Web3 investigator ZachXBT reveals what he claims to be 11 Ethereum and Solana wallets belonging to Murad Mahmudov, a crypto trader who has been actively promoting memecoins on his socials. On an Oct. 8 X post, crypto sleuth ZachXBT claimed…
Taiwan’s financial watchdog reportedly plans to launch a pilot program for crypto custody services, with three banks already expressing interest. Taiwan‘s Financial Supervisory Commission is set to launch a pilot program for crypto custody services, aiming to stimulate institutional adoption…
U.S. political developments to play a role in defining the crypto market trajectory in Q4 and beyond.
SOL and other unproven cryptocurrencies will likely lag ETH and BTC under Harris’s presiden
BNB bulls demonstrate dominance by pushing higher as most top coins face sell pressure.
Binance smart chain yield farming demand could be one of the key reasons behind BNB’s upside.
Render price remains in a stable range near $5.50 after a period of consolidation and rising whale activity.
The long-short ratio decline and OI-weighted funding rate indicate potential shifts
Bitcoin Dogs has set a firm date for the release of its Telegram game, and analysts expect its release to fuel a wild Q4. October 30th is the day all 0DOG holders have marked in their calendars, and w
Coded Estate has achieved a significant milestone by closing an oversubscribed angel funding round, attracting investments from notable players such as Mozaik Capital, Hyperion Ventures, Black Dragon, Dutch Crypto Investors, and others. Coded Estate has officially unveiled its “Pre-Season Mainnet Campaign,” a strategic initiative designed to inject early liquidity into the platform and pave the […]
Azure Data Factory (ADF) is a popular tool for moving data at scale, particularly in Enterprise Data Lakes. It is commonly used to ingest and transform data, often starting by copying data from on-premises to Azure Storage. From there, data is moved through different zones following a medallion architecture. ADF is also essential for creating and restoring backups in case of disasters like data corruption, malware, or account deletion.
This implies that ADF is used to move large amounts of data, TBs and sometimes even PBs. It is thus important to optimize copy performance and so to limit throughput time. A common way to improve ADF performance is to parallelize copy activities. However, the parallelization shall happen where most of the data is and this can be challenging when the data lake is skewed.
Data Lakes come in all sizes and manners. It is important to understand the data distribution within a data lake to improve copy performance. Consider the following situation:
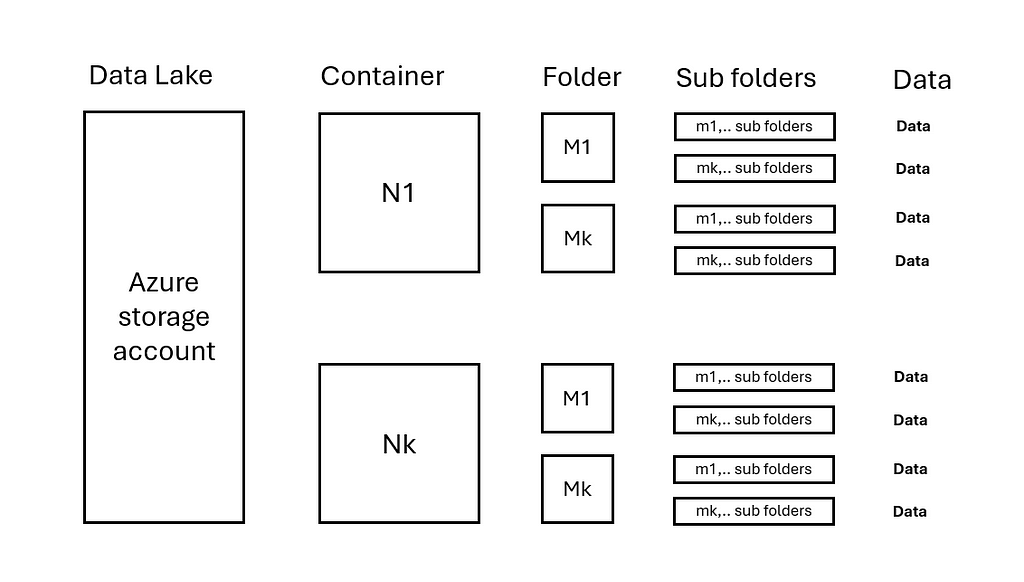
An Azure Storage account has N containers.
