
Originally appeared here:
Continual Learning: The Three Common Scenarios
Go Here to Read this Fast! Continual Learning: The Three Common Scenarios
How a Decentralized Collaborative Intelligence Network works
Originally appeared here:
A Gentle Introduction to the DCIN for Decentralized Inference
Go Here to Read this Fast! A Gentle Introduction to the DCIN for Decentralized Inference


Originally appeared here:
Automate Amazon Bedrock batch inference: Building a scalable and efficient pipeline


Conference attendance has been a frequent occurrence for me as a data professional since my early career days. The field of data science is so vast and diverse. While that means that there is a huge variety of data roles and practitioners out there, it could also mean that no matter how small your niche, or how specific and esoteric your specific problem is, there is always someone else out there with the same problem in a different company. The proof is in the endless number of questions and memes in Stack Overflow /Kaggle threads and other knowledge-base forums. During my early career connecting with the data community out there was so helpful for me to learn novel techniques and apply new knowledge to some of the old problems I was solving and become a more efficient analyst.
“Many ideas grow better when transplanted into another mind than the one where they sprang up.” — Oliver Wendell Holmes.
More recently, I started attending data community gatherings and conferences as a speaker and having a seat at the table with expert panels and the speaker lounges has been a game changer. It has helped me immensely to think creatively about my job and role in Data Stewardship and become a better data mentor and steward for folks who rely on my expertise. I recently attended Data Connect 2024 as a speaker. While most of the conferences happening in the past couple of years have been heavily focused on AI, I was fortunate enough to learn about the following three critical aspects of Data Analytics and management that I could easily apply in my day-to-day responsibilities. In this article, I’ll be sharing my interpretation and learnings from these sessions, action items, and my reflections on these crucial data topics as a data practitioner of over 12 years.
The concept of Data ROI gets talked about a lot, but rarely does it get quantified and becomes an official metric that gets tracked and shared out consistently. Cost containment has been on my mind for me both as an Individual Contributor and a Team Lead, starting from my days as an Analytics Intern. Who can forget their first time letting their un-optimized SQL query with full outer joins run for several hours before getting a warning call from their org’s DBA? (Not me !) Ever since then, Cost containment has been one of those concepts that has been living rent-free in my brain. Many data solutions providers have switched from a Tier-based pricing model to a consumption-based pricing model which makes cost optimization an essential tool in the data management and leadership toolkit.
Data teams may face unexpected bills when query optimization is overlooked or when inefficient data practices are in place. For instance, apart from running extensive queries, even failing to archive unused data can lead to substantial increases in data storage costs. To manage such unexpected expenses, it is crucial to implement effective cost management strategies. This includes monitoring usage patterns, optimizing queries, and setting up alerts for unusual activity. By understanding these hidden costs, teams can better control their data tools’ pricing, ensuring a sustainable data ROI. I also learned about the importance of investing in training data teams to optimize their use of analytics tools. Educating staff on cost-efficient query writing and data handling ensures that resources are utilized to their full potential is often overlooked, but it is one of the low-hanging fruits that can be effective in cutting costs.
Another pitfall occurs when data teams fail to accurately forecast their data usage. This oversight can result in substantial unanticipated expenses, particularly when scaling operations rapidly. To avoid these pitfalls, it is essential for organizations to maintain open communication with vendors, closely monitor data usage, and regularly review contract terms. By anticipating changes and preparing for potential cost fluctuations, businesses can better manage their data tools pricing and ensure their data ROI remains positive.
Actionable takeaways:
While Cost containment is one important piece that influences the Data teams’ ROI, the other side of this coin is measuring the worth and effectiveness of Data Analytics efforts and eventually the data teams. As I was wrapping up my notes from listening to a talk related to Data Analytics Team efficiencies, one of the moderators sparked up an interesting discussion related to “Data Translation” and the need for dedicated organizational efforts to bridge the literacy gaps between Data and Business teams.

As data infrastructure and data team hiring costs have been consistently increasing, it’s crucial for businesses to see a return on this investment. High costs can be justified only if the data team’s work translates into actionable insights that drive business growth, innovation, and efficiency. Without clear value, these expenses can seem burdensome. Data leaders need to ensure that their teams are aligned with business objectives and are working on projects that offer substantial returns. By effectively managing these costs, organizations can maintain a competitive edge and leverage data as a strategic asset. This requires thoughtful allocation of resources, prioritization of impactful projects, and fostering a culture of data literacy to maximize the utility and influence of the data team across the organization.
Actionable takeaways :

