The launch of VulcanX on the DTX Exchange has ignited a surge, leading to a $300K rally in just one day. While excitement builds around this milestone, major cryptocurrencies like Dogecoin (DOGE) and Solana (SOL) have experienced slight declines due to various factors. This article explores the impact of VulcanX’s launch, how it captured market […]
Solana’s immediate prospects look positive as a technical analysis indicator, known to mark inflection points in the market, is flashing a bullish signal.
Rexas Finance (RXS) is set to revolutionize the world of Real World Asset (RWA) tokenization with its upcoming presale, scheduled to begin on September 8, 2024. This highly anticipated event marks a significant milestone for Rexas Finance as it continues to push the boundaries of blockchain technology and redefine asset management. The initiative promises to […]
Python has become the de facto programming language for AI and data science. Although no-code solutions exist, learning how to code is still essential to build fully custom AI projects or products. In this article, I share a beginner QuickStart guide to AI development with Python. I’ll cover the basics and then share a concrete example with code.
Image from Canva.
Python is a programming language, i.e., a way to give computers precise instructions to do things we can’t or don’t want to do [1].
This is handy when automating a unique task without an off-the-shelf solution. For example, if I wanted to automate writing and sending personalized meeting follow-ups, I could write a Python script to do this.
With tools like ChatGPT, it’s easy to imagine a future where one could describe any bespoke task in plain English, and the computer would just do it. However, such a consumer product does not exist right now. Until such products become available, there is tremendous value in knowing (at least a little) Python.
Coding is Easier Than Ever
While current AI products (e.g. ChatGPT, Claude, Gemini) haven’t made programming obsolete (yet), they have made it easier than ever to learn how to code. We all now have a competent and patient coding assistant who is always available to help us learn.
Combined with the “traditional” approach of Googling all your problems, programmers can now move faster. For instance, I generously use ChatGPT to write example code and explain error messages. This accelerates my progress and gives me more confidence when navigating new technology stacks.
Who This is For
I’m writing this with a particular type of reader in mind: those trying to get into AI and have done a little coding (e.g., JS, HTML/CSS, PHP, Java, SQL, Bash/Powershell, VBA) but are new to Python.
I’ll start with Python fundamentals, then share example code for a simple AI project. This is not meant to be a comprehensive introduction to Python. Rather, it’s meant to give you just enough to code your first AI project with Python fast.
About me — I’m a data scientist and self-taught Python programmer (5 years). While there’s still much for me to learn about software development, here I cover what I think are the bare essentials of Python for AI/data science projects based on my personal experience.
Installing Python
Many computers come with Python pre-installed. To see if your machine has it, go to your Terminal (Mac/Linux) or Command Prompt (Windows), and simply enter “python”.
Using Python in Terminal. Image by author.
If you don’t see a screen like this, you can download Python manually (Windows/ Mac). Alternatively, one can install Anaconda, a popular Python package system for AI and data science. If you run into installation issues, ask your favorite AI assistant for help!
With Python running, we can now start writing some code. I recommend running the examples on your computer as we go along. You can also download all the example code from the GitHub repo.
1) Data Types
Strings & Numbers
A data type (or just “type”) is a way to classify data so that it can be processed appropriately and efficiently in a computer.
Types are defined by a possible set of values and operations. For example, strings are arbitrary character sequences (i.e. text) that can be manipulated in specific ways. Try the following strings in your command line Python instance.
"this is a string" >> 'this is a string'
'so is this:-1*!@&04"(*&^}":>?' >> 'so is this:-1*!@&04"(*&^}":>?'
"""and this is too!!11!""" >> 'andn this isn too!!11!'
"we can even " + "add strings together" >> 'we can even add strings together'
Although strings can be added together (i.e. concatenated), they can’t be added to numerical data types like int (i.e. integers) or float (i.e. numbers with decimals). If we try that in Python, we will get an error message because operations are only defined for compatible types.
