ADA’s on-chain metrics with technical analysis indicated mixed sentiment among traders.
53.2% of top traders held short positions, while 46.8% held long positions.
A low-cost cryptocurrency under six cents is attracting attention for its potential to deliver significant returns by 2026. Some believe it could outperform established coins like Solana and Cardano.
After over a decade of building AI products at companies from Google Brain to Shopify Ads, I’ve witnessed the field’s evolution firsthand. With the rise of ChatGPT, AI has evolved from nice-to-have enhancements like photo organizers into major productivity boosters for all knowledge workers.
Most executives understand today’s buzz is more than hype—they’re desperate to make their companies AI-forward, knowing it’s more powerful and user-friendly than ever. So why, despite the potential and enthusiasm, is widespread adoption lagging? The real roadblock is how organizations approach work itself. Systemic issues are keeping these tools from becoming part of our daily grind.
Ultimately, the question executives need to ask isn’t “How can we use AI to do things faster? Or can this feature be built with AI? “ but rather “How can we use AI to create more value? What are the questions that we should be asking but aren’t?”
Real-world Impact
Recently, I leveraged large language models (LLMs) — the technology behind tools like ChatGPT — to tackle a complex data structuring and analysis task that would have traditionally taken a cross-functional team of data analysts and content designers a month or more.
Transformed thousands of rows of unstructured data into a structured, labeled dataset.
Used the AI to identify key user groups within this newly structured data.
Based on these patterns, developed a new taxonomy that can power a better, more personalized end user experience.
Notably, I did not just press a button and let AI do all the work.
It required intense focus, detailed instructions, and multiple iterations. I spent hours crafting precise prompts, providing feedback(like an intern, but with more direct language), and redirecting the AI when it veered off course.
In a sense, I was compressing a month’s worth of work into a day, and it was mentally exhausting.
The result, however, wasn’t just a faster process — it was a fundamentally better and different outcome. LLMs uncovered nuanced patterns and edge cases hidden within the unstructured data, creating insights that traditional analysis of pre-existing structured data would have missed entirely.
The Counterintuitive Truth
Here’s the catch — and the key to understanding our AI productivity paradox: My AI success hinged on having leadership support to dedicate a full day to rethinking our data processes with AI as my thought partner.
This allowed deep, strategic thinking — exploring connections and possibilities that would have otherwise taken weeks.
This type of quality-focused work is often sacrificed in the rush to meet deadlines, yet it’s precisely what fuels breakthrough innovation. Paradoxically, most people don’t have time to figure out how they can save time.
Dedicated time for exploration is a luxury most PMs can’t afford. Under constant pressure to deliver immediate results, most rarely have even an hour for this type of strategic work — the only way many find time for this kind of exploratory work is by pretending to be sick. They are so overwhelmed with executive mandates and urgent customer requests that they lack ownership over their strategic direction. Furthermore, recent layoffs and other cutbacks in the industry have intensified workloads, leaving many PMs working 12-hour days just to keep up with basic tasks.
This constant pressure also hinders AI adoption for improved execution. Developing robust testing plans or proactively identifying potential issues with AI is viewed as a luxury, not a necessity. It sets up a counterproductive dynamic: Why use AI to identify issues in your documentation if implementing the fixes will only delay launch? Why do additional research on your users and problem space if the direction has already been set from above?
Charting a New Course — Investing In People
Giving people time to “figure out AI” isn’t enough; most need some training to understand how to make ChatGPT do more than summarization. However, the training required is usually much less than people expect.
The market is saturated with AI trainings taught by experts. While some classes peddle snake oil, many instructors are reputable experts. Still, these classes often aren’t right for most people. They’re time-consuming, overly technical, and rarely tailored to specific lines of work.
I’ve had the best results sitting down with individuals for 10 to 15 minutes, auditing their current workflows, and identifying areas where they could use LLMs to do more, faster. You don’t need to understand the math behind token prediction to write a good prompt.
Don’t fall for the myth that AI adoption is only for those with technical backgrounds under the age of 40. In my experience, attention to detail and passion for doing the best work possible are far better indicators of success. Try to set aside your biases — you might be surprised by who becomes your next AI champion.
