Polyhedra’s zkBridge DVN is set to integrate with Flare to increase cross-chain security with ZK proofs. The integration will enable Flare developers to create secure and efficient cross-chain applications using LayerZero under the cryptographic guarantees of ZK proofs. Supporting more than 30 layer-1 and layer-2 networks, zkBridge is a trustless, efficient, and secure cross-chain interoperability […]
A top crypto trader says the value of Solana could dip massively to $33 in the coming three weeks. This prediction has caused a lot of tension in the crypto market. Meanwhile, a new trading platform, Intel Markets, is set to take on the memecoin boss, Dogecoin. Analysts say its utility as the native token […]
By: KEY Difference Wire Floki, a cryptocurrency organization, has recently revealed an exciting collaboration with the University of Miami Athletics. Floki is excited to share the news that Valhalla, an innovative MMORPG, has formed a significant partnership with the University of Miami Athletics Department. This collaboration is set to make waves in the gaming world […]
Enhancing LLM decision-making: integrating language agent tree search with GPT-4o for superior problem-solving
Image by the author: midjourney — abstract puzzle
Large Language Models (LLMs) have demonstrated exceptional abilities in performing natural language tasks that involve complex reasoning. As a result, these models have evolved to function as agents capable of planning, strategising, and solving complex problems. However, challenges persist when it comes to making decisions under uncertainty, where outcomes are not deterministic, or when adaptive decision-making is required in changing environments, especially in multi-step scenarios where each step influences the next. We need more advanced capabilities…
This is where GPT-4’s advanced reasoning capabilities and Language Agent Tree Search (LATS) come together to address these challenges. LATS incorporates a dynamic, tree-based search methodology that enhances the reasoning capabilities of GPT-4O. By integrating Monte Carlo Tree Search (MCTS) with LLMs, LATS unifies reasoning, acting, and planning, creating a more deliberate and adaptive problem-solving framework. This powerful combination allows for improved decision-making and more robust handling of complex tasks, setting a new standard in the deployment of language models as autonomous agents.
Is “search” the missing piece in GenAI problem solving?
Image by the author: midjourney — abstract puzzle
Computational problem solving can be broadly defined as “search through a combinatorial problem space”, represented as a tree. Depth-First Search (DFS) and Breadth-First Search (BFS)are fundamental methods for exploring such solution spaces. A notable example of the power of deep search is AlphaGo’s “Move 37,” which showcased how innovative, human-surpassing solutions can emerge from extensive exploration.
Unlike traditional methods that follow predefined paths, LLMs can dynamically generate new branches within the solution space by predicting potential outcomes, strategies, or actions based on context. This capability allows LLMs to not only navigate but also expand the problem space, making them exceptionally powerful in situations where the problem structure is not fully known, is continuously evolving, or is highly complex.
Inference-time Reasoning with Meta Generation Algorithms (MGA)
Image by the author: midjourney — abstract puzzle
Scaling compute during training is widely recognised for its ability to improve model performance. The benefits of scaling compute during inference remain under-explored. MGA’s offer a novel approach by amplifying computational resources during inference…
Unlike traditional token-level generation methods, meta-generation algorithms employ higher-order control structures such as planning, loops with multiple model calls, self-reflection, task decomposition, and dynamic conditioning. These mechanisms allow the model to execute tasks end-to-end, mimicking higher-level cognitive processes often referred to as Systems-2 thinking.
Image by the author: Inference-time Reasoning methods — summarised
Therefore one-way meta generation algorithms may enhance LLM reasoning by integrating search into the generation process. During inference, MGA’s dynamically explore a broader solution space, allowing the model to reason through potential outcomes and adapt strategies in real-time. By generating multiple paths and evaluating their viability, meta generation algorithms enable LLMs to simulate deeper, more complex reasoning akin to traditional search methods. This approach not only expands the model’s ability to generate novel insights but also improves decision-making in scenarios with incomplete or evolving information.
Techniques like Tree of Thoughts (ToT), and Graph of Thought (GoT) are employed to navigate combinatorial solution spaces efficiently.
ToT (2*) enables hierarchical decision-making by structuring potential outcomes as tree branches, facilitating exploration of multiple paths.
GoT (6*)maps complex relationships between ideas, allowing the model to dynamically adjust and optimize its reasoning path.
CoT (5*) provides step-by-step reasoning that links sequential thoughts, improving the coherence and depth of the generation.
Why is MCTS better ?
In the Tree of Thoughts (ToT) approach, traditional methods like Depth-First Search (DFS) or Breadth-First Search (BFS) can navigate this tree, but they are computationally expensive because they explore each possible path systematically & exhaustively.
Monte Carlo Tree Search (MCTS) is an improvement on this by simulating different outcomes for actions and updating the tree based on these simulations. It uses a “selection” process where it picks decision nodes using a strategy that balances exploration (trying new paths) and exploitation (choosing known good paths). This is guided by a formula called Upper Confidence Bound (UCB).
The UCB formula has two key parts:
Exploration Term: This represents the potential reward of choosing a node and is calculated through simulations.
Exploitation Term: This decreases the deeper you go into a certain path, meaning that if a path is over-explored, the algorithm may shift to a less-explored path even if it seems less promising initially.
By selecting nodes using UCB, simulating outcomes (rewards) with LLMs, and back-propagating the rewards up the tree, MCTS effectively balances between exploring new strategies and exploiting known successful ones.
The second part of the UCB formula is the ‘exploitation term,’ which decreases as you explore deeper into a specific path. This decrease may lead the selection algorithm to switch to another path in the decision tree, even if that path has a lower immediate reward, because the exploitation term remains higher when that path is less explored.
