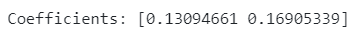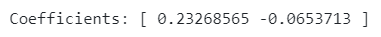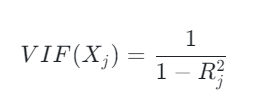Bitwise Chief Information Officer (CIO) Matt Hougan asserted that investment advisors are adopting spot Bitcoin (BTC) exchange-traded funds (ETFs) faster than any other ETF launched in recent history. Hougan made the statement in response to a Sept. 8 social media post by researcher Jim Bianco, who claimed that less than 10% of US-traded spot Bitcoin […]
Current patterns in the crypto total market capitalization chart (TOTAL), specifically an ascending triangle, suggested a major bullish trend is on the horizon.
This sentiment is echoed in the
Recommendations on building robust memory capabilities based on experimentation with Autogen’s “Teachable Agents”
Memory is undoubtedly becoming a crucial aspect of Agentic AI. As the use cases for AI Agents grow in complexity, so does the need for these agents to learn from past experiences, utilize stored business-specific knowledge, and adapt to evolving scenarios based on accumulated information.
In my previous article, “Memory in AI: Key Benefits and Investment Considerations,” I explored why memory is pivotal for AI, discussing its role in recall, reasoning, and continuous learning. This piece, however, will dive directly into the implementation of memory by examining its impact through the “teachability” functionality in the popular agent framework, Autogen.
Note:While this article is technical in nature, it offers value for both technical professionals and business leaders looking to evaluate the role of memory in Agentic AI systems. I’ve structured it so that readers can skip over the code sections and still grasp the way memory can augment the responses of your AI systems. If you don’t wish to follow the code, you may read the descriptions of each step to get a sense of the process… or just the key findings and recommendations section.
Source: Dalle3 , Prompt Author:Sandi Besen
Key Findings and Recommendations
My exploration of Autogen’s Teachable Agents revealed both their potential and limitations in handling both simple and complex memory tasks.
Out of the box, Autogen’s TeachableAgent performs less brilliantly than expected. The Agen’ts reasoning ability conflates memories together in a non productive way and the included retrieval mechanism is not set up for multi-step searches necessary for answering complex questions. This limitation suggests that if you would like to use Autogen’s Teachable Agents, there needs to be substantial customization to both supplement reasoning capabilities and achieve more sophisticated memory retrieval.
To build more robust memory capabilities, it’s crucial to implement multi-step search functionality. A single memory search often falls short of providing the comprehensive information needed for complex tasks. Implementing a series of interconnected searches could significantly enhance the agent’s ability to gather and synthesize relevant information.
The “teachability” feature, while powerful, should be approached with caution. Continuous activation without oversight risks data poisoning and compromise of trusted information sources. Business leaders and solution architects should consider implementing a human-in-the-loop approach, allowing users to approve what the system learns versus treating every inference as ground truth the system should learn from. This oversight in Autogen’s current Teachable Agent design could cause significant risks associated with unchecked learning.
Lastly, the method of memory retrieval from a knowledge store plays a large role in the system’s effectiveness. Moving beyond simple nearest neighbor searches, which is the TeachableAgent’s default, to more advanced techniques such as hybrid search (combining keyword and vector approaches), semantic search, or knowledge graph utilizationcould dramatically improve the relevance and accuracy of retrieved information.
Descriptive Code Implementation
To appropriately demonstrate how external memory can be valuable, I created a fictitious scenario for a car parts manufacturing plant. Follow the code below to implement a Teachable Agent yourself.
Scenario: A car parts manufacturing facility needs to put a plan in place in case there are energy constraints. The plan needs to be flexible and adapt based on how much power consumption the facility can use and which parts and models are in demand.
Step 1:
Pre- set up requires you to pip install autogen if you don’t have it installed in your active environment and create a config JSON file.
Example of a compatible config file which uses Azure OpenAI’s service model GPT4–o:
Import the necessary libraries to your notebook or file and load the config file.
import autogen from autogen.agentchat.contrib.capabilities.teachability import Teachability from autogen import ConversableAgent, UserProxyAgent
config_list = autogen.config_list_from_json( env_or_file="autogenconfig.json", #the json file name that stores the config file_location=".", #this means the file is in the same directory filter_dict={ "model": ["gpt-4o"], #select a subset of the models in your config }, )
Step 3:
Create the Agents. We will need two agents because of the way that Autogen’s framework works. We use a UserProxyAgent to execute tasks and interact with or replace human involvement (depending on the desired amount of human in the loop). We also create a Conversable Agent as the “Teachable Agent” which is meant to interact with other agents (not the user). You can read more about the UserProxyAgents and ConversableAgents here.
teachable_agent = ConversableAgent( name="teachable_agent", # the name can't contain spaces llm_config={"config_list": config_list, "timeout": 120, "cache_seed": None}, # in this example we disable caching but if it is enabled it caches API requests so that they can be reused when the same request is used )
user = UserProxyAgent( name="user", human_input_mode="ALWAYS", #I want to have full control over the code executed so I am setting human_input_mode to ALWAYS. Other options are NEVER and TERMINATE. is_termination_msg=lambda x: True if "TERMINATE" in x.get("content") else False, #setting a termination message is VERY important because it tells the agent when to finish. max_consecutive_auto_reply=0, #we don't need this agent to replies multiple times in a row code_execution_config={ "use_docker": False }, # If you are planning on running code look into setting use_docker=True. For this example I am not because then I have to walk through the docker setup, but it is safer than running the code directly. )
Step 4:
To have a baseline, let’s ask the same question to the agents before and after we “teach” it. I purposely decided to demonstrate different levels of question difficulty to show performance on tasks that require a single step vs multistep memory retrieval. To successfully address the intricate multi-step question, the retrieval mechanism must provide information from two separate memories as context to the language model responsible for generating a final response.
Simple Question: “The facility is experiencing a power shortage of 40%. What models need to be prioritized?”
Complex Multi Step Question: “The facility is experiencing a power shortage of 40%. Provide me a detailed breakdown of what machines should be deactivated and which machines should remain active.”
As expected the responses are generic and not particularly applicable to an individual business.
