Japanese firm Metaplanet has acquired an additional $10 million in Bitcoin (BTC), bringing its total holdings of the flagship crypto to over $1,000 as it continues with its October BTC shopping spree. The Tokyo-based company has purchased 156.78 BTC for approximately $10.4 million, bringing its total holdings to 1,108 ($68.8 million), it announced on Monday. […]
Elon Musk, the world’s richest man and founder of Tesla and SpaceX, has once again recently mentioned the leading meme cryptocurrency, Dogecoin (DOGE).
AI-driven strategies are redefining crypto now. AI-based crypto projects are beginning to gain a better reputation than other types of cryptocurrencies. POPCAT and MAGA are examples of these projects. The same AI system that discovered POPCAT and MAGA has identified a new opportunity, PropiChain (PCHAIN). Positioned to generate 12,000x returns by January 2025, PCHAIN’s revolutionary […]
2025 is just a stone’s throw away, and as we keep getting closer, we see that some of the latest trends in RWA (Real-World Assets) and Crypto AI altcoins are making waves. Among these tokens is PropiChain, which is praised alongside other crypto AI projects for bringing good returns. This article focuses on the best […]
With the Shiba Inu price growth slowing down significantly since its peak, it is facing increased scrutiny as many begin to question the long-term viability of Shiba Inu (SHIB). Although the coin has seen a slight uptick recently, analysts suggest that the dream of the Shiba Inu price reaching $5 by 2030 may be overly […]
What The Paper on LLM Reasoning Got Right — And What It Missed.
Co-authors: Alex Watson, Yev Meyer, Dane Corneil, Maarten Van Segbroeck (Gretel.ai)
Source: Gretel.ai
Introduction
Large language models (LLMs) have recently made significant strides in AI reasoning, including mathematical problem-solving. However, a recent paper titled “GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models” by Mirzadeh et al. raises questions about the true capabilities of these models when it comes to mathematical reasoning. We have reviewed the paper and found it to be a valuable contribution to the ongoing discussion about AI capabilities and limitations, however, our analysis suggests that its conclusions may not fully capture the complexity of the issue.
The GSM-Symbolic Benchmark
The authors introduce GSM-Symbolic, an enhanced benchmark derived from the popular GSM8K dataset. This new benchmark allows for the generation of diverse question variants, enabling a more nuanced evaluation of LLMs’ performance across various setups. The study’s large-scale analysis of 25 state-of-the-art open and closed models provides significant insights into how these models behave when faced with mathematical reasoning tasks.
Figure 1: GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models (Source: Mirzadeh et al., GSM-Symbolic Paper)
Performance Variability and Model Comparisons
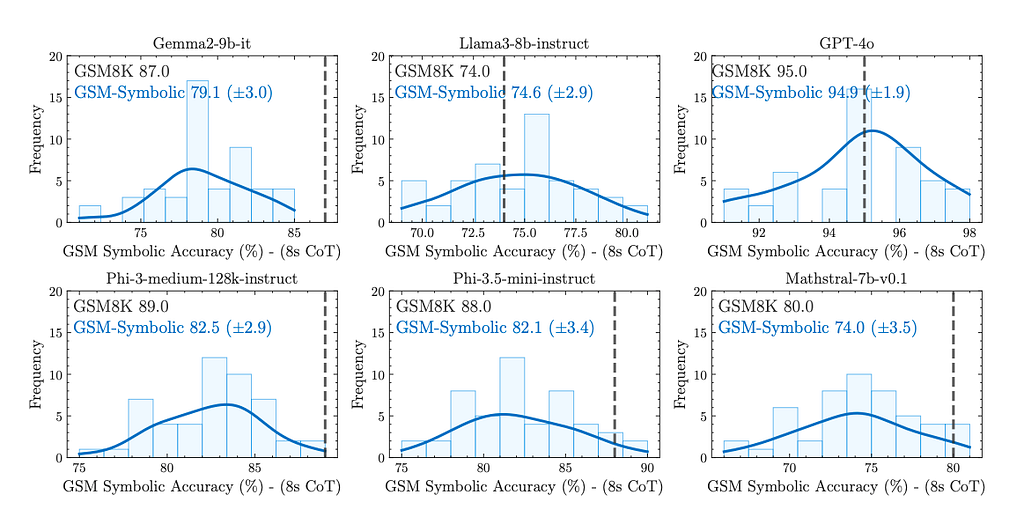
One of the most surprising findings is the high variability in model performance across different instantiations of the same question. All models exhibit “significant variability in accuracy” when tested on GSM-Symbolic. This variability raises concerns about the reliability of currently reported metrics on the GSM8K benchmark, which relies on single point-accuracy responses.