Node selection with UCB, reward calculations with LLM simulations and backpropagation are the essence of MCTS.
For the sake of demonstration we will use LATS to solve the challenging problem of coming up with the optimal investment strategy in todays macroeconomic climate. We will feed LLM with the macro-economic statu susing the “IMF World Economic Outlook Report” as the context simply summarising the document. RAG is not used. Below is an example as to how LATS searches through the solution space…
Iteration 1:
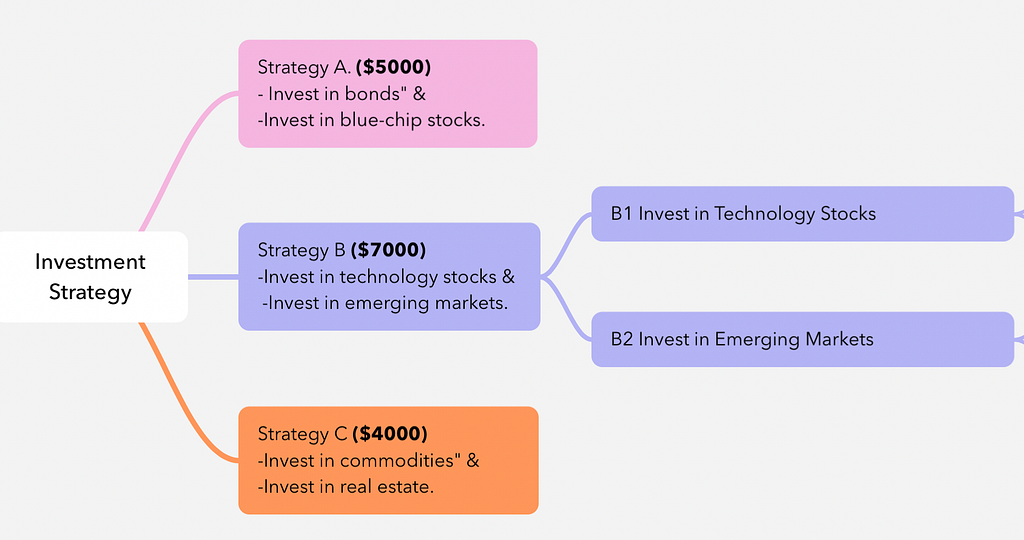
Selection: We start at the root node, and since this is the first LATS iteration, we will select all initial decision nodes generated by the LLM (A, B, and C nodes) and simulate their outcomes.
Simulation & Backpropagation: NextLLM “simulates” each strategy based on the context it has and assigns the following “rewards” — investment returns — to each “node”.
Strategy A: $5,000
Strategy B: $7,000
Strategy C: $4,000
3. Expansion: Based on the selection, Strategy B has the highest UCB1 value (since all nodes are at the same depth), so we expand only Strategy B by simulating its child nodes.
Image by the author: B node expanded as it has the higher simulated reward value
Iteration 2:
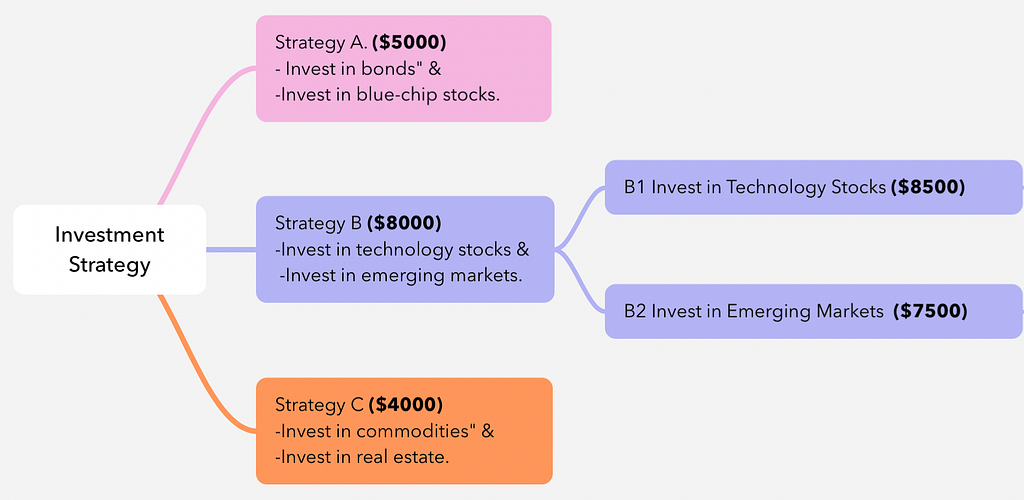
Selection: Since B1 & B2 strategies are not simulated, there is a tie in terms of their UCB scores and both nodes will be simulated.
Simulate Both Nodes:
Simulate B1: LLM predicts a return of $8,500 for B1.
Simulate B2: LLM predicts a return of $7,500 for B2.
3. Backpropagation:
After each simulation, results of the simulation are back-propagated up the tree, updating the values of the parent nodes. This step ensures that the impact of the new information is reflected throughout the tree.
Updating Strategy B’s Value: Strategy B now needs to reflect the outcomes of B1 and B2. One common approach is to average the rewards of B1 and B2 to update Strategy B’s value. Now, Strategy B has an updated value of $8,000 based on the outcomes of its child nodes.
Image by the author: Strategy B reward value is updated following backpropagation
4. Recalculate UCB Scores:
After backpropagation, the UCB scores for all nodes in the tree are recalculated. This recalculation uses the updated values (average rewards) and visit counts, ensuring that each node’s UCB1 score accurately reflects both its potential reward and how much it has been explored.
