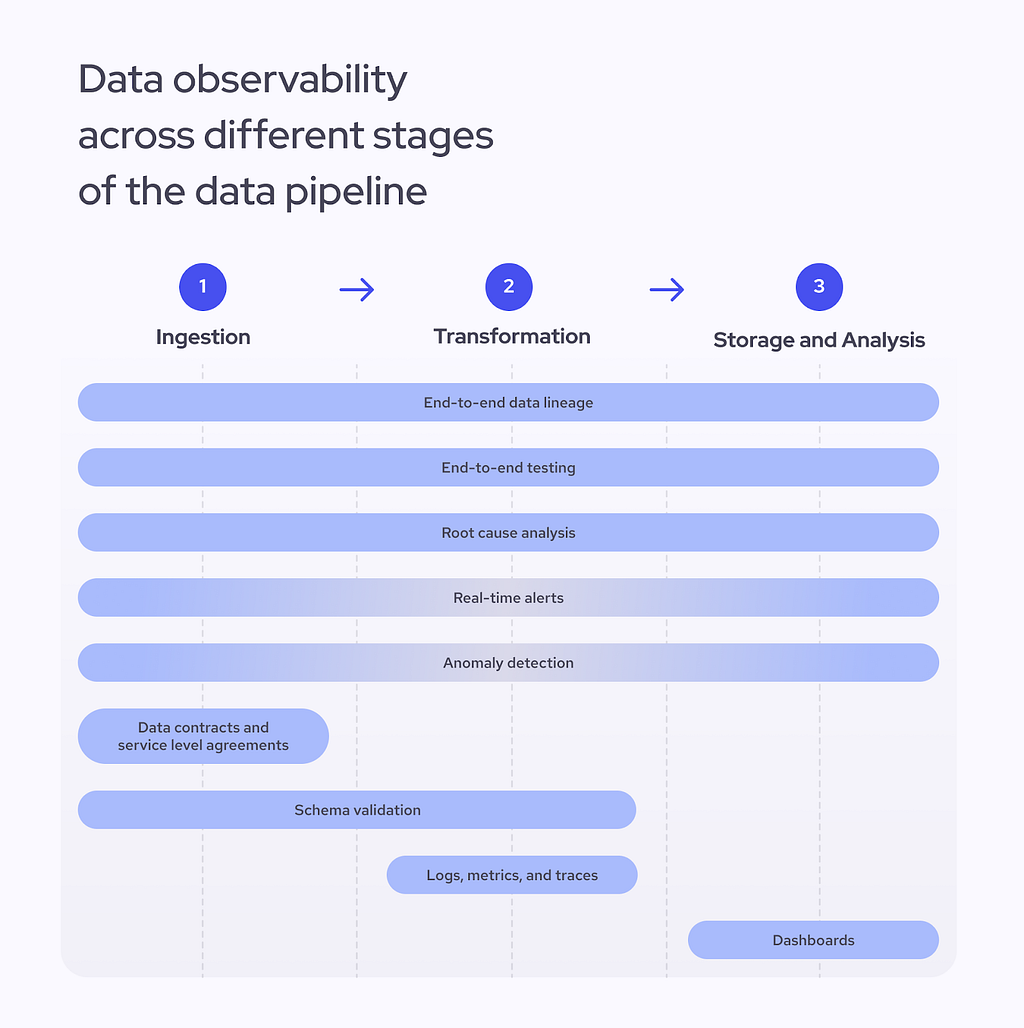
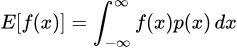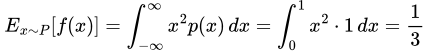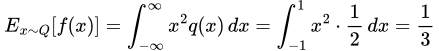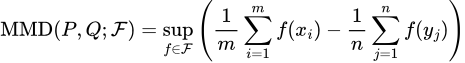A quick-start tutorial
The landscape of artificial intelligence (AI), particularly in Generative AI, has seen significant advancements recently. Large Language Models (LLMs) have been truly transformative in this regard. One popular approach to building an LLM application is Retrieval Augmented Generation (RAG), which combines the ability to leverage an organization’s data with the generative capabilities of these LLMs. Agents are a popular and useful way to introduce autonomous behaviour into LLM applications.