My own father, a lawyer in his 60s, only needed five minutes before he understood what LLMs could do. The key was tailoring the examples to his domain. We came up with a somewhat complex legal gray area and I asked Claude to explain this to a first year law student with edge case examples. He saw the response and immediately understood how he could use the technology for a dozen different projects. Twenty minutes later, he was halfway through drafting a new law review article he’d been meaning to write for months.
Chances are, your company already has a few AI enthusiasts — hidden gems who’ve taken the initiative to explore LLMs in their work. These “LLM whisperers” could be anyone: an engineer, a marketer, a data scientist, a product manager or a customer service manager. Put out a call for these innovators and leverage their expertise.
Once you’ve identified these internal experts, invite them to conduct one or two hour-long “AI audits”, reviewing your team’s current workflows and identifying areas for improvement. They can also help create starter prompts for specific use cases, share their AI workflows, and give tips on how to troubleshoot and evaluate going forward.
Besides saving money on external consultants — these experts are more likely to understand your company’s systems and goals, making them more likely to spot practical and relevant opportunities. People hesitant to adopt are also more likely to experiment when they see colleagues using the technology compared to “AI experts.”
In addition to ensuring people have space to learn, make sure they have time to explore and experiment with these tools in their domain once they understand their capabilities. Companies can’t simply tell employees to “innovate with AI” while simultaneously demanding another month’s worth of features by Friday at 5pm. Ensure your teams have a few hours a month for exploration.
Conclusion
The AI productivity paradox isn’t about the technology’s complexity, but rather how organizations approach work and innovation. Harnessing AI’s power is simpler than “AI influencers” selling the latest certification want you to believe — often requiring just minutes of targeted training. Yet it demands a fundamental shift in leadership mindset. Instead of piling on short-term deliverables, executives must create space for exploration and deep, open-ended, goal-driven work. The true challenge isn’t teaching AI to your workforce; it’s giving them the time and freedom to reinvent how they work.
This post covers my recent paper Cluster and Separate: A GNN Approach to Voice and Staff Prediction for Score Engraving published at ISMIR 2024
Background image originally created with Dall-E 3
Introduction
Music encoded in formats like MIDI, even when it includes quantized notes, time signatures, or bar information, often lacks important elements for visualization such as voice and staff information. This limitation also applies to the output from music generation, transcription, or arrangement systems. As a result, such music can’t be easily transformed into a readable musical score for human musicians to interpret and perform.
It’s worth noting that voice and staff separation are just two of many aspects — others include pitch spelling, rhythmic grouping, and tuplet creation — that a score engraving system might address.
In musical terms, “voice” often refers to a sequence of non-overlapping notes, typically called a monophonic voice. However, this definition falls short when dealing with polyphonic instruments. For example, voices can also include chords, which are groups of notes played simultaneously, perceived as a single unit. In this context, we refer to such a voice, capable of containing chords, as a homophonic voice.
The problem
Separating the notes from a quantized symbolic music piece (e.g., a MIDI file) into multiple voices and staves is an important and non-trivial task. It is a fundamental part of the larger task of music score engraving (or score type-setting), which aims to produce readable musical scores for human performers.
The musical score is an important tool for musicians due to its ability to convey musical information in a compact graphical form. Compared to other music representations that may be easier to define and process for machines, such as MIDI files, the musical score is characterized by how efficiently trained musicians can read it.
Given a Quantized Midi there are many possibilities for transforming it to a readable format, which mostly consists of separating the notes into voices and staves.
See below two of these possibilities. They demonstrate how engraving systems usually work.
The big question is how can we make automatic transcription models better.
Motivation
To develop a more effective system for separating musical notes into voices and staves, particularly for complex piano music, we need to rethink the problem from a different perspective. We aim to improve the readability of transcribed music starting from a quantized MIDI, which is important for creating good score engravings and better performance by musicians.