# we can't add strings to other data types (BTW this is how you write comments in Python) "I am " + 29 >> TypeError: can only concatenate str (not "int") to str
# so we have to write 29 as a string "I am " + "29" >> 'I am 29'
Lists & Dictionaries
Beyond the basic types of strings, ints, and floats, Python has types for structuring larger collections of data.
One such type is a list, an ordered collection of values. We can have lists of strings, numbers, strings + numbers, or even lists of lists.
# a list of strings ["a", "b", "c"]
# a list of ints [1, 2, 3]
# list with a string, int, and float ["a", 2, 3.14]
# a list of lists [["a", "b"], [1, 2], [1.0, 2.0]]
Another core data type is a dictionary, which consists of key-value pair sequences where keys are strings and values can be any data type. This is a great way to represent data with multiple attributes.
# a dictionary {"Name":"Shaw"}
# a dictionary with multiple key-value pairs {"Name":"Shaw", "Age":29, "Interests":["AI", "Music", "Bread"]}
# a list of dictionaries [{"Name":"Shaw", "Age":29, "Interests":["AI", "Music", "Bread"]}, {"Name":"Ify", "Age":27, "Interests":["Marketing", "YouTube", "Shopping"]}]
So far, we’ve seen some basic Python data types and operations. However, we are still missing an essential feature: variables.
Variables provide an abstract representation of an underlying data type instance. For example, I might create a variable called user_name, which represents a string containing my name, “Shaw.” This enables us to write flexible programs not limited to specific values.
# creating a variable and printing it user_name = "Shaw" print(user_name)
#>> Shaw
We can do the same thing with other data types e.g. ints and lists.
# defining more variables and printing them as a formatted string. user_age = 29 user_interests = ["AI", "Music", "Bread"]
print(f"{user_name} is {user_age} years old. His interests include {user_interests}.")
#>> Shaw is 29 years old. His interests include ['AI', 'Music', 'Bread'].
3) Creating Scripts
Now that our example code snippets are getting longer, let’s see how to create our first script. This is how we write and execute more sophisticated programs from the command line.
To do that, create a new folder on your computer. I’ll call mine python-quickstart. If you have a favorite IDE (e.g., the Integrated Development Environment), use that to open this new folder and create a new Python file, e.g., my-script.py. There, we can write the ceremonial “Hello, world” program.
# ceremonial first program print("Hello, world!")
If you don’t have an IDE (not recommended), you can use a basic text editor (e.g. Apple’s Text Edit, Window’s Notepad). In those cases, you can open the text editor and save a new text file using the .py extension instead of .txt.Note: If you use TextEditor on Mac, you may need to put the application in plain text mode via Format > Make Plain Text.
We can then run this script using the Terminal (Mac/Linux) or Command Prompt (Windows) by navigating to the folder with our new Python file and running the following command.
python my-script.py
Congrats! You ran your first Python script. Feel free to expand this program by copy-pasting the upcoming code examples and rerunning the script to see their outputs.
4) Loops and Conditions
Two fundamental functionalities of Python (or any other programming language) are loops and conditions.
Loops allow us to run a particular chunk of code multiple times. The most popular is the for loop, which runs the same code while iterating over a variable.
# a simple for loop iterating over a sequence of numbers for i in range(5): print(i) # print ith element
# for loop iterating over a list user_interests = ["AI", "Music", "Bread"]
for interest in user_interests: print(interest) # print each item in list
# for loop iterating over items in a dictionary user_dict = {"Name":"Shaw", "Age":29, "Interests":["AI", "Music", "Bread"]}
for key in user_dict.keys(): print(key, "=", user_dict[key]) # print each key and corresponding value
The other core function is conditions, such as if-else statements, which enable us to program logic. For example, we may want to check if the user is an adult or evaluate their wisdom.
