The rise of play-to-earn (P2E) gaming has transformed the global gaming industry, and Rocky Rabbit is leading the charge with its innovative platform built on The Open Network (TON) blockchain. As more people embrace the concept of earning through gaming, Rocky Rabbit has solidified its position as one of the most engaging Toncoin (TON)-based entertainment […]
7 steps that helped me transition from a software engineer to machine learning engineer
I receive a lot of inquiries (a LOT) about how to transition from a software engineer to a machine learning engineer (MLE) at FAANG companies. Having successfully transitioned myself, I can say that the biggest challenge I faced was not knowing where to start and feeling lost without a clear plan.
In this article, I am sharing the step-by-step approach that will help you navigate this change. These 7 steps helped me transition from a software engineer to Machine Learning engineer.
Let’s dive in.
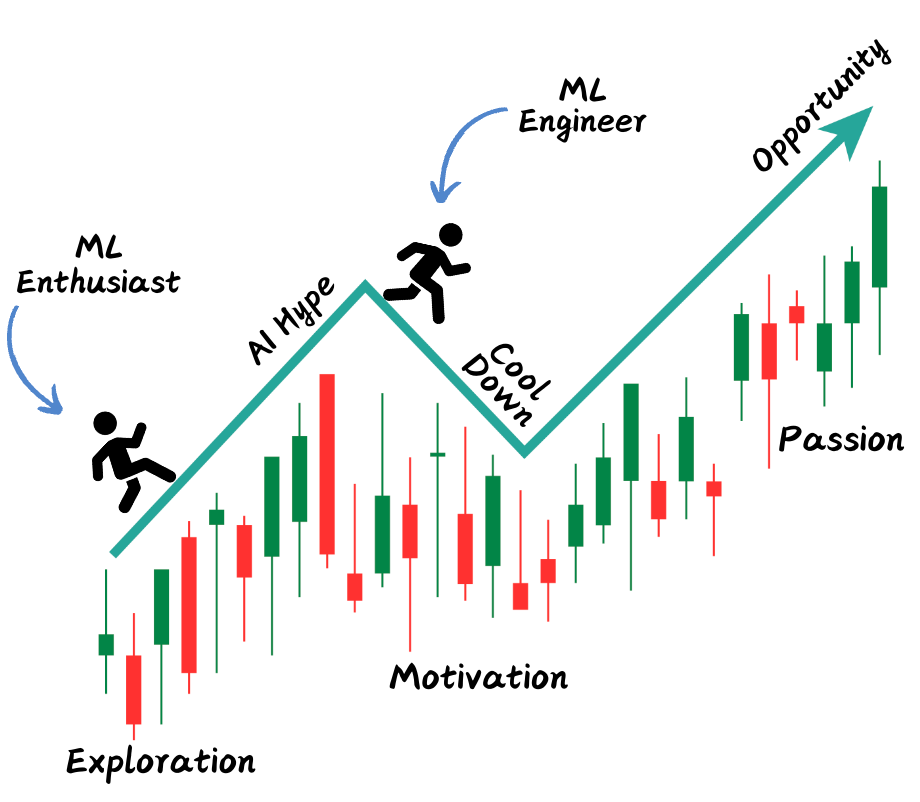
1. Motivation
Image by Author
Find out why
Why Machine Learning? Machine Learning and AI are super hot right now, but you should understand why you want to get into it. This personal motivation will keep you going even when the AI hype dies down.
What Got Me Hooked: For me, it was about how Google search was developed. The way Google could find exactly what I needed so quickly really made me want to know more about the tech behind it. That curiosity got me into Learning to Rank algorithms starting with PageRank and then broader machine learning.
Questions to Ask Yourself:
What part of Machine Learning really grabs my interest? Is it the hot trend or something else?
Are there any specific ML applications I like? For me it is Natural Language Processing and Recommendations, but maybe you’re into using ML in FinTech.
Take Your Time to Explore
It took me 4 years (1 year in Masters, 1 year in PhD where I dropped out, and 2 years in the industry) to realize what I really wanted to do. This is ok. It takes time to build experience and know enough about a new field which is as big as ML.
Build the Basics: Start with the fundamentals like statistics and machine learning basics. This solid base will help you get a better grasp of the field and find the area you’re most excited about.
Networking and Mentorship: Chat with people who are already in the field, find some mentors working around you, and get a feel of their day-to-day work to see if it excites you.