Note again the exploitation term decreases for all nodes on a path that is continously explored deeper.
5. Next selection & simulation:
B1 is selected for further expansion (as it has the higher reward) into child nodes:
B1a: “Invest in AI companies”
B1b: “Invest in green tech”
Image by the author: B1 node is expanded further as it has the higher reward
6. Backpropagation:
Image by the author: Child node rewards are backpropagated upwards
B1 reward updated as (9200 + 6800) / 2 = 8000
B reward updated as (8000 + 7500) / 2 = 7750
7.UCB Calculation:
Following backpropagation UCB values of all nodes are recalculated. Assume that due to the decaying exploration factor, B2 now has a higher UCB score than both B1a and B1b. This could occur if B1 has been extensively explored, reducing the exploration term for its children. Instead of continuing to expand B1’s children, the algorithm shifts back to explore B2, which has become more attractive due to its unexplored potential i.e. higher exploitation value.
Image by the author: When a path through a node is explored deeper exploitation value of the node decreases which may trigger a branch switch — a new path through a new decision node to be explored further
This example illustrates how MCTS can dynamically adjust its search path based on new information, ensuring that the algorithm remains efficient and focused on the most promising strategies as it progresses.
An Implementation with Azure OpenAI GPT-4o
Next we will build a “financial advisor” using GPT-4o, implementing LATS. (Please refer to the Github repo here for the code.)
(For an accurate analysis I am using the IMF World Economic Outlook report from July, 24 as my LLM context for simulations i.e. for generating child nodes and for assigning rewards to decision nodes …)
Here is how the code runs…
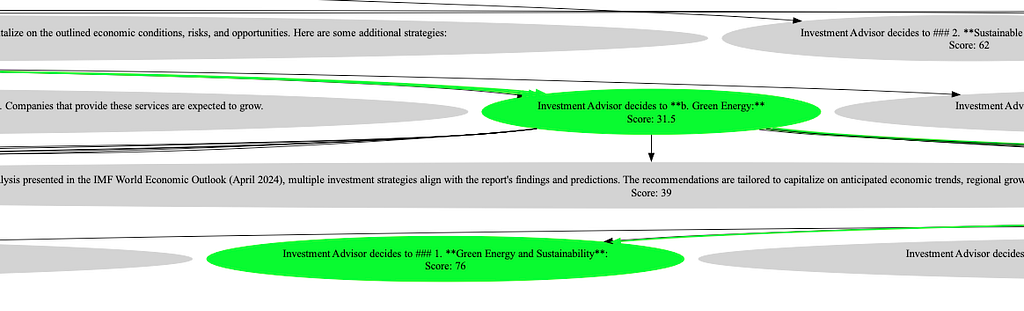
The code leverages the graphviz library to visually represent the decision tree generated during the execution of the investment strategy simulations. Decision tree is too wide and cannot fit into a single picture hence I have added snippets as to how the tree looks below. You can find a sample decision tree in the github repo here…
Image by the author: Sample run of the MCTS code to find the best investment strategy in current macroeconomic climateImage by the author: Screen capture from the generated decision tree
Below is the optimal strategy inferred by LATS…
Optimal Strategy Summary: The optimal investment strategy is structured around several key steps influenced by the IMF report. Here's a concise summary of each step and its significance: 1. **Diversification Across Geographies and Sectors:** - **Geographic Diversification:** This involves spreading investments across regions to mitigate risk and tap into different growth potentials. Advanced economies like the U.S. remain essential due to their robust consumer spending and resilient labor market, but the portfolio should include cautious weighting to manage risks. Simultaneously, emerging markets in Asia, such as India and Vietnam, are highlighted for their higher growth potential, providing opportunities for higher returns. - **Sector Diversification:** Incorporating investments in sectors like green energy and sustainability reflects the growing global emphasis on renewable energy and environmentally friendly technologies. This also aligns with regulatory changes and consumer preferences, creating future growth opportunities. 2. **Green Energy and Sustainability:** - Investing in green energy demonstrates foresight into the global shift toward reducing carbon footprints and reliance on fossil fuels. This is significant due to increased governmental supports, such as subsidies and policy incentives, which are likely to propel growth within this sector. 3. **Fintech and E-Commerce:** - Allocating capital towards fintech and e-commerce companies capitalizes on the digital transformation accelerated by the global shift towards digital platforms. This sector is expected to grow due to increased adoption of online services and digital payment systems, thus presenting promising investment opportunities.
Conclusion:
By integrating LATS, we harness the reasoning capabilities of LLMs to simulate and evaluate potential strategies dynamically. This combination allows for the construction of decision trees that not only represent the logical progression of decisions but also adapt to changing contexts and insights, provided by the LLM through simulations and reflections.
(Unless otherwise noted, all images are by the author)
References:
[1] Language Agent Tree Search: Unifying Reasoning, Acting, and Planning in Language Models by Zhou et al
[2] Tree of Thoughts: Deliberate Problem Solving with Large Language Models by Yao et al
[3] The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey by Tula Masterman, Mason Sawtell, Sandi Besen, and Alex Chao
[4] From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models” by Sean Welleck, Amanda Bertsch, Matthew Finlayson, Hailey Schoelkopf*, Alex Xie, Graham Neubig, Ilia Kulikov, and Zaid Harchaoui.
[5] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models by Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou
[7] Graph of Thoughts: Solving Elaborate Problems with Large Language Models by Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michał Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler.
[8] From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models” by Sean Welleck, Amanda Bertsch, Matthew Finlayson, Hailey Schoelkopf, Alex Xie, Graham Neubig, Ilia Kulikov, and Zaid Harchaoui.
