoning, our custom chains will make requests to external APIs to gather data to perform the transaction.
At every step of prompt chaining, it is crucial to implement error handling, as LLMs can sometimes produce hallucinations or inaccurate responses. By incorporating error handling mechanisms such as validation checks, we identified and addressed inconsistencies or errors in the outputs. This allowed us to generate fallback responses to our users that explained what the LLM failed to reason at.
Lastly, in our custom tool, we refrained from simply using the LLM generated output as the final response due to the risk of hallucination. As a citizen facing chatbot, it is crucial to prevent our chatbots from disseminating any misleading or inaccurate information. Therefore, we ensure that all responses to user queries are derived from actual data points retrieved through our custom chains. We then format these data points into pre-defined responses, ensuring that users do not see any direct output generated by the LLM.
Challenges of productionizing LangChain
Challenges of using LLMs
Challenge #1: Prompt chaining leads to slow inference time
A challenge with LLMs is their inference times. LLMs have high computational demands due to their large number of parameters and having to be called repeatedly for real time processing, leading to relatively slow inference times (a few seconds per prompt). VICA is a chatbot that gets 700,000 queries in a month. To ensure a good user experience, we aim to provide our responses as quickly as possible while ensuring accuracy.
Prompt chaining increases the consistency, controllability and reliability of LLM outputs. However, each additional chain we incorporate significantly slows down our solution as it necessitates making an extra LLM request. To balance simplicity with efficiency, we set a hard limit on the number of chains to prevent excessive wait times for users. We also opted not to use better performing LLM models such as GPT-4 due to their slower speed, but opted for faster but generally well performing LLMs.
Challenge #2 :Hallucination
As seen in the recent incident with Google’s feature, AI Overview, having LLMs generating outputs can lead to inaccurate or non-factual details. Even though grounding the LLM makes it more consistent and less likely to hallucinate, it does not eliminate hallucination.
As mentioned above, we made use of prompt chaining to perform reasoning tasks for transactions by breaking it down into smaller, easier to understand tasks. By chaining LLMs, we are able to extract the information needed to process complex queries. However, for the final output, we crafted non-generative messages as the final response from the reasoning tasks that the LLM performs. This means that in VICA, our users do not see generated responses from our LLM Agent.
Challenges of using LangChain
Challenge #1: Too much abstraction
The first issue with LangChain is that the framework abstracts away too many details, making it very difficult to customize applications for specific real world use cases.
In order to overcome such limitations, we had to delve into the package and customize certain classes to better suit our use case. For instance, we modified the AgentExecutor class to route the ReAct agent’s action input into the tool that was chosen. This gave our custom tools additional context that helped with extracting information from user queries.
Challenge #2: Lack of documentation
The second issue is the lack of documentation and the constantly evolving framework. This makes development difficult as it takes time to understand how the framework works through looking at the package code. There is also a lack of consistency on how things work, making it difficult to pick things up as you go. Also with constant updates on existing classes, an upgrade in version can result in previously working code suddenly breaking.
If you are planning to use LangChain in production, an advice would be to fix your production version and test before upgrading.
Use case of LLM Agents
Use case #1: Department of Statistics (DOS) Table builder
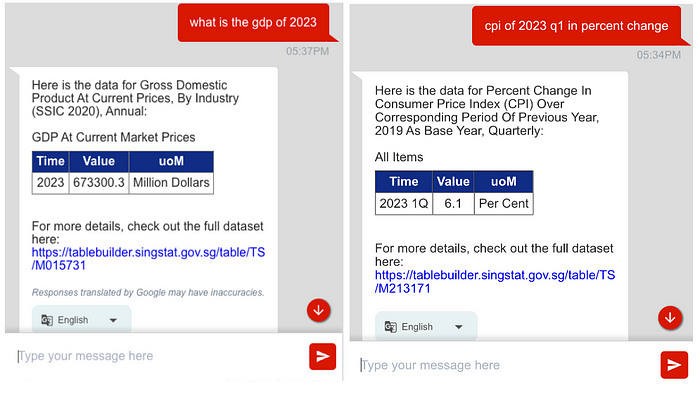
Sample output from DOS Chatbot (examples are for illustrative purposes only), Image by Authors
When it comes to looking at statistical data about Singapore, users can find it difficult to find and analyze the information that they are looking for. To address this issue, we came up with a POC that aims to extract and present statistical data in a table format as a feature in our chatbot.