# check if user is 18 or older if user_dict["Age"] >= 18: print("User is an adult")
# check if user is 1000 or older, if not print they have much to learn if user_dict["Age"] >= 1000: print("User is wise") else: print("User has much to learn")
It’s common to use conditionals within for loops to apply different operations based on specific conditions, such as counting the number of users interested in bread.
# count the number of users interested in bread user_list = [{"Name":"Shaw", "Age":29, "Interests":["AI", "Music", "Bread"]}, {"Name":"Ify", "Age":27, "Interests":["Marketing", "YouTube", "Shopping"]}] count = 0 # intialize count
for user in user_list: if "Bread" in user["Interests"]: count = count + 1 # update count
print(count, "user(s) interested in Bread")
5) Functions
Functions are operations we can perform on specific data types.
We’ve already seen a basic function print(), which is defined for any datatype. However, there are a few other handy ones worth knowing.
# print(), a function we've used several times already for key in user_dict.keys(): print(key, ":", user_dict[key])
# type(), getting the data type of a variable for key in user_dict.keys(): print(key, ":", type(user_dict[key]))
# len(), getting the length of a variable for key in user_dict.keys(): print(key, ":", len(user_dict[key])) # TypeError: object of type 'int' has no len()
We see that, unlike print() and type(), len() is not defined for all data types, so it throws an error when applied to an int. There are several other type-specific functions like this.
# string methods # -------------- # make string all lowercase print(user_dict["Name"].lower())
# make string all uppercase print(user_dict["Name"].upper())
# split string into list based on a specific character sequence print(user_dict["Name"].split("ha"))
# replace a character sequence with another print(user_dict["Name"].replace("w", "whin"))
# list methods # ------------ # add an element to the end of a list user_dict["Interests"].append("Entrepreneurship") print(user_dict["Interests"])
# remove a specific element from a list user_dict["Interests"].pop(0) print(user_dict["Interests"])
# insert an element into a specific place in a list user_dict["Interests"].insert(1, "AI") print(user_dict["Interests"])
# removing a key user_dict.pop("Name") print(user_dict.items())
# adding a key user_dict["Name"] = "Shaw" print(user_dict.items())
While the core Python functions are helpful, the real power comes from creating user-defined functions to perform custom operations. Additionally, custom functions allow us to write much cleaner code. For example, here are some of the previous code snippets repackaged as user-defined functions.
# define a custom function def user_description(user_dict): """ Function to return a sentence (string) describing input user """ return f'{user_dict["Name"]} is {user_dict["Age"]} years old and is interested in {user_dict["Interests"][0]}.'
# print user description description = user_description(user_dict) print(description)
# print description for a new user! new_user_dict = {"Name":"Ify", "Age":27, "Interests":["Marketing", "YouTube", "Shopping"]} print(user_description(new_user_dict))
# define another custom function def interested_user_count(user_list, topic): """ Function to count number of users interested in an arbitrary topic """ count = 0
for user in user_list: if topic in user["Interests"]: count = count + 1
return count
# define user list and topic user_list = [user_dict, new_user_dict] topic = "Shopping"
# compute interested user count and print it count = interested_user_count(user_list, topic) print(f"{count} user(s) interested in {topic}")
6) Libraries, pip, & venv
Although we could implement an arbitrary program using core Python, this can be incredibly time-consuming for some use cases. One of Python’s key benefits is its vibrant developer community and a robust ecosystem of software packages. Almost anything you might want to implement with core Python (probably) already exists as an open-source library.
We can install such packages using Python’s native package manager, pip. To install new packages, we run pip commands from the command line. Here is how we can install numpy, an essential data science library that implements basic mathematical objects and operations.
pip install numpy
After we’ve installed numpy, we can import it into a new Python script and use some of its data types and functions.
import numpy as np
# create a "vector" v = np.array([1, 3, 6]) print(v)
# multiply a "vector" print(2*v)
# create a matrix X = np.array([v, 2*v, v/2]) print(X)
# matrix multiplication print(X*v)
The previous pip command added numpy to our base Python environment. Alternatively, it’s a best practice to create so-called virtual environments. These are collections of Python libraries that can be readily interchanged for different projects.
