
Crypto analyst Raajeev Anand emphasized the rising optimism surrounding XRP, predicting a potential 1,500% price surge for the crypto asset.
Originally appeared here:
Pundit Outlines Factors That Could Push XRP Price to $10, But There’s a Catch

Crypto analyst Raajeev Anand emphasized the rising optimism surrounding XRP, predicting a potential 1,500% price surge for the crypto asset.
Originally appeared here:
Pundit Outlines Factors That Could Push XRP Price to $10, But There’s a Catch


The U.S. dollar’s dominance in global trade and finance is unparalleled. Around 88% of all foreign exchange transactions involve the U.S. dollar, solidifying its position as the backbone of international markets. For traders in Asia—especially in India and Southeast Asia—understanding the dollar’s movements is not just advisable; it’s essential. Changes in the dollar’s value influence […]
Originally appeared here:
Mastering Dollar Volatility: Key Strategies for Traders in Asia and India from Octa Broker


As Sui (SUI) continues to capture attention with its market performance, savvy adherents are shifting their focus towards GoodEgg (GEGG), a new AI-powered dating cryptocurrency poised for explosive growth. With over 93% of its presale Stage 2 tokens already sold and priced at $0.00021, GoodEgg (GEGG) is drawing attention for its innovative approach, and market […]
Originally appeared here:
Sui’s Bulls Push New A.I Social Dating Coin GoodEgg Currently Priced At $0.00021 Due to Skyrocket By 210%


Welcome to part ii of our coming-of-age trilogy on a public health and fitness data pipeline.
In this chapter, we reimagine the backend system as a distributed state machine and explore the art of achieving consistency — with a functional flavour.
In part I, we watched SmartGym grow into (version 2.1), an integrated health and fitness platform that streams, processes, and saves data from a range of gym equipment sensors and medical devices. These data provided insights that empowered users to take more active ownership of their personal health and fitness.
As our system evolved from merely saving and retrieving data to responding to a real-world events, our architecture had to reflect this paradigm shift — from a request-driven to an event-driven one.
There were two pipelines that kept the lights on:
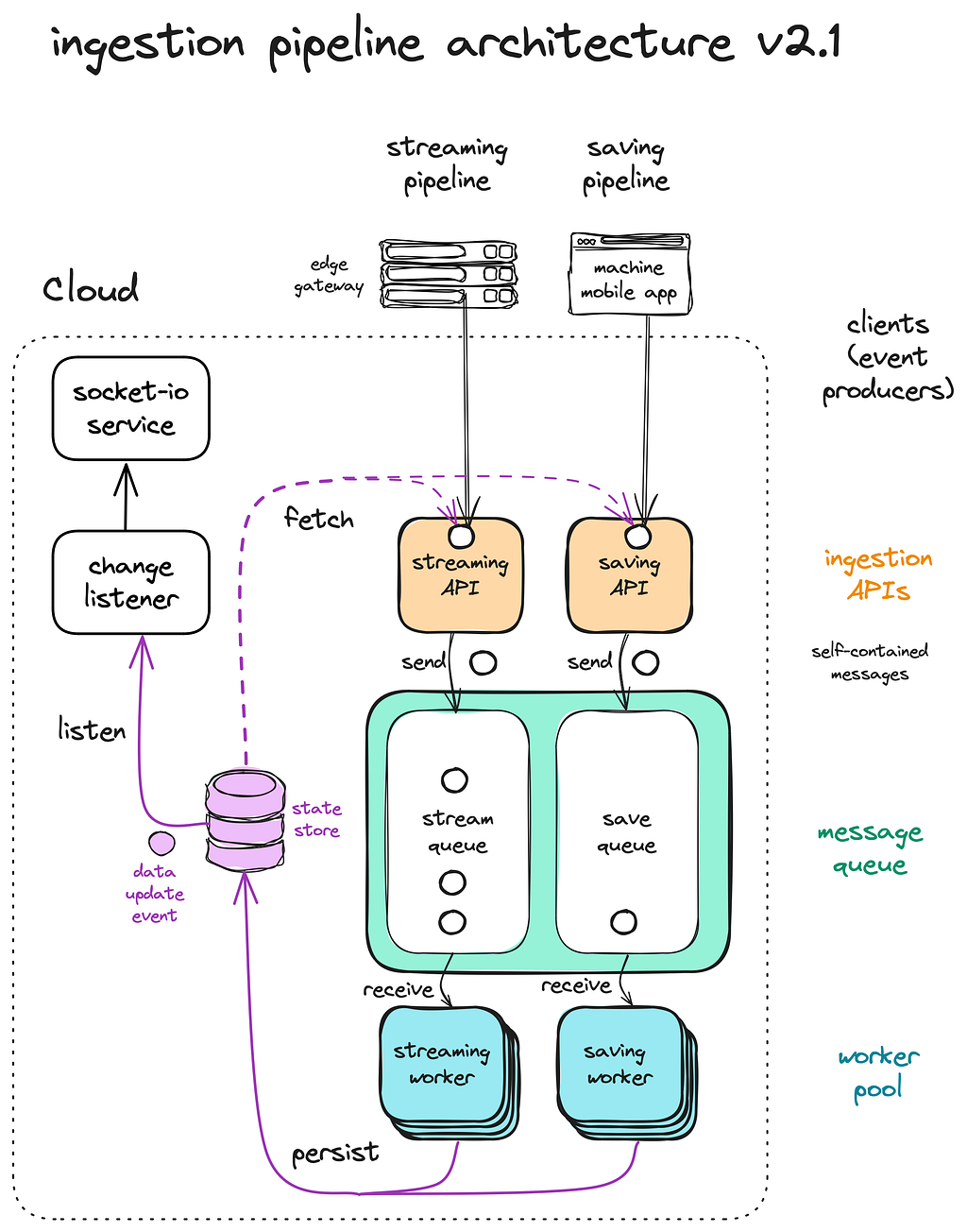
The event-driven architecture was a double-edged sword, introducing both order and chaos. Ultimately, we watched it evolve into a well-oiled machine capable of taming its complexities.
In this installment, we’ll explore the next three versions of the system, each enhancing a user’s workout experience in a different way:
But first, meet the main character of this article!

Be it distributed, event-driven, or not, we can think of the SmartGym/SENSEI backend system as a magic black box.

Input: We feed this black box new information — e.g. users info, sensor data
State Transition: This new information interacts with its existing state based on a certain logic, resulting in a new internal state.
Output: At any time, we can query its internal state to retrieve relevant information — e.g. user workout information
The Magic Black Box is deterministic: if you take two identical black boxes with the same state and logic, feed them with the same inputs in the same order, both will end up with identical internal states.
If we tear it apart, we’ll find there’s nothing truly magical — just a dataflow architecture comprising a bunch of data views and ingestion pipelines.