Understand Your Options: Find out what kind of ML role interests you, whether that’s being an Applied ML Engineer, ML Researcher, or working in MLOps. Learn about different roles in one of my previous article here.
2. Find Your Niche
Understanding your motivations and interests will naturally lead you to identify where you can best apply your skills within the ML landscape.
Be Strategic: Often ML roles will have certain required qualifications like 5 years of relevant industry experience or PhD. If your experience does not match with the required qualifications, it may not be the right fit at that time. Focus on building your skills step by step and find roles strategically that aligns more with your current experience.
Find the Sweet Spot: If possible,use your current domain knowledge to your advantage.Transitioning within a domain you’re already familiar with is easier. As a software engineer, you are already aware of critical metrics, business goals and domain specific problems. Identify where you can contribute the most, take ownership, and aim to lead in that area.
I started working as a software engineer in the Amazon Pricing team. Even though Pricing as a domain was not my preferred choice, but due to extensive amount of experience I acquired there, it helped me to transition to MLE much faster.
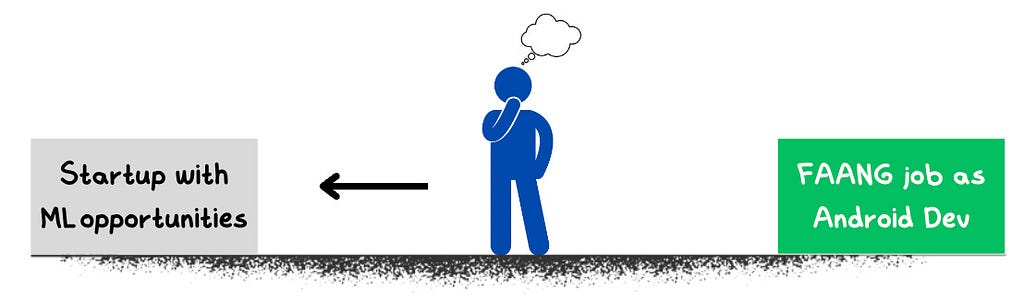
3. Be open to compromises
Image by Author
In your career, you’ll sometimes face decisions that require short-term sacrifices for long-term gains, especially when entering a new field. Here are some tough choices I had to make during my switch:
Rejected my dream company Google’s offer twice: I received offer letters from Google, which offered a higher salary, but I turned them down because the role involved Android development, which had no ML opportunities. Instead, I chose Amazon, where the role didn’t initially involve ML either but allowed me to work more closely with ML teams. To date, the best choice I have made in my life!!
Delayed my promotion for almost 3 years: I had the chance to be promoted to senior software engineer at Amazon much sooner. A senior software engineer transition to a senior MLE is much harder due to increased expectations. Knowing this, I chose to delay my promotion to keep my options open.
4. Find a supportive manager / company
If you’ve pinned down a domain you’re passionate about, you’ll still need a supportive manager and company to make the transition successfully.
Find the Right Environment:
Look for ML Opportunities: Seek out teams within your company that offer the chance to work on ML projects. Join a team that has both software engineering and ML teams working closely, luckily most teams are like that. If your current company lacks these opportunities, consider looking outside.
Tip: Find teams that has transitioned Software Engineers to MLEs in the past. This can greatly accelerate your transition as these teams often have a clear guideline for the transition.
Find a Supportive Manager: A manager familiar with ML roles and who is supportive of your learning and career growth is crucial. They should not only support you verbally but also take active steps to facilitate your transition.