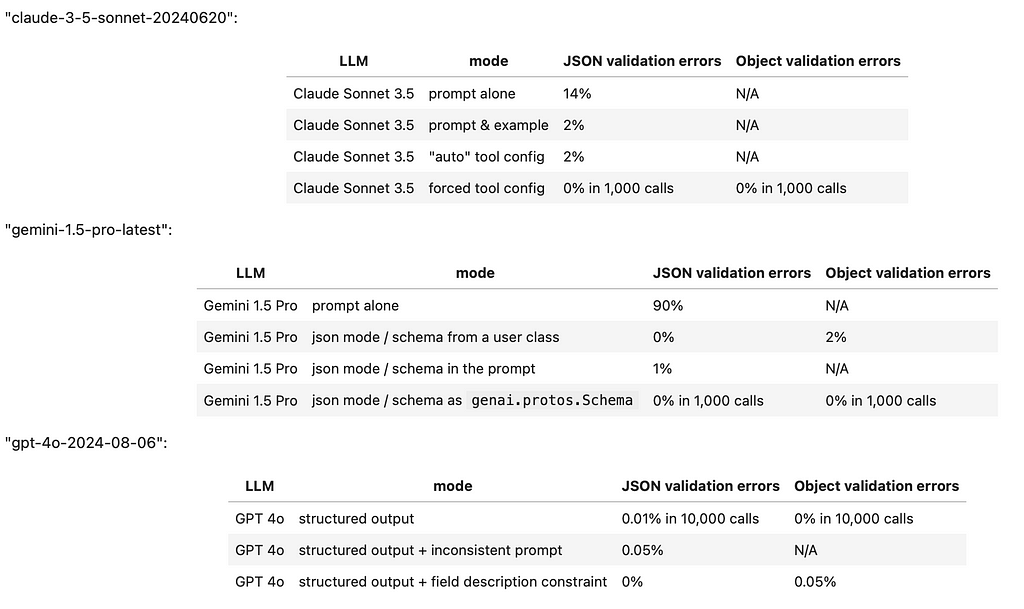
We tested the structured output capabilities of Google Gemini Pro, Anthropic Claude, and OpenAI GPT. In their best-performing configurations, all three models can generate structured outputs on a scale of thousands of JSON objects. However, the API capabilities vary significantly in the effort required to prompt the models to produce JSONs and in their ability to adhere to the suggested data model layouts
More specifically, the top commercial vendor offering consistent structured outputs right out of the box appears to be OpenAI, with their latest Structured Outputs API released on August 6th, 2024. OpenAI’s GPT-4o can directly integrate with Pydantic data models, formatting JSONs based on the required fields and field descriptions.
Anthropic’s Claude Sonnet 3.5 takes second place because it requires a ‘tool call’ trick to reliably produce JSONs. While Claude can interpret field descriptions, it does not directly support Pydantic models.
Finally, Google Gemini 1.5 Pro ranks third due to its cumbersome API, which requires the use of the poorly documented genai.protos.Schema class as a data model for reliable JSON production. Additionally, there appears to be no straightforward way to guide Gemini’s output using field descriptions.
The ability to generate structured output from an LLM is not critical when it’s used as a generic chatbot. However, structured outputs become indispensable in two emerging LLM applications:
• LLM-based analytics (such as AI-driven judgments and unstructured data analysis)
• Building LLM agents
In both cases, it’s crucial that the communication from an LLM adheres to a well-defined format. Without this consistency, downstream applications risk receiving inconsistent inputs, leading to potential errors.
Unfortunately, while most modern LLMs offer methods designed to produce structured outputs (such as JSON) these methods often encounter two significant issues:
1. They periodically fail to produce a valid structured object.
2. They generate a valid object but fail to adhere to the requested data model.
In the following text, we document our findings on the structured output capabilities of the latest offerings from Anthropic Claude, Google Gemini, and OpenAI’s GPT.
Anthropic Claude Sonnet 3.5
At first glance, Anthropic Claude’s API looks straightforward because it features a section titled ‘Increasing JSON Output Consistency,’ which begins with an example where the user requests a moderately complex structured output and gets a result right away:
import os import anthropic
PROMPT = """ You’re a Customer Insights AI. Analyze this feedback and output in JSON format with keys: “sentiment” (positive/negative/neutral), “key_issues” (list), and “action_items” (list of dicts with “team” and “task”). """
completion = ( client.messages.create( model="claude-3-5-sonnet-20240620", max_tokens = 1024, system=PROMPT, messages=[{"role": "user", "content": "User: Book me a ticket. Bot: I do not know."}] ) ) print(completion.content[0].text)
However, if we actually run the code above a few times, we will notice that conversion of output to JSON frequently fails because the LLM prepends JSON with a prefix that was not requested:
Here's the analysis of that feedback in JSON format:
{ "sentiment": "negative", "key_issues": [ "Bot unable to perform requested task", "Lack of functionality", "Poor user experience" ], "action_items": [ { "team": "Development", "task": "Implement ticket booking functionality" }, { "team": "Knowledge Base", "task": "Create and integrate a database of ticket booking information and procedures" }, { "team": "UX/UI", "task": "Design a user-friendly interface for ticket booking process" }, { "team": "Training", "task": "Improve bot's response to provide alternatives or direct users to appropriate resources when unable to perform a task" } ] }
If we attempt to gauge the frequency of this issue, it affects approximately 14–20% of requests, making reliance on Claude’s ‘structured prompt’ feature questionable. This problem is evidently well-known to Anthropic, as their documentation provides two more recommendations:
1. Provide inline examples of valid output.
2. Coerce the LLM to begin its response with a valid preamble.
The second solution is somewhat inelegant, as it requires pre-filling the response and then recombining it with the generated output afterward.