Response prior to enabling long term memory:
SIMPLE QUESTION RESPONSE =========================== >>>>>>>> USING AUTO REPLY... teachable_agent (to user):
To address a power shortage of 30% effectively, it's crucial to prioritize models that are essential to critical operations, safety, and those that have the highest impact on productivity. Here are steps to determine which models to prioritize:
1. **Identify Essential Systems:** Prioritize systems that are vital for safety, security, and essential operations. These might include: - Emergency lighting - Security systems (alarms, surveillance) - Critical environmental controls (e.g., refrigeration for hazardous materials) - Communication systems
2. **Evaluate Impact on Core Operations:** Determine which models are crucial to the facility’s core functions. This can include machinery, servers, or any processes that are indispensable for maintaining productivity and operations.
3. **Energy Efficiency:** Prioritize models and equipment that are more energy-efficient and can operate within the reduced power capacity.
4. **Downtime Cost:** Consider the cost of downtime for each model. Prioritize those where downtime would result in significant financial losses or production delays.
Based on these principles, here’s a generic prioritization framework:
1. **Safety and Security Systems:** - Emergency Lighting - Fire Alarms and Sprinkler Systems - Security Cameras and Sensors
2. **Critical Operational Systems:** - Essential Production Machinery (that cannot be shut down without major issues) - Servers and IT Infrastructure (especially those critical for operations and data integrity) - HVAC Systems (if necessary for maintaining safe operating conditions)
3. **Support Systems:** - Backup Power Systems (uninterruptible power supplies, generators) - Communication Systems (both internal and external communication)
Ensure that non-essential and high energy-consuming equipment is powered down or scheduled to operate during off-peak hours if possible.
Always re-evaluate periodically to ensure that the power allocation aligns with the dynamic needs of the facility. Communication with key stakeholders regarding priorities and decisions is also essential for smooth operations during a power shortage.
COMPLEX MULTISTEP QUESTION RESPONSE ==================================== >>>>>>>> USING AUTO REPLY... teachable_agent (to user):
To effectively manage a facility experiencing a 30% power shortage, we need to prioritize essential operations and consider the criticality and energy consumption of each machine. Here is a detailed breakdown:
### Step 1: Identify Essential Operations
1. **Critical Infrastructure**: Safety systems, security systems, and essential IT infrastructure. 2. **Production Lines**: Machines involved in the primary production process. 3. **Support Systems**: HVAC systems, lighting, and other ancillary equipment necessary to maintain a safe working environment.
### Step 2: Categorize Machines by Importance and Energy Consumption
#### A. Essential and High-Energy Machines
1. **Safety and Security Systems** - Fire alarms and sprinklers - Surveillance cameras - Security access controls
2. **Primary Production Machines** - Core production lines - Central processing units or mainframe servers (for IT-heavy operations)
3. **Critical Support Systems** - Emergency lighting - Essential HVAC systems (for maintaining operation-critical temperature and humidity)
#### B. Non-Essential and High-Energy Machines
1. **Secondary Production Lines** - Non-primary or non-critical production lines - Equipment used for non-essential or ancillary processes
2. **Supplementary IT Infrastructure** - Servers used for non-essential operations - Backup systems that are not in immediate use
3. **Non-Essential HVAC and Lighting** - HVAC systems for non-critical areas - Lighting in non-essential zones
#### C. Non-Essential and Low-Energy Machines
1. **Office Equipment** - Computers, printers, and copiers in non-essential offices 2. **Non-essential Lab or Research Equipment** - Devices not directly linked to current essential tasks
### Step 3: Prioritize Deactivation
#### Immediate Deactivation
1. **Non-Essential and High-Energy Machines** - Secondary production lines - Non-essential backup servers
2. **Non-Essential HVAC and Lighting** - HVAC in non-critical areas - Non-essential lighting
3. **Non-Essential Office Equipment** - Printers, non-essential computers, and copiers
#### Limited Usage
1. **Essential and High-Energy Machines** - Operate critical production lines at reduced capacity if possible - Implement rotational operation schedules for essential processes
2. **Critical Support Systems** - Optimize HVAC settings (e.g., raising or lowering set points within acceptable ranges) - Reduce lighting to minimum safety standards
### Step 4: Implement Energy Conservation Measures
1. **Optimize Operations** - Utilize energy-efficient settings - Implement energy-saving protocols and encourage staff to conserve energy
2. **Scheduled Downtime** - Plan for downtime during off-peak hours for essential machinery to balance the load
3. **Regular Monitoring** - Monitor energy consumption in real-time to make quick adjustments as needed
### Summary
#### Remain Active: 1. Safety and security systems 2. Main production lines 3. Critical IT infrastructure 4. Essential HVAC and lighting for operational areas
#### Deactivate or Limit Use: 1. Non-essential production lines 2. Redundant IT systems 3. Non-critical HVAC and lighting 4. Office equipment in non-essential areas
**Note**: These recommendations should be adjusted based on the specific operational requirements of your facility. Additionally, it could be beneficial to communicate these changes to all staff to ensure compliance and understanding.
Code to ask baseline questions:
#simple question user.initiate_chat(teachable_agent, message="The facility is experiencing a power shortage of 40%. What models need to be prioritized?", clear_history=True) #multistep complex question user.initiate_chat(teachable_agent, message="The facility is experiencing a power shortage of 30%. Provide me a detailed breakdown of what machines should be deactivated and which machines should remain active.", clear_history=True)
Step 5:
Create the “teachability” capability that you then add to the agent. The Teachability class inherits from the AgentCapabiliy class, which essentially allows you to add customizable capabilities to the Agents.
The Teachability class has many optional parameters that can be further explored here.
The out of the box Teachability class is a quick and convenient way of adding long term memory to the agents, but will likely need to be customized for use in a production setting, as outlined in the key findings section. It involves sending messages to an Analyzer Agent that evaluates the user messages for potential storage and retrieval. The Analyzer Agent looks for advice that could be applicable to similar tasks in the future and then summarizes and stores task-advice pairs in a binary database serving as the agent’s “memory”.
teachability = Teachability( verbosity=0, # 0 for basic info, 1 to add memory operations, 2 for analyzer messages, 3 for memo lists. reset_db=True, # we want to reset the db because we are creating a new agent so we don't want any existing memories. If we wanted to use an existing memory store we would set this to false. path_to_db_dir="./tmp/notebook/teachability_db", #this is the default path you can use any path you'd like recall_threshold=1.5, # Higher numbers allow more (but less relevant) memos to be recalled. max_num_retrievals=10 #10 is default bu you can set the max number of memos to be retrieved lower or higher )
teachability.add_to_agent(teachable_agent)
Step 6:
Now that the teachable_agent is configured, we need to provide it the information that we want the agent to “learn” (store in the database and retrieve from).