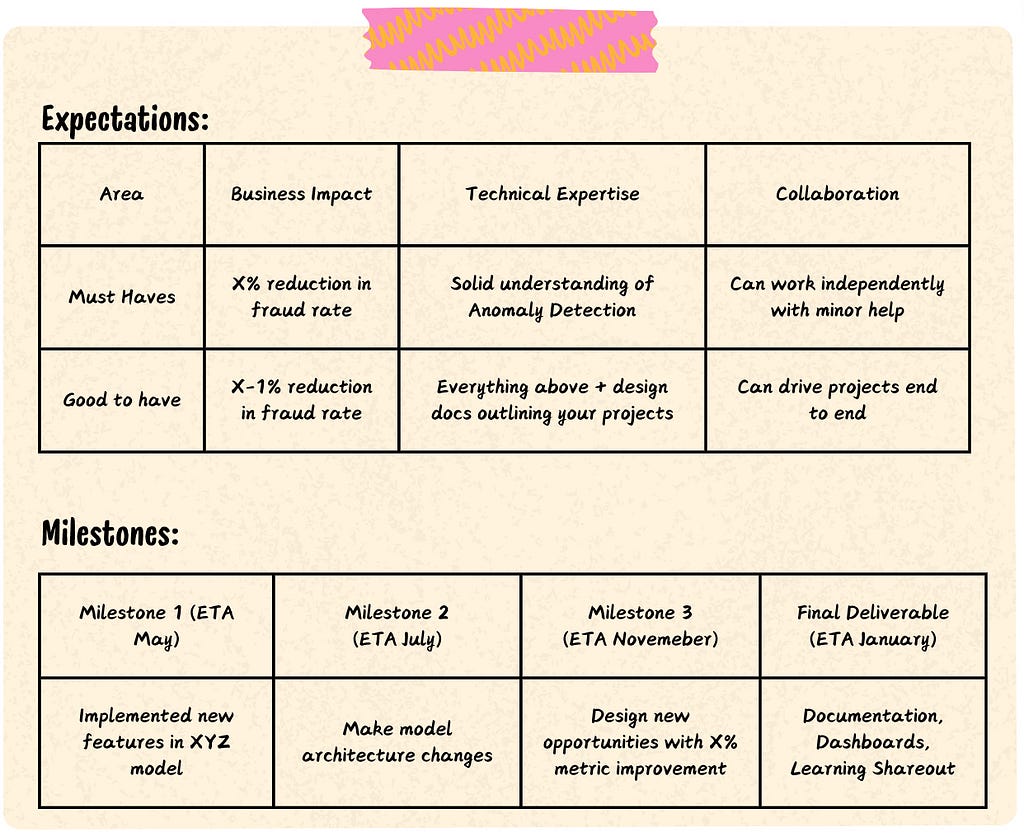
Tip: Always draft a document outlining your transition plan and the projects you’d like to work on and discuss in your 1:1s with your manager. If they repeatedly show disinterest, they might not be motivated to help you switch roles.
Image by Author: Sample Transition Plan
5. Gain trust by being a reliable software engineer
In my first team at Amazon, I gave my 200% as a software engineer, even though the role wasn’t my ideal choice. My goal was to make myself indispensable, allowing me to choose the projects I wanted to work on. This effort built a trusting relationship with my manager, where we valued each other’s advice.
Why is this important? Typically, only top engineers get to choose their projects, while others must tackle the tasks assigned to them. Demonstrating reliability can give you opportunities that might otherwise be unattainable and give you more control over your career path.
6. Work on projects
Once you’ve joined a team with ML opportunities, a supportive manager, and relevant domain space, it’s time to apply your foundational knowledge.
Work on small projects on the side:
Collaborate with experienced ML engineers to work on small features for model training or minor model changes. These tasks might fall outside your primary job responsibilities.
For instance, I worked on a project to improve the AWS SageMaker training pipeline in my team at Amazon. This allowed me to work more closely with ML engineers in the team, understand their development process and contribute to development of new features in upcoming model iterations.
Expand Your Scope:
As you gain confidence in the problem space, begin to explore the broader domain. Research extensively to understand the challenges and limitations of current system and identify potential areas for improvement.
Tip: Read blogs and research articles from other companies within the same space to understand challenges faced by companies to get potential ideas for improvement. For example when I was at Amazon, I followed tech articles from other eCommerce platforms like eBay and Walmart.
This is your opportunity to think creatively and identify original solutions. Maintain a detailed document to track all your learnings throughout this. Include design documents, technical insights, practical challenges, solutions you’ve implemented, and any feedback or evaluations you receive. Not only is it a valuable learning tool to keep track of your learning, but it also acts as tangible evidence during your transition evaluation.
7. Understand Performance Evaluation
Transitions like promotions are lagging indicators, meaning that any new role requires the individual to already be performing at the level expected for that role. Identify the criteria that will be used for evaluation during your transition to an MLE role. Generally, Software Engineers and MLEs are evaluated differently during performance feedback sessions.
With Software Engineer, often the emphasis is more on scalable system design, code quality and project complexity. With MLE, generally the emphasis is much more on Impact to the business metric and technical expertise. This is because, ML has a longer cycle of development compared to software engineering and are often directly tied to specific business metrics.
Parting Note
The Software Engineer to MLE transition can be as challenging as it is rewarding. It requires a blend of strategic planning, continuous learning, and adaptability.
Few more bonus tips:
Find a Mentor: Seek out a mentor within the team where you are making the transition. This mentor will support you throughout your transition process, help resolve any blockers, and identify new opportunities for you.
