The absence of significant catalysts has left the crypto market sensitive to US macro data prints.
Bitcoin’s weekly Relative Strength Index reading closed at its lowest level since January 20
In the previous part, we have set up Elementary in our dbt repository and hopefully also run it on our production. In this part, we will go more in detail and examine the available tests in Elementary with examples and explain which tests are more suitable for which kind of data scenarios.
While running the report we saw a “Test Configuration” Tab available only in Elementary Cloud. This is a convenient UI section of the report in the cloud but we can also create test configurations in the OSS version of the Elementary in .yaml files. It is similar to setting up native dbt tests and follows a similar dbt native hierarchy, where smaller and more specific configurations override higher ones.
What are those tests you can set up? Elementary groups them under 3 main categories: Schema tests, Anomaly tests, and Python tests. So let’s go through them and understand how they are working one by one:
Schema Tests :
As the name suggests, schema tests focus on schemas. Depending on the tests you integrate, it is possible to check schema changes or schema changes from baseline, check inside of a JSON column, or monitor your columns for downstream exposures.
Schema changes: These tests monitor and alert if there are any unexpected changes in the schema like additions or deletions of columns or changes in the data types of the columns.
Schema changes from baseline: Like schema changes tests, schema changes from baseline tests compare the current schema to a defined baseline schema. For this test to work, a baseline schema needs to be defined and added under the columns. Elementary also provides a macro to create this test automatically, and running it would create the test for all sources, so appropriate arguments should be given to create the tests and pasted into the relevant .yml file. The following code would create a configuration with the fail_on_added argument set to true:
#Generating the configuration dbt run-operation elementary.generate_schema_baseline_test --args '{"name": "sales_monthly","fail_on_added": true}'
Both tests appear similar but are designed for different scenarios. The schema_changes test is ideal when dealing with sources where the schema changes frequently, allowing for early detection of unexpected changes like the addition of a new column. On the other hand, the schema_changes_from_baseline test is better suited for situations where the schema should remain consistent over time, such as in regulatory settings or production databases where changes need to be carefully managed.
JSON schema (Currently supported only in BigQuery and Snowflake): Checks if the given JSON schema matches a string column that is defined. Like schema_changes_from_baseline , Elementary also provides a run operation for json_schema as well to automatically create the test given a model or source.
Finally exposure_schema: Elementary powers up the exposures by enabling to detection of changes in the model’s columns that can break the downstream exposures. Following is a sudo example of how we are using it for our BI dashboards, with multiple dependencies:
These tests monitor significant changes or deviations on a specific metric by comparing them with the historical values at a defined time frame. An anomaly is simply an outlier value out of the expected range that was calculated during the time frame defined to measure. Elementary uses the Z-score for anomaly detection in data and values with a Z-score of 3 or higher are marked as anomaly. This threshold can also be set to higher in settings with anomaly_score_threshnold . Next, I will try to explain and tell which kind of data they are suited to the best with examples below.
volume_anomalies: Once you are integrating from a source or creating any tables within your data warehouse, you observe some kind of trends on volume mostly already. These trends can be weekly to daily, and if there are any unexpected anomalies, such as an increase caused by duplication or a really low amount of data inserts that would make freshness tests still successful, can be detected by Elementary’s volume_anomalies tests. How does it calculate any volume anomalies? Most of the anomaly tests work similarly: it splits the data into time buckets and calculates the number of rows per bucket for a training_period Then compares the number of rows per bucket within the detection period to the previous time bucket. These tests are particularly useful for data with already some expected behavior such as to find unusual trading volumes in financial data or sales data analysis as well as for detecting unusual network traffic activity.
models: - name: login_events config: elementary: timestamp_column: "loaded_at" tests: - elementary.volume_anomalies: where_expression: "event_type in ('event_1', 'event_2') and country_name != 'unwanted country'" time_bucket: period: day count: 1 # optional - use tags to run elementary tests on a dedicated run tags: ["elementary"] config: # optional - change severity severity: warn
freshness_anomalies: These tests check for the freshness of your table through a time window. There are also dbt’s own freshness tests, but these two tests serve different purposes. dbt freshness tests are straightforward, check if data is up to date and the goal is validating that the data is fresh within an expected timeframe. Elemantary’s tests focus is detecting anomalies, such as highlighting not-so-visible issues like irregular update patterns or unexpected delays caused by problems in the pipeline. These can be useful, especially when punctuality is important and irregularities might indicate issues.