In line with our scenario, I wanted the agent to have basic understanding of the facility which consisted of:
the types of components the manufacturing plant produces
the types of car models the components need to be made for
which machines are used to make each component
Additionally, I wanted to provide some operational guidance on the priorities of the facility depending on how power constrained it is. This includes:
Guidance in case of energy capacity constraint of more than 50%
Guidance in case of energy capacity constraint between 25–50%
Guidance in case of energy capacity constraint between 0–25%
business_info = """ # This manufacturing plant manufactures the following vehicle parts: - Body panels (doors, hoods, fenders, etc.) - Engine components (pistons, crankshafts, camshafts) - Transmission parts - Suspension components (springs, shock absorbers) - Brake system parts (rotors, calipers, pads)
# This manufactoring plant produces parts for the following models: - Ford F-150 - Ford Focus - Ford Explorer - Ford Mustang - Ford Escape - Ford Edge - Ford Ranger
# Equipment for Specific Automotive Parts and Their Uses
## 1. Body Panels (doors, hoods, fenders, etc.) - Stamping presses: Form sheet metal into body panel shapes - Die sets: Used with stamping presses to create specific panel shapes - Hydraulic presses: Shape and form metal panels with high pressure - Robotic welding systems: Automate welding of body panels and structures - Laser cutting machines: Precisely cut sheet metal for panels - Sheet metal forming machines: Shape flat sheets into curved or complex forms - Hemming machines: Fold and crimp edges of panels for strength and safety - Metal finishing equipment (grinders, sanders): Smooth surfaces and remove imperfections - Paint booths and spraying systems: Apply paint and protective coatings - Drying ovens: Cure paint and coatings - Quality control inspection systems: Check for defects and ensure dimensional accuracy
## 2. Engine Components (pistons, crankshafts, camshafts) - CNC machining centers: Mill and drill complex engine parts - CNC lathes: Create cylindrical parts like pistons and camshafts - Boring machines: Enlarge and finish cylindrical holes in engine blocks - Honing machines: Create a fine surface finish on cylinder bores - Grinding machines: Achieve precise dimensions and smooth surfaces - EDM equipment: Create complex shapes in hardened materials - Forging presses: Shape metal for crankshafts and connecting rods - Die casting machines: Produce engine blocks and cylinder heads - Heat treatment furnaces: Alter material properties for strength and durability - Quenching systems: Rapidly cool parts after heat treatment - Balancing machines: Ensure rotating parts are perfectly balanced - Coordinate Measuring Machines (CMMs): Verify dimensional accuracy
## 3. Transmission Parts - Gear cutting machines: Create precise gear teeth on transmission components - CNC machining centers: Mill and drill complex transmission housings and parts - CNC lathes: Produce shafts and other cylindrical components - Broaching machines: Create internal splines and keyways - Heat treatment equipment: Harden gears and other components - Precision grinding machines: Achieve extremely tight tolerances on gear surfaces - Honing machines: Finish internal bores in transmission housings - Gear measurement systems: Verify gear geometry and quality - Assembly lines with robotic systems: Put together transmission components - Test benches: Evaluate completed transmissions for performance and quality
## 4. Suspension Components (springs, shock absorbers) - Coil spring winding machines: Produce coil springs to exact specifications - Leaf spring forming equipment: Shape and form leaf springs - Heat treatment furnaces: Strengthen springs and other components - Shot peening equipment: Increase fatigue strength of springs - CNC machining centers: Create precision parts for shock absorbers - Hydraulic cylinder assembly equipment: Assemble shock absorber components - Gas charging stations: Fill shock absorbers with pressurized gas - Spring testing machines: Verify spring rates and performance - Durability test rigs: Simulate real-world conditions to test longevity
## 5. Brake System Parts (rotors, calipers, pads) - High-precision CNC lathes: Machine brake rotors to exact specifications - Grinding machines: Finish rotor surfaces for smoothness - Die casting machines: Produce caliper bodies - CNC machining centers: Mill and drill calipers for precise fit - Precision boring machines: Create accurate cylinder bores in calipers - Hydraulic press: Compress and form brake pad materials - Powder coating systems: Apply protective finishes to calipers - Assembly lines with robotic systems: Put together brake components - Brake dynamometers: Test brake system performance and durability
"""
business_rules_over50 = """ - The engine components are critical and machinery should be kept online that corresponds to producing these components when capacity constraint is more or equal to 50%: engine components - Components for the following models should be prioritized when capacity constraint is more or equal to 50%: 1.Ford F-150 """
business_rules_25to50 = """ - The following components are critical and machinery should be kept online that corresponds to producing these components when capacity constraint is between 25-50%: engine components and transmission parts - Components for the following models should be prioritized when capacity constraint is between 25-50%: 1.Ford F-150 2.Ford Explorer """
business_rules_0to25 = """ - The following components are critical and machinery should be kept online that corresponds to producing these components when capacity constraint is between 0-25%: engine components,transmission parts, Brake System Parts - Components for the following models should be prioritized when capacity constraint is between 0-25%: 1.Ford F-150 2.Ford Explorer 3.Ford Mustang 4.Ford Focus """
Now that we have added important information to long term memory, let’s ask the Agent the same question and see the difference in its responses.
Simple Question: “The facility is experiencing a power shortage of 40%. What models need to be prioritized?”
Complex Multi Step Question: “The facility is experiencing a power shortage of 40%. Provide me a detailed breakdown of what machines should be deactivated and which machines should remain active.”
Results after implementing long term memory:
The Teachable Agent was able to partially answer the simple question. It was correct on the car models that need to be prioritized, but it provided additional incorrect information about which components needed to be included.
The complex multi-step question was not adequately addressed. It erroneously merged two distinct business guidelines for 0–25% and 25–50% capacity constraints into a single, generalized guideline, resulting in an inaccurate response. Additionally, it only provided a partial list of machines that should remain active or be deactivated for each component’s production, omitting crucial details from the complete operational protocol. This demonstrates the challenges in accurately retrieving and synthesizing information from multiple, separate memory sources for complex queries.