What is Agentic RAG?
Agentic RAG represents an advanced evolution in AI systems, where autonomous agents utilize RAG techniques to enhance their decision-making and response abilities. Unlike traditional RAG models, which often rely on user input to trigger actions, agentic RAG systems adopt a proactive approach. These agents autonomously seek out relevant information, analyse it and use it to generate responses or take specific actions. An agent is equipped with a set of tools and can judiciously select and use the appropriate tools for the given problem.
This proactive behaviour is particularly valuable in many use cases such as customer service, research assistance, and complex problem-solving scenarios. By integrating the generative capability of LLMs with advanced retrieval systems agentic RAG offers a much more effective AI solution.
Key Features of RAG Using Agents
1.Task Decomposition:
Agents can break down complex tasks into manageable subtasks, handling retrieval and generation step-by-step. This approach enhances the coherence and relevance of the final output.
2. Contextual Awareness:
RAG agents maintain contextual awareness throughout interactions, ensuring that retrieved information aligns with the ongoing conversation or task. This leads to more coherent and contextually appropriate responses.
3. Flexible Retrieval Strategies:
Agents can adapt their retrieval strategies based on the context, such as switching between dense and sparse retrieval or employing hybrid approaches. This optimization balances relevance and speed.
4. Feedback Loops:
Agents often incorporate mechanisms to use user feedback for refining future retrievals and generations, which is crucial for applications that require continuous learning and adaptation.
5. Multi-Modal Capabilities:
Advanced RAG agents are starting to support multi-modal capabilities, handling and generating content across various media types (text, images, videos). This versatility is useful for diverse use cases.
6. Scalability:
The agent architecture enables RAG systems to scale efficiently, managing large-scale retrievals while maintaining content quality, making them suitable for enterprise-level applications.
7.Explainability:
Some RAG agents are designed to provide explanations for their decisions, particularly in high-stakes applications, enhancing trust and transparency in the system’s outputs.
This blog post is a getting-started tutorial which guides the user through building an agentic RAG system using Langchain with IBM Watsonx.ai (both for embedding and generative capabilities) and Milvus vector database service provided through IBM Watsonx.data (for storing the vectorized knowledge chunks). For this tutorial, we have created a ReAct agent.
Step 1: Package installation
Let us first install the necessary Python packages. These include Langchain, IBM Watson integrations, milvus integration packages, and BeautifulSoup4 for web scraping.
%pip install langchain
%pip install langchain_ibm
%pip install BeautifulSoup4
%pip install langchain_community
%pip install langgraph
%pip install pymilvus
%pip install langchain_milvus
Step 2: Imports
Next we import the required libraries to set up the environment and configure our LLM.
import bs4
from Langchain.tools.retriever import create_retriever_tool
from Langchain_community.document_loaders import WebBaseLoader
from Langchain_core.chat_history import BaseChatMessageHistory
from Langchain_core.prompts import ChatPromptTemplate
from Langchain_text_splitters import CharacterTextSplitter
from pymilvus import MilvusClient, DataType
import os, re
Here, we are importing modules for web scraping, chat history, text splitting, and vector storage (milvus)
Step 3: Configuring environment variables
We need to set up environment variables for IBM Watsonx, which will be used to access the LLM which is provided by Watsonx.ai
os.environ["WATSONX_APIKEY"] = "<Your_API_Key>"
os.environ["PROJECT_ID"] = "<Your_Project_ID>"
os.environ["GRPC_DNS_RESOLVER"] = "<Your_DNS_Resolver>"
Please make sure to replace the placeholder values with your actual credentials.