Figure 3: GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models (Source: Mirzadeh et al., GSM-Symbolic Paper)
Not all models are created equal. Llama-3–8b and GPT-4o are clear outliers in that they don’t exhibit as significant of a drop on the new benchmark as other models like gemma-2–9b, phi-3, phi-3.5 and mathstral-7b. This observations suggests two important points:
Llama-3–8b and GPT-4o generally demonstrate a more robust understanding of mathematical concepts, although they are still not immune to performance variations.
The training data for Llama-3–8b and GPT-4o likely has not been contaminated (or at least not to the same extent) with GSM8K data. In this context, data contamination refers to the unintentional inclusion of test or benchmark data in a model’s training set, leading to artificially inflated model performance during evaluation. If contamination had occurred, as the authors hypothesize for some models, we would expect to see very high performance on GSM8K but significantly lower performance on even slight variations of these problems.
These findings highlight a opportunity for improvement through the use of synthetic data, where properly designed synthetic datasets can address both of these points for anyone training models:
To mitigate potential data contamination issues, there’s no need to use the original GSM8K data in training when high-quality synthetic versions can be generated (blog link). These synthetic datasets retain the mathematical reasoning challenges of GSM8K without reusing the exact problems or solutions, thus preserving the integrity of the model’s evaluation.
Even more importantly, it’s possible to generate synthetic data that surpass the quality of both the OpenAI GSM8K and Apple GSM-Symbolic datasets. This approach can lead to a more robust understanding of mathematical concepts, addressing the performance variability observed in current models.
Sensitivity to Changes and Complexity
The authors show that LLMs are more sensitive to changes in numerical values than to changes in proper names within problems, suggesting that the models’ understanding of the underlying mathematical concepts may not be as robust as previously thought. As the complexity of questions increases (measured by the number of clauses), the performance of all models degrades, and the variance in their performance increases. This highlights the importance of using diverse data in training, and this is something that synthetics can help with. As the authors demonstrate, there is logically no reason why a AI model should perform worse on a given set of problems, with just a simple change in numbers or a slight variation in the number of clauses.