Each container contains M folders and m levels of sub folders.
Data is evenly distributed in folders N/M/..
See also image below:
2.1 Data lake with uniformly distributed data — image by author
In this situation, copy activities can be parallelized on each container N. For larger data volumes, performance can be further enhanced by parallelizing on folders M within container N. Subsequently, per copy activity it can be configured how much Data Integration Units (DIU) and copy parallelizationwithin a copy activity is used.
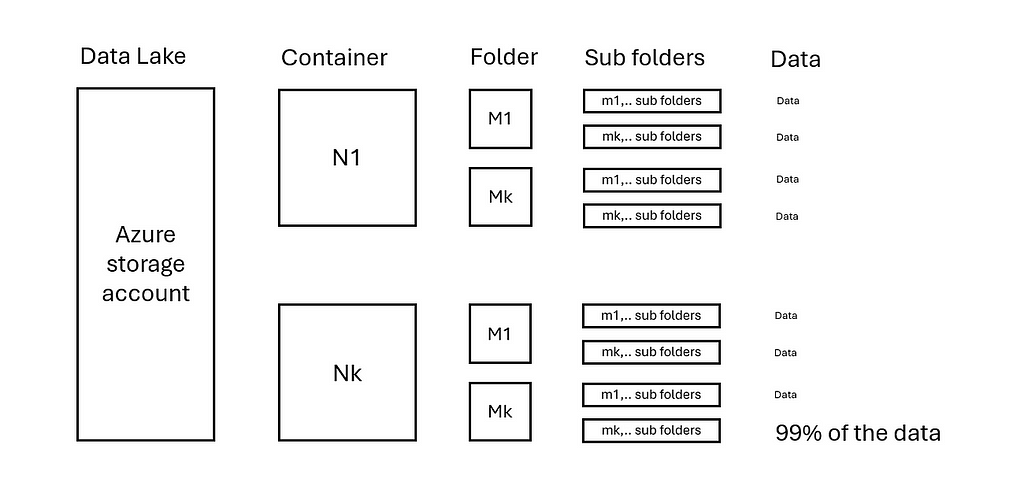
Now consider the following extreme situation that the last folder Nk and Mk has 99% of data, see image below:
2.2 Data lake with skewed distributed data — image by author
This implies that parallelization shall be done on the sub folders in Nk/Mk where the data is. More advanced logic is then needed to pinpoint the exact data locations. An Azure Function, integrated within ADF, can be used to achieve this. In the next chapter a project is deployed and are the parallelization options discussed in more detail.