There are two main types of data views:
1. Source of truth (solid line) — e.g. users, sensor stream
2. Derived data (dotted line) — e.g. workouts
The process of deriving data views from sources of truth is known as materialisation, a deterministic task handled by workers in the ingestion pipeline.
All internal state of the magic box are encapsulated within these data views, while the ingestion pipeline — the machinery behind the materialisation process — remains stateless.
Note that whenever the source of truth changes, the derived data has to be re-derived. Else, the state transition is incomplete and the magic black box is left in an inconsistent state.
In the previous example, we feed the magic black box:
These inputs serve as sources of truth, reflecting real-world entities or events.
From these two pieces of information, we derive a single workout session record in the saving pipeline.
Now, you might be offended by Mr. Magic Black Box mansplaining what appears to be common sense to you. But bear with him because he would prove to be a useful abstraction throughout this article.
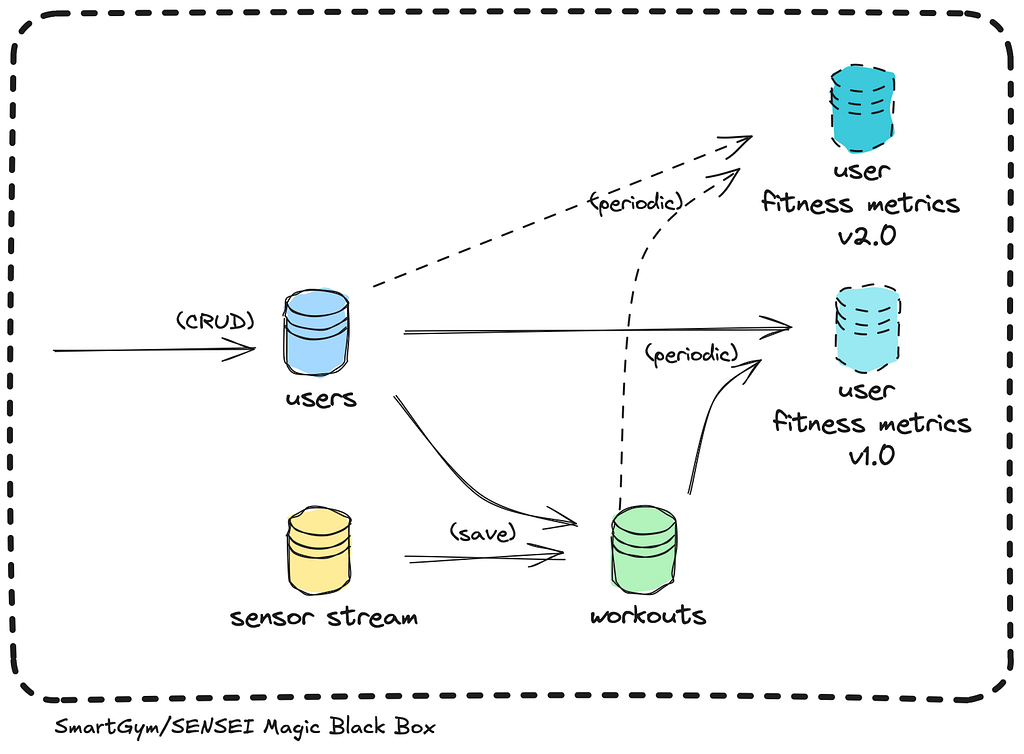
With the streaming and saving pipelines working tirelessly to ingest data into the system, our database now houses a wealth of user and workout records. We are empowered to provide meaningful macro insights by analysing trends, groups, averages, and totals for our users and stakeholders.
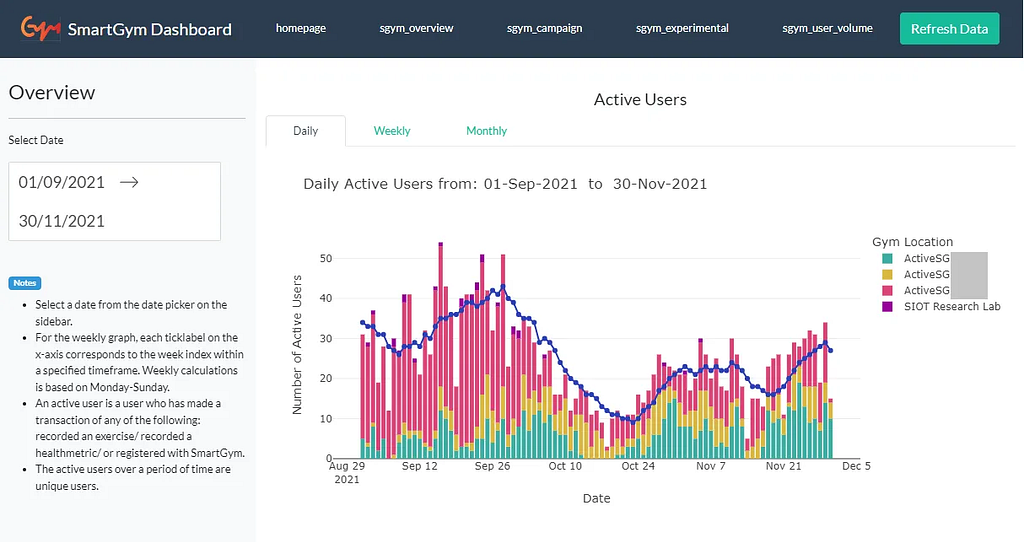
This is where SmartGym’s vision of becoming “every citizen’s #1 fitness companion” begins to take shape. Beyond giving real-time feedback during my workout, recalling my historical performance, and telling me what a great job I’ve done — a diligent fitness companion provides tangible metrics to measure my improvement in performance over time.
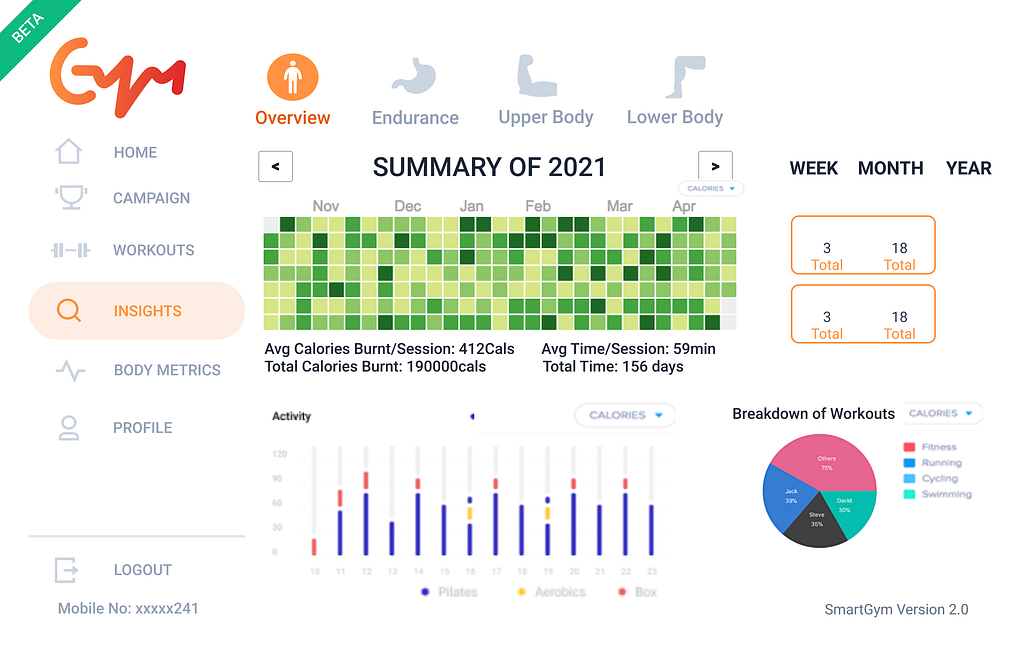
By leveraging recent workouts and user information — such as body metrics captured by the SmartGym weighing scale — we can estimate various performance metrics, including:
Deriving both product and fitness metrics typically involves denormalization and aggregation across records, which can be resource-intensive in terms of memory usage, database reads, and network throughput.
Since it doesn’t make sense to run these operations every time a user loads the dashboard, we need a precomputed intermediate data representation, ready for query and visualisation — another derived data view for user fitness metrics!
Let’s return to our magic black box.