Figure 4: GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models (Source: Mirzadeh et al., GSM-Symbolic Paper)
The GSM-NoOp Challenge
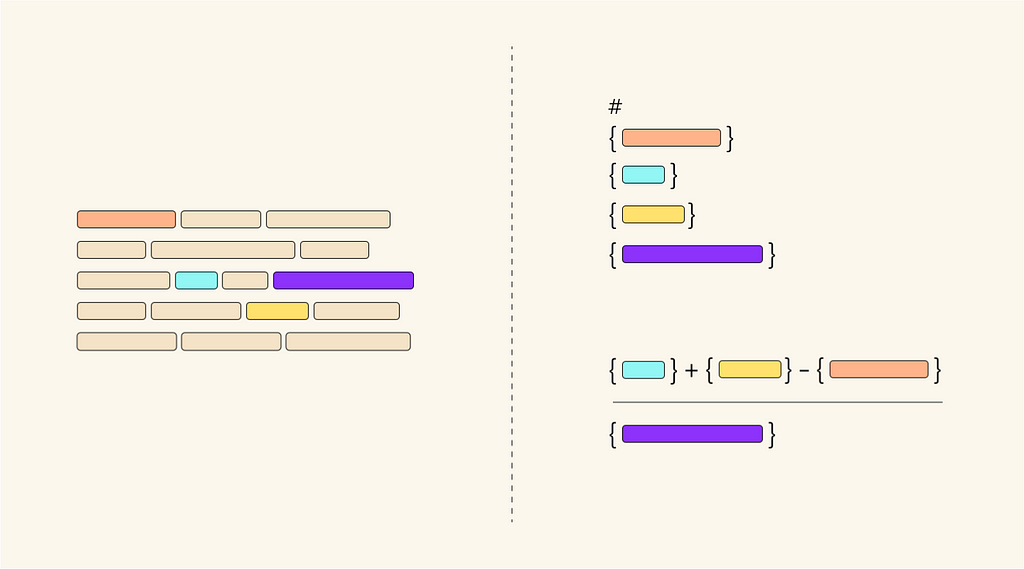
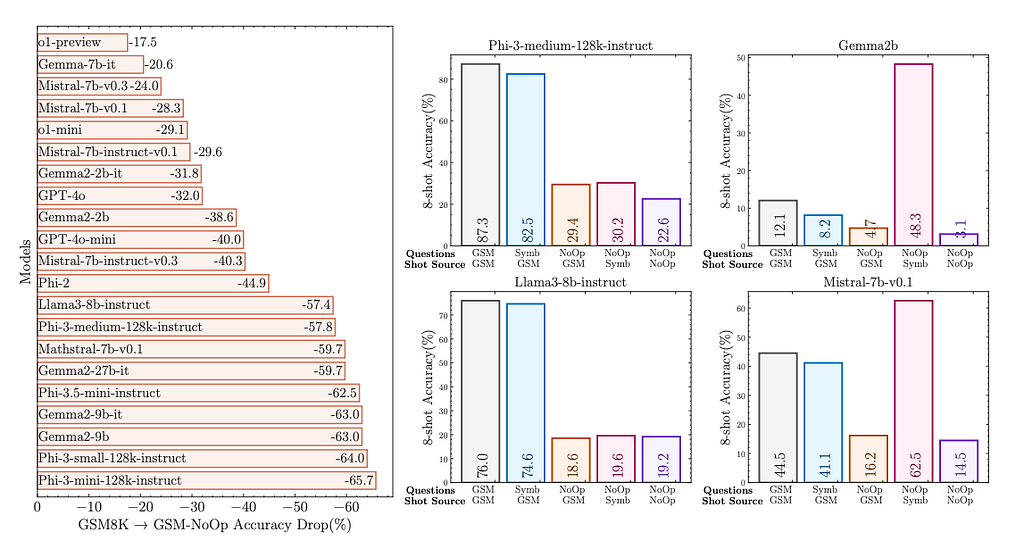
Perhaps the most concerning finding is the introduction of GSM-NoOp, a dataset designed to challenge the reasoning capabilities of LLMs. By adding seemingly relevant but ultimately inconsequential information to problems, the authors observed substantial performance drops across all models — up to 65% for some. The authors propose that this points to current LLMs relying more on a type of pattern matching than true logical reasoning
Figure 6: GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models (Source: Mirzadeh et al., GSM-Symbolic Paper)
A Critical Perspective on the Paper’s Conclusions
While the GSM-Symbolic study provides valuable insights into the performance of LLMs on mathematical reasoning tasks, it’s important to critically examine the paper’s conclusions. The authors argue that the observed limitations suggest LLMs are not capable of true logical reasoning. However, this interpretation may be oversimplifying a complex issue.
The paper’s argument for LLMs relying on pattern matching rather than reasoning seems less definitive when examined closely. It’s clear that these models are not perfect reasoners — if they were, they would achieve 100% accuracy on GSM8K. But the leap from imperfect performance to a lack of reasoning capability is not necessarily justified.
There are at least two potential explanations for why LLMs, like humans, sometimes get questions wrong:
The model tries to strictly pattern match a problem to something it has seen before, and fails if it can’t.
The model tries to follow a logical program but has a certain (compounding) probability of making an error at each step, as expected based on the fact that it literally samples tokens.
The paper seems to lean towards explanation (1), but doesn’t make a convincing case for why this should be preferred over explanation (2). In fact, (2) is more akin to human-like reasoning and potentially more interesting from a research perspective.