Track Your Learnings: Maintain a detailed record of all your learnings throughout your transition. This documentation will allow you to revisit and refine ideas and also act as a reference during performance evaluations.
Communicate Proactively: Regularly communicate with your team and manager about both the challenges you encounter and the successes you achieve. Open communication will help in adjusting strategies as needed and ensure continued support from your team.
These strategies have been instrumental in navigating my career transition effectively. By following above steps, you can improve your journey and set a solid foundation for success in your new role as a Machine Learning Engineer.
Best of luck and as always Happy Learning!
If this article was helpful to you and you want to learn more about real-world tips for Machine Learning, Sign up for my newsletter or connect with me on LinkedIn.
Disclaimer: This blog is based on personal experiences and publicly available resources. Please note, the opinions expressed are solely my own and do not represent those of my past or current employers. Always refer to official resources and guidelines from hiring companies for the most accurate information.
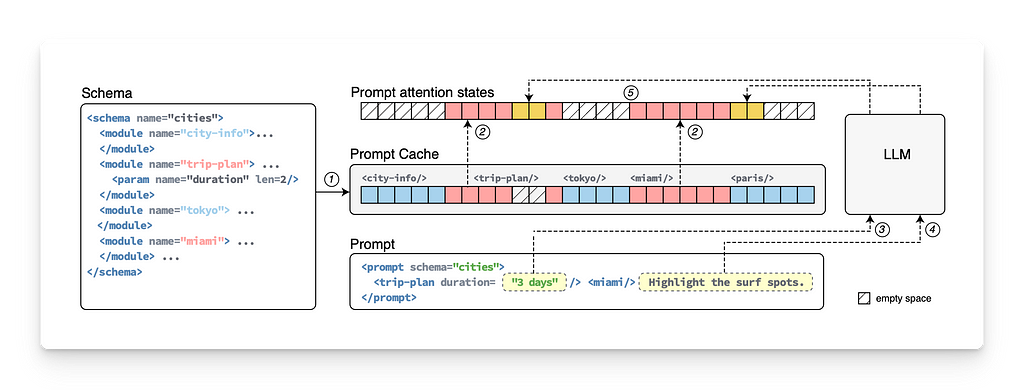
A brief tour of how caching works in attention-based models
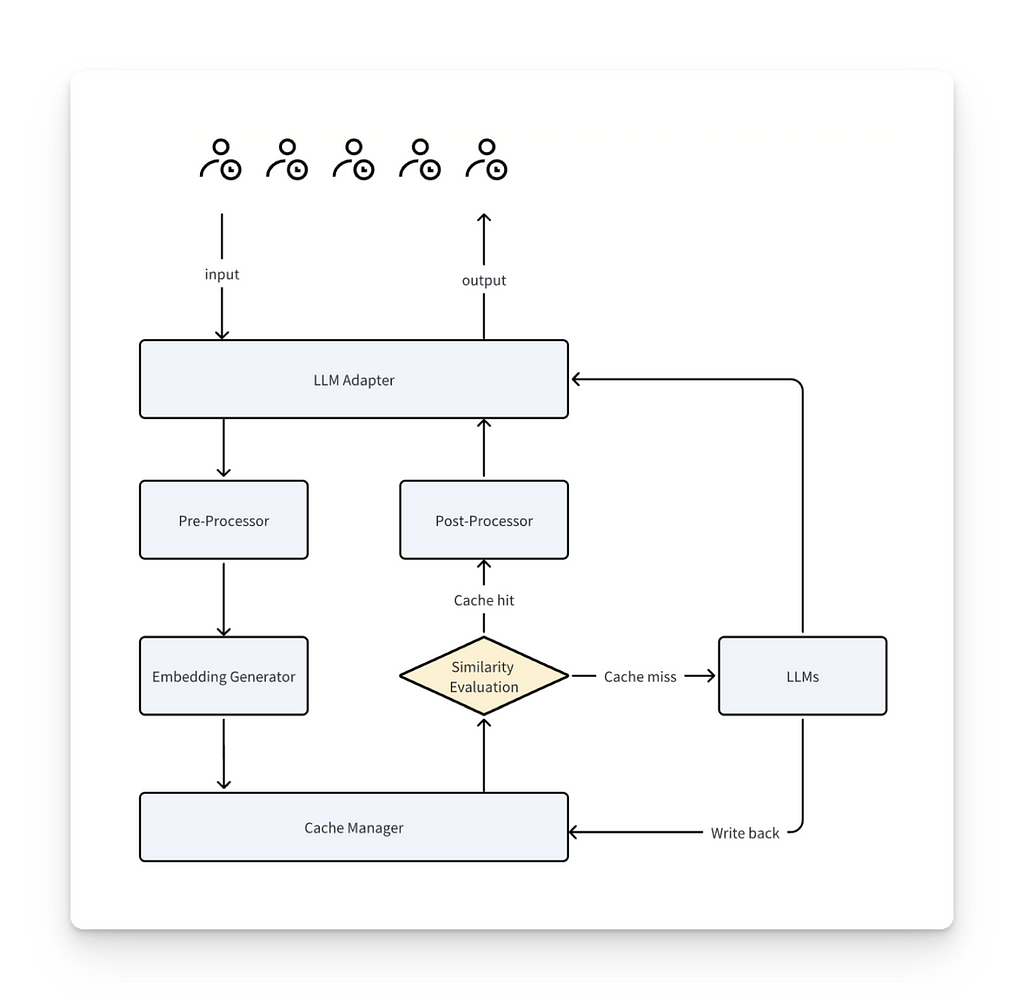
Image by Author using ChatGPT
I’ve been exploring articles about how Prompt Caching works, and while a few blogs touch on its usefulness and how to implement it, I haven’t found much on the actual mechanics or the intuition behind it.
The question really comes down to this: GPT-like model generation relies on the relationships between every token in a prompt. How could caching just part of a prompt even make sense?
Surprisingly, it does. Let’s dive in!
Prompt caching has recently emerged as a significant advancement in reducing computational overhead, latency, and cost, especially for applications that frequently reuse prompt segments.
To clarify, these are cases where you have a long, static pre-prompt (context) and keep adding new user questions to it. Each time the API model is called, it needs to completely re-process the entire prompt.
Google was the first to introduce Context Caching with the Gemini model, while Anthropic and OpenAI have recently integrated their prompt caching capabilities, claiming great cost and latency reduction for long prompts.
What is Prompt Caching?
Prompt caching is a technique that stores parts of a prompt (such as system messages, documents, or template text) to be efficiently reused. This avoids reprocessing the same prompt structure repeatedly, improving efficiency.