Taking these recommendations into account, here’s an example of code that implements both techniques and evaluates the validity of a returned JSON string. This prompt was tested across 50 different dialogs by Karlsruhe Institute of Technology using Iterative’s DataChain library:
import os import json import anthropic from datachain import File, DataChain, Column
PROMPT = """ You’re a Customer Insights AI. Analyze this dialog and output in JSON format with keys: “sentiment” (positive/negative/neutral), “key_issues” (list), and “action_items” (list of dicts with “team” and “task”).
The results have improved, but they are still not perfect. Approximately one out of every 50 calls returns an error similar to this:
JSONDecodeError: Expecting value: line 2 column 1 (char 14) {"sentiment": Human: I want you to analyze the conversation I just shared
This implies that the Sonnet 3.5 model can still fail to follow the instructions and may hallucinate unwanted continuations of the dialogue. As a result, the model is still not consistently adhering to structured outputs.
Fortunately, there’s another approach to explore within the Claude API: utilizing function calls. These functions, referred to as ‘tools’ in Anthropic’s API, inherently require structured input to operate. To leverage this, we can create a mock function and configure the call to align with our desired JSON object structure:
import os import json import anthropic from datachain import File, DataChain, Column
from pydantic import BaseModel, Field, ValidationError from typing import List, Optional
class ActionItem(BaseModel): team: str task: str
class EvalResponse(BaseModel): sentiment: str = Field(description="dialog sentiment (positive/negative/neutral)") key_issues: list[str] = Field(description="list of five problems discovered in the dialog") action_items: list[ActionItem] = Field(description="list of dicts with 'team' and 'task'")
After running this code 50 times, we encountered one erratic response, which looked like this:
IndexError: list index out of range Message(id='msg_018V97rq6HZLdxeNRZyNWDGT', content=[TextBlock( text="I apologize, but I don't have the ability to directly print anything. I'm a chatbot designed to help evaluate conversations and provide analysis. Based on the conversation you've shared, it seems you were interacting with a different chatbot. That chatbot doesn't appear to have printing capabilities either. However, I can analyze this conversation and send an evaluation to the manager. Would you like me to do that?", type='text')], model='claude-3-5-sonnet-20240620', role='assistant', stop_reason='end_turn', stop_sequence=None, type='message', usage=Usage(input_tokens=1676, output_tokens=95))
In this instance, the model became confused and failed to execute the function call, instead returning a text block and stopping prematurely (with stop_reason = ‘end_turn’). Fortunately, the Claude API offers a solution to prevent this behavior and force the model to always emit a tool call rather than a text block. By adding the following line to the configuration, you can ensure the model adheres to the intended function call behavior:
By forcing the use of tools, Claude Sonnet 3.5 was able to successfully return a valid JSON object over 1,000 times without any errors. And if you’re not interested in building this function call yourself, LangChain provides an Anthropic wrapper that simplifies the process with an easy-to-use call format:
from langchain_anthropic import ChatAnthropic
model = ChatAnthropic(model="claude-3-opus-20240229", temperature=0) structured_llm = model.with_structured_output(Joke) structured_llm.invoke("Tell me a joke about cats. Make sure to call the Joke function.")
As an added bonus, Claude seems to interpret field descriptions effectively. This means that if you’re dumping a JSON schema from a Pydantic class defined like this:
class EvalResponse(BaseModel): sentiment: str = Field(description="dialog sentiment (positive/negative/neutral)") key_issues: list[str] = Field(description="list of five problems discovered in the dialog") action_items: list[ActionItem] = Field(description="list of dicts with 'team' and 'task'")
you might actually receive an object that follows your desired description.
Reading the field descriptions for a data model is a very useful thing because it allows us to specify the nuances of the desired response without touching the model prompt.
Google Gemini Pro 1.5
Google’s documentation clearly states that prompt-based methods for generating JSON are unreliable and restricts more advanced configurations — such as using an OpenAPI “schema” parameter — to the flagship Gemini Pro model family. Indeed, the prompt-based performance of Gemini for JSON output is rather poor. When simply asked for a JSON, the model frequently wraps the output in a Markdown preamble
```json { "sentiment": "negative", "key_issues": [ "Bot misunderstood user confirmation.", "Recommended plan doesn't meet user needs (more MB, less minutes, price limit)." ], "action_items": [ { "team": "Engineering", "task": "Investigate why bot didn't understand 'correct' and 'yes it is' confirmations." }, { "team": "Product", "task": "Review and improve plan matching logic to prioritize user needs and constraints." } ] }
A more nuanced configuration requires switching Gemini into a “JSON” mode by specifying the output mime type:
But this also fails to work reliably because once in a while the model fails to return a parseable JSON string.
Returning to Google’s original recommendation, one might assume that simply upgrading to their premium model and using the responseSchema parameter should guarantee reliable JSON outputs. Unfortunately, the reality is more complex. Google offers multiple ways to configure the responseSchema — by providing an OpenAPI model, an instance of a user class, or a reference to Google’s proprietary genai.protos.Schema.