Here’s how to create a new virtual environment called my-env.
python -m venv my-env
Then, we can activate it.
# mac/linux source my-env/bin/activate
# windows .my-envScriptsactivate.bat
Finally, we can install new libraries, such as numpy, using pip.
pip install pip
Note: If you’re using Anaconda, check out this handy cheatsheet for creating a new conda environment.
Several other libraries are commonly used in AI and data science. Here is a non-comprehensive overview of some helpful ones for building AI projects.
A non-comprehensive overview of Python libs for data science and AI. Image by author.
Example Code: Extracting summary and keywords from research papers
Now that we have been exposed to the basics of Python, let’s see how we can use it to implement a simple AI project. Here, I will use the OpenAI API to create a research paper summarizer and keyword extractor.
Like all the other snippets in this guide, the example code is available at the GitHub repository.
Install Dependencies
We start by installing a few helpful libraries. You can use the same my-env environment we created earlier or make a new one. Then, you can install all the required packages using the requirements.txt file from the {GitHub repo}.
pip install -r requirements.txt
This line of code scans each library listed in requirements.txt and installs each.
Imports
Next, we can create a new Python script and import the needed libraries.
import fitz # PyMuPDF import openai import sys
Next, to use OpenAI’s Python API, we will need to import an AI key. Here’s one way to do that.
from sk import my_sk
# Set up your OpenAI API key openai.api_key = my_sk
Note that sk is not a Python library. Rather, it is a separate Python script that defines a single variable, my_sk, which is a string consisting of my OpenAI API key i.e. a unique (and secret) token allowing one to use OpenAI’s API.
I shared a beginner-friendly introduction to APIs, OpenAI’s API, and setting up an API key in a previous article.
Next, we will create a function that, given the path to a research paper saved as a .pdf file, will extract the abstract from the paper.
# Function to read the first page of a PDF and extract the abstract def extract_abstract(pdf_path):
# Open the PDF file and grab text from the 1st page with fitz.open(pdf_path) as pdf: first_page = pdf[0] text = first_page.get_text("text")
# Extract the abstract (assuming the abstract starts with 'Abstract')
# find where abstract starts start_idx = text.lower().find('abstract')
# end abstract at introduction if it exists on 1st page if 'introduction' in text.lower(): end_idx = text.lower().find('introduction') else: end_idx = None
# extract abstract text abstract = text[start_idx:end_idx].strip()
# if abstract appears on 1st page return it, if not resturn None if start_idx != -1: abstract = text[start_idx:end_idx].strip() return abstract else: return None
Summarize with LLM
Now that we have our abstract text, we can use an LLM to summarize it and generate keywords. Here, I define a function to pass an abstract to OpenAI’s GPT-4o-mini model to do this.
# Function to summarize the abstract and generate keywords using OpenAI API def summarize_and_generate_keywords(abstract):
# Use OpenAI Chat Completions API to summarize and generate keywords prompt = f"Summarize the following paper abstract and generate (no more than 5) keywords:nn{abstract}"
# make api call response = openai.chat.completions.create( model="gpt-4o-mini", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": prompt} ], temperature = 0.25 )
Output: The paper introduces the Transformer, a novel network architecture for sequence transduction tasks that relies solely on attention mechanisms, eliminating the need for recurrent and convolutional structures. The Transformer demonstrates superior performance in machine translation tasks, achieving a BLEU score of 28.4 on the WMT 2014 English-to-German translation and a state-of-the-art score of 41.8 on the English-to-French translation task, while also being more efficient in training time. Additionally, the Transformer shows versatility by successfully applying to English constituency parsing with varying amounts of training data.
Designing asynchronous pipelines for efficient data processing
Note. This article already assumes that you are familiar with callbacks, promises, and have a basic understanding of the asynchronous paradigm in JavaScript.