Let’s examine each main finding of the paper through this critical lens:
GSM-Symbolic Performance
The GSM-Symbolic approach is a valuable method for dataset expansion, validating the potential of synthetic data generation techniques like those used by Gretel. However, it’s worth noting that model performance doesn’t completely fall apart on these new variants — it just gets somewhat worse. If the models were strictly pattern matching, we might expect performance to drop to near zero on these new variants. The observed behavior seems more consistent with a model that can generalize to some degree but makes more errors on unfamiliar problem structures.
Even human experts are not infallible. On the MATH benchmark, for instance, former math olympians typically scored 18/20 or 19/20, making small arithmetic errors. This suggests that error-prone reasoning, rather than a lack of reasoning capability, might be a more accurate description of both human and LLM performance.
Varying Difficulty
The paper’s findings on performance degradation with increasing question complexity are consistent with the idea of compounding errors in a multi-step reasoning process. As the number of steps increases, so does the probability of making an error at some point in the chain. This behavior is observed in human problem-solving as well and doesn’t necessarily indicate a lack of reasoning ability.
GSM-NoOp Challenge
The GSM-NoOp results, may not be as directly related to reasoning capability as the paper suggests. In real-world scenarios, we typically assume that all information provided in a problem statement is relevant. For instance, in the example question in Figure 7, a reasonable human might infer (like the LLMs did) that the size of the kiwis was only mentioned because they were discarded.
The ability to discern relevant information from irrelevant information, especially when the irrelevant information is inserted with the intent to be misleading (i.e. seemingly relevant), is a separate skill from pure mathematical reasoning.
The authors include a follow-up experiment (NoOp-NoOp) in which the models are implicitly “warned” of the misleading intent: they use few-shot examples that also contain irrelevant information. The subset of models illustrated with this experiment still show a drop in performance. Several follow-up experiments could serve to better understand the phenomenon:
Expand the NoOp-NoOp experiment to more models;
Measure how well models perform when explicitly warned that some information may be irrelevant in the prompt;
Fine-tune models on synthetic training examples that include irrelevant information in addition to examples that contain entirely relevant information.
Opportunities for Improvement: The Promise of Synthetic Data
While the paper by Mirzadeh et al. highlights important limitations in current LLMs, at Gretel we have developed datasets that address many of the challenges identified in the paper:
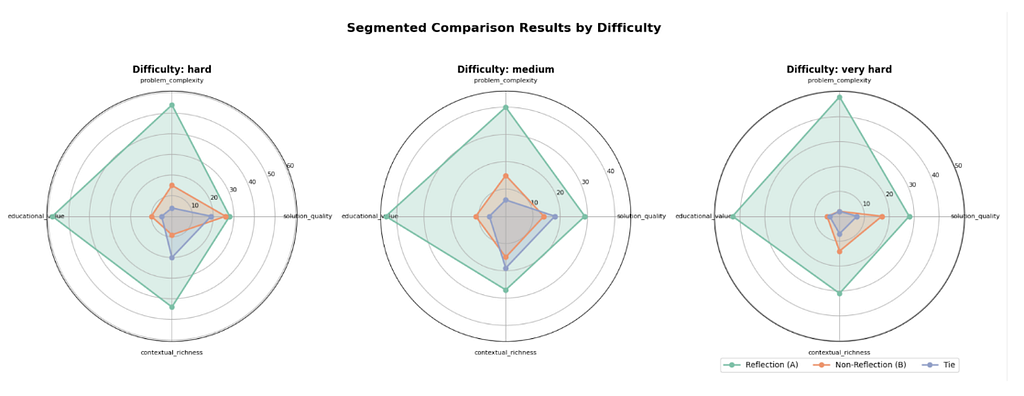
Synthetic GSM8K Dataset: Available on HuggingFace at gretelai/synthetic-gsm8k-reflection-405b, this dataset focuses on generating more complex, multi-step reasoning versions of problems than what existed in the original human generated dataset from OpenAI. It incorporates advanced prompting techniques, including Reflection and other cognitive models, to capture detailed reasoning processes. This approach has shown significant improvements, particularly for very hard problems, demonstrating its potential to enhance AI’s ability to handle complex, multi-step reasoning tasks. As covered in our blog, Gretel’s synthetic data created using these techniques achieved a 92.3% win-rate on problem complexity and an 82.7% win-rate for educational value over the standard Llama 3.1 405B parameter model outputs, using these advanced techniques as judged by GPT-4o- demonstrating that LLM reasoning can further be unlocked with more sophisticated training data examples and prompting techniques than the basic Chain-of-Thought used in the paper.