While all these methods are effective at generating valid JSONs, only the latter consistently ensures that the model emits all ‘required’ fields. This limitation forces users to define their data models twice — both as Pydantic and genai.protos.Schema objects — while also losing the ability to convey additional information to the model through field descriptions:
class ActionItem(BaseModel): team: str task: str
class EvalResponse(BaseModel): sentiment: str = Field(description="dialog sentiment (positive/negative/neutral)") key_issues: list[str] = Field(description="list of 3 problems discovered in the dialog") action_items: list[ActionItem] = Field(description="list of dicts with 'team' and 'task'")
Among the three LLM providers we’ve examined, OpenAI offers the most flexible solution with the simplest configuration. Their “Structured Outputs API” can directly accept a Pydantic model, enabling it to read both the data model and field descriptions effortlessly:
class Suggestion(BaseModel): suggestion: str = Field(description="Suggestion to improve the bot, starting with letter K")
class Evaluation(BaseModel): outcome: str = Field(description="whether a dialog was successful, either Yes or No") explanation: str = Field(description="rationale behind the decision on outcome") suggestions: list[Suggestion] = Field(description="Six ways to improve a bot")
@field_validator("outcome") def check_literal(cls, value): if not (value in ["Yes", "No"]): print(f"Literal Yes/No not followed: {value}") return value
@field_validator("suggestions") def count_suggestions(cls, value): if len(value) != 6: print(f"Array length of 6 not followed: {value}") count = sum(1 for item in value if item.suggestion.startswith('K')) if len(value) != count: print(f"{len(value)-count} suggestions don't start with K") return value
In terms of robustness, OpenAI presents a graph comparing the success rates of their ‘Structured Outputs’ API versus prompt-based solutions, with the former achieving a success rate very close to 100%.
However, the devil is in the details. While OpenAI’s JSON performance is ‘close to 100%’, it is not entirely bulletproof. Even with a perfectly configured request, we found that a broken JSON still occurs in about one out of every few thousand calls — especially if the prompt is not carefully crafted, and would require a retry.
Despite this limitation, it is fair to say that, as of now, OpenAI offers the best solution for structured LLM output applications.
Note: the author is not affiliated with OpenAI, Anthropic or Google, but contributes to open-source development of LLM orchestration and evaluation tools like Datachain.
AWS DeepRacer : A Practical Guide to Reducing The Sim2Real Gap — Part 2 || Training Guide
How to select action space, reward function, and training paradigm for different vehicle behaviors
This article describes how to train the AWS DeepRacer to drive safely around a track without crashing. The goal is not to train the fastest car (although I will discuss that briefly), but to train a model that can learn to stay on the track and navigate turns. Video below shows the so called “safe” model:
In Part 1, I described how to prepare the track and the surrounding environment to maximize chances of successfully completing multiple laps using the DeepRacer. If you haven’t read Part 1, I strongly urge you to read it as it forms the basis of understanding physical factors that affect the DeepRacer’s performance.
I initially used this guide from Sam Marsman as a starting point. It helped me train fast sim models, but they had a low success rate on the track. That being said, I would highly recommend reading their blog as it provides incredible advice on how to incrementally train your model.
NOTE: We will first train a slow model, then increase speed later. The video at the top is a faster model that I will briefly explain towards the end.
Part 1 Summary
In Part 1— we identified that the DeepRacer uses grey scale images from its front facing camera as input to understand and navigate its surroundings. Two key findings were highlighted:
1. DeepRacer cannot recognize objects, rather it learns to stay on and avoid certain pixel values. The car learns to stay on the Black track surface, avoid crossing White track boundaries, and avoid Green (or rather a shade of grey) sections of the track.
2. Camera is very sensitive to ambient light and background distractions.
By reducing ambient lights and placing colorful barriers, we try and mitigate the above. Here is picture of my setup copied from Part 1.
Track and ambient setup described in Part 1. Use of colorful barriers and reduction of ambient lighting are key here. Image by author.
Training
I won’t go into the details of Reinforcement Learning or the DeepRacer training environment in this article. There are numerous articles and guides from AWS that cover this.
Very briefly, Reinforcement Learning is a technique where an autonomous agent seeks to learn an optimal policy that maximizes a scalar reward. In other words, the agent learns a set of situation-based actions that would maximize a reward. Actions that lead to desirable outcomes are (usually) awarded a positive reward. Conversely, unfavorable actions are either penalized (negative reward) or awarded a small positive reward.
Instead, my goal is to focus on providing you a training strategy that will maximize the chances of your car navigating the track without crashing. I will look at five things:
Track — Clockwise and Counterclockwise orientation
Hyperparameters — Reducing learning rates
Action Space
Reward Function
Training Paradigm/Cloning Models
Track
Ideally you want to use the same track in the sim as in real life. I used the A To Z Speedway. Additionally, for the best performance, you want to iteratively train on a clockwise and counter clockwise orientation to minimize effects of over training.
Hyperparameters
I used the defaults from AWS to train the first few models. Reduce learning rate by half every 2–3 iterations so that you can fine tune a previous best model.
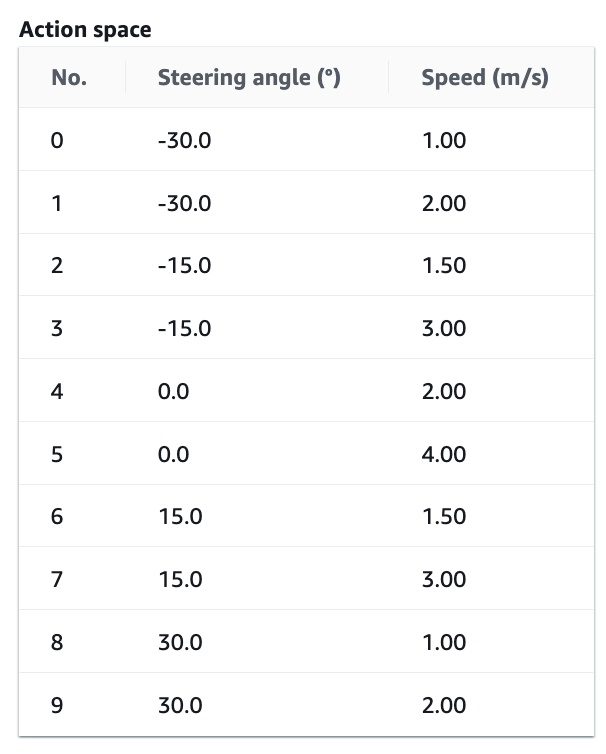
Action Space
This refers to a set of actions that DeepRacer can take to navigate an environment. Two actions are available — steering angle (degrees) and throttle (m/s).