Introduction
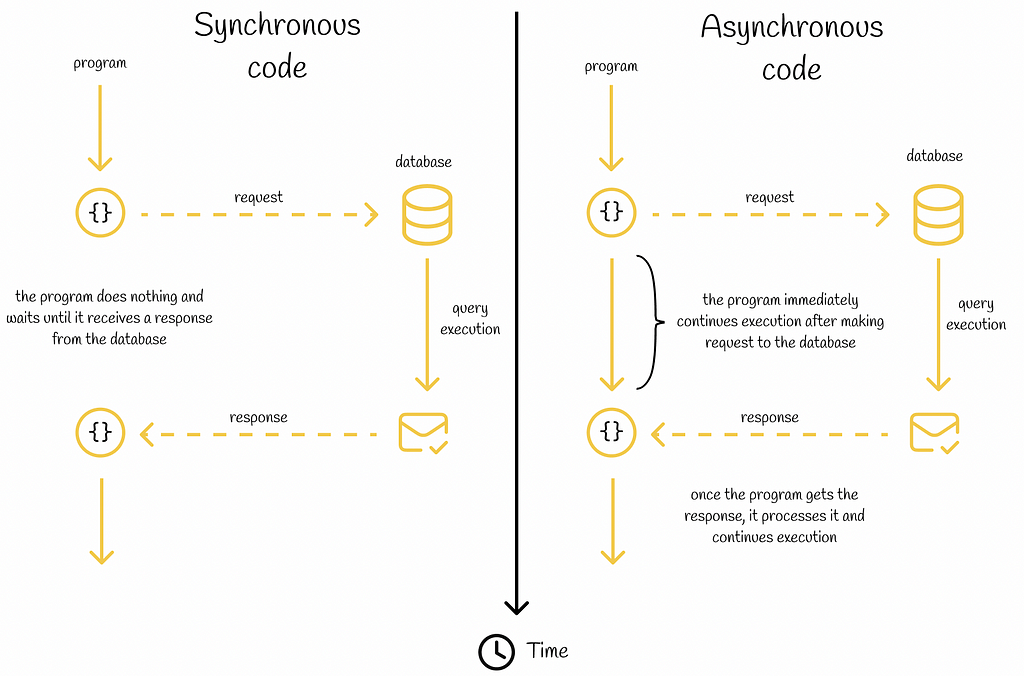
The asynchronous mechanism is one of the most important concepts in JavaScript and programming in general. It allows a program to separately execute secondary tasks in the background without blocking the current thread from executing primary tasks. When a secondary task is completed, its result is returned and the program continues to run normally. In this context, such secondary tasks are called asynchronous.
Asynchronous tasks typically include making requests to external environments like databases, web APIs or operating systems. If the result of an asynchronous operation does not affect the logic of the main program, then instead of just waiting before the task will have completed, it is much better not to waste this time and continue executing primary tasks.
Nevertheless, sometimes the result of an asynchronous operation is used immediately in the next code lines. In such cases, the succeeding code lines should not be executed until the asynchronous operation is completed.
Depending on the program logic, some asynchronous requests can be blocking in regard to the following code
Note. Before getting to the main part of this article, I would like to provide the motivation for why asynchronicity is considered an important topic in Data Science and why I used JavaScript instead of Python to explain the async / await syntax.
# 01. Why to care about asynchronicity in Data Science?
Data engineering is an inseparable part of Data Science, which mainly consists of designing robust and efficient data pipelines. One of the typical tasks in data engineering includes making regular calls to APIs, databases, or other sources to retrieve data, process it, and store it somewhere.
Imagine a data source that encounters network issues and cannot return the requested data immediately. If we simply make the request in code to that service, we will have to wait quite a bit, while doing nothing. Would notit be better to avoid wasting precious processor time and execute another function, for example? This is where the power of asynchronicity comes into play, which will be the central topic of this article!