As I went through the speaker coaching boot camp, I couldn’t help but draw parallels between public speaking tactics and the data storytelling tactics we often learn in our jobs. The process of brainstorming and picking a well-rounded topic, being okay with imperfections, and finally getting it all mapped into an overall governing idea made me reflect on how Data storytelling is much more than pretty charts and documenting patterns. I also got to listen to a great presentation focusing on Effective visual communication tips for data presentations. I learned that by integrating narrative with data visualization, you engage both the logical and emotional sides of your audience’s brain, making your insights more memorable. This approach ensures that data isn’t just seen as numbers on a page but as a critical driver of strategic decisions. I also learned that aligning your data story with the audience’s needs and data literacy is the easiest way to encourage them to take meaningful action based on the data.
Actionable takeaways :
Attending data conferences is a great way to keep up with the current trends and learn new concepts. While AI-adjacent topics have dominated most of the conference agendas over the past couple of years for very valid reasons, I was deeply grateful to learn about these three crucial Data management advancements that helped solidify my foundational knowledge, Data communication skills, and tap into the collective hive mind of experienced Data Subject matter experts to solve problems that are as ubiquitous as AI.
Note: A big thank you to Data Leaders Kathy Koontz, Lindsey Cohen, Akia Obas, Lyndsey Pereira-Brereton, and many more bright minds for having these thought-provoking discussions with me and inspiring this post.
About the Author :
Nithhyaa Ramamoorthy is a Data Subject matter Expert with over 12 years’ worth of experience in Analytics and Big Data, specifically in the intersection of Healthcare and Consumer behavior. She holds a Master’s Degree in Information Sciences and more recently a CSPO along with several other professional certifications. She is passionate about leveraging her analytics skills to drive business decisions that create inclusive and equitable digital products rooted in empathy.
Three Crucial Data Lessons That I Learned from a Data Conference That’s Not Related to AI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Three Crucial Data Lessons That I Learned from a Data Conference That’s Not Related to AI
From unstructured Wikipedia text to structured JSON: A step-by-step guide.
Originally appeared here:
An Agentic Approach to Textual Data Extraction Using LLMs and LangGraph
Go Here to Read this Fast! An Agentic Approach to Textual Data Extraction Using LLMs and LangGraph


How I created an immersive AI group chat using Ollama, FastAPI, open-source LLMs, and React
Originally appeared here:
Building Your Own AI Group Chat: A Journey into Custom Universes and Characters


Originally appeared here:
Build a video insights and summarization engine using generative AI with Amazon Bedrock


Originally appeared here:
Automate document processing with Amazon Bedrock Prompt Flows (preview)
Go Here to Read this Fast! Automate document processing with Amazon Bedrock Prompt Flows (preview)

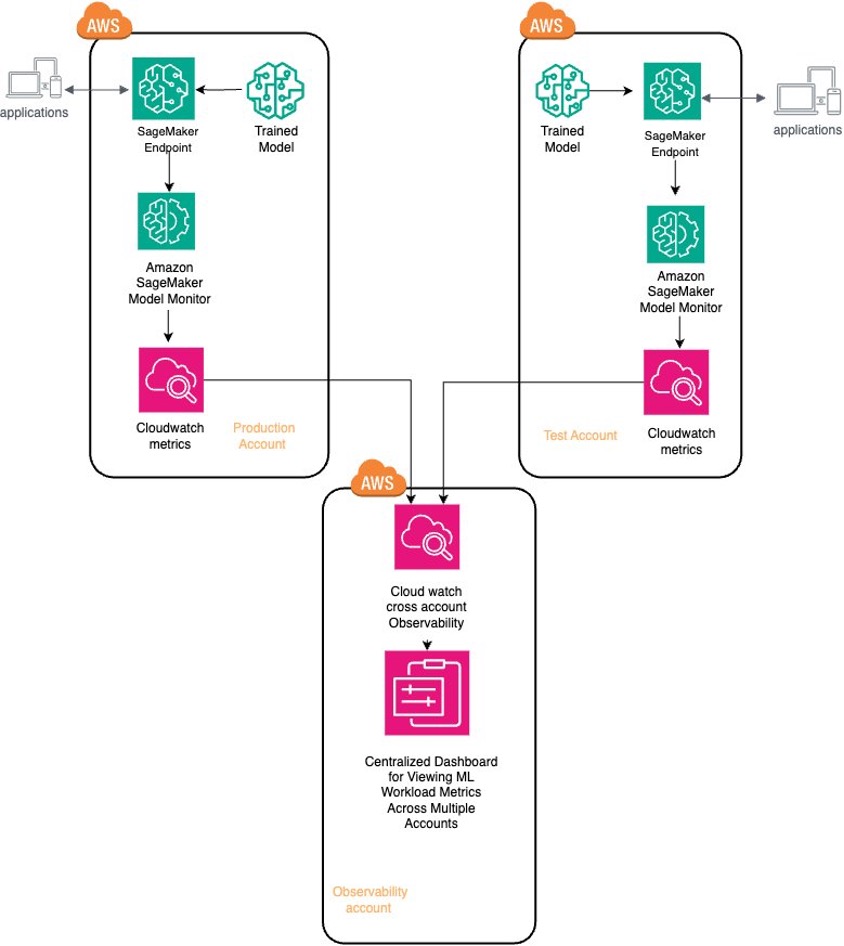
Originally appeared here:
Governing the ML lifecycle at scale: Centralized observability with Amazon SageMaker and Amazon CloudWatch


If the position of the charging port on the Magic Mouse isn’t the questionable design choice it’s been called, the New Mac mini power button might be. As pointedly not shown by Apple in its launch video or new ad — the Mac mini power button is underneath the device.
As can be seen on the online store’s page for the new M4 Mac mini, the button is not on the very base of the model. It is, though, underneath it, raised off the ground only by the cooling vent.
Go Here to Read this Fast! Apple stuck the Mac mini power button on the bottom
Originally appeared here:
Apple stuck the Mac mini power button on the bottom