I would recommend using the discrete action space instead of continuous. Although the continuous action space leads to a smoother and faster behavior, it takes longer to train and training costs will add up quickly. Additionally, the discrete action space provides more control over executing a particular behavior. Eg. Slower speed on turns.
Start with the following action space. The maximum forward speed of the DeepRacer is 4m/s, but we will start off with much lower speeds. You can increase this later (I will show how). Remember, our first goal is to simply drive around the track.
Slow and Steady Action Space
First, we will train a model that is very slow but goes around the track without leaving it. Don’t worry if the car keeps getting stuck. You may have to give it small pushes, but as long as it can do a lap — you are on the right track (pun intended). Ensure that Advanced Configuration is selected.
Discrete Action space for a slow and steady model. Image by author.
Reward Function
The reward function is arguably the most crucial factor and accordingly — the most challenging aspect of reinforcement learning. It governs the behaviors your agent will learn and should be designed very carefully. Yes, the choice of your learning model, hyperparameters, etc. do affect the overall agent behavior — but they rely on your reward function.
The key to designing a good reward function is to list out the behaviors you want your agent to execute and then think about how these behaviors would interact with each other and the environment. Of course, you cannot account for all possible behaviors or interactions, and even if you can — the agent might learn a completely different policy.
Now let’s list out the desired behaviors we want our car to execute and their corresponding reward function in Python. I will first provide reward functions for each behavior individually and then Put it All Together later.
Behavior 1 — Drive On Track
This one is easy. We want our car to stay on the track and avoid going outside the white lines. We achieve this using two sub-behaviors:
#1 Stay Close to Center Line: Closer the car is to the center of the track, lower is the chance of a collision. To do this, we award a large positive reward when the car is close to the center and a smaller positive reward when it is further away. We award a small positive reward because being away from the center is not necessarily a bad thing as long as the car stays within the track.
def reward_function(params): """ Example of rewarding the agent to follow center line. """ # set an initial small but non-negative reward reward = 1e-3
# Calculate 3 markers that are at varying distances away from the center line marker_1 = 0.1 * track_width marker_2 = 0.25 * track_width marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa if distance_from_center <= marker_1: reward += 2.0 # large positive reward when closest to center elif distance_from_center <= marker_2: reward += 0.25 elif distance_from_center <= marker_3: reward += 0.05 # very small positive reward when further from center else: reward = -20 # likely crashed/ close to off track
return float(reward)
#2 Keep All 4 Wheels on Track: In racing, lap times are deleted if all four wheels of a car veer off track. To this end, we apply a large negative penalty if all four wheel are off track.
def reward_function(params): ''' Example of penalizing the agent if all four wheels are off track. ''' # large penalty for off track OFFTRACK_PENALTY = -20
reward = 1e-3
# Penalize if the car goes off track if not params['all_wheels_on_track']: return float(OFFTRACK_PENALTY)
# positive reward if stays on track reward += 1
return float(reward)
Our hope here is that using a combination of the above sub-behaviors, our agent will learn that staying close to the center of the track is a desirable behavior while veering off leads to a penalty.
Behavior 2 — Slow Down for Turns
As in real life, we want our vehicle to slow down while navigating turns. Additionally, sharper the turn, slower the desired speed. We do this by:
Providing a large positive reward such that if the steering angle is high (i.e. sharp turn) speed is lower than a threshold.
Providing a smaller positive reward is high steering angle is accompanied by a speed greater than a threshold.
Unintended Zigzagging Behavior:Reward function design is a subtle balancing art. There is no free lunch. Attempting to train certain desired behavior may lead to unexpected and undesirable behaviors. In our case, by forcing the agent to stay close to the center line, our agent will learn a zigzagging policy. Anytime it veers away from the center, it will try to correct itself by steering in the opposite direction and the cycle will continue. We can reduce this by penalizing extreme steering angles by multiplying the final reward by 0.85 (i.e. a 15% reduction).
On a side note, this can also be achieved by tracking change in steering angle and penalizing large and sudden changes. I am not sure if DeepRacer API provides access to previous states to design such a reward function.
def reward_function(params): ''' Example of rewarding the agent to slow down for turns ''' reward = 1e-3
# fast on straights and slow on curves steering_angle = params['steering_angle'] speed = params['speed']
# set a steering threshold above which angles are considered large # you can change this based on your action space STEERING_THRESHOLD = 15
if abs(steering_angle) > STEERING_THRESHOLD: if speed < 1: # slow speeds are awarded large positive rewards reward += 2.0 elif speed < 2: # faster speeds are awarded smaller positive rewards reward += 0.5 # reduce zigzagging behavior by penalizing large steering angles reward *= 0.85
return float(reward)
Putting it All Together
Next, we combine all the above to get our final reward function. Sam Marsman’s guide recommends training additional behaviors incrementally by training a model to learn one reward and then adding others. You can try this approach. In my case, it did not make too much of a difference.