models: - name: ger_login_events config: elementary: timestamp_column: "ingested_at" tags: ["elementary"] tests: - elementary.freshness_anomalies: where_expression: "event_id in ('successfull') and country != 'ger'" time_bucket: period: day count: 1 config: severity: warn - elementary.event_freshness_anomalies: event_timestamp_column: "created_at" update_timestamp_column: "ingested_at" config: severity: warn
event_freshness_anomalies: Similar to freshness anomalies, event freshness is more granular and focuses on specific events within datasets, but still compliments the freshness_tests. These tests are ideal for real/near-real-time systems where the timeliness of individual events is critical such as sensor data, real-time user actions, or transactions. For example, if the pattern is to log data within seconds, and suddenly they start being logged with minutes of delay, Elementary would detect and alert.
dimension_anomalies: These are suited best to track the consistency and the distribution of categorical data, for example, if you have a table that tracks events across countries, Elementary can track the distribution of events across these countries and alerts if there is a sudden drop attributed to one of these countries.
all_columns_anomalies: Best to use when you need to ensure the overall health and consistency within the dataset. This test checks the data type of each column and runs only the relevant tests for them. It is useful after major updates to check if the changes introduced any errors that were missed before or when the dataset is too large and it is impractical to check each column manually.
Besides all of these tests mentioned above, Elementary also enables running Python tests using dbt’s building blocks. It powers up your testing coverage quite a lot, but that part requires its own article.
How are we using the tests mentioned in this article? Besides some of the tests from Elementary, we use Elementary to write metadata for each dbt execution into BigQuery so that it becomes easier available since these are otherwise just output as JSON files by dbt.
Implementing all the tests mentioned in this article is not necessary—I would even say discouraged/not possible. Every data pipeline and its requirements are different. Wrong/excessive alerting may decrease the trust in your pipelines and data by business. Finding the sweet spot with the correct amount of test coverage comes with time.
I hope this article was useful and gave you some insights into how to implement data observability with an open-source tool. Thanks a lot for reading and already a member of Medium, you can follow me here too ! Let me know if you have any questions or suggestions.
Open-Source Data Observability with Elementary — From Zero to Hero (Part 1)
A step-by-step hands-on guide I wish I had when I was a beginner
Data observability and its importance have often been discussed and written about as a crucial aspect of modern data and analytics engineering. Many tools are available on the market with various features and prices. In this 2 part article, we will focus on the open-source version of Elementary, one of these data observability platforms, tailored for and designed to work seamlessly with dbt. We will start by setting up from zero and aiming to understand how it works and what is possible in different data scenarios by the end of part 2. Before we start, I also would like to disclose that I have no affiliation with Elementary, and all opinions expressed are my own.
In part 1, we will set up the Elementary and check how to read the Elementary’s daily report. If you are comfortable with this part already and interested in checking different types of data tests and which one suits bests for which scenario, you can directly jump into part 2 here:
I have been using Elementary for quite some time and my experiences as a data engineer are positive, as to how my team conceives the results. Our team uses Elementary for automated daily monitoring with a self-hosted elementary dashboard. Elementary also has a very convenient cloud platform as a paid product, but the open-source version is far more than enough for us. If you want to explore the differences and what features are missing in open source, elementary compares both products here. Let us start by setting up the open-source version first.