There are multiple ways to implement Prompt Caching, so the techniques can vary by provider, but we’ll try to abstract the concept out of two popular approaches:
When a prompt comes in, it goes through tokenization, vectorization, and full model inference (typically an attention model for LLMs).
The system stores the relevant data (tokens and their embeddings) in a cache layer outside the model. The numerical vector representation of tokens is stored in memory.
On the next call, the system checks if a part of the new prompt is already stored in the cache (e.g., based on embedding similarity).
Upon a cache hit, the cached portion is retrieved, skipping both tokenization and full model inference.
In its most basic form, different levels of caching can be applied depending on the approach, ranging from simple to more complex. This can include storing tokens, token embeddings, or even internal states to avoid reprocessing:
Tokens: The next level involves caching the tokenized representation of the prompt, avoiding the need to re-tokenize repeated inputs.
Token Encodings: Caching these allows the model to skip re-encoding previously seen inputs and only process the new parts of the prompt.
Internal States: At the most complex level, caching internal states such as key-value pairs (see below) stores relationships between tokens, so the model only computes new relationships.
Caching Key-Value States
In transformer models, tokens are processed in pairs: Keys and Values.
Keys help the model decide how much importance or “attention” each token should give to other tokens.
Values represent the actual content or meaning that the token contributes in context.
For example, in the sentence “Harry Potter is a wizard, and his friend is Ron,” the Key for “Harry” is a vector with relationships with each one of the other words in the sentence:
Precompute and Cache KV States: The model computes and stores KV pairs for frequently used prompts, allowing it to skip re-computation and retrieve these pairs from the cache for efficiency.
Merging Cached and New Context: In new prompts, the model retrieves cached KV pairs for previously used sentences while computing new KV pairs for any new sentences.
Cross-Sentence KV Computation: The model computes new KV pairs that link cached tokens from one sentence to new tokens in another, enabling a holistic understanding of their relationships.
All of the relationships between tokens of the cached prompt are already computed. Only new relationships between NEW-OLD or NEW-NEW tokens must be computed.
Is This the End of RAG?
As models’ context sizes increase, prompt caching will make a great difference by avoiding repetitive processing. As a result, some might lean toward just using huge prompts and skipping retrieval processes entirely.