As new users and workout records continuously flow in, user fitness metrics — a derived data view — require continuous updates in response to changes in the upstream data views they rely on.
To address this, we decided to recompute user fitness metrics periodically, accepting that these metrics may be a few hours stale.
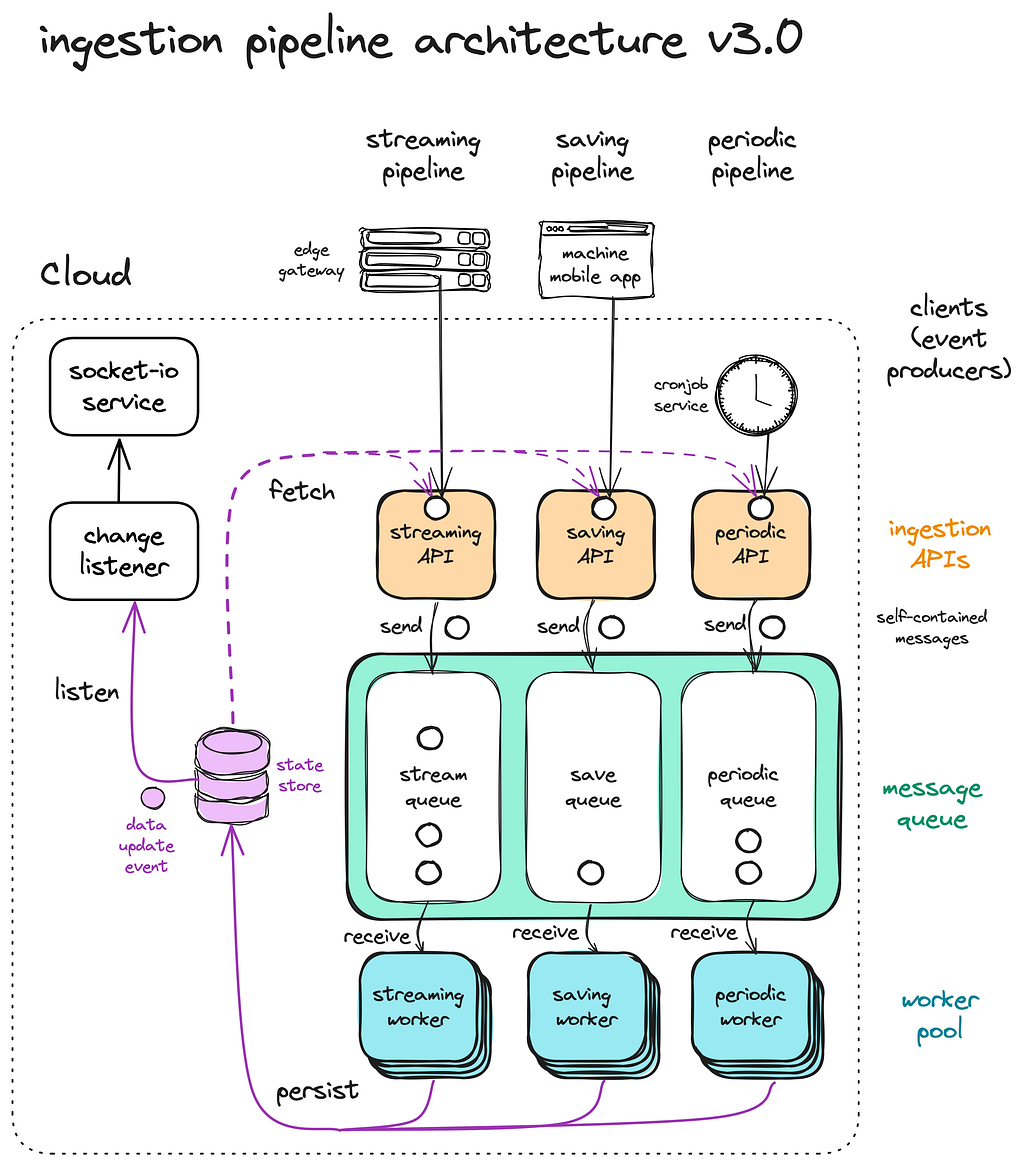
Our ingestion pipeline now includes a cronjob service that schedules batch processing jobs within the periodic pipeline based on a preconfigured schedule, ensuring timely updates without overloading the system.
Staying fit is difficult work. But with a healthy dose of competition and collective suffering, it can be an experience that feels larger than life. Imagine if every rep, every set, and every workout session contributed to something greater.
Introducing exercise leaderboard and fitness challenges.
The leaderboard showcases users who have logged the most effort over the month — measured by distance run, weights lifted, and more.
Boy, did this feature stroke some egos! Some of the gym regulars started renaming their randomly-generated username with titles like “Beefy” or “Armstrong”. For many others, surveying the leaderboard became the first order of business upon entering the gym, and the same post-workout ritual before strutting out with newfound swagger.

Similar to how we compute product and user fitness metrics, the leaderboard data is updated periodically in batches, derived from user profiles and their historical workout data.

In collaboration with the gym management team, we launched a fitness challenge to coincide with periods such as Singapore’s National Day.

Each day, users received a challenge requiring them to complete a specific number of reps on a weighted machine or spend a certain number of minutes on a cardio machine, earning rewards for their hard work.
This kickstarted a series of diverse fitness challenges, each featuring unique gameplay variations in terms of duration, workout types, intensity, streaks, and more.
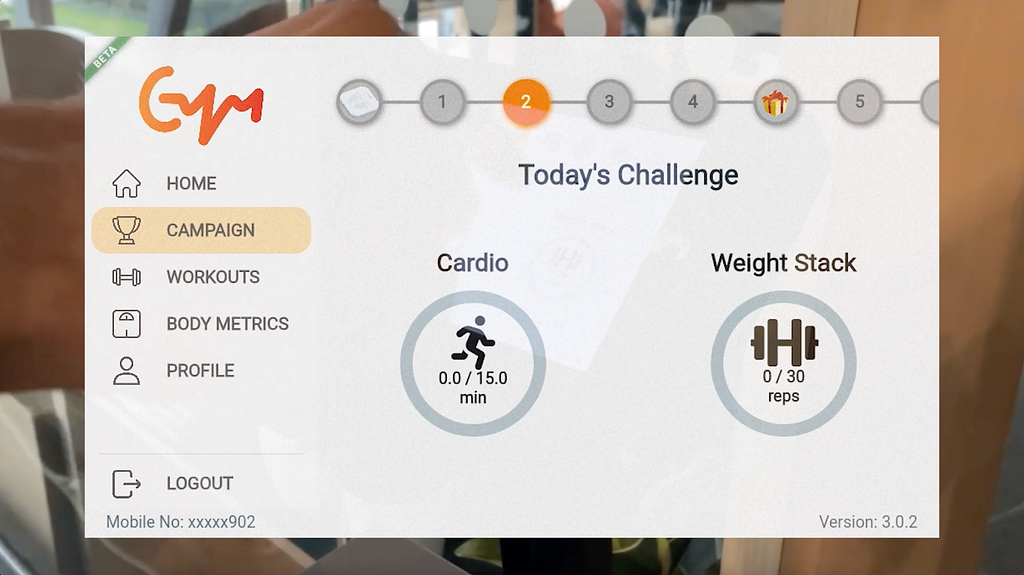
At its core, a fitness challenge is a unique set of workout requirements, specified by an administrator. By comparing a user’s workout history to these requirements, we can assess their progress and completion status for the challenge.
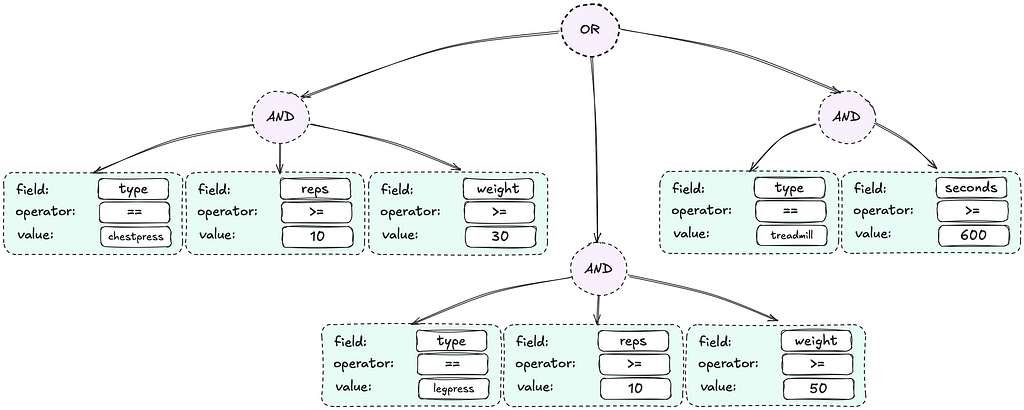
Instead of cluttering our codebase with a new bunch of if-else statements for each variation of the fitness challenge, we externalised the business logic by representing these logical rules in a syntax tree. During runtime, the rule engine parses this tree and evaluates it against users’ actual workout histories to track their challenge progress.

