Open-Source Data Observability with Elementary — From Zero to Hero (Part 1)
A step-by-step hands-on guide I wish I had when I was a beginner
Data observability and its importance have often been discussed and written about as a crucial aspect of modern data and analytics engineering. Many tools are available on the market with various features and prices. In this 2 part article, we will focus on the open-source version of Elementary, one of these data observability platforms, tailored for and designed to work seamlessly with dbt. We will start by setting up from zero and aiming to understand how it works and what is possible in different data scenarios by the end of part 2. Before we start, I also would like to disclose that I have no affiliation with Elementary, and all opinions expressed are my own.
In part 1, we will set up the Elementary and check how to read the Elementary’s daily report. If you are comfortable with this part already and interested in checking different types of data tests and which one suits bests for which scenario, you can directly jump into part 2 here:
I have been using Elementary for quite some time and my experiences as a data engineer are positive, as to how my team conceives the results. Our team uses Elementary for automated daily monitoring with a self-hosted elementary dashboard. Elementary also has a very convenient cloud platform as a paid product, but the open-source version is far more than enough for us. If you want to explore the differences and what features are missing in open source, elementary compares both products here. Let us start by setting up the open-source version first.
- How to Install Elementary
Installing Elementary is as easy as installing any other package in your dbt project. Simply add the following to your packages.yml file. If you don’t have one yet, you can create a packages.yml file at the same level as your dbt_project.yml file. A package is essentially another dbt project, consisting of additional SQL and Jinja code that can be incorporated into your dbt project.
packages:
- package: elementary-data/elementary
version: 0.15.2
## you can also have different minor versions as:
## version: [">=0.14.0", "<0.15.0"]
## Docs: https://docs.elementary-data.com
We want Elementary to have its own schema for writing outputs. In the dbt_project.yml file, we define the schema name for Elementary under models. If you are using dbt Core, by default all dbt models are built in the schema specified in your profile’s target. Depending on how you define your custom schema, the schema will be named either elementary or <target_schema>_elementary.
models:
## see docs: https://docs.elementary-data.com/
elementary:
## elementary models will be created in the schema 'your_schema_elementary'
+schema: "elementary"
## If you dont want to run Elementary in your Dev Environment Uncomment following:
# enabled: "{{ target.name in ['prod','analytics'] }}"
From dbt 1.8 onwards, dbt depreciated the ability of installed packages to override build-in materializations without an explicit opt-in from the user. Some elementary features crash with this change, hence a flag needs to be added under the flags section at the same level as models in the dbt_project.yml file.
flags:
require_explicit_package_overrides_for_builtin_materializations: True
Finally, for Elementary to function properly, it needs to connect to the same data warehouses that your dbt project uses. If you have multiple development environments, Elementary ensures consistency between how dbt connects to these warehouses and how Elementary connects to them. This is why Elementary requires a specified configuration in your profiles.yml file.
elementary:
outputs:
dev:
type: bigquery
method: oauth
project: dev
dataset: elementary
location: EU
priority: interactive
retries: 0
threads: 4
pp:
type: bigquery
method: oauth # / service-account
# keyfile : [full path to your keyfile]
project: prod # project_id
dataset: elementary # elementary dataset, usually [dataset name]_elementary
location: EU # [dataset location]
priority: interactive
retries: 0
threads: 4
The following code would also generate the profile for you once run within the dbt project :
dbt run-operation elementary.generate_elementary_cli_profile
Finally, install Elementary CLI by running:
pip install elementary-data
# you should also run following for your platform too, Postgres does not requiere this step
pip install 'elementary-data[bigquery]'
- How does elementary work?
Now that you have Elementary hopefully working on your dbt project, it is also useful to understand how Elementary operates. Essentially, Elementary operates by utilizing the dbt artifacts generated during dbt runs. These artifacts, such as manifest.json, run_results.json, and other logs, are used to gather detailed model metadata, track model execution, and evaluate test results. Elementary centralizes this data to offer a comprehensive view of your pipeline’s performance. It then produces a report based on the analysis and can generate alerts.
- How to use elementary
In most simple terms, if you would like to create a general Elementary report the following code would generate a report as an HTML file:
edr report
on your CLI, this would access your data warehouse by using connection profiles that we have provided in the previous steps. If the elementary profile does not have a default target name defined, it will throw you an error, to avoid the error you can also give–profile-target <target_name> as variable while running on your terminal.