SIMPLE QUESTION RESPONSE =========================== >>>>>>>> USING AUTO REPLY... teachable_agent (to user): Given the facility is experiencing a power shortage of 40%, this falls within the 25-50% capacity constraint range. According to your previously established priorities for such a scenario, the following models and components need to be prioritized:
### Components to Prioritize - Engine components - Transmission parts - Brake System Parts
### Models to Prioritize 1. Ford F-150 2. Ford Explorer
You should ensure that the machinery necessary to produce these critical components for the Ford F-150 and Ford Explorer is kept online.
COMPLEX MULTISTEP QUESTION RESPONSE ==================================== >>>>>>>> USING AUTO REPLY... teachable_agent (to user):
In response to the 40% power shortage, let's create a detailed plan to ensure the most critical machinery remains operational while deactivating less essential ones.
### Critical Prioritization (0-50% capacity constraint): - **Critical Components**: - Engine components (pistons, crankshafts, camshafts) - Transmission parts - Brake System Parts (rotors, calipers, pads)
- **Prioritized Models**: - Ford F-150 - Ford Explorer
2. **Transmission Part Machines**: - Transmission Housing Caster - Gear Cutting Machine - Transmission Assembly Line
3. **Brake System Part Machines**: - Brake Rotor Casting Machine - Brake Caliper Milling Machine - Brake Pad Press
### Machines to Deactivate: 1. **Body Panel Machines**: - Door Stamping Machine - Hood Assembly Machine - Fender Bending Machine
2. **Suspension Component Machines**: - Coil Spring Forming Machine - Shock Absorber Assembly Line
### Detailed Breakdown:
#### Active Machines: - **Engine Block Milling Machine**: - Produces critical engine blocks, essential for Ford F-150 and Ford Explorer. - **Crankshaft Grinding Machine**: - Ensures high precision crankshafts; crucial for the performance of Ford F-150 and Ford Explorer. - **Camshaft Milling Machine**: - Produces camshafts, necessary for Ford F-150 and Ford Explorer engines.
- **Transmission Housing Caster**: - Important for casting the housing of transmissions used in Ford F-150 and Ford Explorer. - **Gear Cutting Machine**: - Precision gears production, vital for Ford F-150 and Ford Explorer transmissions. - **Transmission Assembly Line**: - Assembly of complete transmission units for Ford F-150 and Ford Explorer.
- **Brake Rotor Casting Machine**: - Produces brake rotors, crucial for the safe braking systems in Ford F-150 and Ford Explorer. - **Brake Caliper Milling Machine**: - Machining of brake calipers, essential for Ford F-150 and Ford Explorer. - **Brake Pad Press**: - Manufacturing of brake pads, necessary for ensuring braking efficiency in Ford F-150 and Ford Explorer.
#### Deactivated Machines: - **Door Stamping Machine**: - While important, body panels like doors are less critical than engine and transmission components under current constraints. - **Hood Assembly Machine**: - Deactivating hood assembly to free up power for critical components manufacturing. - **Fender Bending Machine**: - Non-critical compared to engine and brake components during a significant power shortage. - **Coil Spring Forming Machine**: - Suspension springs are lower priorities under current circumstances. - **Shock Absorber Assembly Line**: - Suspension components aren’t critical enough to keep operational during this level of power shortage.
This plan ensures that production focuses on maintaining the critical components needed for primary models, the Ford F-150 and Ford Explorer, thereby maximizing the utility of the remaining power while managing production constraints effectively.
Code:
#simple question user.initiate_chat(teachable_agent, message="The facility is experiencing a power shortage of 40%. What models need to be prioritized?", clear_history=True) #multistep complex question user.initiate_chat(teachable_agent, message="The facility is experiencing a power shortage of 30%. Provide me a detailed breakdown of what machines should be deactivated and which machines should remain active.", clear_history=True)
Conclusion
While Autogen provides a straightforward introduction to AI systems with memory, it falls short in handling complex tasks effectively.
When developing your own AI Agent System with memory capabilities, consider focusing on these key capabilities:
Implement multi-step searches to ensure comprehensive and relevant results. This allows the agent to assess the usefulness of search outcomes and address all aspects of a query using the retrieved information. Additionally, consider using more advanced retrieval approaches such as semantic search, hybrid search, or knowledge graphs for the best results.
To limit the potential for data poisoning, develop a thoughtful approach to who should be able to “teach” the agent and when the agent should “learning”. Based on guidelines set by the business or developer, one can also use agent reasoning to determine if something should be added to memory and by whom.
Remove the likelihood of retrieving out of date information by adding a memory decaying mechanism that determines when a memory is no longer relevant or a newer memory should replace it.
For multi-agent systems involving group chats or inter-agent information sharing, explore various communication patterns. Determine the most effective methods for transferring supplemental knowledge and establish limits to prevent information overload.
Note: The opinions expressed both in this article and paper are solely those of the authors and do not necessarily reflect the views or policies of their respective employers.
If you still have questions or think that something needs to be further clarified? Drop me a DM on Linkedin! I‘m always eager to engage in food for thought and iterate on my work.
Welcome to my series on Causal AI, where we will explore the integration of causal reasoning into machine learning models. Expect to explore a number of practical applications across different business contexts.
In the last article we covered powering experiments with CUPED and double machine learning. Today, we shift our focus to understanding how multi-collinearity can damage the causal inferences you make, particularly in marketing mix modelling.
If you missed the last article on powering experiments with CUPED and double machine learning, check it out here:
In this article, we will explore how damaging multi-collinearity can be and evaluate some methods we can use to address it. The following aspects will be covered:
What is multi-collinearity?
Why is it a problem in causal inference?
Why is it so common in marketing mix modelling?
How can we detect it?
How can we address it?
An introduction to Bayesian priors.
A Python case study exploring how Bayesian priors and random budget adjustments can help alleviate multi-collinearity.
Multi-collinearity occurs when two or more independent variables in a regression model are highly correlated with each other. This high correlation means they provide overlapping information, making it difficult for the model to distinguish the individual effect of each variable.