How to Install Elementary
Installing Elementary is as easy as installing any other package in your dbt project. Simply add the following to your packages.yml file. If you don’t have one yet, you can create a packages.yml file at the same level as your dbt_project.yml file. A package is essentially another dbt project, consisting of additional SQL and Jinja code that can be incorporated into your dbt project.
packages: - package: elementary-data/elementary version: 0.15.2 ## you can also have different minor versions as: ## version: [">=0.14.0", "<0.15.0"] ## Docs: https://docs.elementary-data.com
We want Elementary to have its own schema for writing outputs. In the dbt_project.yml file, we define the schema name for Elementary under models. If you are using dbt Core, by default all dbt models are built in the schema specified in your profile’s target. Depending on how you define your custom schema, the schema will be named either elementary or <target_schema>_elementary.
models: ## see docs: https://docs.elementary-data.com/ elementary: ## elementary models will be created in the schema 'your_schema_elementary' +schema: "elementary" ## If you dont want to run Elementary in your Dev Environment Uncomment following: # enabled: "{{ target.name in ['prod','analytics'] }}"
From dbt 1.8 onwards, dbt depreciated the ability of installed packages to override build-in materializations without an explicit opt-in from the user. Some elementary features crash with this change, hence a flag needs to be added under the flags section at the same level as models in the dbt_project.yml file.
Finally, for Elementary to function properly, it needs to connect to the same data warehouses that your dbt project uses. If you have multiple development environments, Elementary ensures consistency between how dbt connects to these warehouses and how Elementary connects to them. This is why Elementary requires a specified configuration in your profiles.yml file.