2. Synthetic Text-to-SQL Dataset: Generated by Gretel to help improve LLMs ability to interact with SQL-based databases/warehouses & lakes, available at gretelai/synthetic_text_to_sql, has proven highly effective in improving model performance on Text-to-SQL tasks. When used to fine-tune CodeLlama models, it led to 36%+ improvements on the BIRD benchmark, a challenging cross-domain Text-to-SQL evaluation platform. Further supporting the theory about today’s LLMs being trained on data that is too simple and leading to memorization, a single epoch of fine-tuning the Phi-3 and Llama 3.1 models on this dataset yielded a 300%+ improvement on BIRD benchmark problems labeled as “very hard”.
These results demonstratethat high-quality synthetic data can be a powerful tool in addressing the limitations of current LLMs in complex reasoning tasks.
Future Directions
In conclusion, the GSM-Symbolic paper provides valuable insights into the current limitations of LLMs in mathematical reasoning tasks. However, its conclusions should be approached critically. The observed behavior of LLMs could be interpreted in multiple ways, and it’s possible that the paper’s emphasis on pattern matching over reasoning may be oversimplifying a more complex issue.
The limitations identified by the study are real and significant. The variability in performance, sensitivity to numerical changes, and struggles with irrelevant information all point to areas where current LLMs can be improved.
However, as demonstrated by more advanced models such as GPT-4o and Llama 3.1 above- by synthesizing diverse, challenging problem sets that push the boundaries of what AI models can tackle, we can develop LLMs that exhibit more robust, human-like reasoning capabilities.
The proliferation of data-driven systems and ML applications escalates a number of privacy risks, including those related to unauthorized access to sensitive information. In response, international data protection frameworks like the European General Data Protection Regulation (GDPR), the California Privacy Rights Act (CPRA), the Brazilian General Data Protection Law (LGPD), etc.have adopted data minimizationas a key principle to mitigate these risks.
Excerpts of the data minimization principle from six different data protection regulations across the world. Image by Author.
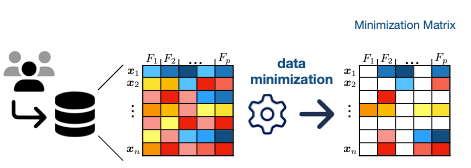
At its core, the data minimization principle requires organizations to collect, process, and retain only personal data that is adequate, relevant, and limited to what is necessary for specified objectives. It’s grounded in the expectation that not all data is essential and, instead, contributes to a heightened risk of information leakage. The data minimization principle builds on two core pillars, purpose limitation and data relevance.
Purpose Limitation
Data protection regulations mandate that data be collected for a legitimate, specific and explicit purpose (LGPD, Brazil) and prohibit using the collected data for any other incompatible purpose from the one disclosed (CPRA, USA). Thus, data collectors must define a clear, legal objective before data collection and use the data solely for that objective. In an ML setting, this purpose can be seen as collecting data for training models to achieve optimal performance on a given task.
Data Relevance
Regulations like the GDPR require that all collected data be adequate, relevant, and limited to what is necessary for the purposes it was collected for. In other words, data minimization aims to remove data that does not serve the purpose defined above. In ML contexts, this translates to retaining only data that contributes to the performance of the model.
Data minimization. Image by Author
Privacy expectations through minimization
As you might have already noticed, there is an implicit expectation of privacy through minimization in data protection regulations. The data minimization principle has even been hailed by many in the public discourse (EDPS, Kiteworks, The Record, Skadden, k2view) as a principle to protect privacy.