#02. Why JavaScript?
Nobody will deny the fact that Python is the most popular current choice for creating Data Science applications. Nevertheless, JavaScript is another language with a huge ecosystem that serves various development purposes, including building web applications that process data retrieved from other services. As it turns out, asynchronicity plays one of the most fundamental roles in JavaScript.
Furthermore, compared to Python, JavaScript has richer built-in support for dealing with asynchronicity and usually serves as a better example to dive deeper into this topic.
Finally, Python has a similar async / await construction. Therefore, the information presented in this article about JavaScript can also be transferable to Python for designing efficient data pipelines.
Asynchronous code in JavaScript
In the first versions of JavaScript, asynchronous code was mainly written with callbacks. Unfortunately, it led developers to a well-known problem named “callback hell”. A lot of times asynchronous code written with raw callbacks led to several nested code scopes which were extremely difficult to read. That is why in 2012 the JavaScript creators introduced promises.
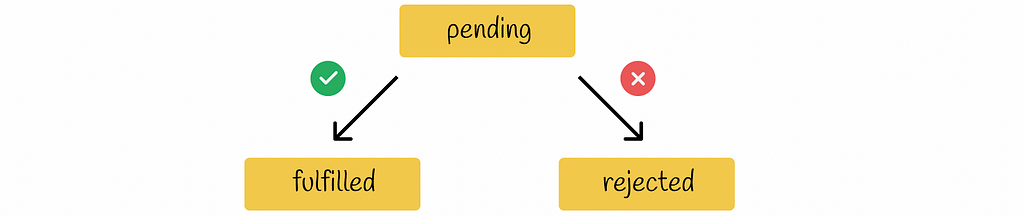
Promises provide a convenient interface for asynchronous code development. A promise takes into a constructor an asynchronous function which is executed at a certain moment of time in the future. Before the function is executed, the promise is said to be in a pending state. Depending on whether the asynchronous function has been completed successfully or not, the promise changes its state to either fulfilled or rejected respectively. For the last two states, programmers can chain .then()and .catch() methods with a promise to declare the logic of how the result of the asynchronous function should be handled in different scenarios.
Promise state diagram
Apart from that, a group of promises can be chained by using combination methods like any(), all(), race(), etc.
Shortcomings of promises
Despite the fact that promises have become a significant improvement over callbacks, they are still not ideal, for several reasons:
Verbosity. Promises usually require writing a lot of boilerplate code. In some cases, creating a promise with a simple functionality requires a few extra lines of code because of its verbose syntax.
Readability. Having several tasks depending on each other leads to nesting promises one inside another. This infamous problem is very similar to the “callback hell” making code difficult to read and maintain. Furthermore, when dealing with error handling, it is usually hard to follow code logic when an error is propagated through several promise chains.
Debugging. By checking the stack trace output, it might be challenging to identify the source of an error inside promises as they do not usually provide clear error descriptions.
Integration with legacy libraries. Many legacy libraries in JavaScript were developed in the past to work with raw callbacks, thus not making it easily compatible with promises. If code is written by using promises, then additional code components should be created to provide compatibility with old libraries.
Both callback and promises can lead to the notorious “callback hell” problem
Async / await
For the most part, the async / await construction was added into JavaScript as synthetic sugar over promises. As the name suggests, it introduces two new code keywords:
async is used before the function signature and marks the function as asynchronous which always returns a promise (even if a promise is not returned explicitly as it will be wrapped implicitly).
await is used inside functions marked as async and is declared in the code before asynchronous operations which return a promise. If a line of code contains the await keyword, then the following code lines inside the async function will not be executed until the returned promise is settled (either in the fulfilled or rejected state). This makes sure that if the execution logic of the following lines depends on the result of the asynchronous operation, then they will not be run.
– The await keyword can be used several times inside an async function.
– If await is used inside a function that is not marked as async, the SyntaxErrorwill be thrown.