For good score readability, two elements are probably the most important:
the separation of staves, which organizes the notes between the top and bottom staff;
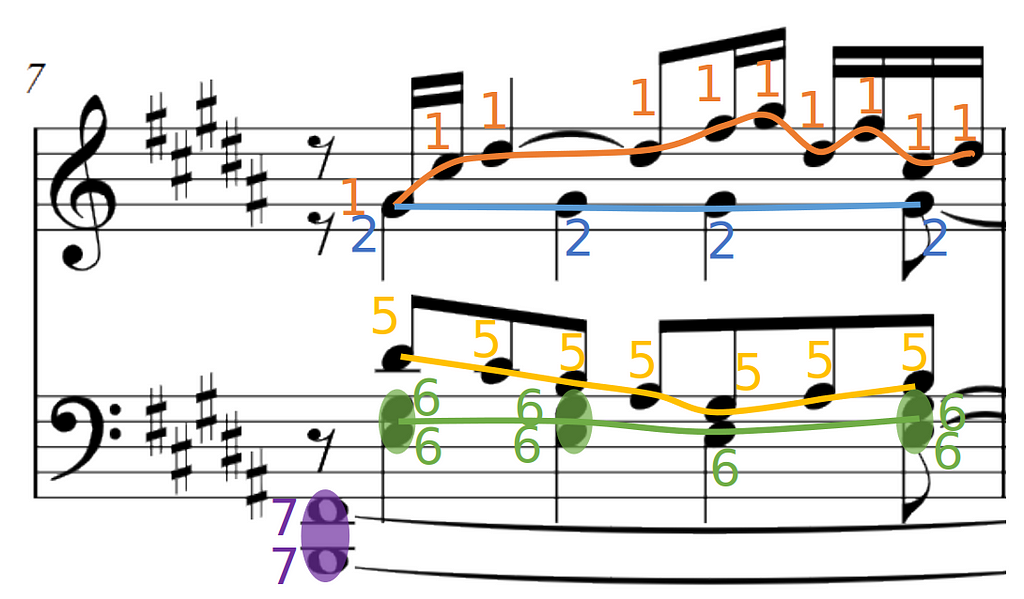
and the separation of voices, highlighted in this picture with lines of different colors.
Voice streams in a piano score
In piano scores, as said before, voices are not strictly monophonic but homophonic, which means a single voice can contain one or multiple notes playing at the same time. From now on, we call these chords. You can see some examples of chord highlighted in purple in the bottom staff of the picture above.
From a machine-learning perspective, we have two tasks to solve:
The first is staff separation, which is straightforward, we just need to predict for each note a binary label, for top or bottom staff specifically for piano scores.
The voice separation task may seem similar, after all, if we can predict the voice number for each voice, with a multiclass classifier, and the problem would be solved!
However, directly predicting voice labels is problematic. We would need to fix the maximum number of voices the system can accept, but this creates a trade-off between our system flexibility and the class imbalance within the data.
For example, if we set the maximum number of voices to 8, to account for 4 in each staff as it is commonly done in music notation software, we can expect to have very few occurrences of labels 8 and 4 in our dataset.
Voice Separation with absolute labels
Looking specifically at the score excerpt here, voices 3,4, and 8 are completely missing. Highly imbalanced data will degrade the performance of a multilabel classifier and if we set a lower number of voices, we would lose system flexibility.
Methodology
The solution to these problems is to be able to translate the knowledge the system learned on some voices, to other voices. For this, we abandon the idea of the multiclass classifier, and frame the voice prediction as a link prediction problem. We want to link two notes if they are consecutive in the same voice. This has the advantage of breaking a complex problem into a set of very simple problems where for each pair of notes we predict again a binary label telling whether the two notes are linked or not. This approach is also valid for chords, as you see in the low voice of this picture.
This process will create a graph which we call an output graph. To find the voices we can simply compute the connected components of the output graph!
To re-iterate, we formulate the problem of voice and staff separation as two binary prediction tasks.
For staff separation, we predict the staff number for each note,
and to separate voices we predict links between each pair of notes.
While not strictly necessary, we found it useful for the performance of our system to add an extra task:
Chord prediction, where similar to voice, we link each pair of notes if they belong to the same chord.
Let’s recap what our system looks like until now, we have three binary classifiers, one that inputs single notes, and two that input pairs of notes. What we need now are good input features, so our classifiers can use contextual information in their prediction. Using deep learning vocabulary, we need a good note encoder!