As DOS’s API is open for public use, we made use of the API documentation that was provided in their website. Using LLM’s natural language understanding capabilities, we passed the API documentation into the prompt. The LLM was then tasked to pick the correct API endpoint based on what the statistical data that the user was asking for. This meant that users could ask for statistical information for annual/half-yearly/quarterly/monthly data in percentage change/absolute values in a given time filter. For example, we are able to query specific information such as “GDP for Construction in 2022” or “CPI in quarter 1 for the past 3 years”.
We then did further prompt chaining to break the task down even more, allowing for more consistency in our final output. The queries were then processed to generate the statistics provided in a table. As all the information were obtained from the API, none of the numbers displayed are generated by LLMs thus avoiding any risk of spreading non-factual information.
Use case #2: Natural Conversation Facility Booking Chatbot
In today’s digital age, the majority of bookings are conducted through online websites. Depending on the user interface, it could be a process that entails sifting through numerous dates to secure an available slot, making it troublesome as you might need to look through multiple dates to find an available booking slot.
Booking through natural conversation could simplify this process. By just typing one line such as “I want to book a badminton court at Fengshan at 9.30 am”, you would be able to get a booking or recommendations from a virtual assistant.
When it comes to booking a facility, there are three things we need from a user:
The facility type (e.g. Badminton, Meeting room, Soccer)
Location (e.g. Ang Mo Kio, Maple Tree Business Centre, Hive)
Date (this week, 26 Feb, today)
Once we are able to detect these information from natural language, we can create a custom booking chatbot that is reusable for multiple use cases (e.g. the booking of hotdesk, booking of sports facilities, etc).
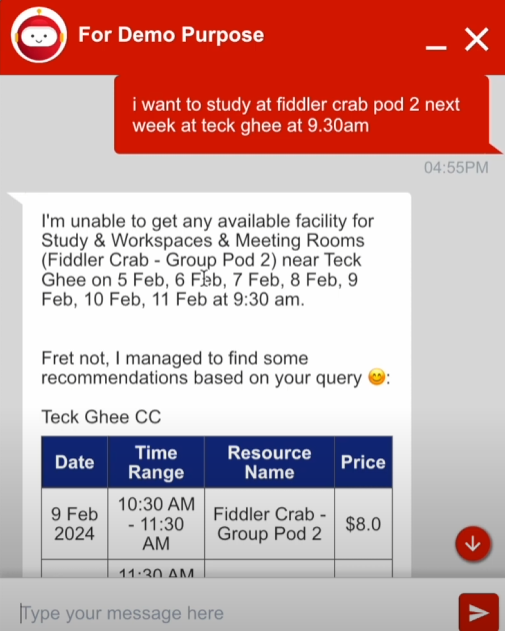
Sample output from Facility Booking Chatbot (examples are for illustrative purposes only), Image by Authors
The above example illustrates a user inquiring about the availability of a football field at 2.30pm. However, the user is missing a required information which is the date. Therefore, the chatbot will ask a clarifying question to obtain the missing date. Once the user provides the date, the chatbot will process this multi-turn conversation and attempt to find any available booking slots that matches the user’s request. As there was a booking slot that fits the user’s exact description, the chatbot will present this information as a table.
Sample recommendation output from Facility Booking Chatbot (examples are for illustrative purposes only), Image by Authors
If there are no available booking slots available, our facility booking chatbot would expand the search, exploring different timeslots or increasing the search date range. It would also attempt to recommend users available booking slots based on their previous query if there their query results in no available bookings. This aims to enhance the user experience by eliminating the need to filter out unavailable dates when making a booking, saving users the hassle and time.
Because we use LLMs as our reasoning engine, an additional benefit is their multilingual capabilities, which enable them to reason and respond to users writing in different languages.
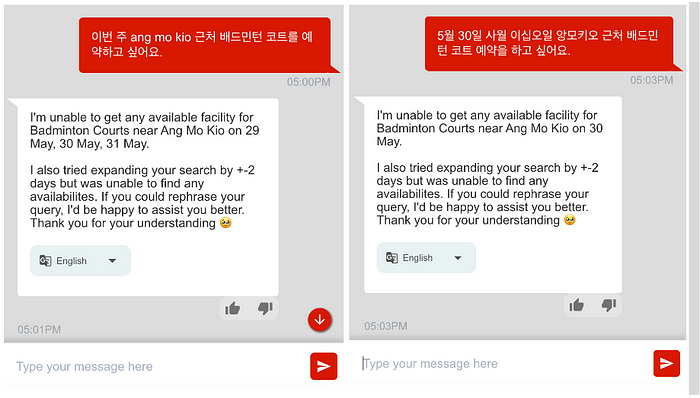
Sample multilingual output from Facility Booking Chatbot (examples are for illustrative purposes only), Image by Authors
The example above illustrates the chatbot’s ability to accurately process the correct facility, dates, and location from the user’s message that was written in Korean to give the appropriate non-generative response although there are no available slots for the date range provided.