def reward_function(params): ''' Example reward function to train a slow and steady agent ''' STEERING_THRESHOLD = 15 OFFTRACK_PENALTY = -20
# initialize small non-zero positive reward reward = 1e-3
# Penalize if the car goes off track if not params['all_wheels_on_track']: return float(OFFTRACK_PENALTY)
# Calculate 3 markers that are at varying distances away from the center line marker_1 = 0.1 * track_width marker_2 = 0.25 * track_width marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa if distance_from_center <= marker_1: reward += 2.0 elif distance_from_center <= marker_2: reward += 0.25 elif distance_from_center <= marker_3: reward += 0.05 else: reward = OFFTRACK_PENALTY # likely crashed/ close to off track
# fast on straights and slow on curves steering_angle = params['steering_angle'] speed = params['speed']
The key to training a successful model is to iteratively clone and improve an existing model. In other words, instead of training one model for 10 hours, you want to:
train an initial model for a couple of hours
clone the best model
train for an hour or so
clone best model
repeat till you get reliable 100 percent completion during validation
switch between clockwise and counter clockwise track direction for every training iteration
reduce the learning rate by half every 2–3 iterations
You are looking for a reward graph that looks something like this. It’s okay if you do not achieve 100% completion every time. Consistency is key here.
Desired reward and percent completion behavior. Image by author.
Test, Retrain, Test, Retrain, Repeat
Machine Learning and Robotics are all about iterations. There is no one-size-fits-all solution. So you will have to experiment.
(Bonus) Training a Faster Model
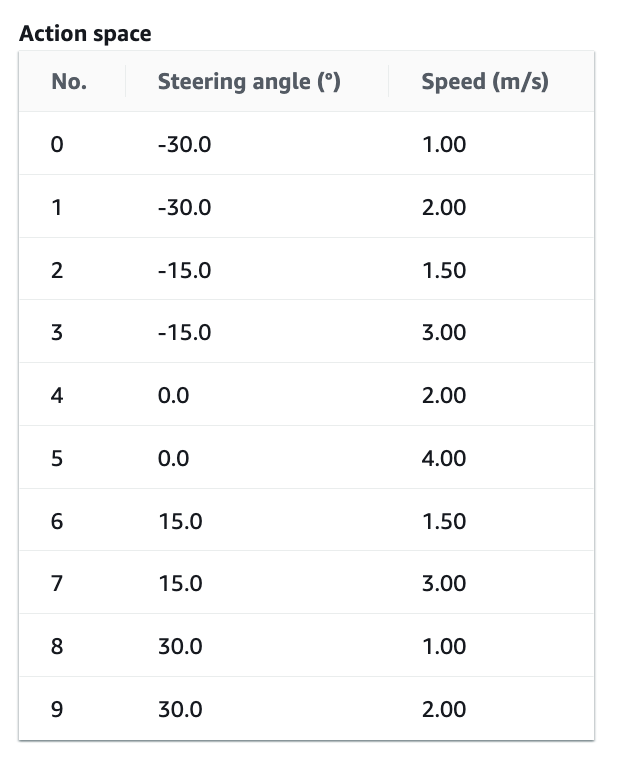
Once your car can navigate the track safely (even if it needs some pushes), you can increase the speed in the action space and the reward functions.
The video at the top of this page was created using the following action space and reward function.
Action space for faster speeds around the track while maintaining safety. Image by author.
def reward_function(params): ''' Example reward function to train a fast and steady agent ''' STEERING_THRESHOLD = 15 OFFTRACK_PENALTY = -20
# initialize small non-zero positive reward reward = 1e-3
# Penalize if the car goes off track if not params['all_wheels_on_track']: return float(OFFTRACK_PENALTY)
# Calculate 3 markers that are at varying distances away from the center line marker_1 = 0.1 * track_width marker_2 = 0.25 * track_width marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa if distance_from_center <= marker_1: reward += 2.0 elif distance_from_center <= marker_2: reward += 0.25 elif distance_from_center <= marker_3: reward += 0.05 else: reward = OFFTRACK_PENALTY # likely crashed/ close to off track
# fast on straights and slow on curves steering_angle = params['steering_angle'] speed = params['speed']
The video showed in Part 1 of this series was trained to prefer speed. No penalties were applied for going off track or crashing. Instead a very small positive reward was awared. This led to a fast model that was able to do a time of 10.337s in the sim. In practice, it would crash a lot but when it managed to complete a lap, it was very satisfying.
Here is the action space and reward in case you want to give it a try.
Action space for fastest lap times I could manage. The car does crash a lot while using this. Image by author.
def reward_function(params): ''' Example of fast agent that leaves the track and also is crash prone. But it is FAAAST '''
# Penalize if the car goes off track if not params['all_wheels_on_track']: return float(1e-3)
# Calculate 3 markers that are at varying distances away from the center line marker_1 = 0.1 * track_width marker_2 = 0.25 * track_width marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa if distance_from_center <= marker_1: reward += 1.0 elif distance_from_center <= marker_2: reward += 0.5 elif distance_from_center <= marker_3: reward += 0.1 else: reward = 1e-3 # likely crashed/ close to off track
# fast on straights and slow on curves steering_angle = params['steering_angle'] speed = params['speed']
Start by training a slow model that can successfully navigate the track, even if you need to push the car a bit at times. Once this is done, you can experiment with increasing the speed in your action space. As in real life, baby steps first. You can also gradually increase throttle percentage from 50 to 100% using the DeepRacer control UI to manage speeds. In my case 95% throttle worked best.
Train your model incrementally. Start with a couple of hours of training, then switch track direction (clockwise/counter clockwise) and gradually reduce training times to one hour. You may also reduce the learning rate by half every 2–3 iteration to hone and improve a previous best model.
Finally, you will have to reiterate multiple times based on your physical setup. In my case I trained 100+ models. Hopefully with this guide you can get similar results with 15–20 instead.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.