On Oct. 31, 2008, the Bitcoin white paper came out — now 16 years ago to the day.
Originally appeared here:
Bitcoin’s White Paper Turns 16: How BTC Went From An Abstract Idea To A Household Name On Wall Street

On Oct. 31, 2008, the Bitcoin white paper came out — now 16 years ago to the day.
Originally appeared here:
Bitcoin’s White Paper Turns 16: How BTC Went From An Abstract Idea To A Household Name On Wall Street


One of the world’s leading cryptocurrency exchanges and Web3 companies, Bitget, has been named one of the top 12 finalists in the Digital Currency Exchange (DCE) of the Year category at Australia’s 2024 Blockies Awards. According to an official announcement today, Bitget is among the 12 finalists announced for the category among more than 400 […]
Originally appeared here:
Bitget Emerges as Finalist for Digital Currency Exchange of the Year Category at Australia’s 2024 Blockies Awards


In the crypto world, price hikes are grabbing everyone’s attention. Cardano is up by 8% but struggles at the $0.40 resistance. Ethereum is under the microscope for possible centralization in its staking process, with concerns voiced by its co-founder. BlockDAG (BDAG) is turning heads with a dynamic new video and a presale that’s crossed $107.5 […]

OpenAI founder Sam Altman has made ambitious calculations, suggesting a potential investment scale of $7 trillion in GPUs for an AI future. This number, rejected by industry leaders like Nvidia’s founder Jensen Huang, implies a monumental acquisition of GPUs, requiring enormous energy, almost on a galactic scale. To put this in perspective, Nvidia’s current market worth is around $3 trillion, below half of Altman’s proposed investment. When compared to the GDPs of the United States (approximately $26.8 trillion) and China (around $17.8 trillion), this $7 trillion investment is still indeed staggering.
Despite this, the AI era is still in its infancy, and achieving such a scale might necessitate even more advanced computational structures. This brings us to a critical underlying question: how much energy will be needed to power computational units and data centers?
Let’s take a look at some simple and direct numbers from three perspectives,
1. Energy consumption per computational unit
2. Energy costs of training/operating modern models
3. Energy supply and demand
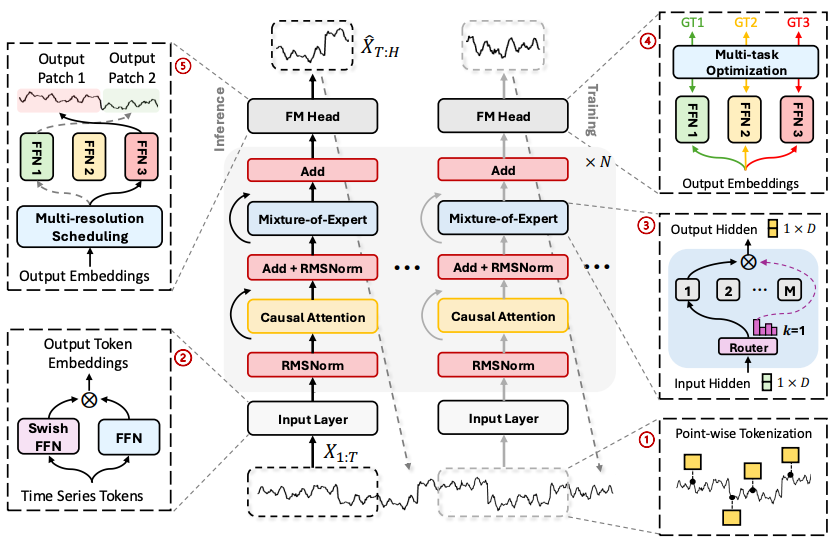
From a user perspective, some video game enthusiasts have built their own PCs equipped with high-performance GPUs like the NVIDIA GeForce RTX 4090. Interestingly, this GPU is also capable of handling small-scale deep-learning tasks. The RTX 4090 requires a power supply of 450 W, with a recommended total power supply of 850 W (in most cases you don’t need that and will not run under full load). If your task runs continuously for a week, that translates to 0.85 kW × 24 hours × 7 days = 142.8 kWh per week. In California, PG&E charges as high as 50 cents per kWh for residential customers, meaning you would spend around $70 per week on electricity. Additionally, you’ll need a CPU and other components to work alongside your GPU, which will further increase the electricity consumption. This means the overall electricity cost can be even higher.