What we demonstrated was a brief example of how our LLM Agent handles facility booking transactions. In reality, the actual solution is a lot more complex, being able to give multiple available bookings for multiple locations, handle postal codes, handle locations too far from the stated location, etc. Although we needed to make some modifications to the package to fit our specific use case, LangChain’s Agent Framework was useful in helping us chain multiple prompts together and use their outputs in the ReAct Agent.
Additionally, we designed this customized solution to be easily extendable to any similar booking system that requires booking through natural language.
Conclusion
In this first part of our series, we explored how GovTech’s Virtual Intelligent Chat Assistant (VICA) leverages LLM Agents to enhance chatbot capabilities, particularly for transaction-based chatbots.
By integrating LangChain’s Agent Framework into VICA’s architecture, we demonstrated its potential through the Department of Statistics (DOS) Table Builder and Facility Booking Chatbot use cases. These examples highlight how LangChain can streamline complex transaction interactions, enabling chatbots to handle transaction related tasks like data retrieval and booking through natural conversation.
LangChain offers solutions to quickly develop and prototype sophisticated chatbot features, allowing developers to harness the power of large language models efficiently. However, challenges like insufficient documentation and excessive abstraction can lead to increased maintenance efforts as customizing the framework to fit specific needs may require significant time and resources. Therefore, evaluating an in-house solution might offer greater long term customizability and stability.
In the next article, we will be covering how chatbot engines can be improved through understanding multi-turn conversations.
Find out more about VICA
Curious about the potential of AI chatbots? If you are a Singapore public service officer, you can visit our website at https://www.vica.gov.sg/ to create your own custom chatbot and find out more!
Acknowledgements
Special thanks to Wei Jie Kong for establishing requirements for the Facility Booking Chatbot. We also wish to thank Justin Wang and Samantha Yom, our hardworking interns, for their initial work on the DOS Table builder.
References
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629.
This is my third post on the series about penalized regression. In the first one we talked about how to implement a sparse group lasso in python, one of the best variable selection alternatives available nowadays for regression models, and in the second we talked about adaptive estimators, and how they are much better than their traditional counterparts. But today I would like to talk about quantile regression. and delve into the realm of high-dimensional quantile regression using the robust asgl package, focusing on the implementation of quantile regression with an adaptive lasso penalization.
Today we will see:
What is quantile regression
What are the advantages of quantile regression compared to traditional least squares regression
How to implement penalized quantile regression models in python
What is quantile regression
Let’s kick things off with something many of us have probably encountered: least squares regression. This is the classic go-to method when we’re looking to predict an outcome based on some input variables. It works by finding the line (or hyperplane in higher dimensions) that best fits the data by minimizing the squared differences between observed and predicted values. In simpler terms, it’s like trying to draw the smoothest line through a scatterplot of data points. But here’s the catch: it’s all about the mean. Least squares regression focuses solely on modeling the average trend in the data.
So, what’s the issue with just modeling the mean? Well, life isn’t always about averages. Imagine you’re analyzing income data, which is often skewed by a few high earners. Or consider data with outliers, like real estate prices in a neighborhood with a sudden luxury condo development. In these situations, concentrating on the mean can give a skewed view, potentially leading to misleading insights.
Advantages of quantile regression
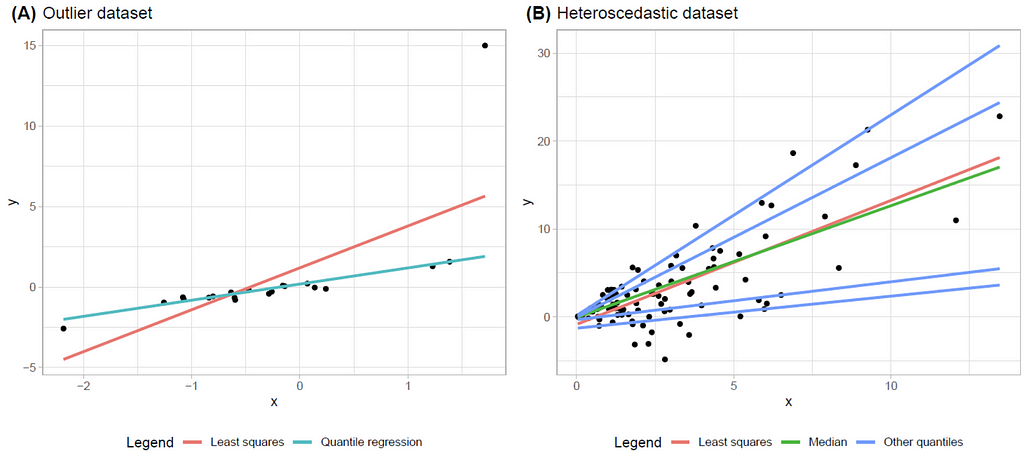
Enter quantile regression. Unlike its least squares sibling, quantile regression allows us to explore various quantiles (or percentiles) of the data distribution. This means we can understand how different parts of the data behave, beyond just the average. Want to know how the bottom 10% or the top 90% of your data are reacting to changes in input variables? Quantile regression has got you covered. It’s especially useful when dealing with data that has outliers or is heavily skewed, as it provides a more nuanced picture by looking at the distribution as a whole. They say one image is worth a thousand words, so let’s see how quantile regression and least squares regression look like in a couple of simple examples.