elementary: outputs: dev: type: bigquery method: oauth project: dev dataset: elementary location: EU priority: interactive retries: 0 threads: 4 pp: type: bigquery method: oauth # / service-account # keyfile : [full path to your keyfile] project: prod # project_id dataset: elementary # elementary dataset, usually [dataset name]_elementary location: EU # [dataset location] priority: interactive retries: 0 threads: 4
The following code would also generate the profile for you once run within the dbt project :
pip install elementary-data # you should also run following for your platform too, Postgres does not requiere this step pip install 'elementary-data[bigquery]'
How does elementary work?
Now that you have Elementary hopefully working on your dbt project, it is also useful to understand how Elementary operates. Essentially, Elementary operates by utilizing the dbt artifacts generated during dbt runs. These artifacts, such as manifest.json, run_results.json, and other logs, are used to gather detailed model metadata, track model execution, and evaluate test results. Elementary centralizes this data to offer a comprehensive view of your pipeline’s performance. It then produces a report based on the analysis and can generate alerts.
How to use elementary
In most simple terms, if you would like to create a general Elementary report the following code would generate a report as an HTML file:
edr report
on your CLI, this would access your data warehouse by using connection profiles that we have provided in the previous steps. If the elementary profile does not have a default target name defined, it will throw you an error, to avoid the error you can also give–profile-target <target_name> as variable while running on your terminal.
Once the Elementary run finishes, it automatically opens up the elementary report as an HTML file.
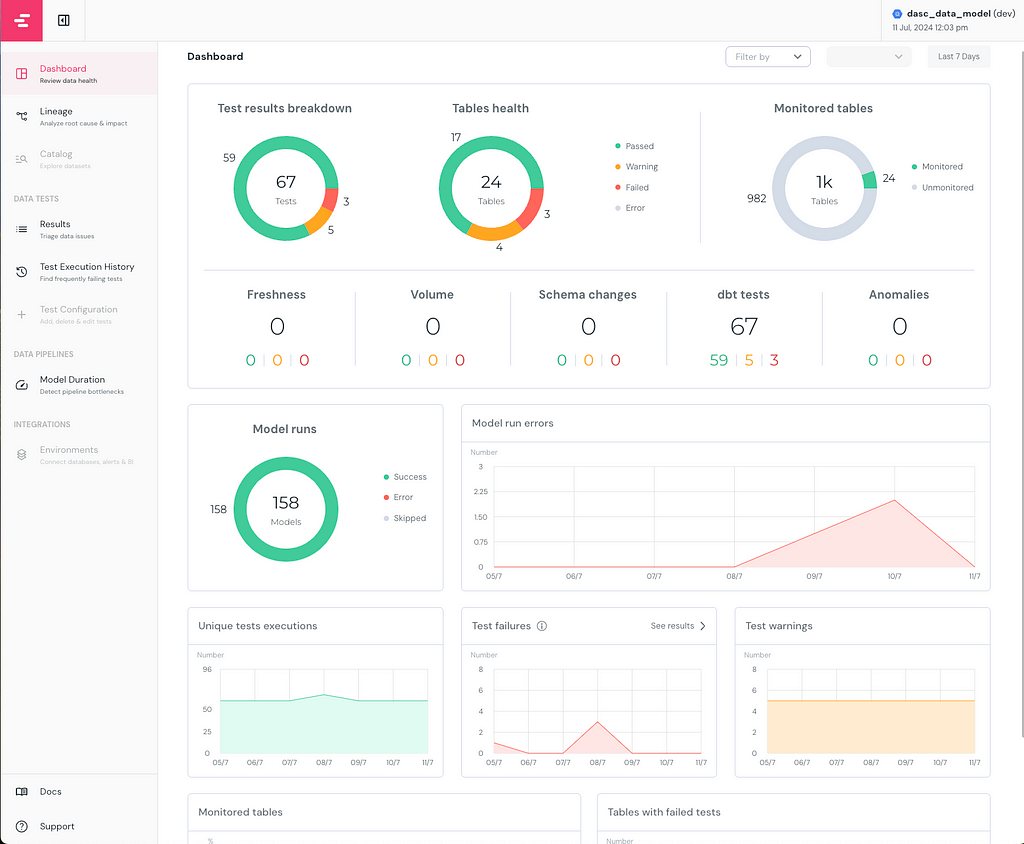
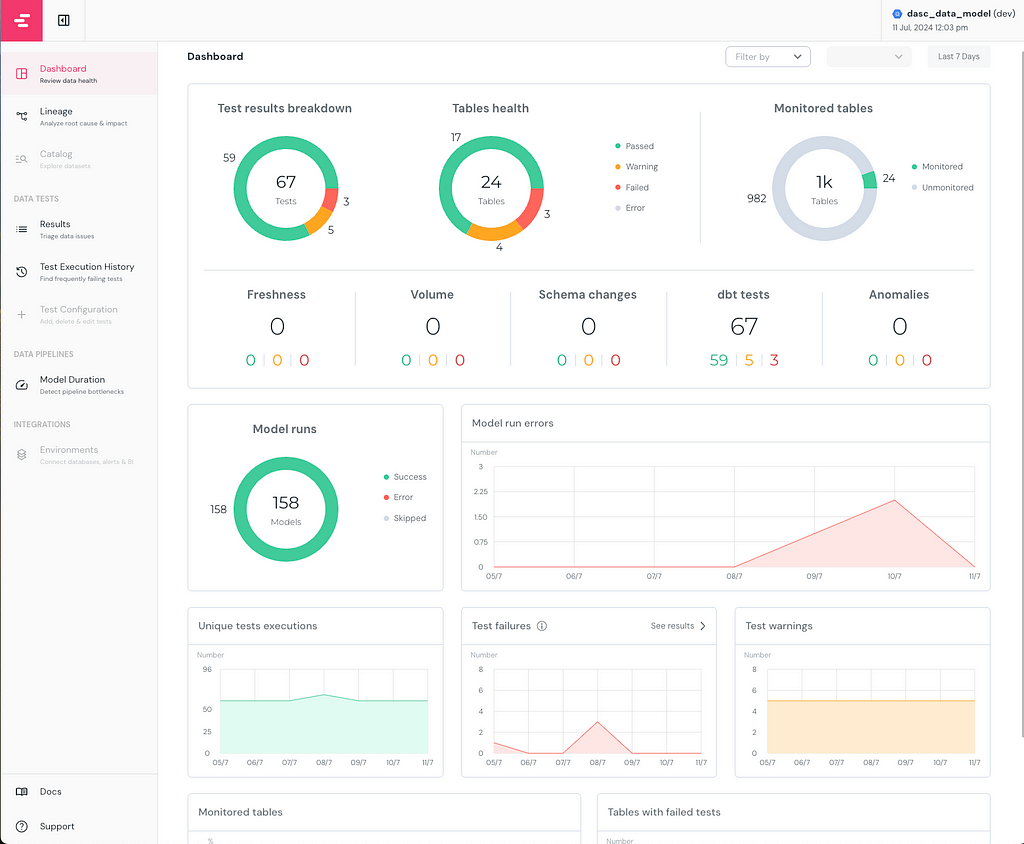
Elementary Report Dashboard
On the left lane of the dashboard, you can see the different pages, the Dashboard page gives a comprehensive overview of the dbt project’s performance and status. Catalog and Test Configuration pages are only available in Elementary Cloud but these configurations can also be implemented manually in the OSS version, explained more in detail in part 2.