Now, your AI business is going to accelerate. According to the manufacturer, an H100 Tensor Core GPU has a maximum thermal design power (TDP) of around 700 Watts, depending on the specific version. This is the energy required to cool the GPU under a full working load. A reliable power supply unit for this high-performance deep-learning tool is typically around 1600W. If you use the NVIDIA DGX platform for your deep-learning tasks, a single DGX H100 system, equipped with 8 H100 GPUs, consumes approximately 10.2 kW. For even greater performance, an NVIDIA DGX SuperPOD can include anywhere from 24 to 128 NVIDIA DGX nodes. With 64 nodes, the system could conservatively consume about 652.8 kW. While your startup might aspire to purchase this millions-dollar equipment, the costs for both the cluster and the necessary facilities would be substantial. In most cases, it makes more sense to rent GPU clusters from cloud computation providers. Focusing on energy costs, commercial and industrial users typically benefit from lower electricity rates. If your average cost is around 20 cents per kWh, operating 64 DGX nodes at 652.8 kW for 24 hours a day, 7 days a week would result in 109.7 MWh per week. This could cost you approximately $21,934 per week.
According to rough estimations, a typical family in California would spend around 150 kWh per week on electricity. Interestingly, this is roughly the same cost you’d incur if you were to run a model training task at home using a high-performance GPU like the RTX 4090.
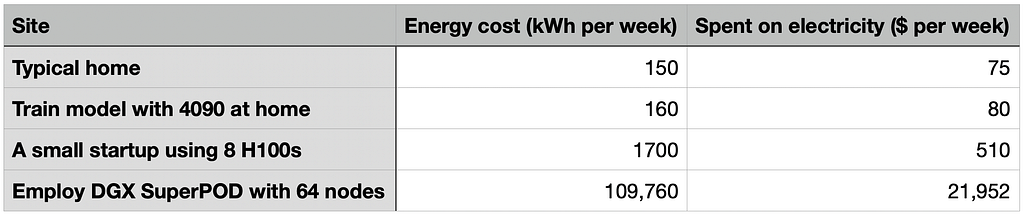
From this table, we may observe that operating a SuperPOD with 64 nodes could consume as much energy in a week as a small community.
Now, let’s dive into some numbers related to modern AI models. OpenAI has never disclosed the exact number of GPUs used to train ChatGPT, but a rough estimate suggests it could involve thousands of GPUs running continuously for several weeks to months, depending on the release date of each ChatGPT model. The energy consumption for such a task would easily be on the megawatt scale, leading to costs in the thousands scale of MWh.
Recently, Meta released LLaMA 3.1, described as their “most capable model to date.” According to Meta, this is their largest model yet, trained on over 16,000 H100 GPUs — the first LLaMA model trained at this scale.
Let’s break down the numbers: LLaMA 2 was released in July 2023, so it’s reasonable to assume that LLaMA 3 took at least a year to train. While it’s unlikely that all GPUs were running 24/7, we can estimate energy consumption with a 50% utilization rate:
1.6 kW × 16,000 GPUs × 24 hours/day × 365 days/year × 50% ≈ 112,128 MWh
At an estimated cost of $0.20 per kWh, this translates to around $22.4 million in energy costs. This figure only accounts for the GPUs, excluding additional energy consumption related to data storage, networking, and other infrastructure.
Training modern large language models (LLMs) requires power consumption on a megawatt scale and represents a million-dollar investment. This is why modern AI development often excludes smaller players.
Running AI models also incurs significant energy costs, as each inquiry and response requires computational power. Although the energy cost per interaction is small compared to training the model, the cumulative impact can be substantial, especially if your AI business achieves large-scale success with billions of users interacting with your advanced LLM daily. Many insightful articles discuss this issue, including comparisons of energy costs among companies operating ChatBots. The conclusion is that, since each query could cost from 0.002 to 0.004 kWh, currently, popular companies would spend hundreds to thousands of MWh per year. And this number is still increasing.

