Spot Bitcoin exchange-traded funds in the U.S. recorded outflows of over $300 million this week as global macroeconomic events sparked uncertainty over short-term direction. After closing the historically bearish September with over $1.1 billion in inflows, roughly $388.4 million moved…
Abdul Rafay Gadit made a move that is still seldom done in the banking world: He jumped from traditional finance, or TradFi, to decentralized finance, or DeFi. TradFi is highly regulated and emphasizes protecting consumers. Yet, it can be slow,…
The sharp price dip saw a quick turnaround, although recovery was not complete
The higher timeframe trend since April was bearish, but this uptrend could be the beginning of a rally
Bitcoin miners exiting the cycle may signal a market bottom, paving the way for fresh interest
And yet, specific conditions must align for a confirmed bull rally
As the meme coin scene gets hotter, Pepe (PEPE) is drawing attention with its market cap now at $4 billion, sparking discussions about its potential. PEPE isn’t alone in the spotlight—Shiba Inu (SHIB) is also seeing significant gains with a 25% increase. However, BlockDAG is witnessing massive inflows, with a notable $3M raised in just […]
Unpacking problem solving and tool-driven decision making in AI
Image by Author and GPT-4o depicting an AI agent at the intersection of reasoning and tool calling
Introduction: The Rise of Agentic AI
Today, new libraries and low-code platforms are making it easier than ever to build AI agents, also referred to as digital workers. Tool calling is one of the primary abilities driving the “agentic” nature of Generative AI models by extending their ability beyond conversational tasks. By executing tools (functions), agents can take action on your behalf and solve complex, multi-step problems that require robust decision making and interacting with a variety of external data sources.
This article focuses on how reasoning is expressed through tool calling, explores some of the challenges of tool use, covers common ways to evaluate tool-calling ability, and provides examples of how different models and agents interact with tools.
Expressions of Reasoning to Solve Problems
At the core of successful agents lie two key expressions of reasoning: reasoning through evaluation and planning and reasoning through tool use.
Reasoning through evaluation and planning relates to an agent’s ability to effectively breakdown a problem by iteratively planning, assessing progress, and adjusting its approach until the task is completed. Techniques like Chain-of-Thought (CoT), ReAct, and Prompt Decomposition are all patterns designed to improve the model’s ability to reason strategically by breaking down tasks to solve them correctly. This type of reasoning is more macro-level, ensuring the task is completed correctly by working iteratively and taking into account the results from each stage.
Reasoning through tool use relates to the agents ability to effectively interact with it’s environment, deciding which tools to call and how to structure each call. These tools enable the agent to retrieve data, execute code, call APIs, and more. The strength of this type of reasoning lies in the proper execution of tool calls rather than reflecting on the results from the call.
While both expressions of reasoning are important, they don’t always need to be combined to create powerful solutions. For example, OpenAI’s newo1 model excels at reasoning through evaluation and planning because it was trained to reason using chain of thought. This has significantly improved its ability to think through and solve complex challenges as reflected on a variety of benchmarks. For example, the o1 model has been shown to surpass human PhD-level accuracy on the GPQA benchmark covering physics, biology, and chemistry, and scored in the 86th-93rd percentile on Codeforces contests. While o1’s reasoning ability could be used to generate text-based responses that suggest tools based on their descriptions, it currently lacks explicit tool calling abilities (at least for now!).
In contrast, many models are fine-tuned specifically for reasoning through tool use enabling them to generate function calls and interact with APIs very effectively. These models are focused on calling the right tool in the right format at the right time, but are typically not designed to evaluate their own results as thoroughly as o1 might. The Berkeley Function Calling Leaderboard (BFCL) is a great resource for comparing how different models perform on function calling tasks. It also provides an evaluation suite to compare your own fine-tuned model on various challenging tool calling tasks. In fact, the latest dataset, BFCL v3, was just released and now includes multi-step, multi-turn function calling, further raising the bar for tool based reasoning tasks.
Both types of reasoning are powerful independently, and when combined, they have the potential to create agents that can effectively breakdown complicated tasks and autonomously interact with their environment. For more examples of AI agent architectures for reasoning, planning, and tool calling check out my team’s survey paper on ArXiv.
Challenges with Tool-Calling: Navigating Complex Agent Behaviors
Building robust and reliable agents requires overcoming many different challenges. When solving complex problems, an agent often needs to balance multiple tasks at once including planning, interacting with the right tools at the right time, formatting tool calls properly, remembering outputs from previous steps, avoiding repetitive loops, and adhering to guidance to protect the system from jailbreaks/prompt injections/etc.