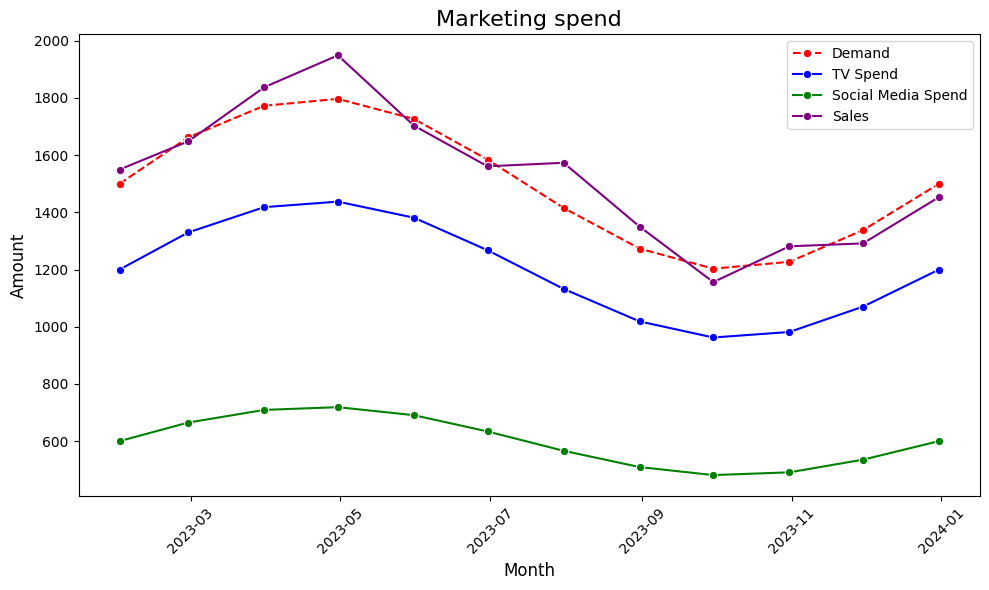
Let’s take an example from marketing. You sell a product where demand is highly seasonal — therefore, it makes sense to spend more on marketing during peak periods when demand is high. However, if both TV and social media spend follow the same seasonal pattern, it becomes difficult for the model to accurately determine the individual contribution of each channel.
User generated image
Why is it a problem in causal inference?
Multi-collinearity can lead to the coefficients of the correlated variables becoming unstable and biased. When multi-collinearity is present, the standard errors of the regression coefficients tend to inflate. This means that the uncertainty around the estimates increases, making it harder to tell if a variable is truly significant.
Let’s go back to our marketing example, even if TV advertising and social media both drive sales, the model might struggle to separate their impacts because the inflated standard errors make the coefficient estimates unreliable.
We can simulate some examples in python to get a better understanding:
Example 1 — Marketing spend on each channel is equal, resulting in biased coefficients:
# Example 1 - marketing spend on each channel is equal: biased coefficients np.random.seed(150)
Additionally, multi-collinearity can cause a phenomenon known as sign flipping, where the direction of the effect (positive or negative) of a variable can reverse unexpectedly. For instance, even though you know social media advertising should positively impact sales, the model might show a negative coefficient simply because of its high correlation with TV spend. We can see this in example 2.
Why is it so common in marketing mix modelling?
We’ve already touched upon one key issue: marketing teams often have a strong understanding of demand patterns and use this knowledge to set budgets. Typically, they increase spending across multiple channels during peak demand periods. While this makes sense from a strategic perspective, it can inadvertently create a multi-collinearity problem.
Even for products where demand is fairly constant, if the marketing team upweight or downweight each channel by the same percentage each week/month, then this will also leave us with a multi-collinearity problem.
The other reason I’ve seen for multi-collinearity in MMM is poorly specified causal graphs (DAGs). If we just throw everything into a flat regression, it’s likely we will have a multi-collinearity problem. Take the example below — If paid search impressions can be explained using TV and Social spend, then including it alongside TV and Social in a flat linear regression model is likely going to lead to multi-collinearity.
User generated image
How can we detect it?
Detecting multi-collinearity is crucial to prevent it from skewing causal inferences. Here are some common methods to identify it:
Correlation
A simple and effective way to detect multi-collinearity is by examining the correlation matrix. This matrix shows pairwise correlations between all variables in the dataset. If two predictors have a correlation coefficient close to +1 or -1, they are highly correlated, which could indicate multi-collinearity.
Variance inflation factor (VIF)
Quantifies how much the variance of a regression coefficient is inflated due to multi-collinearity:
User generated image
The R-squared is obtained by regressing all of the other independent variables on the chosen variable. If the R-squared is high this means the chosen variable can be predicted using the other independent variables (which results in a high VIF for the chosen variable).
There are some rule-of-thumb cut-offs for VIF in terms of detecting multi-collinearity – However, i’ve not found any convincing resources backing them up so I will not quote them here.
Standard errors
The standard error of a regression coefficient tells you how precisely that coefficient is estimated. It is calculated as the square root of the variance of the coefficient estimate. High standard errors may indicate multi-collinearity.
Simulations
Also the knowing the 3 approaches highlighted above is useful, it can still be hard to quantify whether you have a serious problem with multi-collinearity. Another approach you could take is running a simulation with known coefficients and then seeing how well you can estimate them with your model. Let’s illustrate using an MMM example:
Extract channel spend and sales data as normal.
-- example SQL code to extract data select observation_date, sum(tv_spend) as tv_spend, sum(social_spend) as social_spend, sum(sales) as sales from mmm_data_mart group by observation_date;
Create data generating process, setting a coefficient for each channel.
# set coefficients for each channel using actual spend data marketing_contribution = tv_spend * 0.10 + social_spend * 0.20
# calculate the remaining contribution other_contribution = sales - marketing_contribution
# create arrays for regression X = np.column_stack((tv_spend, social_spend, other_contribution)) y = sales
Train model and compare estimated coefficients to those set in the last step.
# train regression model clf = LinearRegression() clf.fit(X, y)
Now we know how we can identify multi-collinearity, let’s move on and explore how we can address it!
How can we address it?
There are several strategies to address multi-collinearity:
Removing one of the correlated variables This is a straightforward way to reduce redundancy. However, removing a variable blindly can be risky — especially if the removed variable is a confounder. A helpful step is determining the causal graph (DAG). Understanding the causal relationships allows you to assess whether dropping a correlated variable still enables valid inferences.
Combining variables When two or more variables provide similar information, you can combine them. This method reduces the dimensionality of the model, mitigating multi-collinearity risk while preserving as much information as possible. As with the previous approach, understanding the causal structure of the data is crucial.