Step 4: Initializing Watsonx LLM
With the environment set up, we initialize the IBM Watsonx LLM with specific parameters to control the generation process. We are using the ChatWatsonx class here with mistralai/mixtral-8x7b-instruct-v01 model from watsonx.ai.
from Langchain_ibm import ChatWatsonx
llm = ChatWatsonx(
model_id="mistralai/mixtral-8x7b-instruct-v01",
url="https://us-south.ml.cloud.ibm.com",
project_id=os.getenv("PROJECT_ID"),
params={
"decoding_method": "sample",
"max_new_tokens": 5879,
"min_new_tokens": 2,
"temperature": 0,
"top_k": 50,
"top_p": 1,
}
)
This configuration sets up the LLM for text generation. We can tweak the inference parameters here for generating desired responses. More information about model inference parameters and their permissible values here
Step 5: Loading and splitting documents
We load the documents from a web page and split them into chunks to facilitate efficient retrieval. The chunks generated are stored in the milvus instance that we have provisioned.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1500, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
This code scrapes content from a specified web page, then splits the content into smaller segments, which will later be indexed for retrieval.
Disclaimer: We have confirmed that this site allows scraping, but it’s important to always double-check the site’s permissions before scraping. Websites can update their policies, so ensure your actions comply with their terms of use and relevant laws.
Step 6: Setting up the retriever
We establish a connection to Milvus to store the document embeddings and enable fast retrieval.
from AdpativeClient import InMemoryMilvusStrategy, RemoteMilvusStrategy, BasicRAGHandler
def adapt(number_of_files=0, total_file_size=0, data_size_in_kbs=0.0):
strategy = InMemoryMilvusStrategy()
if(number_of_files > 10 or total_file_size > 10 or data_size_in_kbs > 0.25):
strategy = RemoteMilvusStrategy()
client = strategy.connect()
return client
client = adapt(total_size_kb)
handler = BasicRAGHandler(client)
retriever = handler.create_index(splits)
This function decides whether to use an in-memory or remote Milvus instance based on the size of the data, ensuring scalability and efficiency.
BasicRAGHandler class covers the following functionalities at a high level:
· Initializes the handler with a Milvus client, allowing interaction with the Milvus vector database provisioned through IBM Watsonx.data
· Generates document embeddings, defines a schema, and creates an index in Milvus for efficient retrieval.
· Inserts document, their embeddings and metadata into a collection in Milvus.
Step 7: Defining the tools
With the retrieval system set up, we now define retriever as a tool . This tool will be used by the LLM to perform context-based information retrieval
tool = create_retriever_tool(
retriever,
"blog_post_retriever",
"Searches and returns excerpts from the Autonomous Agents blog post.",
)
tools = [tool]
Step 8: Generating responses
Finally, we can now generate responses to user queries, leveraging the retrieved content.
from langgraph.prebuilt import create_react_agent
from Langchain_core.messages import HumanMessage
agent_executor = create_react_agent(llm, tools)
response = agent_executor.invoke({"messages": [HumanMessage(content="What is ReAct?")]})
raw_content = response["messages"][1].content
In this tutorial (link to code), we have demonstrated how to build a sample Agentic RAG system using Langchain and IBM Watsonx. Agentic RAG systems mark a significant advancement in AI, combining the generative power of LLMs with the precision of sophisticated retrieval techniques. Their ability to autonomously provide contextually relevant and accurate information makes them increasingly valuable across various domains.
As the demand for more intelligent and interactive AI solutions continues to rise, mastering the integration of LLMs with retrieval tools will be essential. This approach not only enhances the accuracy of AI responses but also creates a more dynamic and user-centric interaction, paving the way for the next generation of AI-powered applications.
NOTE: This content is not affiliated with or endorsed by IBM and is in no way an official IBM documentation. It is a personal project pursued out of personal interest, and the information is shared to benefit the community.
Building an Agentic Retrieval-Augmented Generation (RAG) System with IBM Watsonx and Langchain was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Building an Agentic Retrieval-Augmented Generation (RAG) System with IBM Watsonx and Langchain