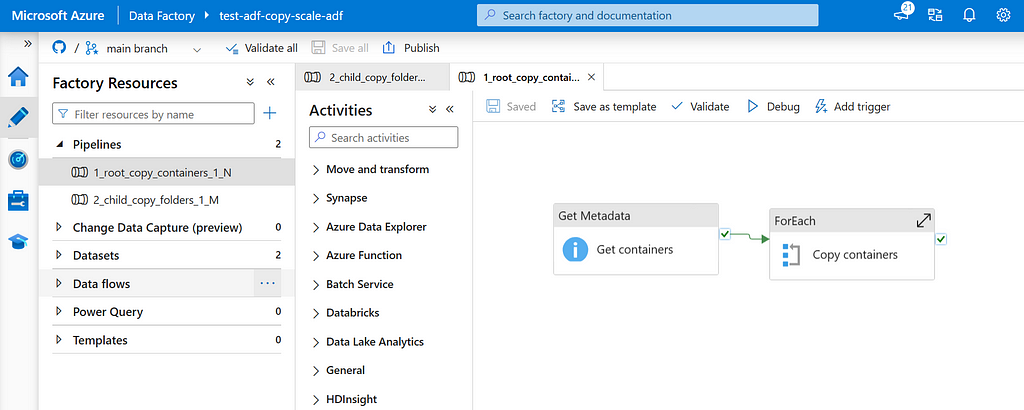
Run the script deploy_adf.ps1. In case ADF is successfully deployed, there are two pipelines deployed:
3.1.1 Data Factory project with root and child pipeline — image by author
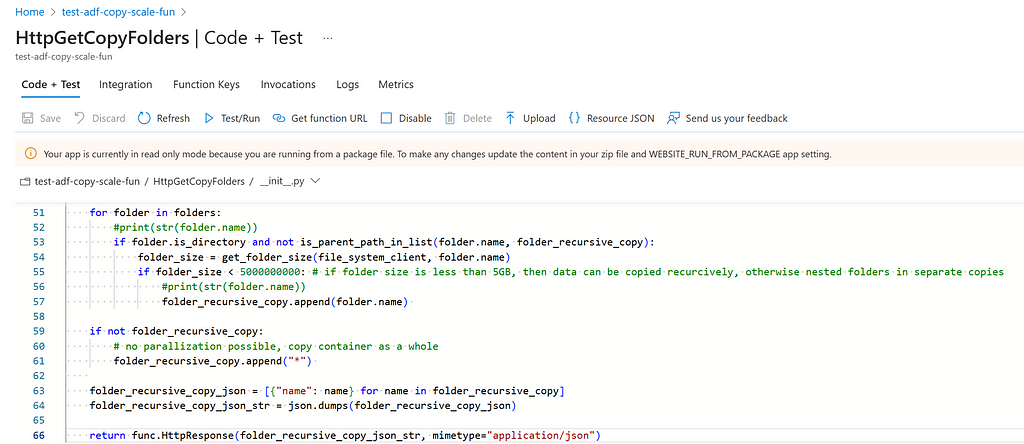
Subsequently, run the script deploy_azurefunction.ps1. In case the Azure Function is successfully deployed, the following code is deployed.
3.1.2 Azure Function to find “pockets of data” such that ADF can better parallelize
To finally run the project, make sure that the system assigned managed identity of the Azure Function and Data Factory can access the storage account where the data is copied from and to.
3.2 Parallelization used in project
After the project is deployed, it can be noticed that the following tooling is deployed to improve the performance using parallelization.
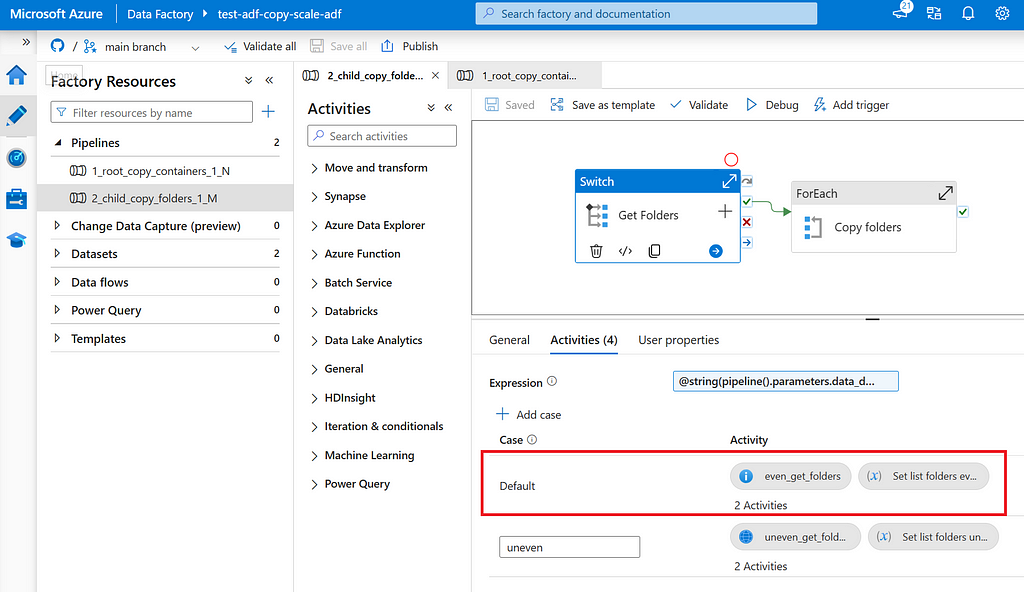
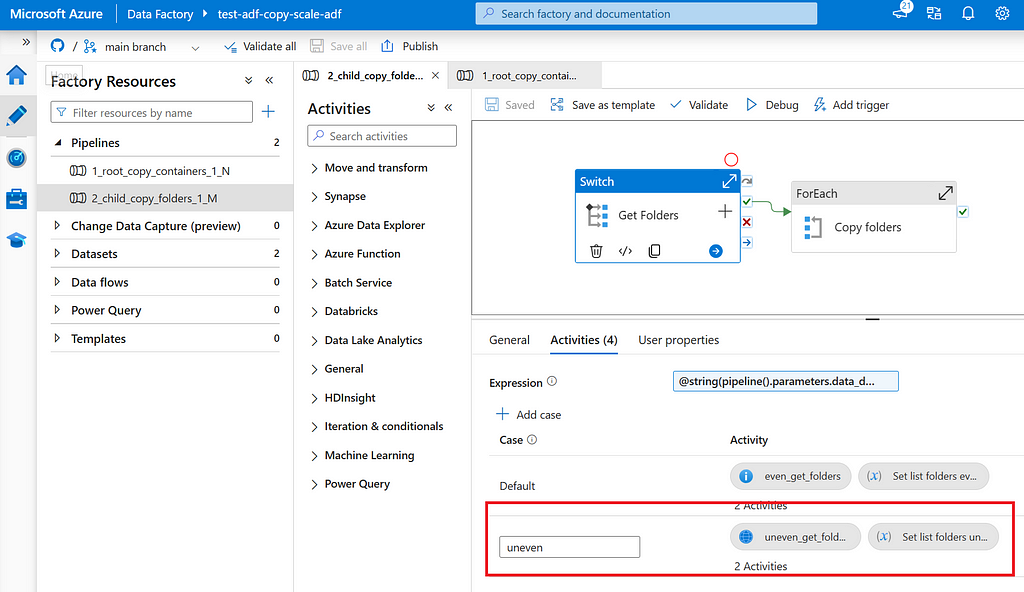
Root pipeline: Root pipeline that lists containers N on storage account and triggers child pipeline for each container.
Child pipeline: Child pipeline that lists folders M in a container and triggers recursive copy activity for each folder.
Switch: Child pipeline uses a switch to decide how list folders shall be determined. For case “default” (even), Get Metadata is used, for case “uneven” an Azure Function is used.
Get Metadata: List all root folders M in a given container N.
Azure Function: List all folders and sub folders that contain no more than X GB of data and shall be copied as a whole.
Copy activity: Recursively copy for all data from a given folder.
DIU: Number of Data Integration Units per copy activity.
Copy parallelization: Within a copy activity, number of parallel copy threads that can be started. Each thread can copy a file, maximum of 50 threads.
In the uniformly distributed data lake, data is evenly distributed over N containers and M folders. In this situation, copy activities can just be parallelized on each folder M. This can be done using a Get Meta Data to list folders M, For Each to iterate over folders and copy activity per folder. See also image below.
3.2.1 Child pipeline structure focusing on uniformly distributed data
Using this strategy, this would imply that each copy activity is going to copy an equal amount of data. A total of N*M copy activities will be run.