Regularization techniques Regularization methods such as Ridge or Lasso regression are powerful tools to counteract multi-collinearity. These techniques add a penalty to the model’s complexity, shrinking the coefficients of correlated predictors. Ridge focuses on reducing the magnitude of all coefficients, while Lasso can drive some coefficients to zero, effectively selecting a subset of predictors.
Bayesian priors Using Bayesian regression techniques, you can introduce prior distributions for the parameters based on existing knowledge. This allows the model to “regularize” based on these priors, reducing the impact of multi-collinearity. By informing the model about reasonable ranges for parameter values, it prevents overfitting to highly correlated variables. We’ll delve into this method in the case study to illustrate its effectiveness.
Random budget adjustments Another strategy, particularly useful in marketing mix modeling (MMM), is introducing random adjustments to your marketing budgets at a channel level. By systematically altering the budgets you can start to observe the isolated effects of each. There are two main challenges with this method (1) Buy-in from the marketing team and (2) Once up and running it could take months or even years to collect enough data for your model. We will also cover this one off in the case study with some simulations.
We will test some of these strategies out in the case study next.
An introduction to Bayesian priors
A deep dive into Bayesian priors is beyond the scope of this article, but let’s cover some of the intuition behind them to ensure we can follow the case study.
Bayesian priors represent our initial beliefs about the values of parameters before we observe any data. In a Bayesian approach, we combine these priors with actual data (via a likelihood function) to update our understanding and calculate the posterior distribution, which reflects both the prior information and the data.
To simplify: when building an MMM, we need to feed the model some prior beliefs about the coefficients of each variable. Instead of supplying a fixed upper and lower bound, we provide a distribution. The model then searches within this distribution and, using the data, calculates the posterior distribution. Typically, we use the mean of this posterior distribution to get our coefficient estimates.
Of course, there’s more to Bayesian priors than this, but the explanation above serves as a solid starting point!
Case study
You’ve recently joined a start-up who have been running their marketing strategy for a couple of years now. They want to start measuring it using MMM, but their early attempts gave unintuitive results (TV had a negative contribution!). It seems their problem stems from the fact that each marketing channel owner is setting their budget based on the demand forecast, leading to a problem with multi-collinearity. You are tasked with assessing the situation and recommending next steps.
Data-generating-process
Let’s start by creating a data-generating function in python with the following properties:
Demand is made up of 3 components: trend, seasonality and noise.
The demand forecast model comes from the data science team and can accurately predict within +/- 5% accuracy.
This demand forecast is used by the marketing team to set the budget for social and TV spend — We can add some random variation to these budgets using the spend_rand_change parameter.
The marketing team spend twice as much on TV compared to social media.
Sales are driven by a linear combination of demand, social media spend and TV spend.
The coefficients for social media and TV spend can be set using the true_coef parameter.
def data_generator(spend_rand_change, true_coef): ''' Generate simulated marketing data with demand, forecasted demand, social and TV spend, and sales.
Args: spend_rand_change (float): Random variation parameter for marketing spend. true_coef (list): True coefficients for demand, social media spend, and TV spend effects on sales.
Returns: pd.DataFrame: DataFrame containing the simulated data. '''
# Parameters for data generation start_date = "2018-01-01" periods = 365 * 3 # Daily data for three years trend_slope = 0.01 # Linear trend component seasonal_amplitude = 5 # Amplitude of the seasonal component seasonal_period = 30.44 # Monthly periodicity noise_level = 5 # Level of random noise in demand
# Generate time variables time = np.arange(periods) date_range = pd.date_range(start=start_date, periods=periods)
# Add forecasted demand with slight random variation df['demand_forecast'] = df['demand'] * np.random.uniform(0.95, 1.05, len(df))
# Simulate social media and TV spend with random variation df['social_spend'] = df['demand_forecast'] * 10 * np.random.uniform(1 - spend_rand_change, 1 + spend_rand_change, len(df)) df['tv_spend'] = df['demand_forecast'] * 20 * np.random.uniform(1 - spend_rand_change, 1 + spend_rand_change, len(df)) df['total_spend'] = df['social_spend'] + df['tv_spend']
# Calculate sales based on demand, social, and TV spend, with some added noise df['sales'] = ( df['demand'] * true_coef[0] + df['social_spend'] * true_coef[1] + df['tv_spend'] * true_coef[2] ) sales_noise = 0.01 * df['sales'] * np.random.randn(len(df)) df['sales'] += sales_noise
return df
Initial assessment
Now let’s simulate some data with no random variation applied to how the marketing team set the budget — We will try and estimate the true coefficients. The function below is used to train the regression model:
def run_reg(df, features, target): ''' Runs a linear regression on the specified features to predict the target variable.
Args: df (pd.DataFrame): The input data containing features and target. features (list): List of column names to be used as features in the regression. target (str): The name of the target column to be predicted. Returns: np.ndarray: Array of recovered coefficients from the linear regression model. '''
# Extract features and target values X = df[features].values y = df[target].values
# Initialize and fit linear regression model model = LinearRegression() model.fit(X, y)
We can see that the coefficient for social spend is underestimated whilst the coefficient for tv spend is overestimated. Good job you didn’t give the marketing team this model to optimise their budgets — It would have ended in disaster!
In the short-term, could using Bayesian priors give less biased coefficients?
In the long-term, would random budget adjustments create a dataset which doesn’t suffer from multi-collinearity?
Let’s try and find out!