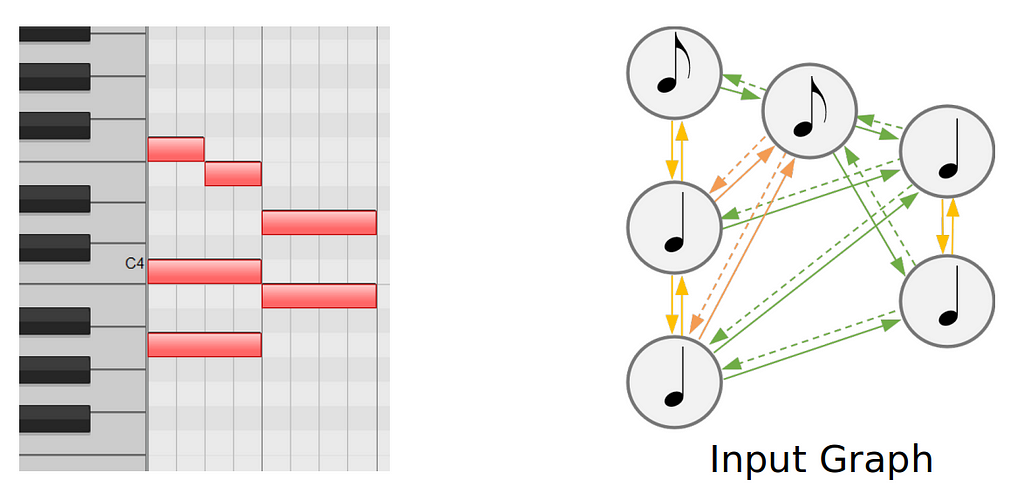
We choose to use a Graph Neural Network (GNN) as a note encoder as it often excels in symbolic music processing. Therefore we need to create a graph from the musical input.
For this, we deterministically build a new graph from the Quantized midi, which we call input graph.
Creating these input graph can be done easily with tools such as GraphMuse.
Now, putting everything together, our model looks something like this:
It starts with some quantized midi which is preprocessed to a graph to create the input graph.
The input graph goes through a Graph Neural Network (GNN) to create an intermediate latent representation for every note. We encode every note therefore we call this part, the GNN encoder;
Then we feed this to a shallow MLP classifier for our three tasks, voice, staff, and chord prediction. We can also call this part the decoder;
After the prediction, we obtain an output graph.
The approach until now, can be seen as a graph-to-graph approach, where we start from the input graph that we built from the MIDI, to predict the output graph containing voice and chord links and staff labels.
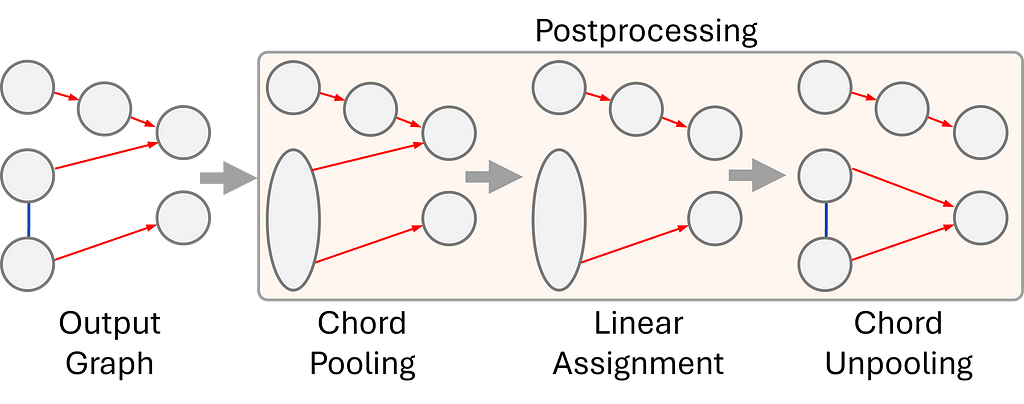
5. For the final step, our output graph goes through a postprocessing routine to create a beautiful and easy-to-read musical score.