Imagine for a moment that one billion people use a ChatBot frequently, averaging around 100 queries per day. The energy cost for this usage can be estimated as follows:
0.002 kWh × 100 queries/day × 1e9 people × 365 days/year ≈ 7.3e7 MWh/year
This would require an 8000 MW power supply and could result in an energy cost of approximately $14.6 billion annually, assuming an electricity rate of $0.20 per kWh.

The largest power plant in the U.S. is the Grand Coulee Dam in Washington State, with a capacity of 6,809 MW. The largest solar farm in the U.S. is Solar Star in California, which has a capacity of 579 MW. In this context, no single power plant is capable of supplying all the electricity required for a large-scale AI service. This becomes evident when considering the annual electricity generation statistics provided by EIA (Energy Information Administration),

The 73 billion kWh calculated above would account for approximately 1.8% of the total electricity generated annually in the US. However, it’s reasonable to believe that this figure could be much higher. According to some media reports, when considering all energy consumption related to AI and data processing, the impact could be around 4% of the total U.S. electricity generation.
However, this is the current energy usage.
Today, Chatbots primarily generate text-based responses, but they are increasingly capable of producing two-dimensional images, “three-dimensional” videos, and other forms of media. The next generation of AI will extend far beyond simple Chatbots, which may provide high-resolution images for spherical screens (e.g. for Las Vegas Sphere), 3D modeling, and interactive robots capable of performing complex tasks and executing deep logistical. As a result, the energy demands for both model training and deployment are expected to increase dramatically, far exceeding current levels. Whether our existing power infrastructure can support such advancements remains an open question.
On the sustainability front, the carbon emissions from industries with high energy demands are significant. One approach to mitigating this impact involves using renewable energy sources to power energy-intensive facilities, such as data centers and computational hubs. A notable example is the collaboration between Fervo Energy and Google, where geothermal power is being used to supply energy to a data center. However, the scale of these initiatives remains relatively small compared to the overall energy needs anticipated in the upcoming AI era. There is still much work to be done to address the challenges of sustainability in this context.

Please correct any numbers if you find them unreasonable.
Massive Energy for Massive GPU Empowering AI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Massive Energy for Massive GPU Empowering AI
Go Here to Read this Fast! Massive Energy for Massive GPU Empowering AI


Exploring the limits of artificial intelligence: why mastering patterns may not equal genuine reasoning
Originally appeared here:
The Savant Syndrome: Is Pattern Recognition Equivalent to Intelligence?
Go Here to Read this Fast! The Savant Syndrome: Is Pattern Recognition Equivalent to Intelligence?


When I read the recent article in VentureBeat about how Glean just secured over $260 million in its latest funding round, I had two immediate gut feelings. First, it was satisfying to see this very public example of graph RAG living up to its potential as a powerful, valuable technology that connects people with knowledge more efficiently than ever. Second, it felt surprising but validating to read:
One of the world’s largest ride-sharing companies experienced its benefits firsthand. After dedicating an entire team of engineers to develop a similar in-house solution, they ultimately decided to transition to Glean’s platform.
“Within a month, they were seeing twice the usage on the Glean platform because the results were there,” says Matt Kixmoeller, CMO at Glean.
Although I was surprised to read about the failure in a news article, struggling to bring graph RAG into production is what I would expect, based on my experience as well as the experiences of coworkers and customers. I’m not saying that I expect large tech companies to fail at building their own graph RAG system. I merely expect that most folks will struggle to build out and productionize graph RAG — even if they already have a very successful proof-of-concept.
I wrote a high-level reaction to the VentureBeat article in The New Stack, and in this article, I’d like to dive deeper into why graph RAG can be so hard to get right. First, I’ll note how easy it has become, using the latest tools, to get started with graph RAG. Then, I’ll dig into some of the specific challenges of graph RAG that can make it so difficult to bring from R&D into production. Finally, I’ll share some tips on how to maximize your chances of success with graph RAG.
So if a big ride-sharing company couldn’t build their own platform effectively, then why would I say that it’s easy to implement graph RAG yourself?