Bayesian priors
Let’s start with exploring Bayesian priors…
We will be using my favourite MMM implementation pymc marketing:
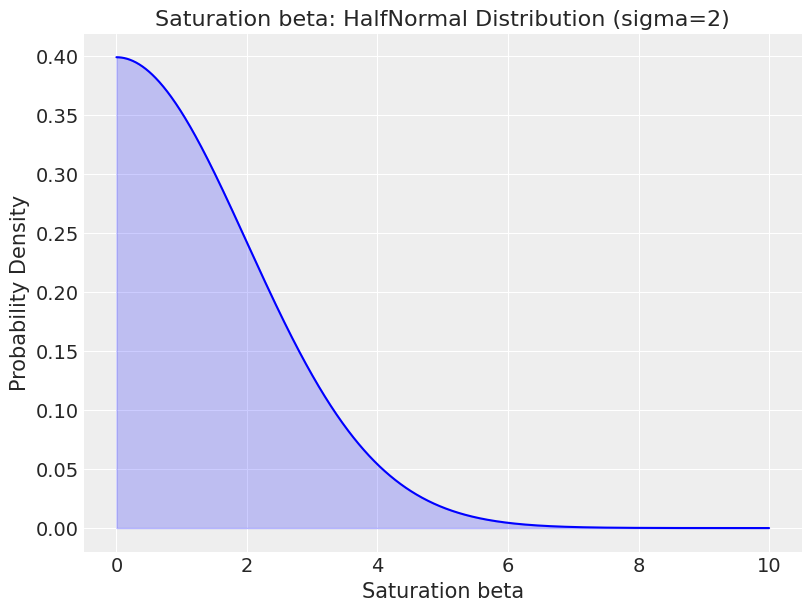
Let’s see what result we get if we use the default priors. Below you can see that there are a lot of priors! This is because we have to supply priors for the intercept, ad stock and saturation transformation amongst other things. It’s the saturation beta we are interested in – This is the equivalent of the variable coefficients we are trying to estimate.
We have to supply a distribution. The HalfNormal is a sensible choice for channel coefficients as we know they can’t be negative. Below we visualise what the distribution looks like to bring it to life:
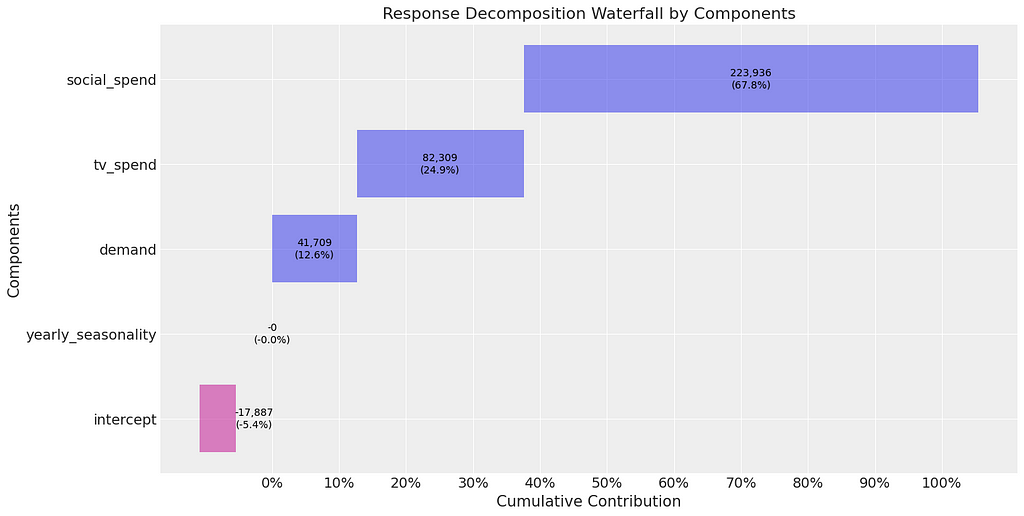
Now we are ready to train the model and extract the contributions of each channel. As before our coefficients are biased (we know this as the contributions for each channel aren’t correct — social media should be 50% and TV should be 35%). However, interestingly they are much closer to the true contribution compared to when we ran linear regression before. This would actually be a reasonable starting point for the marketing team!
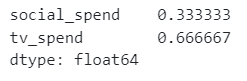
Before we move on, let’s take the opportunity to think about custom priors. One (very bold) assumption we can make is that each channel has a similar return on investment (or in our case where we don’t have revenue, cost per sale). We can therefore use the spend distribution across channel to set some custom priors.
As the MMM class does feature scaling in both the target and features, priors also need to be supplied in the scaled space. This actually makes it quite easy for us to do as you can see in the below code:
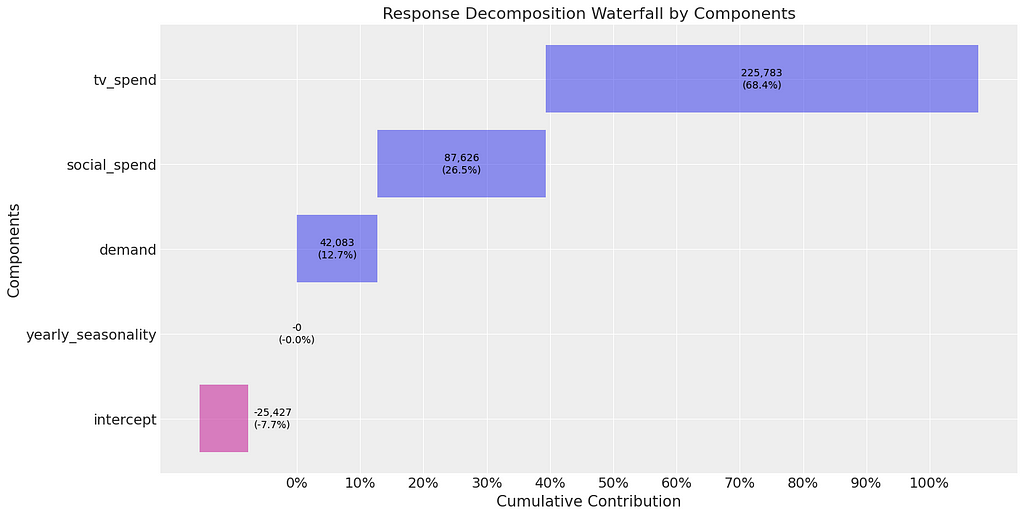
When we train the model and extract the coefficients we see that the priors have come into play, with tv now having the highest contribution (because we spent more than social). However, this is very wrong and illustrates why we have to be so careful when setting priors! The marketing team should really think about running some experiments to help them set priors.
Now we have our short-term plan in place, let’s think about the longer term plan. If we could persuade the marketing team to apply small random adjustments to their marketing channel budgets each month, would this create a dataset without multi-collinearity?