Too many demands can easily overwhelm a single agent, leading to a growing trend where what may appear to an end user as one agent, is behind the scenes a collection of many agents and prompts working together to divide and conquer completing the task. This division allows tasks to be broken down and handled in parallel by different models and agents tailored to solve that particular piece of the puzzle.
It’s here that models with excellent tool calling capabilities come into play. While tool-calling is a powerful way to enable productive agents, it comes with its own set of challenges. Agents need to understand the available tools, select the right one from a set of potentially similar options, format the inputs accurately, call tools in the right order, and potentially integrate feedback or instructions from other agents or humans. Many models are fine-tuned specifically for tool calling, allowing them to specialize in selecting functions at the right time with high accuracy.
Some of the key considerations when fine-tuning a model for tool calling include:
Proper Tool Selection: The model needs to understand the relationship between available tools, make nested calls when applicable, and select the right tool in the presence of other similar tools.
Handling Structural Challenges: Although most models use JSON format for tool calling, other formats like YAML or XML can also be used. Consider whether the model needs to generalize across formats or if it should only use one. Regardless of the format, the model needs to include the appropriate parameters for each tool call, potentially using results from a previous call in subsequent ones.
Ensuring Dataset Diversity and Robust Evaluations: The dataset used should be diverse and cover the complexity of multi-step, multi-turn function calling. Proper evaluations should be performed to prevent overfitting and avoid benchmark contamination.
Common Benchmarks to Evaluate Tool-Calling
With the growing importance of tool use in language models, many datasets have emerged to help evaluate and improve model tool-calling capabilities. Two of the most popular benchmarks today are the Berkeley Function Calling Leaderboard and Nexus Function Calling Benchmark, both of which Meta used to evaluate the performance of their Llama 3.1 model series. A recent paper, ToolACE, demonstrates how agents can be used to create a diverse dataset for fine-tuning and evaluating model tool use.
Let’s explore each of these benchmarks in more detail:
Berkeley Function Calling Leaderboard (BFCL): BFCL contains 2,000 question-function-answer pairs across multiple programming languages. Today there are 3 versions of the BFCL dataset each with enhancements to better reflect real-world scenarios. For example, BFCL-V2, released August 19th, 2024 includes user contributed samples designed to address evaluation challenges related to dataset contamination. BFCL-V3 released September 19th, 2024 adds multi-turn, multi-step tool calling to the benchmark. This is critical for agentic applications where a model needs to make multiple tool calls over time to successfully complete a task. Instructions for evaluating models on BFCL can be found on GitHub, with the latest dataset available on HuggingFace, and the current leaderboard accessible here. The Berkeley team has also released various versions of their Gorilla Open-Functions model fine-tuned specifically for function-calling tasks.
Nexus Function Calling Benchmark: This benchmark evaluates models on zero-shot function calling and API usage across nine different tasks classified into three major categories for single, parallel, and nested tool calls. Nexusflow released NexusRaven-V2, a model designed for function-calling. The Nexus benchmark is available on GitHub and the corresponding leaderboard is on HuggingFace.
ToolACE: The ToolACE paper demonstrates a creative approach to overcoming challenges related to collecting real-world data for function-calling. The research team created an agentic pipeline to generate a synthetic dataset for tool calling consisting of over 26,000 different APIs. The dataset includes examples of single, parallel, and nested tool calls, as well as non-tool based interactions, and supports both single and multi-turn dialogs. The team released a fine-tuned version of Llama-3.1–8B-Instruct, ToolACE-8B, designed to handle these complex tool-calling related tasks. A subset of the ToolACE dataset is available on HuggingFace.
Each of these benchmarks facilitates our ability to evaluate model reasoning expressed through tool calling. These benchmarks and fine-tuned models reflect a growing trend towards developing more specialized models for specific tasks and increasing LLM capabilities by extending their ability to interact with the real-world.
Examples of Tool-Calling in Action
If you’re interested in exploring tool-calling in action, here are some examples to get you started organized by ease of use, ranging from simple built-in tools to using fine-tuned models, and agents with tool-calling abilities.