Well, first of all, technologies supporting RAG and graph RAG have come a long way in the past year. Twelve months ago, most enterprises hadn’t even heard of retrieval-augmented generation. Now, not only is RAG support a key feature of the best AI-building tools like LangChain, but just about every major player in the AI space has a RAG tutorial, and there is even a Coursera course. There is no shortage of quick entry points for trying RAG.
Microsoft may not have been the first to do graph RAG, but they gave the concept a big push with a research blog post earlier this year, and they continue to work on related tech.
Here on Medium, there is also a nice conceptual introduction, with some technical details, from a gen AI engineer at Google. And, in Towards Data Science, there is a recent and very thorough how-to article on building a graph RAG system and testing on a dataset of scientific publications.
An established name in traditional graph databases and analytics, Neo4j, added vector capabilities to their flagship graph DB product in response to the recent gen AI revolution, and they have an excellent platform of tools for projects that require sophisticated graph analytics and deep graph algorithms in addition to standard graph RAG capabilities. They also have a Getting Started With Graph RAG guide.
On the other hand, you don’t even need a graph DB to do graph RAG. Many folks who are new to graph RAG believe that they need to deploy a specialized graph DB, but this is not necessary, and in fact may simply complicate your tech stack.
My employer, DataStax, also has a Guide to Graph RAG.
And, of course, the two most popular gen AI application composition frameworks, LangChain and LlamaIndex, each have their own graph RAG introductions. And there’s a DataCamp article that uses both.
With all of the tools and tutorials available, getting started with graph RAG is the easy part…
This is a very old story in data science: a new software methodology, technology, or tool solves some imposing problem in a research context, but industry struggles to build it into products that deliver value on a daily basis. It’s not just an issue of effort and proficiency in software development — even the biggest, best, and brightest teams might not be able to overcome the uncertainty, unpredictability, and uncontrollability of real-world data involved in solving real-world problems.

Uncertainty is an inherent part of building and using data-centric systems, which almost always have some elements of stochasticity, probability, or unbounded inputs. And, uncertainty can be even greater when inputs and outputs are unstructured, which is the case with natural language inputs and outputs of LLMs and other GenAI applications.
Folks who want to try graph RAG typically already have an existing RAG application that performs well for simple use cases, but fails on some of the more complex use cases and prompts requiring multiple pieces of information across a knowledge base, potentially in different documents, contexts, formats, or even data stores. When all of the information needed to answer a question is in the knowledge base, but the RAG system isn’t finding it, it seems like a failure. And from a user experience (UX) perspective, it is — the correct answer wasn’t given.
But that doesn’t necessarily mean there is a “problem” with the RAG system, which might be performing exactly as it was designed. If there isn’t a problem or a bug, but we still aren’t getting the responses we want, that must mean that we are expecting the RAG system to have a capability it simply doesn’t have.
Before we look at why specifically graph RAG is hard to bring into production, let’s take a look at the problem we’re trying to solve.
Because plain RAG systems (without knowledge graphs) retrieve documents based solely on vector search, only documents that are most semantically similar to the query can be retrieved. Documents that are not semantically similar at all — or not quite similar enough — are left out and are not generally made available to the LLM generating a response to the prompt at query time.
When the documents we need to answer a question in a prompt are not all semantically similar to the prompt, one or more of them is often missed by a RAG system. This can happen when answering the question requires a mix of generalized and specialized documents or terms, and when documents are detail-dense in the sense that some very important details for this specific prompt are buried in the middle of related details that aren’t as relevant to this prompt. See this article for an example of RAG missing documents because two related concepts (“Space Needle” and “Lower Queen Anne neighborhood” in this case) are not semantically similar, and see this article for an example of important details getting buried in detail-dense documents because vector embeddings are “lossy”.
When we see retrieval “failing” to find the right documents, it can be tempting to try to make vector search better or more tailored to our use case. But this would require fiddling with embeddings, and embeddings are complicated, messy, expensive to calculate, and even more expensive to fine-tune. Besides, that wouldn’t even be the best way to solve the problem.
For example, looking at the example linked above, would we really want to use an embedding algorithm that puts the text “Space Needle” and “Lower Queen Anne neighborhood” close together in semantic vector space? No, fine-tuning or finding an embedding algorithm that puts those two terms very close together in semantic space would likely have some unexpected and undesired side effects.
It is better not to try to force a semantic model to do a job that geographical or tourism information would be much better suited for. If I were a travel or tourism company who relied on knowing which neighborhood such landmarks are in, I would rather build a database that knows these things with certainty — a task that is much easier than making semantic vector search do the same task… without complete certainty.
So, the main issue here is that we have concepts and information that we know are related in some way, but not in semantic vector space. Some other (non-vector) source of information is telling us that there are connections among the wide variety of concepts we are working with. The task of building a graph RAG application is to effectively capture these connections between concepts into a knowledge graph, and to use the graph connections to retrieve more relevant documents for responding to a prompt.