The goal of the postprocessing is to remove configurations that could lead to an invalid output, such as a voice splitting into two voices. To mitigate these issues:
we cluster the notes that belong to the same chord according to the chord prediction head
We ensure every node has a maximum of one incoming and outgoing edge by applying a linear assignment solution;
And, finally, propagate the information back to the original nodes.
Postprocessing routine of our system
One of the standout features of our system is its ability to outperform other existing systems in music analysis and score engraving. Unlike traditional approaches that rely on musical heuristics — which can sometimes be unreliable — our system avoids these issues by maintaining a simple but robust approach. Furthermore, our system is able to compute a global solution for the entire piece, without segmentation due to its low memory and computational requirements. Additionally, it is capable of handling an unlimited number of voices, making it a more flexible and powerful tool for complex musical works. These advantages highlight the system’s robust design and its capacity to tackle challenges in music processing with greater precision and efficiency.
Datasets
To train and evaluate our system we used two datasets. The J-pop dataset, which contains 811 pop piano scores, and the DCML romantic corpus which contains 393 romantic music piano scores. Comparatively, the DCML corpus is much more complex, since it contains scores that present a number of difficulties such as a high number of voices, voice crossing, and staff crossing. Using a combination of complex and simpler data we can train a system that remains robust and flexible to diverse types of input.
Visualizing the Predictions
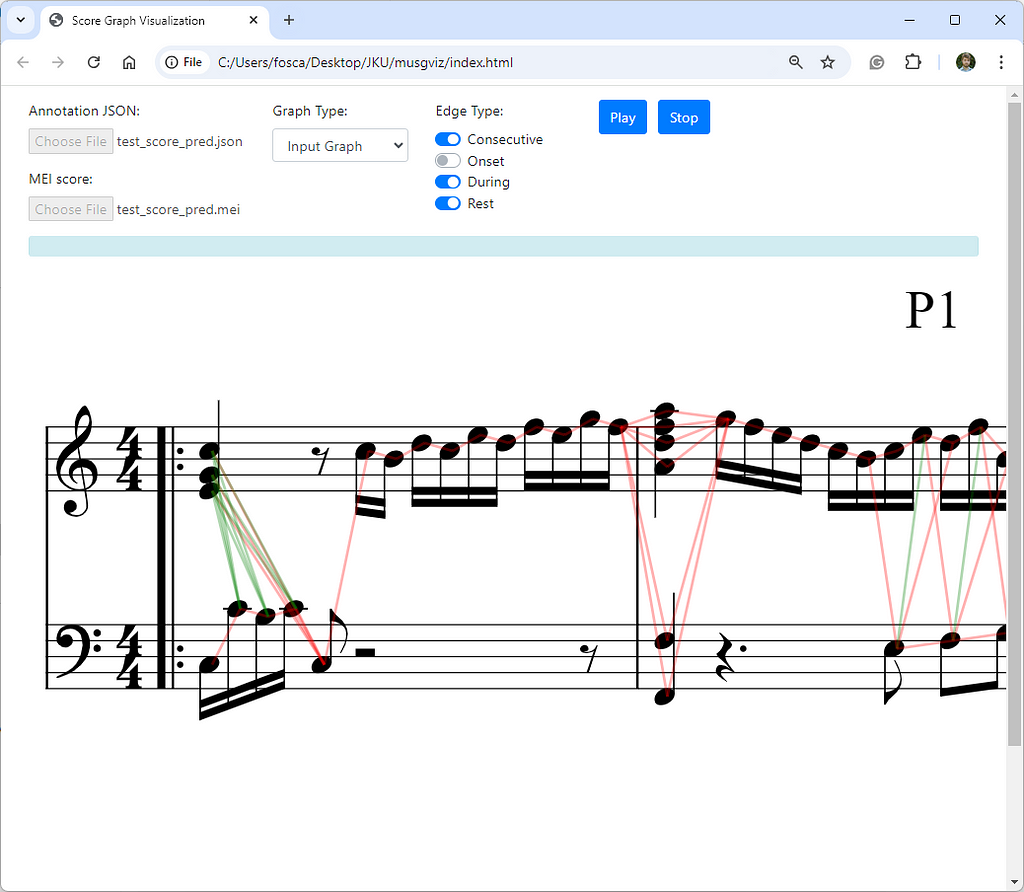
To accompany our system, we also developed a web interface where the input and output graphs can be visualized and explored, to debug complex cases, or simply to have a better understanding of the graph creation process. Check it out here.