When the program admin modifies the parameters of a fitness challenge, they are directly updating the underlying rules syntax tree. This same data structure is shared between the backend rules engine and the frontend rules configuration page, ensuring consistency and ease of management.
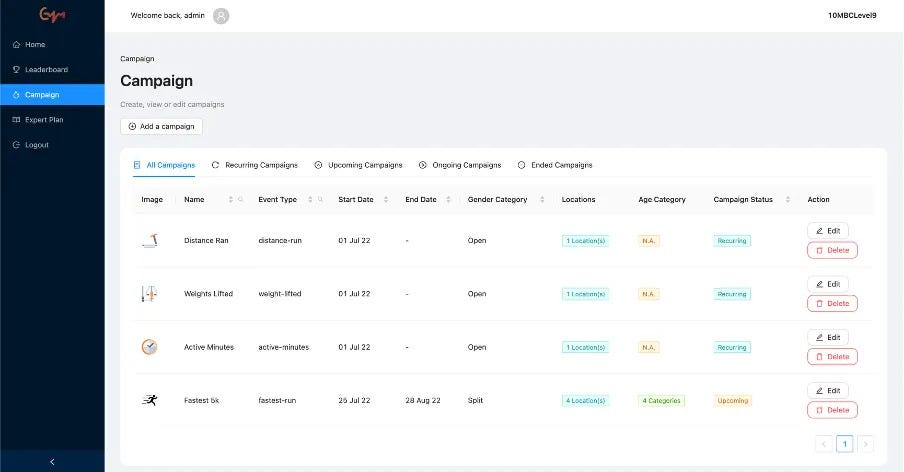
Lets revisit our magic black box.

User fitness challenge results, derived from the workouts and user fitness challenge data through the rules engine, need to be recalculated whenever changes occur in the upstream data views they depend on — such as each time a user completes a workout set.
Among our enthusiastic users, these fitness challenges are a matter of honour and glory. If they don’t see updated challenge results immediately after finishing a set, they get confused and frustrated. Therefore, we can’t afford to reprocess user fitness challenge results in periodic batches; every change in the workouts data view must be propagated instantly.
To achieve that, we extend our ingestion pipeline with a Change Data Capture mechanism, introducing a service that continuously listens for changes in relevant data views, using built-in database triggers or change streams. This on-demand pipeline triggers a cascade of updates to the downstream derived data views.
In this case, an on-demand worker implements the logic of the rules engine to evaluate user fitness challenges results on the fly.
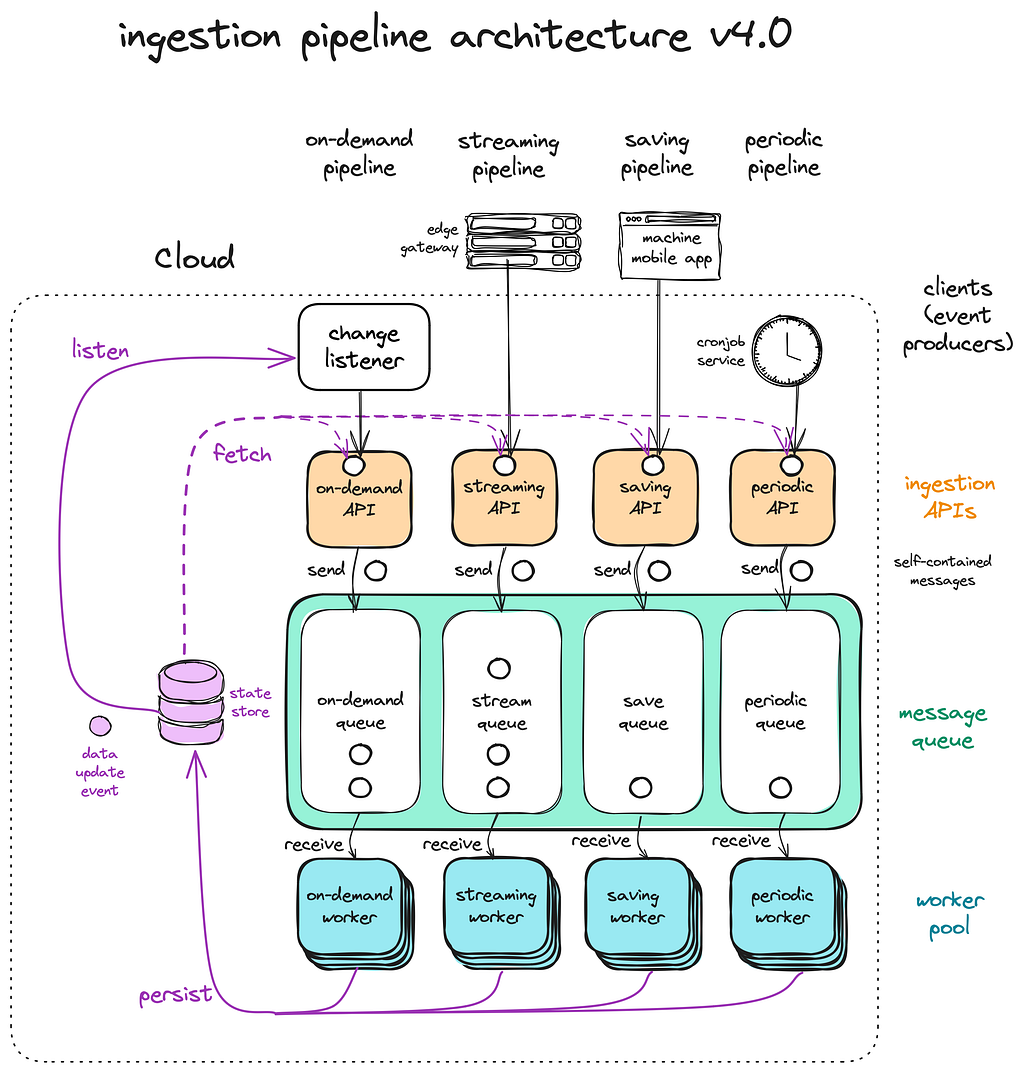
A recap of the different stages of our ingestion pipeline:
What if we could give the fitness challenges a personal touch?
In late 2021, a team from the Singapore Army described their predicament: each year, servicemen must meet specific fitness benchmarks. If they fall short, they are enrolled in a structured training program, known as NSFIT. However, these sessions were limited to specific times, required sign-ups, and needed staff to facilitate and monitor progress. With the ongoing pandemic and social distancing measures then, gathering servicemen for group sessions wasn’t feasible.
Using the SmartGym fitness challenge system, servicemen could carry out their training on their own schedule — no need for staff to hover over every session. All that’s required is for the staff to verify that the training was completed and the standards were met.