To summarize the issue that we’re trying to tackle with graph RAG: there exists semi-structured, non-semantic information connecting many of the concepts that appear in my unstructured documents — and I would like to use this connection information to complement semantic vector search in order to retrieve documents that are best suited to answer prompts and questions within my use cases. We simply want to make retrieval better, and we want to use some external information or external logic to accomplish that, instead of relying solely on semantic vector search to connect prompts with documents,
Considering the above motivation — to use “external” information to make document connections that semantic search misses — there are some guiding principles that we can keep in mind while building and testing a graph RAG application:
Perhaps in a future article, we will dig into the nuances and potential impacts of following these principles, but for now, I’ll just note that this list is intended to jointly increase explainability, prevent over-complexity, and maximize efficiency of both building and using a graph RAG system.
Following these principles along with other core principles from software engineering and data science can increase your chances of successfully building a useful and powerful graph RAG app, but there are certainly pitfalls along the way, which we outline in the next section.


Anyone who has spent a lot of time building software around data, complex algorithms, statistics, and human users probably understands that there is a lot of uncertainty in building a system like graph RAG. Unexpected things can happen during data prep and loading, while building a knowledge graph, while querying and traversing the graph, during results compilation and prompt construction, and at virtually any other point in the workflow.
Above, we discussed how it’s easy to implement graph RAG to get preliminary results, but it can be hard to get good results, much less production-quality results. Next, we look at a few potential issues that you might encounter when building and testing a graph RAG application.

If the performance of your graph RAG system is about the same as with plain RAG, there can be any number of causes. Generally speaking, this seems to imply that the graph is not adding value to the system, but this could be caused by a low-quality knowledge graph, under-utilization of the graph, sub-optimal parameter settings, or many others. Or, there may not be a problem at all; vector search may be doing an excellent job of finding the right documents, and a graph simply isn’t needed.
What to look at:
If you’re seeing hallucinations with graph RAG that you didn’t see with plain RAG, I would suspect a bug or a bad parameter setting somewhere. If you are seeing a similar level of hallucinations, this sounds like a general problem beyond the graph aspects.
What to look at:
When your knowledge graph is “too big” or too dense, two main types of problems can occur. First, there could be issues with scaling, which I discuss below. Second, graph traversal could result in “too many” documents, which must then be re-ranked and filtered. If the re-ranking and filtering strategy doesn’t play well with the retrieval and graph traversal elements, you could end up filtering out important documents immediately after your graph just discovered them.
What to look at:
Per above, if the graph is “too big”, it might be filled with low-quality connections. And if the graph is “too small”, I would hope that the connections there are meaningful, which is good, but missing connections come in two main types. The first is caused by a bug in the graph construction process. The second is caused by graph construction that was not designed for it. Data in a different contexts or different formats may be processed differently by different graph-construction methods.
What to look at:
Do you feel like you can build a graph that is “too big” or one that is “too small”, but you can’t build something in the middle?
What to look at:
This is a classic Data Science problem: build really cool and cutting-edge methods, only to see development teams refuse or struggle to bring the code from your notebooks into the production stack. Sticking to the most popular, best supported, and largely open-source tools can make it easier to get to production, especially if your organization is already using those tools elsewhere.
What to look at:
The article Scaling Knowledge Graphs by Eliminating Edges in The New Stack shows one way to make graph RAG very scalable. Like above, the most popular, best supported, and largely open-source tools are usually the best path to painless scaling, but it’s not always easy.
What to look at:
The key to creating a successful graph RAG system lies in constructing a knowledge graph and traversal logic that complement semantic vector retrieval, not replacing or competing with it. The graph design should aim to connect the right nodes, knowledge, entities, and documents at the right time, enabling the assembly of the appropriate documents to produce the most helpful and actionable query response.