– The returned result of a function marked with await it the resolved value of a promise.
The async / await usage example is demonstrated in the snippet below.
// Async / await example. // The code snippet prints start and end words to the console.
function getPromise() { return new Promise((resolve, reject) => { setTimeout(() => { resolve('end'); }, 1000); }); }
// since this function is marked as async, it will return a promise async function printInformation() { console.log('start'); const result = await getPromise(); console.log(result) // this line will not be executed until the promise is resolved }
It is important to understand that await does not block the main JavaScript thread from execution. Instead, it only suspends the enclosing async function (while other program code outside the async function can be run).
Error handling
The async / await construction provides a standard way for error handling with try / catch keywords. To handle errors, it is necessary to wrap all the code that can potentially cause an error (including await declarations) in the try block and write corresponding handle mechanisms in the catch block.
In practice, error handling with try / catch blocks is easier and more readable than achieving the same in promises with .catch() rejection chaining.
// Error handling template inside an async function
async function functionOne() { try { ... const result = await functionTwo() } catch (error) { ... } }
Promises vs async / await
async / await is a great alternative to promises. They eliminate the aforementioned shortcomings of promises: the code written with async / await is usually more readable, and maintainable and is a preferable choice for most software engineers.
Simple syntax of async / await eliminates the “callback hell” problem.
However, it would be incorrect to deny the importance of promises in JavaScript: in some situations, they are a better option, especially when working with functions returning a promise by default.
Code interchangeability
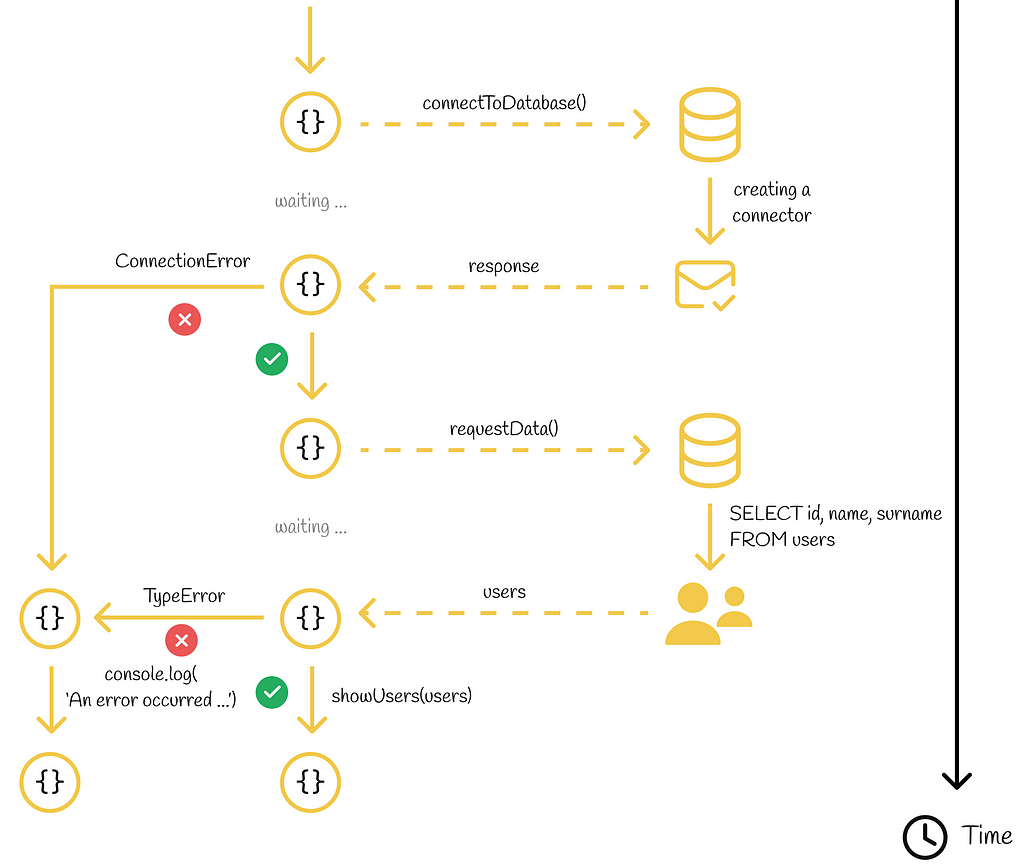
Let us look at the same code written with async / await and promises. We will assume that our program connects to a database and in case of an established connection it requests data about users to further display them in the UI.