But here’s the twist: servicemen come in all shapes, sizes, and fitness levels. A one-size-fits-all fitness challenge just wouldn’t cut it. They need something that meets them where they are, in order to push their fitness to new heights.
So, why not add a recommendation step before curating a user fitness challenge? By leveraging the fitness metrics we already compute (like in v3.0), we could tailor the intensity of their subsequent training sessions.
Our personalized fitness challenge now follows three key steps:
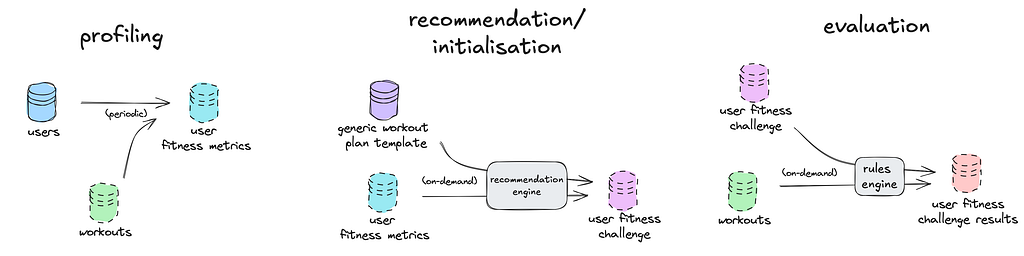
Step 1 — Profiling
Using historical workout data, we profile each user’s fitness level.
To further optimise this process, we could expand our profiling methods beyond simple heuristics, incorporating machine learning methods to extract more sophisticated features — resulting in new derived data views.
Step 2 — Recommendation
Starting with a generic challenge template (including general information like location, total workouts, participant groups, start/end dates, etc), the recommendation engine fleshes out this skeletal template into a rules syntax tree tailored to each user’s fitness profile.
For even greater personalization, a domain expert could manually fine-tune the challenge requirements, offering a professional perspective beyond algorithmic deduction.
Step 3 — Evaluation
Once personalized parameters are embedded into the rules syntax tree, evaluations can be triggered on-demand after the workout is saved, or even performed in real-time against the sensor stream and displayed on the frontend console.


Earlier in the article, we mentioned that the magic black box is composed of data views, where the state lives, and a stateless ingestion pipeline.
To get reliable outputs from the magic black box, these data views must be consistent, achieved through a deterministic series of materialisation in the ingestion pipeline.
Buckle up and brace yourself, because we will be diving deep into consistency and determinism — the undercurrents of dataflow.
At first glance, it might seem simpler to create one massive data view containing every bit of detail from the raw data. With only one data source, consistency is implied. However, there are several reasons why we need derived data views despite the complexity of maintaining consistency:
Data can be represented in a myriad of forms — in different combinations and at multiple levels of granularity — each serving their own unique purpose.
For example, it turns out that a user is not interested in knowing if the 3rd rep of his 2nd set of chest press on September 2020 was fully extended or not — after that real-time window of immediacy, low-level raw details become increasingly irrelevant, while higher-level derived insights become much more valuable.
To avoid having to assume how data will be used and represented in future — raw is better, a.k.a the Sushi Principle.
With that, we decouple the write model from the range of potential read models, and bridge the gap with a series of materialisation stages. This separation is commonly known as Command and Query Responsibility Segregation (CQRS).
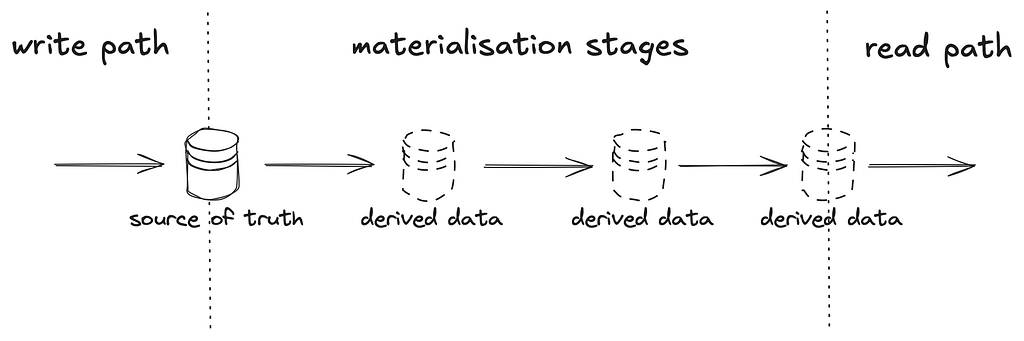
Having a materialisation path gives a piece of data the space and time — to morph and discover its different personalities, enabling:
By designating the write model as the authoritative source of truth to reason from, it is easier to achieve consistency — without the complexities of having multiple authoritative systems trying to reach a consensus.
There are instances when the raw data grows too rapidly. E.g. with 1 message/sec per treadmill sensor, with multiple gyms, you end up with millions of messages in the sensor stream in just one day.