The code below uses the data generator function and simulates a range of random spend adjustments:
np.random.seed(40)
# Define list to store results results = []
# Loop through a range of random adjustments to spend for spend_rand_change in np.arange(0.00, 0.05, 0.001): # Generate simulated data with the current spend_rand_change sim_data = data_generator(spend_rand_change, true_coef)
# Run the regression coefficients = run_reg(sim_data, features=['demand', 'social_spend', 'tv_spend'], target='sales')
# Store the spend_rand_change and coefficients for later plotting results.append({ 'spend_rand_change': spend_rand_change, 'coef_demand': coefficients[0], 'coef_social_spend': coefficients[1], 'coef_tv_spend': coefficients[2] })
# Convert results to DataFrame for easy plotting results_df = pd.DataFrame(results)
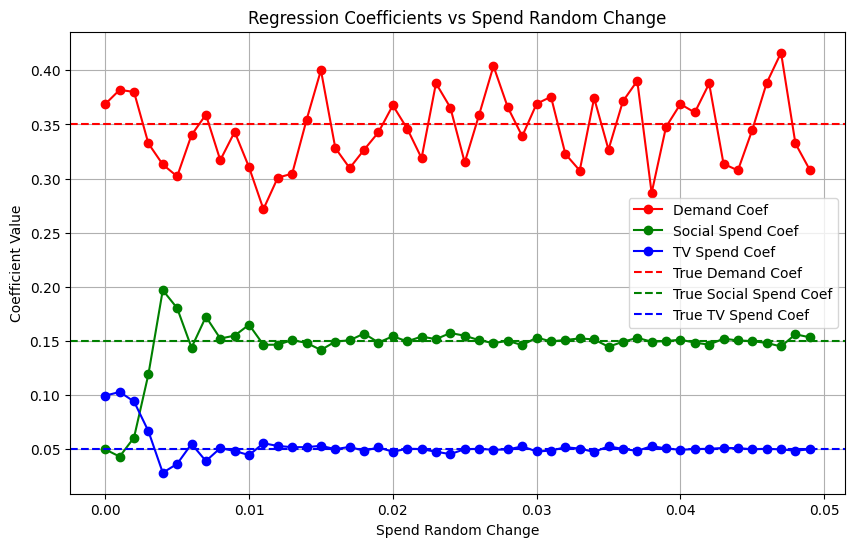
# Plot the coefficients as a function of spend_rand_change plt.figure(figsize=(10, 6)) plt.plot(results_df['spend_rand_change'], results_df['coef_demand'], label='Demand Coef', color='r', marker='o') plt.plot(results_df['spend_rand_change'], results_df['coef_social_spend'], label='Social Spend Coef', color='g', marker='o') plt.plot(results_df['spend_rand_change'], results_df['coef_tv_spend'], label='TV Spend Coef', color='b', marker='o')
# Add lines for the true coefficients plt.axhline(y=true_coef[0], color='r', linestyle='--', label='True Demand Coef') plt.axhline(y=true_coef[1], color='g', linestyle='--', label='True Social Spend Coef') plt.axhline(y=true_coef[2], color='b', linestyle='--', label='True TV Spend Coef')
plt.title('Regression Coefficients vs Spend Random Change') plt.xlabel('Spend Random Change') plt.ylabel('Coefficient Value') plt.legend() plt.grid(True) plt.show()
We can see from the results that just a small random adjustment to the budget for each channel can break free of the multi-collinearity curse!
User generated image
It’s worth noting that if I change the random seed (almost like resampling), the starting point for the coefficients varies — However, whatever seed I used the coefficients stabilised after a 1% random change in spend. I’m sure this will vary depending on your data-generating process so make sure you test it out using your own data!
Final thoughts
Although the focus of this article was multi-collinearity, the big take away is the importance of simulating data and then trying to estimate the known coefficients (remember you set them yourself so you know them) — It’s an essential step if you want to have confidence in your results!
When it comes to MMM, it can be useful to use your actual spend and sales data as the base for your simulation — This will help you understand if you have a multi-collinearity problem.
If you use actual spend and sales data you can also carry out a random budget adjustment simulation to help come up with a suitable randomisation strategy for the marketing team. Keep in mind my simulation was simplistic to illustrate a point — We could design a much more effective strategy e.g. testing different areas of the response curve for each channel.
Bayesian can be a steep learning curve — The other approach we could take is using a constrained regression in which you set upper and lower bounds for each channel coefficient based on prior knowledge.
If you are setting Bayesian priors, it’s super important to be transparent about how they work and how they were selected. If you go down the route of using the channel spend distribution, the assumption that each channel has a similar ROI needs signing off from the relevant stakeholders.
Bayesian priors are not magic! Ideally you would use results from experiments to set your priors — It’s worth checking out how the pymc marketing have approached this:
That is it, hope you enjoyed this instalment! Follow me if you want to continue this journey into Causal AI – In the next article we will immerse ourselves in the topic of bad controls!
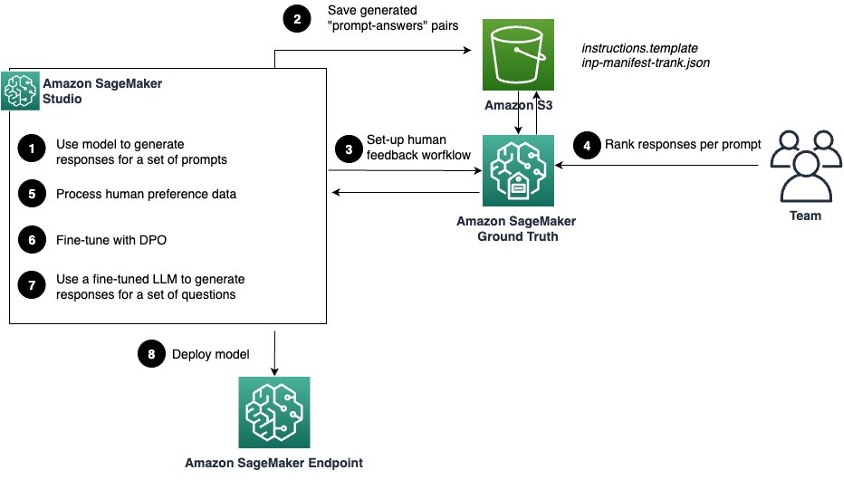
In this post, we show you how to enhance the performance of Meta Llama 3 8B Instruct by fine-tuning it using direct preference optimization (DPO) on data collected with SageMaker Ground Truth.
In this post, we discuss the core capabilities of Amazon Elastic Compute Cloud (Amazon EC2) P5e instances and the use cases they’re well-suited for. We walk you through an example of how to get started with these instances and carry out inference deployment of Meta Llama 3.1 70B and 405B models on them.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.