Image by author: Examples comparing quantile regression and least squares regression.
These two images show very simple regression models with one predictive variable and one response variable. The left image has an outlier on the top right corner (that lonely dot over there). This outlier affects the estimation provided by least squares (the red line), which is way out of way providing very poor predictions. But quantile regression is not affected by outliers, and it’s predictions are spot-on. On the right image we have a dataset that is heteroscedastic. What does that mean? Picture your data forming a cone shape, widening as the value of X increases. More technically, the variability of our response variable isn’t playing by the rules — it expands as X grows. Here, the least squares (red) and quantile regression for the median (green) trace similar paths, but they only tell part of the story. By introducing additional quantiles into the mix(in blue, 10%, 25%, 75% and 90%) we are able to capture how our data dances across the spectrum and see its behavior.
Implementations of quantile regression
High-dimensional scenarios, where the number of predictors exceeds the number of observations, are increasingly common in today’s data-driven world, popping up in fields like genomics, where thousands of genes might predict a single outcome, or in image processing, where countless pixels contribute to a single classification task. These complex situations demand the use of penalized regression models to manage the multitude of variables effectively. However, most existing software in R and Python offers limited options for penalizing quantile regression in such high-dimensional contexts.
This is where my Python package, asgl, appears. asgl package provides a comprehensive framework for fitting various penalized regression models, including sparse group lasso and adaptive lasso — techniques I’ve previously talked about in other posts. It is built on cutting-edge research and offers full compatibility with scikit-learn, allowing seamless integration with other machine learning tools.
Example (with code!)
Let’s see how we can use asgl to perform quantile regression with an adaptive lasso penalization. First, ensure the asgl library is installed:
pip install asgl
Next, we’ll demonstrate the implementation using synthetic data:
import numpy as np from sklearn.datasets import make_regression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_absolute_error from asgl import Regressor
# Generate synthetic data X, y = make_regression(n_samples=100, n_features=200, n_informative=10, noise=0.1, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define and train the quantile regression model with adaptive lasso model = Regressor(model='qr', penalization='alasso', quantile=0.5)
# Fit the model model.fit(X_train, y_train)
# Make predictions predictions = model.predict(X_test)
# Evaluate the model mae = mean_absolute_error(y_test, predictions) print(f'Mean Absolute Error: {mse:.3f}')
In this example, we generate a dataset with 100 samples and 200 features, where only 10 features are truly informative making it a high dimensional regression problem). The Regressor class from the asgl package is configured to perform quantile regression (by selecting model=’qr’) for the median (by selecting quantile=0.5). If we are interested in other quantiles, we just need to set the new quantile value somewhere in the (0, 1) interval. We solve an adaptive lasso penalization (by selecting penalization=’alasso’), and we could optimize other aspects of the model like how the adaptive weights are estimated etc, or use the default configuration.
Advantages of asgl
Let me finish by summarising the benefits of asgl:
Scalability: The package efficiently handles high-dimensional datasets, making it suitable for applications in a wide range of scenarios.
Flexibility: With support for various models and penalizations, asgl caters to diverse analytical needs.
Integration: Compatibility with scikit-learn simplifies model evaluation and hyperparameter tuning
And that’s it on this post about quantile regression! By squashing the average and exploring the full distribution of the data, we open up new possibilities for data-driven decision-making. Stay tuned for more insights into the world of penalized regression and the asgl library.
This post demonstrates how you can bring your existing SageMaker Data Wrangler flows—the instructions created when building data transformations—from SageMaker Studio Classic to SageMaker Canvas. We provide an example of moving files from SageMaker Studio Classic to Amazon Simple Storage Service (Amazon S3) as an intermediate step before importing them into SageMaker Canvas.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.