With respect to Glean, it should be noted that an internal document dataset is a perfect use case for graph RAG. A knowledge graph can connect people, projects, products, customers, meetings, locations, etc — and all of these are somewhat limited in number by the size of the organization and the work it does. Building and managing a graph of thousands of employees is much more tractable than, for example, trying to do the same with all of the people mentioned on Wikipedia or in a large database of financial or legal documents. So, possibly the first great decision that Glean made was to find a great use case for graph RAG to tackle.
One often understated aspect of graph RAG systems is the quality and reliability of the input data and the pipelines that get it there. This has more to do with data engineering and traditional software development than AI. In previous tech paradigms, connecting different data systems was challenging due to incompatible data types and access methods. Now, AI and LLMs enable the integration of disparate sources of unstructured data, allowing for the consolidation of data from various origins into a single RAG system. This integration capability enables LLMs to process and make sense of unstructured data from various sources, such as internal web pages, wikis, code repositories, databases, Google Docs, and chat logs. Simply connecting all of this information together and making it accessible from a single interface can be a big win.
Construction of graph RAG systems for any use case involves leveraging foundational components such as data stores for vectors and graphs, embeddings, and LLMs, enhanced by open-source orchestration tools like LangChain and LlamaIndex. These tools facilitate the development of robust, scalable, and efficient systems, promising a future where companies achieve substantial success by optimizing knowledge work through automation and streamlining.
The public success of knowledge graphs and graph RAG systems, particularly by companies like Glean, showcases how effective these technologies are for internal use cases, creating value by making the organization more efficient. However, the broader application potential for external, enterprise and consumer-facing products remains largely untapped, presenting many opportunities for other companies to explore.
It is perhaps notable that we have been in what is called the “Information Age” for at least 30 years, and it is only in the past year or two that we have really started to put together the building blocks for connecting all of this information across sources, across ideas, across documents, and across concepts, so that our software systems can make the same types of reasoning, logic, and judgment that we as humans use as a daily part of our knowledge work. Some people are calling this the “Intelligence Age”.
While initially focusing on simple, straightforward decisions, AI’s trajectory is set towards managing more complex scenarios, dramatically improving efficiency in both time and cost. This exciting evolution positions many AI applications — including graph RAG — as pivotal in transforming how knowledge is interconnected and utilized in a wide variety of contexts.
To get started with graph RAG now, or to learn more, take a look at the DataStax guide to graph RAG.
by Brian Godsey, Ph.D. (LinkedIn) — mathematician, data scientist and engineer // AI and ML products at DataStax // Wrote the book Think Like a Data Scientist


The Quest for Production-Quality Graph RAG: Easy to Start, Hard to Finish was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
The Quest for Production-Quality Graph RAG: Easy to Start, Hard to Finish
Go Here to Read this Fast! The Quest for Production-Quality Graph RAG: Easy to Start, Hard to Finish


Originally appeared here:
Create a generative AI–powered custom Google Chat application using Amazon Bedrock