When the sensor stream grows prohibitively large, we can treat workouts records as a “lossy compression” of the sensor stream, purge the processed sensor stream, and promote the derived workouts records as a new authoritative source of truth.
Since the one-way chain of materialisation still starts from a single source of truth, we retain our basis of consistency.
Derived views offers resilience. If a bug corrupts the output, we can roll back to previous versions and rerun the materialisation process, ensuring accurate data again.
Derived views also enable gradual evolution of application. You can introduce new data views without deleting or restructuring the old ones, keeping both as independent views of the same data, with the option of falling back if something goes wrong.
In part one of the series, we’ve seen how the publisher-subscriber (pub/sub) pattern (via a fanout exchange) of the ingestion pipeline makes it easy to extend system functionality in a plug-and-play manner, without disrupting existing pipelines or requiring upstream modifications.
A key to agile development and building anti-fragile systems — those that improve with each bug fix or new feature — is the ease of recovery and evolution. The decoupling enabled by the pub/sub pattern and derived views makes this possible.
Next, let’s dissect the nature of consistency and control flow of the dataflow architecture.
Broadly speaking, distributed systems can be categorised by two consistency levels — strong or eventual; and two types of control flow — orchestration (centralised) or choreography (decentralised).
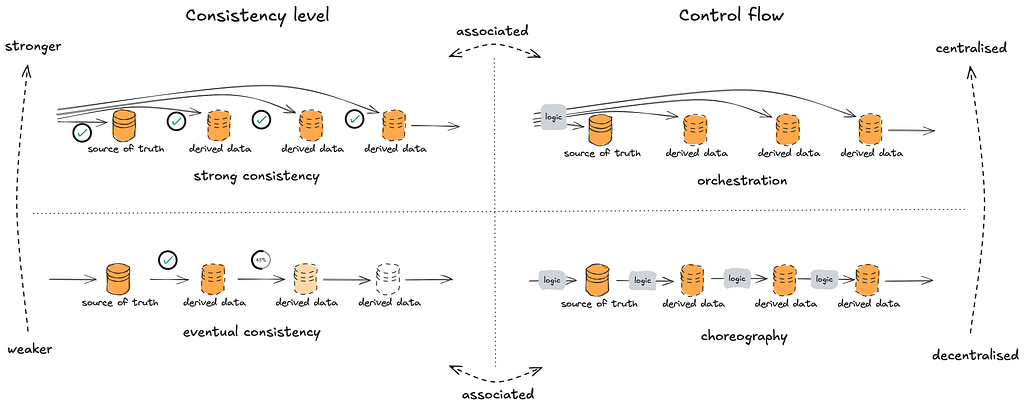
Strong consistency guarantees that every read reflects the most recent write. It ensures that all data views are updated immediately and accurately after a change. Strong consistency is typically associated with orchestration, since it often relies on a central coordinator to manage atomic updates across multiple data views — either updating all at once, or none at all. Such “over-engineering” may be required for systems where minor discrepancies can be disastrous, e.g. financial transactions, but not in our case.
Eventual consistency allows for temporary discrepancies between data views, but given enough time, all views will converge to the same state. This approach typically pairs with choreography, where each worker reacts to events independently and asynchronously, without needing a central coordinator.
The asynchronous and loosely-coupled design of the dataflow architecture is characterised by eventual consistency of data views, achieved through a choreography of materialisation logic.
And there are perks to that.
Resilience to partial failures: The asynchrony of choreography is more robust against component failures or performance bottlenecks, as disruptions are contained locally. In contrast, orchestration can propagate failures across the system, amplifying the issue through tight coupling.
Simplified write path: Choreography also reduces the responsibility of the write path, which reduces the code surface area for bugs to corrupt the source of truth. Conversely, orchestration makes the write path more complex, and increasingly harder to maintain as the number of different data representations grows.
The decentralised control logic of choreography allows different materialisation stages to be developed, specialised, and maintained independently and concurrently.
A reliable dataflow system is akin to a spreadsheet: when one cell changes, all related cells update instantly — no manual effort required.
In an ideal dataflow system, we want the same effect: when an upstream data view changes, all dependent views update seamlessly. Like in a spreadsheet, we shouldn’t have to worry about how it works; it just should.
But ensuring this level of reliability in distributed systems is far from simple. Network partitions, service outages, and machine failures are the norm rather than the exception, and the concurrency in the ingestion pipeline only adds complexity.
Since message queues in the ingestion pipeline provide reliability guarantees, deterministic retries can make transient faults seem like they never happened. To achieve that, our ingestion workers need to adopt the event-driven work ethic:
In computer science, pure functions exhibit determinism, meaning their behaviour is entirely predictable and repeatable.
They are ephemeral — here for a moment and gone the next, retaining no state beyond their lifespan. Naked they come, and naked they shall go. And from the immutable message inscribed into their birth, their legacy is determined. They always return the same output for the same input — everything unfolds exactly as predestined.
And that is exactly what we want our ingestion workers to be.
Immutable inputs (statelessness)
This immutable message encapsulates all necessary information, removing any dependency on external, changeable data. Essentially we are passing data to the workers by value rather than by reference, such that processing a message tomorrow would yield the same result as it would today.
Task isolation
To avoid concurrency issues, workers should not share mutable state.
Transitional states within the workers should be isolated, like local variables in pure functions — without reliance on shared caches for intermediate computation.
It’s also crucial to scope tasks independently, ensuring that each worker handles tasks without sharing input or output spaces, allowing parallel execution without race conditions. E.g. scoping the user fitness profiling task by a particular user_id, since inputs (workouts) are outputs (user fitness metrics) are tied to a unique user.
Deterministic execution
Non-determinism can sneak in easily: using system clocks, depending on external data sources, probabilistic/statistical algorithms relying on random numbers, can all lead to unpredictable results. To prevent this, we embed all “moving parts” (e.g. random seeds or timestamp) directly in the immutable message.
Deterministic ordering
Load balancing with message queues (multiple workers per queue) can result in out-of-order message processing when a message is retried after the next one is already processed. E.g. Out-of-order evaluation of user fitness challenge results appearing as 50% completion to 70% and back to 60%, when it should increase monotonically. For operations that require sequential execution, like inserting a record followed by notifying a third-party service, out-of-order processing could break such causal dependencies.
At the application level, these sequential operations should either run synchronously on a single worker or be split into separate sequential stages of materialisation.
At the ingestion pipeline level, we could assign only one worker per queue to ensure serialised processing that “blocks” until retry is successful. To maintain load balancing, you can use multiple queues with a consistent hash exchange that routes messages based on the hash of the routing key. This achieves a similar effect to Kafka’s hashed partition key approach.
Idempotent outputs
Idempotence is a property where multiple executions of a piece of code should always yield the same result, no matter how many times it got executed.
For example, a trivial database “insert” operation is not idempotent while an “insert if does not exist” operation is.
This ensures that you get the same outcome as if the worker only executed once, regardless of how many retries it actually took.
Caveat: Note that unlike pure functions, the worker does not “return” an object in the programming sense. Instead, they overwrite a portion of the database. While this may look like a side-effect, you can think of this overwrite as similar to the immutable output of a pure function: once the worker commits the result, it reflects a final, unchangeable state.
Traditionally, we think of web/mobile apps as stateless clients talking to a central database. However, modern “single-page” frameworks have changed the game, offering “stateful” client-side interaction and persistent local storage.
This extends our dataflow architecture beyond the confines of a backend system into a multitude of client devices. Think of the on-device state (the “model” in model-view-controller) as derived view of server state — the screen displays a materialised view of local on-device state, which mirrors the central backend’s state.
Push-based protocols like server-sent events and WebSockets take this analogy further, enabling servers to actively push updates to the client without relying on polling — delivering eventual consistency from end to end.

In fact, this real-time synchronization is exactly how we evaluated personalized fitness challenges in the frontend console — as a derived data view residing in a client device.
Even down the stack, we see a semblance of dataflow in databases. Database triggers, stored procedures, and materialized view maintenance routines are not very different from the on-demand and periodic processing pipelines; B-tree indexes and materialised views of a relational database are essentially derived data views— talk about dataflows within dataflows!
“The goal of data integration is to make sure that data ends up in the right form, in all the right places.”
— Designing Data-Intensive Applications (Martin Kleppmann)
As data systems scale, we should progress beyond seeing them as passive databases manipulated by applications like global variables.
Instead, it is useful to reimagine data systems in an organisation as an interplay of data views, one derived from another, with state changes rippling out from a central source of truth, propagated through functional application code. Dataflows, built upon dataflows.
It’s magic black boxes — all the way down.
Congratulations on making it this far!
In part I, we evolved from a trivial request-response system into an event-driven system that streams, processes, and saves data from a range of gym equipment sensors and medical devices.
In this second instalment, we expanded upon those saved records and processed them periodically and on-demand. This enabled new features that enhance a user’s workout experience into a more collective yet personalised one. As our ingestion pipeline evolved, so did our dataflow architecture, scaling to meet new demands.

The story of our evolution doesn’t end here.
In the next and final part, we explore adding and removing functionality in a plug-and-play manner, paving the way for an ecosystem to emerge from our platform.
Stay tuned…
All images and gifs featured in this article are original works created and captured by the author.
Shoutout to the data engineering bible, a.k.a Designing Data-Intensive Applications — by Martin Kleppmann, for giving me the vocabulary to think about these distributed systems with clarity.
User insights dashboard
Fitness Lover to Developer: Building a SmartGym Vision
Product metrics dashboard
Leaderboard and fitness challenge analytics dashboard
Personalised workout for physiotherapy
Designing an end to end experience for Physiotherapist and Patients
Dataflow Architecture-Derived Data Views and Eventual Consistency was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Dataflow Architecture-Derived Data Views and Eventual Consistency
Go Here to Read this Fast! Dataflow Architecture-Derived Data Views and Eventual Consistency
Synthetic data serves many purposes, and has been gathering attention for a while, partly due to the convincing capabilities of LLMs. But what is «good» synthetic data, and how can we know we managed to generate it ?