Our web interface, MusGViz!
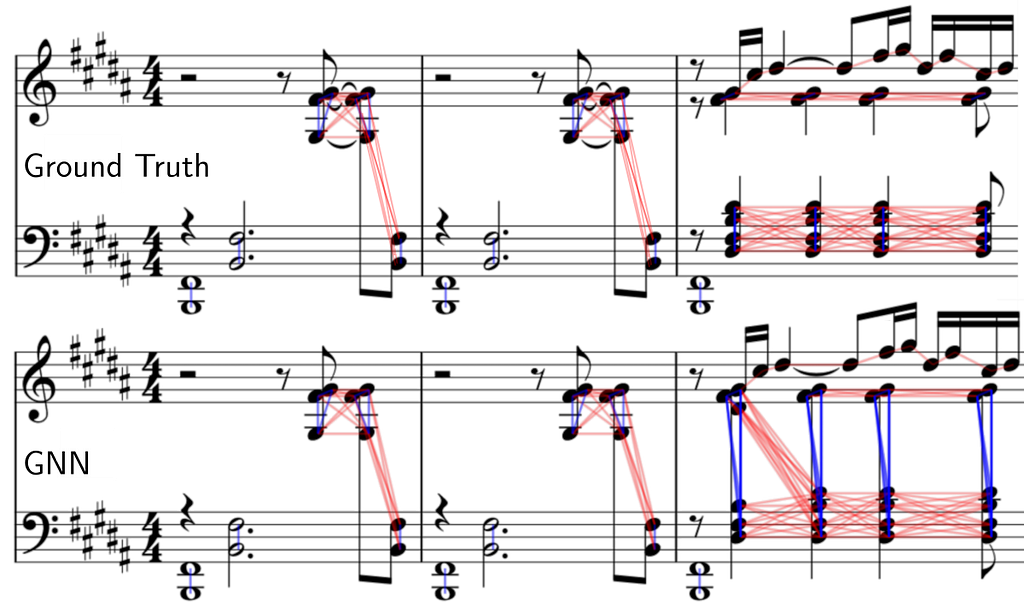
In the interest of giving a fair comparison and deeper understanding of how our model works and how the predictions can vary, we take a closer look at some.
We compare the ground truth edges (links) to our predicted edges for chord and voice prediction. Note that in the example you are viewing below the output graph is plotted directly on top of the score with the help of our visualization tool.
The first two bars are done perfectly, however we can see some limitations of our system at the third bar. Synchronous notes within a close pitch range but with a different voice arrangement can be problematic.
Our model predicts a single chord (instead of splitting across the staff) containing all the synchronous syncopated quarter notes and also mispredicts the staff for the first D#4 note. A more in-depth study of why this happens is not trivial, as neural networks are not directly interpretable.
Open Challenges
Despite the strengths of our system, several challenges remain open for future development. Currently, grace notes are not accounted for in this version, and overlapping notes must be explicitly duplicated in the input, which can be troublesome. Additionally, while we have developed an initial MEI export feature for visualizing the results, this still requires further updates to fully support the various exceptions and complexities found in symbolic scores. Addressing these issues will be key to enhancing the system’s versatility and making it more adaptable to diverse musical compositions.
Conclusion
This blog presented a graph-based method for homophonic voice separation and staff prediction in symbolic piano music. The new approach performs better than existing deep-learning or heuristic-based systems. Finally, it includes a post-processing step that can remove problematic predictions from the model that could result in incorrect scores.
The OnePlus Watch 2R is a streamlined version of its flagship sibling, with a sharp design and marathon battery life at a competitive, discounted price ahead of Black Friday.
The GE Opal 2.0 is a premium ice maker with all the smarts to make it an exceptionally satisfying kitchen appliance. It’s $50 off ahead of Black Friday.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.