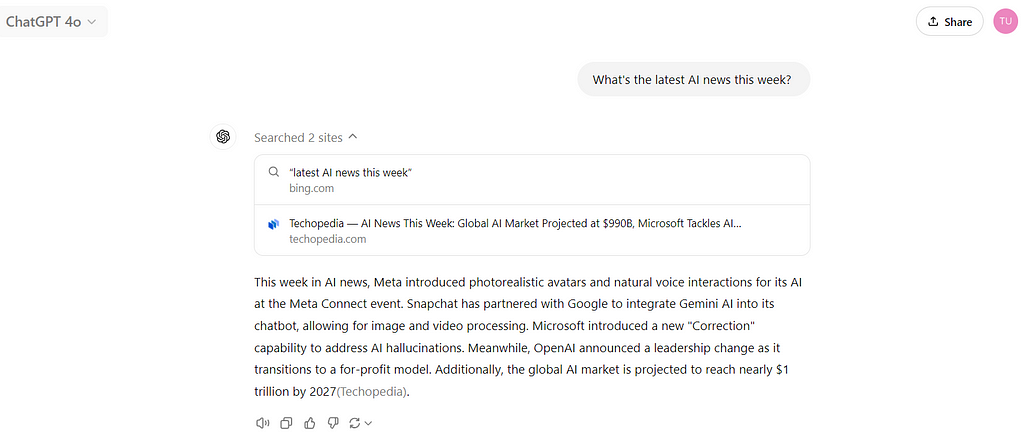
Level 1 — ChatGPT: The best place to start and see tool-calling live without needing to define any tools yourself, is through ChatGPT. Here you can use GPT-4o through the chat interface to call and execute tools for web-browsing. For example, when asked “what’s the latest AI news this week?” ChatGPT-4o will conduct a web search and return a response based on the information it finds. Remember the new o1 model does not have tool-calling abilities yet and cannot search the web.
Image by author 9/30/24
While this built-in web-searching feature is convenient, most use cases will require defining custom tools that can integrate directly into your own model workflows and applications. This brings us to the next level of complexity.
Level 2 — Using a Model with Tool Calling Abilities and Defining Custom Tools:
This level involves using a model with tool-calling abilities to get a sense of how effectively the model selects and uses it’s tools. It’s important to note that when a model is trained for tool-calling, it only generates the text or code for the tool call, it does not actually execute the code itself. Something external to the model needs to invoke the tool, and it’s at this point — where we’re combining generation with execution — that we transition from language model capabilities to agentic systems.
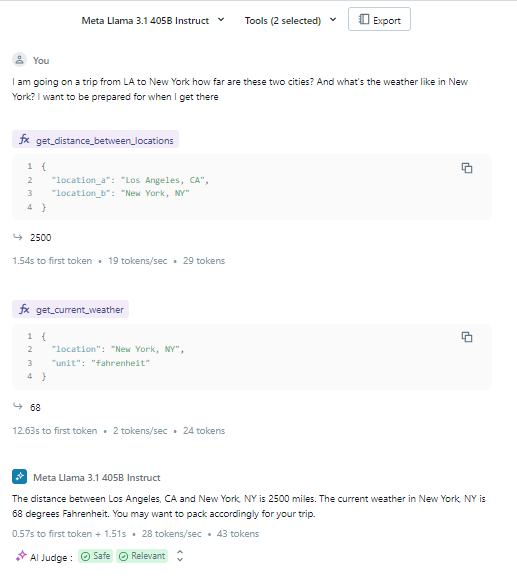
To get a sense for how models express tool calls we can turn towards the Databricks Playground. For example, we can select the model Llama 3.1 405B and give it access to the sample tools get_distance_between_locations and get_current_weather. When prompted with the user message “I am going on a trip from LA to New York how far are these two cities? And what’s the weather like in New York? I want to be prepared for when I get there” the model decides which tools to call and what parameters to pass so it can effectively reply to the user.
Image by author 10/2/2024 depicting using the Databricks Playground for sample tool calling
In this example, the model suggests two tool calls. Since the model cannot execute the tools, the user needs to fill in a sample result to simulate the tool output (e.g., “2500” for the distance and “68” for the weather). The model then uses these simulated outputs to reply to the user.
This approach to using the Databricks Playground allows you to observe how the model uses custom defined tools and is a great way to test your function definitions before implementing them in your tool-calling enabled applications or agents.
Outside of the Databricks Playground, we can observe and evaluate how effectively different models available on platforms like HuggingFace use tools through code directly. For example, we can load different models like Llama 3.2–3B-Instruct, ToolACE-8B, NexusRaven-V2–13B, and more from HuggingFace, give them the same system prompt, tools, and user message then observe and compare the tool calls each model returns. This is a great way to understand how well different models reason about using custom-defined tools and can help you determine which tool-calling models are best suited for your applications.