How to read this report?
In this exemplary report, I intentionally created warnings and errors beforehand for this article. 67 Tests were running in total, where 3 of them failed and 5 of them gave a warning. I monitored 24 tables, and all tests configured and checked were here dbt tests, if freshness or volume tests of Elementary had been configured, they would show up in the second row of the first visual.
As you can see in the Model runs visual, I have run 158 models without any errors or skipping. In the previous days, there were an increasing number of errors while running the models. I can easily see the errors that started occurring on 09/7 and troubleshoot them accordingly.
You can host this dashboard on your production and send it to your communication/alerting channel. Below is an example from an Argo workflow, but you can also check here for different methods that fit your setup/where you want to host it in your production.
- name: generate-elementary-report container: image: "{{inputs.parameters.elementary_image}}" ##pre-defined elemantary image in configmap.yaml command: ["edr"] ##run command for elemantary report args: ["report", "--profile-target={{inputs.parameters.target}}"] workingDir: workdir ##working directory inputs: parameters: - name: target - name: elementary_image - name: bucket artifacts: - name: source path: workdir ##working directory outputs: artifacts: - name: state path: /workdir/edr_target gcs: bucket: "{{inputs.parameters.bucket}}" ##here is the bucket that you would like to host your dashboard output key: path_to_key archive: none: {}
By using the template above in our Argo workflows, we would create the Elementary HTML report and save it in the defined bucket. We can later take this report from your bucket and send it with your alerts.
Now we know how we set up our report and hopefully know the basics of Elementary, next, we will check different types of tests and which test would suit the best in which scenario. Just jump into Part 2.
If that was enough for you already, thanks a lot for reading!
References in This Article
Elementary Data Documentation. (n.d.). Elementary Data Documentation. Retrieved September 5, 2024, from https://docs.elementary-data.com
dbt Labs. (n.d.). dbt Documentation. Retrieved September 5, 2024, from https://docs.getdbt.com
Hands-on guide with side-by-side examples in Pandas
Image created with AI by Dall-E
This article is not about comparing Polars with Pandas or highlighting their differences. It’s a story about how adding a new tool can be beneficial not only for data science professionals but also for others who work with data. I like Polars because it is multithreaded, providing strong performance out-of-the-box, and it supports Lazy evaluation with query optimization capabilities. This tool will undoubtedly enhance your data skills and open up new opportunities.
Although Polars and Pandas are different libraries, they share similarities in their APIs. Drawing parallels between them can make it easier for those familiar with the Pandas API to start using Polars. Even if you’re not familiar with Pandas and want to start learning Polars, it will still be incredibly useful and rewarding.
We will look at the most common actions that, in my experience, are most often used for data analysis. To illustrate the process of using Polars, I will consider an abstract task with reproducible data, so you can follow all the steps on your computer.
Imagine that we have data from three online stores, where we register user actions, such as viewing and purchasing. Let’s assume that at any given time, only one action of each type can occur for each online store, and in case of a transaction error, our data might be missing the product identifier or its quantity. Additionally, for our task, we’ll need a product catalog with prices for each item.
Let’s formulate the main task: to calculate a summary table with the total purchase for each online store.
I will break down this task into the following steps:
Data preparation and DataFrame creation.
Summary statistics of the DataFrame.
Retrieving the first five records.