But here’s the catch: as contexts grow, models lose focus. Not because models will do a bad job but because finding answers in a big chunk of data is a subjective task that depends on the use case needs.
Systems capable of storing and managing vast volumes of vectors will remain essential, and RAG goes beyond caching prompts by offering something critical: control.
With RAG, you can filter and retrieve only the most relevant chunks from your data rather than relying on the model to process everything. A modular, separated approach ensures less noise, giving you more transparency and precision than full context feeding.
Finally, larger context models emerging will probably ask for better storage for prompt vectors instead of simple caching. Does that take us back to… vector stores?
At Langflow, we’re building the fastest path from RAG prototyping to production. It’s open-source and features a free cloud service! Check it out at https://github.com/langflow-ai/langflow ✨
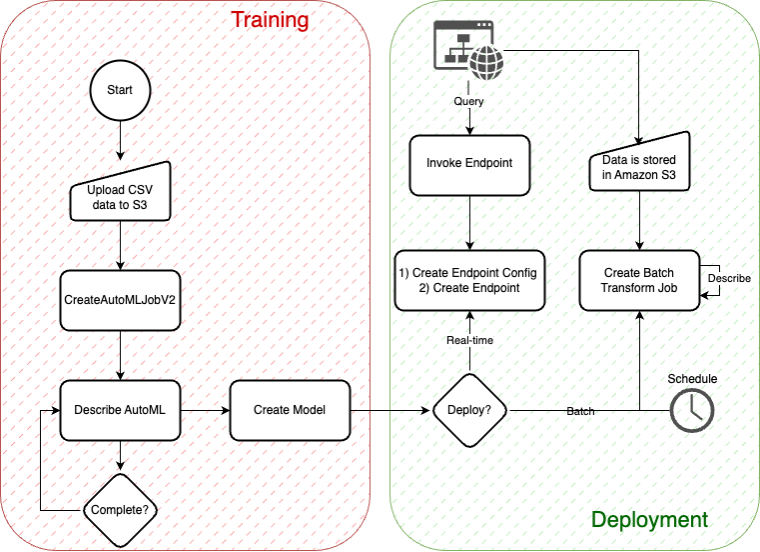
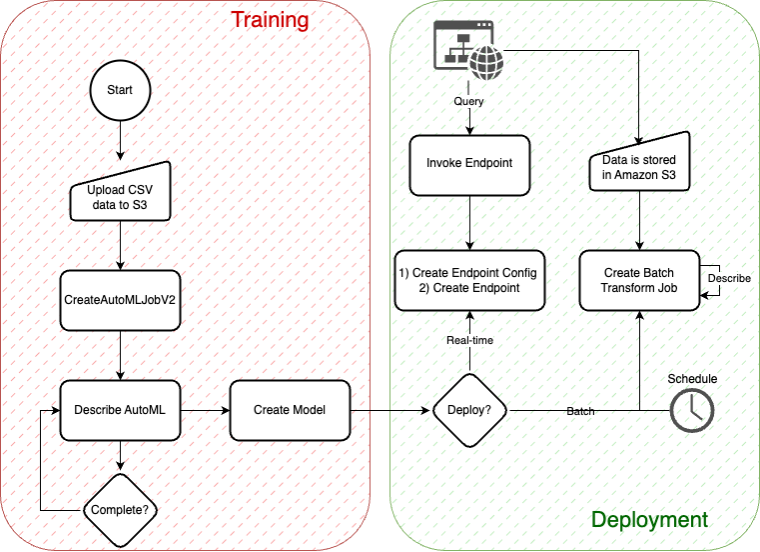
In this blog post, we explore a comprehensive approach to time series forecasting using the Amazon SageMaker AutoMLV2 Software Development Kit (SDK). SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from data preparation to model deployment.
In this post, we present a solution that harnesses the power of generative AI to streamline the user onboarding process for financial services through a digital assistant.
Two more retailers are joining the many others that support Apple Pay in the United States, with H-E-B adding and Home Depot quietly returning support to their stores.
Apple Pay
Apple Pay will be celebrating the tenth anniversary of its launch in the United States on October 20. Just in time for the milestone, two more retailers are finally adopting the mobile payments platform in their retail stores.
A press release from the Texas-based H-E-B grocery chain confirms that there will be a phased rollout of digital tap-to-pay services across its 380 outlets. This includes support for Apple Pay, along with Samsung Pay and Google Pay.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.