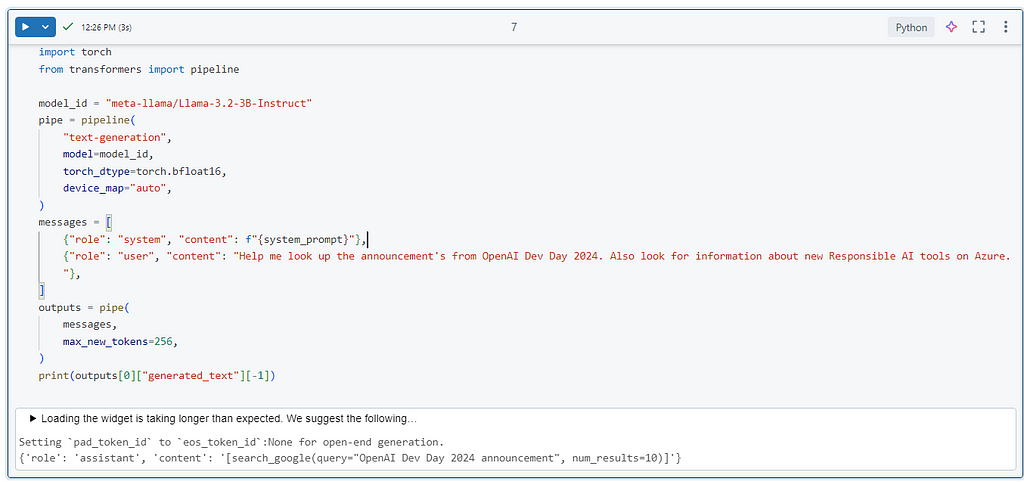
Here is an example demonstrating a tool call generated by Llama-3.2–3B-Instruct based on the following tool definitions and user message, the same steps could be followed for other models to compare generated tool calls.
import torch from transformers import pipeline
function_definitions = """[ { "name": "search_google", "description": "Performs a Google search for a given query and returns the top results.", "parameters": { "type": "dict", "required": [ "query" ], "properties": { "query": { "type": "string", "description": "The search query to be used for the Google search." }, "num_results": { "type": "integer", "description": "The number of search results to return.", "default": 10 } } } }, { "name": "send_email", "description": "Sends an email to a specified recipient.", "parameters": { "type": "dict", "required": [ "recipient_email", "subject", "message" ], "properties": { "recipient_email": { "type": "string", "description": "The email address of the recipient." }, "subject": { "type": "string", "description": "The subject of the email." }, "message": { "type": "string", "description": "The body of the email." } } } } ] """
# This is the suggested system prompt from Meta system_prompt = """You are an expert in composing functions. You are given a question and a set of possible functions. Based on the question, you will need to make one or more function/tool calls to achieve the purpose. If none of the function can be used, point it out. If the given question lacks the parameters required by the function, also point it out. You should only return the function call in tools call sections.
If you decide to invoke any of the function(s), you MUST put it in the format of [func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)]n You SHOULD NOT include any other text in the response.
Here is a list of functions in JSON format that you can invoke.nn{functions}n""".format(functions=function_definitions)
Image by author sample output demonstrating generated tool call from Llama 3.2–3B-Instruct
From here we can move to Level 3 where we’re defining Agents that execute the tool-calls generated by the language model.
Level 3 Agents (invoking/executing LLM tool-calls): Agents often express reasoning both through planning and execution as well as tool calling making them an increasingly important aspect of AI based applications. Using libraries like LangGraph, AutoGen, Semantic Kernel, or LlamaIndex, you can quickly create an agent using models like GPT-4o or Llama 3.1–405B which support both conversations with the user and tool execution.
Check out these guides for some exciting examples of agents in action:
The future of agentic systems will be driven by models with strong reasoning abilities enabling them to effectively interact with their environment. As the field evolves, I expect we will continue to see a proliferation of smaller, specialized models focused on specific tasks like tool-calling and planning.
It’s important to consider the current limitations of model sizes when building agents. For example, according to the Llama 3.1 model card, the Llama 3.1–8B model is not reliable for tasks that involve both maintaining a conversation and calling tools. Instead, larger models with 70B+ parameters should be used for these types of tasks. This alongside other emerging research for fine-tuning small language models suggests that smaller models may serve best as specialized tool-callers while larger models may be better for more advanced reasoning. By combining these abilities, we can build increasingly effective agents that provide a seamless user experience and allow people to leverage these reasoning abilities in both professional and personal endeavors.
Interested in discussing further or collaborating? Reach out on LinkedIn!
Save big ahead of Best Buy’s 48-hour Flash Sale coming up Oct. 8-9: The retailer is already offering deals on TVs, laptops, appliances, and more, rivaling Prime Day.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.