Renaming columns.
Changing column types.
Filling missing values.
Removing missing values.
Removing duplicate records.
Filtering data.
Selecting the required columns.
Grouping data.
Merging data with another DataFrame.
Calculating a new column.
Creating a Pivot table.
Let’s get started!
Data Preparation and DataFrame Creation
We have the following data:
OnlineStore — indicates the store.
product — stores the product ID.
Action type — the type of action (either a view or a purchase).
quantity — the amount of the purchased or viewed product.
Action_time — the timestamp for the action.
Requirements:
polars==1.6.0 pandas==2.0.0
from dataclasses import dataclass from datetime import datetime, timedelta from random import choice, gauss, randrange, seed from typing import Any, Dict
import polars as pl import pandas as pd
seed(42)
base_time= datetime(2024, 8, 31, 0, 0, 0, 0)
user_actions_data = [ { "OnlineStore": choice(["Shop1", "Shop2", "Shop3"]), "product": choice(["0001", "0002", "0003"]), "quantity": choice([1.0, 2.0, 3.0]), "Action type": ("purchase" if gauss() > 0.6 else "view"), "Action_time": base_time - timedelta(minutes=randrange(1_000_000)), } for x in range(1_000_000) ]
corrupted_data = [ { "OnlineStore": choice(["Shop1", "Shop2", "Shop3"]), "product": choice(["0001", None]), "quantity": choice([1.0, None]), "Action type": ("purchase" if gauss() > 0.6 else "view"), "Action_time": base_time - timedelta(minutes=randrange(1_000)), } for x in range(1_000) ]
For product catalog, which in our case include only product_id and its price (price).
In this way, we have easily created DataFrames for further work.
Of course, each method has its own parameters, so it’s best to have the documentation handy to avoid confusion and use them appropriately.
Summary Statistics of the DataFrame
After loading or preparing data, it’s useful to quickly explore the resulting dataset. For summary statistics, the method name remains the same, but the results may differ:
OnlineStore product quantity Action type Action_time count 1001000 1000492 1.000510e+06 1001000 1001000 unique 3 3 NaN 2 632335 top Shop3 0001 NaN view 2024-08-30 22:02:00 freq 333931 333963 NaN 726623 9 first NaN NaN NaN NaN 2022-10-06 13:23:00 last NaN NaN NaN NaN 2024-08-30 23:58:00 mean NaN NaN 1.998925e+00 NaN NaN std NaN NaN 8.164457e-01 NaN NaN min NaN NaN 1.000000e+00 NaN NaN 25% NaN NaN 1.000000e+00 NaN NaN 50% NaN NaN 2.000000e+00 NaN NaN 75% NaN NaN 3.000000e+00 NaN NaN max NaN NaN 3.000000e+00 NaN NaN
As you can notice, Pandas calculates statistics differently for various data types and provides unique values for all columns. Polars, on the other hand, calculates the null_count value.
We do not guarantee the output of describe to be stable. It will show statistics that we deem informative, and may be updated in the future. Using describe programmatically (versus interactive exploration) is not recommended for this reason.
Retrieving the First Five Records
When encountering data for the first time, we always want to explore it. Beyond obtaining summary statistics, it’s also important to see the actual records it contains. To do this, we often look at the first five records as a sample.
Polars has a useful glimpse() function that provides a dense preview of the DataFrame. It not only returns the first 10 records (or any number you specify using the max_items_per_column parameter) but also shows data types and record counts.
After exploring the data, it is often necessary to edit it for further use. If the column names are not satisfactory or if your company has its own naming conventions, you can easily rename them.
When working with data, optimizing their processing is often a priority, and data types are no exception. Choosing the right type not only unlocks available functions but also saves memory. In our example, I will change the column type of quantity from float to int. In Pandas, you would use the astype() method, while in Polars, you use the cast() method.
Although the method names for changing types differ, SQL enthusiasts will appreciate the ease of transition.