Once the Elementary run finishes, it automatically opens up the elementary report as an HTML file.
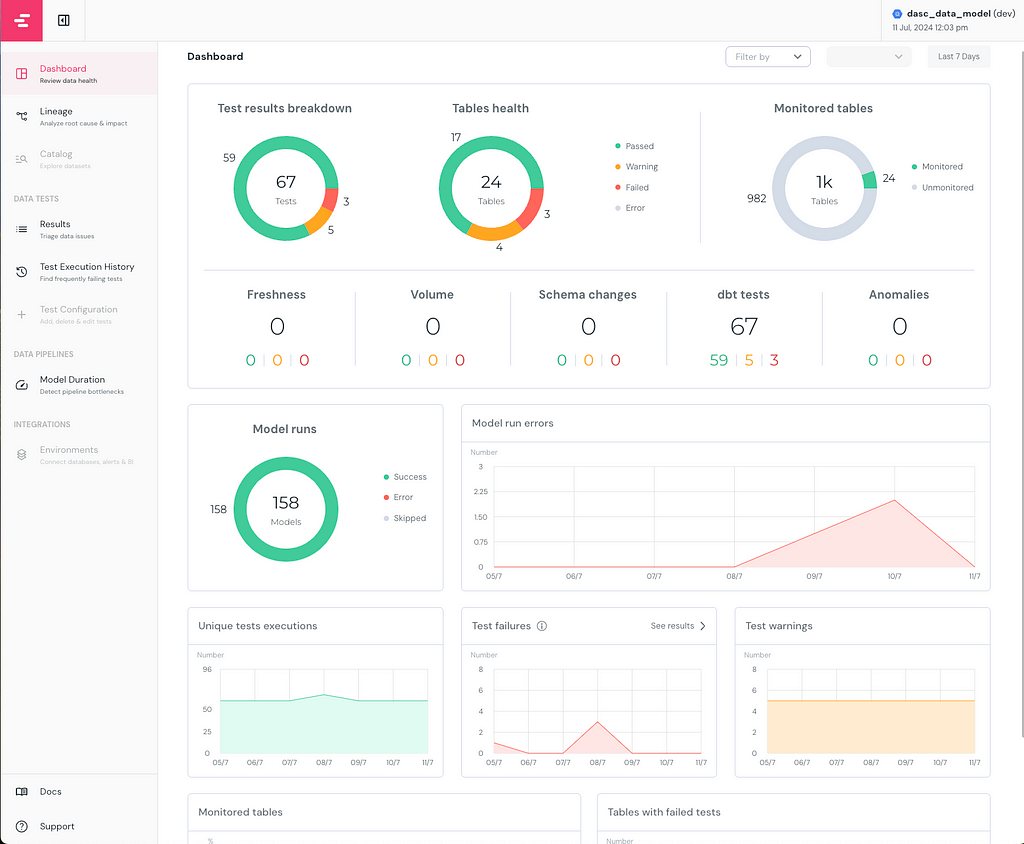
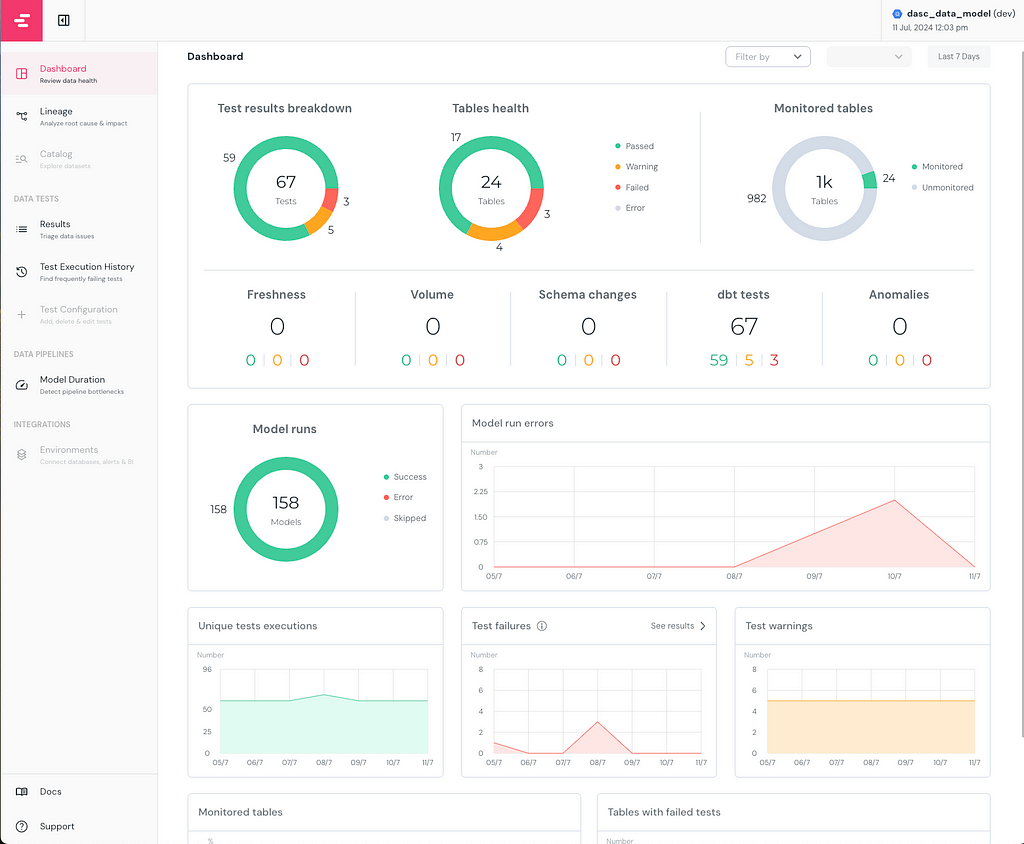
On the left lane of the dashboard, you can see the different pages, the Dashboard page gives a comprehensive overview of the dbt project’s performance and status. Catalog and Test Configuration pages are only available in Elementary Cloud but these configurations can also be implemented manually in the OSS version, explained more in detail in part 2.
- How to read this report?
In this exemplary report, I intentionally created warnings and errors beforehand for this article. 67 Tests were running in total, where 3 of them failed and 5 of them gave a warning. I monitored 24 tables, and all tests configured and checked were here dbt tests, if freshness or volume tests of Elementary had been configured, they would show up in the second row of the first visual.
As you can see in the Model runs visual, I have run 158 models without any errors or skipping. In the previous days, there were an increasing number of errors while running the models. I can easily see the errors that started occurring on 09/7 and troubleshoot them accordingly.
You can host this dashboard on your production and send it to your communication/alerting channel. Below is an example from an Argo workflow, but you can also check here for different methods that fit your setup/where you want to host it in your production.
- name: generate-elementary-report
container:
image: "{{inputs.parameters.elementary_image}}" ##pre-defined elemantary image in configmap.yaml
command: ["edr"] ##run command for elemantary report
args: ["report", "--profile-target={{inputs.parameters.target}}"]
workingDir: workdir ##working directory