In the skewed distributed data lake, data is not evenly distributed over N containers and M folders. In this situation, copy activities shall be dynamically determined. This can be done using an Azure Function to list the data heavy folders, then a For Each to iterate over folders and copy activity per folder. See also image below.
3.2.2 Child pipeline structure focusing on skewed distributed data
Using this strategy, copy activities are dynamically scaled in data lake where data can be found and parallelization is thus needed most. Although this solution is more complex than the previous solution since it requires an Azure Function, it allows for copying skewed distributed data.
3.3: Parallelization performance test
To compare the performance of different parallelization options, a simple test is set up as follows:
Two storage accounts and 1 ADF instance using an Azure IR in region westeurope. Data is copied from source to target storage account.
Source storage account contains three containers with 0.72 TB of data each spread over multiple folders and sub folders.
Data is evenly distributed over containers, no skewed data.
Test A: Copy 1 container with 1 copy activity using 32 DIU and 16 threads in copy activity (both set to auto) => 0.72 TB of data is copied, 12m27s copy time, average throughput is 0.99 GB/s
Test B: Copy 1 container with 1 copy activity using 128 DIU and 32 threads in copy activity => 0.72 TB of data is copied, 06m19s copy time, average throughput is 1.95 GB/s.
Test C: Copy 1 container with 1 copy activity using 200 DIU and 50 threads (max) => test aborted due to throttling, no performance gain compared to test B.
Test D: Copy 2 containers with 2 copy activities in parallel using 128 DIU and 32 threads for each copy activity => 1.44 TB of data is copied, 07m00s copy time, average throughput is 3.53 GB/s.
Test E: Copy 3 containers with 3 copy activities in parallel using 128 DIU and 32 threads for each copy activity => 2.17 TB of data is copied, 08m07s copy time, average throughput is 4.56 GB/s. See also screenshot below.
3.3 Test E: Copy throughput of 3 parallel copy activities of 128 DIU and 32 threads, data size is 3*0.72TB
In this, it shall be noticed that ADF does not immediately start copying since there is a startup time. For an Azure IR this is ~10 seconds. This startup time is fixed and its impact on throughput can be neglected for large copies. Also, maximum ingress of a storage account is 60 Gbps (=7.5 GB/s). There cannot be scaled above this number, unless additional capacity is requested on the storage account.
The following takeaways can be drawn from the test:
Significant performance can already be gained by increasing DIU and parallel settings within copy activity.
By running copy pipelines in parallel, performance can be further increased.
In this test, data was uniformly distributed across two containers. If the data had been skewed, with all data from container 1 located in a sub folder of container 2, both copy activities would need to target container 2. This ensures similar performance to Test D.
If the data location is unknown beforehand or deeply nested, an Azure Function would be needed to identify the data pockets to make sure the copy activities run in the right place.
4. Conclusion
Azure Data Factory (ADF) is a popular tool to move data at scale. It is widely used for ingesting, transforming, backing up, and restoring data in Enterprise Data Lakes. Given its role in moving large volumes of data, optimizing copy performance is crucial to minimize throughput time.
In this blog post, we discussed the following parallelization strategies to enhance the performance of data copying to and from Azure Storage.
Within a copy activity, utilize standard Data Integration Units (DIU) and parallelization threads within a copy activity.
Run copy activities in parallel. If data is known to be evenly distributed, standard functionality in ADF can be used to parallelize copy activities across each container (N) and root folder (M).
Run copy activities where the data is. In case this is not known on beforehand or deeply nested, an Azure Function can be leveraged to locate the data. However, incorporating an Azure Function within an ADF pipeline adds complexity and should be avoided when not needed.
Unfortunately, there is no silver bullet solution and it always requires analyses and testing to find the best strategy to improve copy performance for Enterprise Data Lakes. This article aimed to give guidance in choosing the best strategy.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.