Filling Missing Values
In real projects, data is rarely perfect, and we often discuss with managers, analysts, and other systems how to interpret data behavior. During data preparation, I specifically generated corrupted_data to introduce some chaos into the data. Handling missing values could easily be the subject of an entire book.
There are several strategies for filling in missing values, and the choice of method depends on the task: sometimes filling missing values with zeros is sufficient, while other times the mean value may be used. In Polars, the fill_null() method can be applied both to the DataFrame and to specific columns. To add a new column or replace values in an existing one, the with_columns() method is also used.
In our example, I will fill missing values in the quantity column with 0:
In Polars, you can use various strategies for filling missing values in the data, such as: {None, ‘forward’, ‘backward’, ‘min’, ‘max’, ‘mean’, ‘zero’, ‘one’}. The names of these strategies are self-explanatory, so we won’t delve into their details.
It’s also worth noting that for filling NaN values in floating-point columns, you should use the fill_nan() method, which does not involve strategies.
Removing Missing Values
Not all missing values can be filled, so those that cannot be correctly filled and used in further calculations are best removed. In our case, this applies to the product_id column, as we cannot compute the final result without this identifier.
To remove rows with missing values in Pandas and Polars, use the following methods:
It’s also worth noting that to remove NaN values in floating-point columns, you should use the drop_nans() method.
Removing Duplicate Records
The simplest case of duplicate records occurs when all values of one record are identical to another. In our case, duplicates might arise if the same action is recorded multiple times for the same action type in the same online store at a single point in time. I will keep only the most recent value in case duplicates are found.
To remove duplicate records in Pandas, use the drop_duplicates() method, and in Polars, the unique() method.
After the data cleaning phase, we need to filter the relevant data for future calculations. In Polars, this is done using the method with a quite descriptive name, filter().
Rows where the filter does not evaluate to True are discarded, including nulls.
After filtering the data, you may need to retain only the columns relevant for further analysis. In Polars, this is achieved using the select() method.
After preparing the data, we can aggregate it to get the sum of quantity for each online store and product. I will also retain action_type for further steps. We use the group_by() method in Polars, which is similar to the groupby() method in Pandas.
To calculate the total purchases, we need to join our data with the price catalog. In Pandas, we have two methods for this, join() and merge(), which differ in their specifics and functionality. In Polars, we use only the join() method.
Our final step is to create a pivot table. We have already calculated the total sales for each product, and now we will easily calculate the total sales for each online store. In Pandas, we use the pivot_table() method, which allows for the application of aggregate functions. In Polars, we use the pivot() method to create the pivot table.
DeprecationWarning: The argument columns for pl.DataFrame.pivot` is deprecated. It has been renamed to on.
Here we are, concluding our little journey. As we can see, the results for both Pandas and Polars match. Everyone who made it to this point is great and incredibly hardworking — you will succeed!
Summary
In this article, we explored Polars using practical examples and comparisons with Pandas. I demonstrated how to handle data preparation, descriptive statistics, missing values, duplicates, filtering, column selection, grouping, merging, and pivot tables. By showcasing these tasks with both Pandas and Polars, I highlighted the ease of using Polars and transitioning to it from Pandas. This guide serves as a practical introduction to leveraging Polars for efficient data analysis.
If you enjoyed this article and want to support my work, the best way is to follow me on Medium. Let’s connect on LinkedIn if you’re also interested in working with data like I am. Your claps are greatly appreciated — they help me know how useful this post was for you.
Fans of “Fallout Shelter” rejoice, “The Elder Scrolls: Castles” has finally launched on Apple platforms, bringing the whimsical strategy sim format to Tamriel.
‘Elder Scrolls: Castles’ now on iPhone, iPad, Mac, and Apple Vision Pro
The long-awaited “Elder Scrolls: Castles” has finally launched on Apple platforms, including iPhone, iPad, Mac, and Apple Vision Pro. It is a similar format to the game “Fallout Shelter,” where players control and grow a society within the universe’s ruleset.
The premise of “The Elder Scrolls: Castles” is simple — manage a growing castle and make decisions to grow wealth, power, and respect. As your castle grows and years pass, your dynasty will grow.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.