The EU AI Act states in Recital 69, “The right to privacy and to protection of personal data must be guaranteed throughout the entire lifecycle of the AI system. In this regard, the principles of data minimisation and data protection by design and by default, as set out in Union data protection law, are applicable when personal data are processed”.
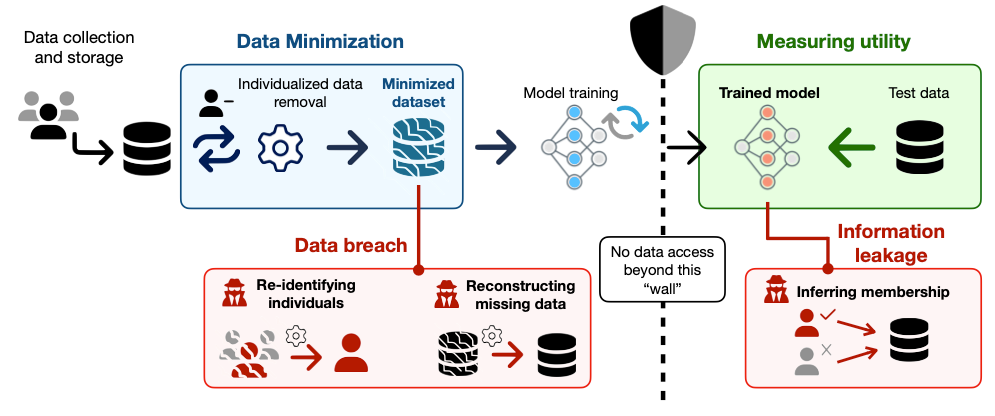
However, this expectation of privacy from minimization overlooks a crucial aspect of real world data–the inherent correlations among various features! Information about individuals is rarely isolated, thus, merely minimizing data, may still allow for confident reconstruction. This creates a gap, where individuals or organizations using the operationalization attempts of data minimization, might expect improved privacy, despite using a framework that is limited to only minimization.
The Correct Way to Talk about Privacy
Privacy auditing often involves performing attacks to assess real-world information leakage. These attacks serve as powerful tools to expose potential vulnerabilities and by simulating realistic scenarios, auditors can evaluate the effectiveness of privacy protection mechanisms and identify areas where sensitive information may be revealed.
Some adversarial attacks that might be relevant in this situation include reconstruction and re-identification attacks. Reconstruction attacks aim to recover missing information from a target dataset.Re-identification attacks aim to re-identify individuals using partial or anonymized data.
The Overall Framework. Image by Author
The gap between Data Minimization and Privacy
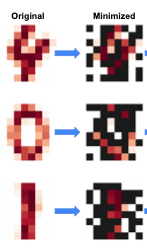
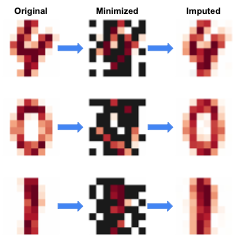
Consider the example of minimizing data from an image, and removing pixels that do not contribute to the performance of the model. Solving that optimization would give you minimized data that looks something like this.
Image by Author
The trends in this example are interesting. As you’ll notice, the central vertical line is preserved in the image of the digit ‘1’, while the outer curves are retained for ‘0’. In other words, while 50% of the pixels are removed, it doesn’t seem like any information is lost. One can even show that is the case by applying a very simple reconstruction attack using data imputation.
Image by Author
Despite minimizing the dataset by 50%, the images can still be reconstructed using overall statistics. This provides a strong indication of privacy risks and suggests that a minimized dataset does not equate to enhanced privacy!
So What Can We Do?
While data protection regulations aim to limit data collection with an expectation of privacy, current operationalizations of minimization fall short of providing robust privacy safeguards. Notice, however, that this is not to say that minimization is incompatible with privacy; instead, the emphasis is on the need for approaches that incorporate privacy into their objectives, rather than treating them as an afterthought.
We provide a deeper empirical exploration of data minimization and its misalignment with privacy, along with potential solutions, in our paper. We seek to answer a critical question: “Do current data minimization requirements in various regulations genuinely meet privacy expectations in legal frameworks?” Our evaluations reveal that the answer is, unfortunately, no.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.