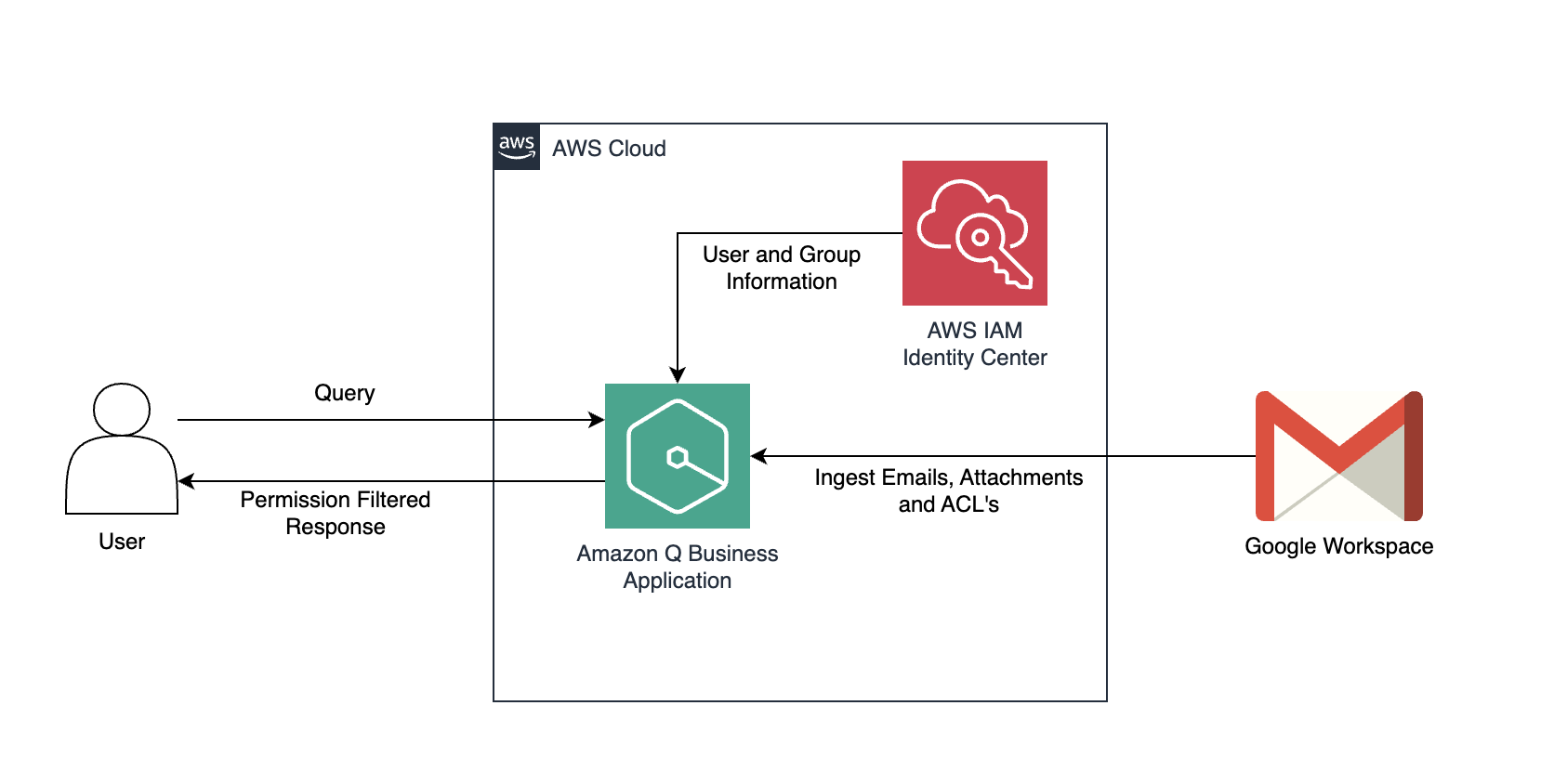
Originally appeared here:
Discover insights from Gmail using the Gmail connector for Amazon Q Business