Synthetic data is data that has been generated with the intent to look like real data, at least on some aspects (schema at the very least, statistical distributions, …). It is usually generated randomly, using a wide range of models : random sampling, noise addition, GAN, diffusion models, variational autoencoders, LLM, …
It is used for many purposes, for instance :
It is particularily used in software testing, and in sensitive domains like healthcare technology : having access to data that behaves like real data without jeopardizing patients privacy is a dream come true.
For a sample to be useful it must, in some way, look like real data. The ultimate goal is that generated samples must be indistinguishable from real samples : generate hyper-realistic faces, sentences, medical records, … Obviously, the more complex the source data, the harder it is to generate «good» synthetic data.
In many cases, especially data augmentation, we need more than one realistic sample, we need a whole dataset. And it is not the same to generate a single sample and a whole dataset : the problem is very well known, under the name of mode collapse, which is especially frequent when training a generative adversarial network (GAN). Essentially, the generator (more generally, the model that generates synthetic data) could learn to generate a single type of sample and totally miss out on the rest of the sample space, leading to a synthetic dataset that is not as useful as the original dataset.
For instance, if we train a model to generate animal pictures, and it finds a very efficient way to generate cat pictures, it could stop generating anything else than cat pictures (in particular, no dog pictures). Cat pictures would then be the “mode” of the generated distribution.
This type of behaviour is harmful if our initial goal is to augment our data, or create a dataset for training. What we need is a dataset that is realistic in itself, which in absolute means that any statistic derived from this dataset should be close enough to the same statistic on real data. Statistically speaking, this means that univariate and multivariate distributions should be the same (or at least “close enough”).
We will not dive too deep on this topic, which would deserve an article in itself. To keep it short : according to our initial goal, we may have to share data (more or less publicly), which means, if it is personal data, that it should be protected. For instance, we need to make sure we cannot retrieve any information on any given individual of the original dataset using the synthetic dataset. In particular, that means being cautious about outliers, or checking that no original sample was generated by the generator.
One way to consider the privacy issue is to use the differential privacy framework.

Let’s start by loading data and generating a synthetic dataset from this data. We’ll start with the famous `iris` dataset. To generate it synthetic counterpart, we’ll use the Synthetic Data Vault package.
pip install sdv
from sklearn.datasets import load_iris
from sdv.single_table import GaussianCopulaSynthesizer
from sdv.metadata.metadata import Metadata
data = load_iris(return_X_y=False, as_frame=True)
real_data = data["data"]
# metadata of the `iris` dataset
metadata = Metadata().load_from_dict({
"tables": {
"iris": {
"columns": {
"sepal length (cm)": {
"sdtype": "numerical",
"computer_representation": "Float"
},
"sepal width (cm)": {
"sdtype": "numerical",
"computer_representation": "Float"
},
"petal length (cm)": {
"sdtype": "numerical",
"computer_representation": "Float"
},
"petal width (cm)": {
"sdtype": "numerical",
"computer_representation": "Float"
}
},
"primary_key": None
}
},
"relationships": [],
"METADATA_SPEC_VERSION": "V1"
})
# train the synthesizer
synthesizer = GaussianCopulaSynthesizer(metadata)
synthesizer.fit(data=real_data)
# generate samples - in this case,
# synthetic_data has the same shape as real_data
synthetic_data = synthesizer.sample(num_rows=150)
Now, we want to test whether it is possible to tell if a single sample is synthetic or not.
With this formulation, we easily see it is fundamentally a binary classification problem (synthetic vs original). Hence, we can train any model to classify original data from synthetic data : if this model achieves a good accuracy (which here means significantly above 0.5), the synthetic samples are not realistic enough. We aim for 0.5 accuracy (if the test set contains half original samples and half synthetic samples), which would mean that the classifier is making random guesses.
As in any classification problem, we should not limit ourself to weak models and give a fair amount of effort in hyperparameters selection and model training.
Now for the code :
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
def classification_evaluation(
real_data: pd.DataFrame,
synthetic_data: pd.DataFrame
) -> float:
X = pd.concat((real_data, synthetic_data))
y = np.concatenate(
(
np.zeros(real_data.shape[0]),
np.ones(synthetic_data.shape[0])
)
)
Xtrain, Xtest, ytrain, ytest = train_test_split(
X,
y,
test_size=0.2,
stratify=y
)
clf = RandomForestClassifier()
clf.fit(Xtrain, ytrain)
score = accuracy_score(clf.predict(Xtest), ytest)
return score
classification_evaluation(real_data, synthetic_data)
>>> 0.9
In this case, it appears the synthesizer was not able to fool our classifier : the synthetic data is not realistic enough.
If our samples were realistic enough to fool a reasonably powerful classifier, we would need to evaluate our dataset as a whole. This time, it cannot be translated into a classification problem, and we need to use several indicators.
Statistical distributions
The most obvious tests are statistical tests : are the univariate distributions in the original dataset the same as in the synthetic dataset ? Are the correlations the same ?
Ideally, we would like to test N-variate distributions for any N, which can be particularily expensive for a high number of variables. However, even univariate distributions make it possible to see if our dataset is subject to mode collapse.
Now for the code :
import pandas as pd
from scipy.stats import ks_2samp
def univariate_distributions_tests(
real_data: pd.DataFrame,
synthetic_data: pd.DataFrame
) -> None:
for col in real_data.columns:
if real_data[col].dtype.kind in "biufc":
stat, p_value = ks_2samp(real_data[col], synthetic_data[col])
print(f"Column: {col}")
print(f"P-value: {p_value:.4f}")
print("Significantly different" if p_value < 0.05 else "Not significantly different")
print("---")
univariate_distributions_tests(real_data, synthetic_data)
>>> Column: sepal length (cm)
P-value: 0.9511
Not significantly different
---
Column: sepal width (cm)
P-value: 0.0000
Significantly different
---
Column: petal length (cm)
P-value: 0.0000
Significantly different
---
Column: petal width (cm)
P-value: 0.1804
Not significantly different
---
In our case, out of the 4 variables, only 2 have similar distributions in the real dataset and in the synthetic dataset. This shows that our synthesizer fails to reproduce basic properties of this dataset.
Visual inspection
Though no mathematically proof, a visual comparison of the datasets can be useful.
The first method is to plot bivariate distributions (or correlation plots).
We can also represent all the dataset dimensions at once: for instance, given a tabular dataset and its synthetic equivalent, we can plot both datasets using a dimension reduction technique, such as t-SNE, PCA or UMAP. With a perfect synthetizer, the scatter plots should look the same.
Now for the code :
pip install umap-learn
import pandas as pd
import seaborn as sns
import umap
import matplotlib.pyplot as plt
def plot(
real_data: pd.DataFrame,
synthetic_data: pd.DataFrame,
kind: str = "pairplot"
):
assert kind in ["umap", "pairplot"]
real_data["label"] = "real"
synthetic_data["label"] = "synthetic"
X = pd.concat((real_data, synthetic_data))
if kind == "pairplot":
sns.pairplot(X, hue="label")
elif kind == "umap":
reducer = umap.UMAP()
embedding = reducer.fit_transform(X.drop("label", axis=1))
plt.scatter(
embedding[:, 0],
embedding[:, 1],
c=[sns.color_palette()[x] for x in X["label"].map({"real":0, "synthetic":1})],
s=30,
edgecolors="white"
)
plt.gca().set_aspect('equal', 'datalim')
sns.despine(top=True, right=True, left=False, bottom=False)
plot(real_data, synthetic_data, kind="pairplot")