inputs:
parameters:
- name: target
- name: elementary_image
- name: bucket
artifacts:
- name: source
path: workdir ##working directory
outputs:
artifacts:
- name: state
path: /workdir/edr_target
gcs:
bucket: "{{inputs.parameters.bucket}}" ##here is the bucket that you would like to host your dashboard output
key: path_to_key
archive:
none: {}
By using the template above in our Argo workflows, we would create the Elementary HTML report and save it in the defined bucket. We can later take this report from your bucket and send it with your alerts.
Now we know how we set up our report and hopefully know the basics of Elementary, next, we will check different types of tests and which test would suit the best in which scenario. Just jump into Part 2.
If that was enough for you already, thanks a lot for reading!
References in This Article
- Elementary Data Documentation. (n.d.). Elementary Data Documentation. Retrieved September 5, 2024, from https://docs.elementary-data.com
- dbt Labs. (n.d.). dbt Documentation. Retrieved September 5, 2024, from https://docs.getdbt.com
- Elementary Data. (n.d.). GitHub Repository. Retrieved September 5, 2024, from https://github.com/elementary-data
- dbt Labs. (2024). Upgrading to dbt v1.8. Retrieved September 5, 2024, from https://docs.getdbt.com/docs/dbt-versions/core-upgrade/upgrading-to-v1.8#deprecated-functionality
- Elementary Data. (n.d.). Elementary in Production. Retrieved September 5, 2024, from https://docs.elementary-data.com/oss/deployment-and-configuration/elementary-in-production#ways-to-run-elementary-in-production
Open-Source Data Observability with Elementary — From Zero to Hero (Part 1) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Open-Source Data Observability with Elementary — From Zero to Hero (Part 1)