// Example of asynchronous requests handled by async / await
async function functionOne() { try { ... const result = await functionTwo() } catch (error) { ... } }
Both asynchronous requests can be easily wrapped by using the await syntax. At each of these two steps, the program will stop code execution until the response is retrieved.
Since something wrong can happen during asynchronous requests (broken connection, data inconsistency, etc.), we should wrap the whole code fragment into a try / catch block. If an error is caught, we display it to the console.
Activity diagram
Now let us write the same code fragment with promises:
// Example of asynchronous requests handled by promises
This nested code looks more verbose and harder to read. In addition, we can notice that every await statement was transformed into a corresponding then() method and that the catch block is now located inside the .catch() method of a promise.
Following the same logic, every async / await code can be rewritten with promises. This statement demonstrates the fact that async / await is just synthetic sugar over promises.
Code written with async / await can be transformed into the promise syntax where each await declaration would correspond to a separate .then() method and exception handling would be performed in the .catch() method.
Fetch example
In this section, we will have a look a real example of how async / await works.
Firstly, let us declare a function that will retrieve the main information from the JSON. We are interested in retrieving information regarding the country’s name, its capital, area and population. The JSON is returned in the form of an array where the first object contains all the necessary information. We can access the aforementioned properties by accessing the object’s keys with corresponding names.
Then we will use the fetch API to perform HTTP requests. Fetch is an asynchronous function which returns a promise. Since we immediately need the data returned by fetch, we must wait until the fetch finishes its job before executing the following code lines. To do that, we use the await keyword before fetch.
// Fetch example with async / await
const getCountryDescription = async function (country) { try { const response = await fetch( `https://restcountries.com/v3.1/name/${country}` ); if (!response.ok) { throw new Error(`Bad HTTP status of the request (${response.status}).`); } const data = await response.json(); console.log(retrieveInformation(data)); } catch (error) { console.log( `An error occurred while processing the request.nError message: ${error.message}` ); } };
Similarly, we place another await before the .json() method to parse the data which is used immediately after in the code. In case of a bad response status or inability to parse the data, an error is thrown which is then processed in the catch block.
For demonstration purposes, let us also rewrite the code snippet by using promises:
// Fetch example with promises
const getCountryDescription = function (country) { fetch(`https://restcountries.com/v3.1/name/${country}`) .then((response) => { if (!response.ok) { throw new Error(`Bad HTTP status of the request (${response.status}).`); } return response.json(); }) .then((data) => { console.log(retrieveInformation(data)); }) .catch((error) => { console.log( `An error occurred while processing the request. Error message: ${error.message}` ); }); };
Calling an either function with a provided country name will print its main information:
// The result of calling getCountryDescription("Argentina")
In this article, we have covered the async / await construction in JavaScript which appeared in the language in 2017. Having appeared as an improvement over promises, it allows writing asynchronous code in a synchronous manner eliminating nested code fragments. Its correct usage combined with promises results in a powerful blend making the code as clean as possible.
Lastly, the information presented in this article about JavaScript is also valuable for Python as well, which has the same async / await construction. Personally, if someone wants to dive deeper into asynchronicity, I would recommend focusing more on JavaScript than on Python. Being aware of the abundant tools that exist in JavaScript for developing asynchronous applications provides an easier understanding of the same concepts in other programming languages.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.