We already see on these plots that the bivariate distributions are not identical between real data and synthetic data, which is one more hint that the synthetization process failed to reproduce high-order relationship between data dimensions.
Now let’s take a look at a representation of the four dimensions at once :
plot(real_data, synthetic_data, kind="umap")
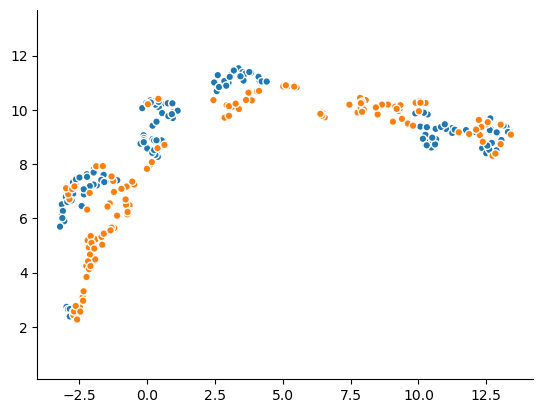
In this image is also clear that the two datasets are distinct from one another.
Information
A synthetic dataset should be as useful as the original dataset. Especially, it should be equivalently useful for prediction tasks, meaning it should capture complex relationships between features. Hence a comparison : TSTR vs TRTR, which mean “Train on Synthetic Test on Real” vs “Train on Real Test on Real”. What does it mean in practice ?
For a given dataset, we take a given task, like predicting the next token or the next event, or predicting a column given the others. For this given task, we train a first model on the synthetic dataset, and a second model on the original dataset. We then evaluate these two models on a common test set, which is an extract of the original dataset. Our synthetic dataset is considered useful if the performance of the first model is close to the performance of the second model, whatever the performance. It would mean that it is possible to learn the same patterns in the synthetic dataset as in the original dataset, which is ultimately what we want (especially in the case of data augmentation).
Now for the code :
import pandas as pd
from typing import Tuple
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
def tstr(
real_data: pd.DataFrame,
synthetic_data: pd.DataFrame,
target: str = None
) -> Tuple[float]:
# if no target is specified, use the last column of the dataset
if target is None:
target = real_data.columns[-1]
X_real_train, X_real_test, y_real_train, y_real_test = train_test_split(
real_data.drop(target, axis=1),
real_data[target],
test_size=0.2
)
X_synthetic, y_synthetic = synthetic_data.drop(target, axis=1), synthetic_data[target]
# create regressors (could have been classifiers)
reg_real = RandomForestRegressor()
reg_synthetic = RandomForestRegressor()
# train the models
reg_real.fit(X_real_train, y_real_train)
reg_synthetic.fit(X_synthetic, y_synthetic)
# evaluate
trtr_score = reg_real.score(X_real_test, y_real_test)
tstr_score = reg_synthetic.score(X_real_test, y_real_test)
return trtr_score, tstr_score
tstr(real_data, synthetic_data)
>>> (0.918261846477529, 0.5644428690930647)
It appears clearly that a certain relationship was learnt by the “real” regressor, whereas the “synthetic” regressor failed to learn this relationship. This hints that the relationship was not faithfully reproduced in the synthetic dataset.
Synthetic data quality evaluation does not rely on a single indicator, and one should combine metrics to get the whole idea. This article displays some indicators that can easily be built . I hope that this article gave you some useful hints on how to do it best in your use case !
Feel free to share and comment ✨
Evaluating synthetic data was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Evaluating synthetic data


Originally appeared here:
Introducing SageMaker Core: A new object-oriented Python SDK for Amazon SageMaker
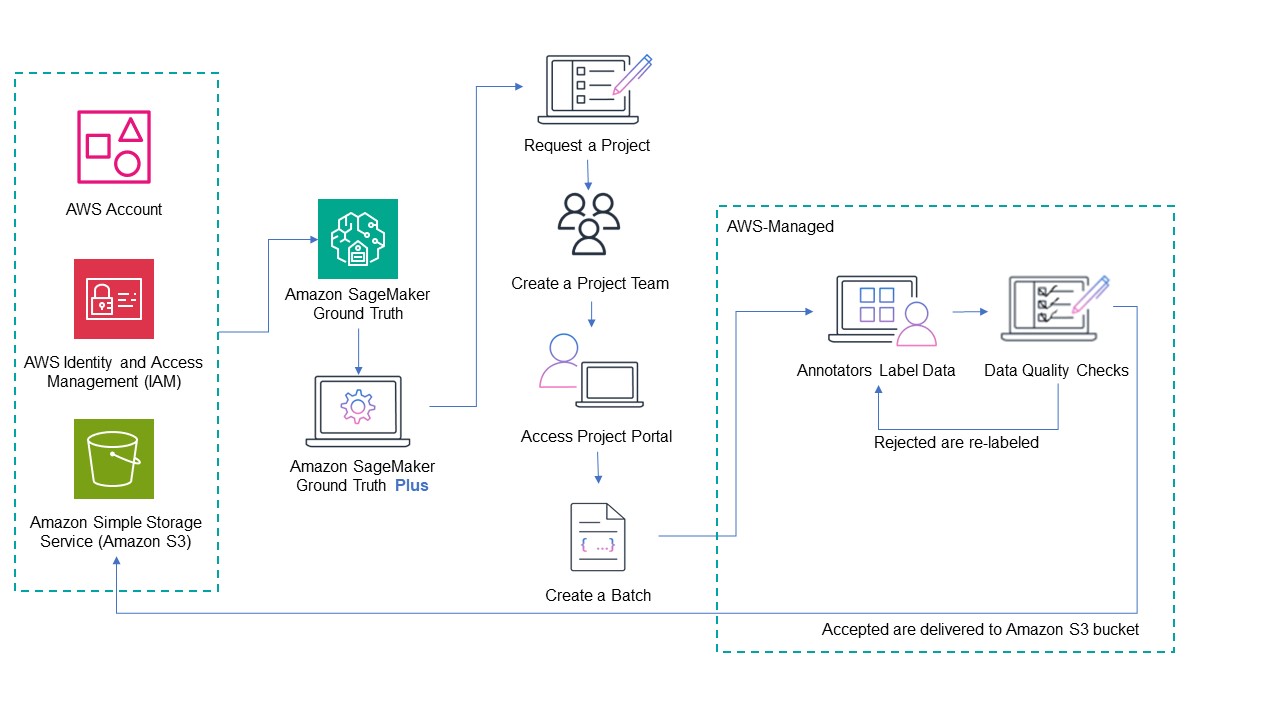

Originally appeared here:
Create a data labeling project with Amazon SageMaker Ground Truth Plus
Go Here to Read this Fast! Create a data labeling project with Amazon SageMaker Ground Truth Plus


The celebrity Kim Kardashian has worked with Beats on new variants of its products previously. In the latest and third collaboration, the focus is on the Beats Pill.
The special edition releases under the Beats x Kim collection offers the revamped portable speaker in two new hues. This time, they are Light Gray and Dark Gray, selected for function and style.
Go Here to Read this Fast! Beats partners with Kim Kardashian on new Beats Pill colors
Originally appeared here:
Beats partners with Kim Kardashian on new Beats Pill colors


Morgan Stanley has previously told investors that the sales of the iPhone 16 have been lower than expected. Now, though, while iPhone 16 lead times are still shorter than at this time for the iPhone 15 range, the iPhone 16 Pro and iPhone 16 Pro Max appear to be selling better.
This is chiefly based on the lead times quoted by Apple, and Apple does not release any details about the numbers of iPhones either sold or produced. In a note to investors seen by AppleInsider, though, Morgan Stanley says it believes that better supply conditions are contributing to the shorter lead times.
Go Here to Read this Fast! iPhone SE 4 may be what Apple needs to make Apple Intelligence a hit
Originally appeared here:
iPhone SE 4 may be what Apple needs to make Apple Intelligence a hit

