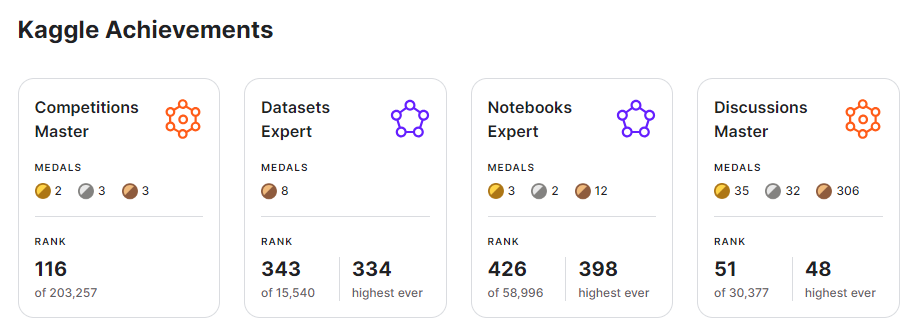
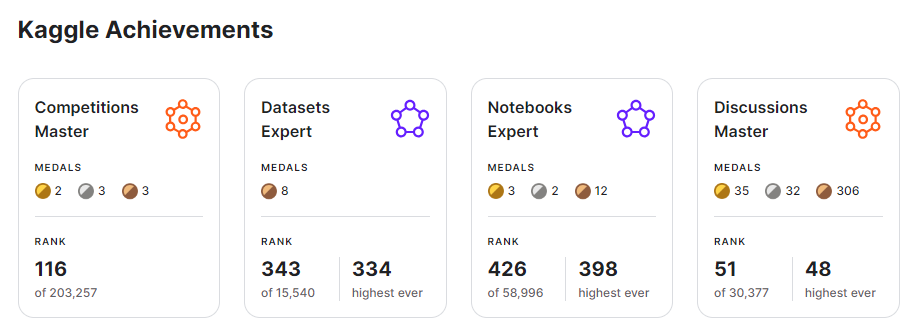
Competitions are more valuable than other components
Kaggle is a platform for users to gain hands-on experience on practical data science and machine learning. It has 4 different progression components, namely Competitions, Datasets, Notebooks and Discussions. No prior experience in data science is necessary to get yourself started in using this platform and learn
My background: I did my first project on Kaggle as part of a Machine Learning course in my Bachelor’s curriculum (Math + Comp Sci) in early 2023. Since then I have been hooked to this platform as a favorite pastime. I have taken part in 20 competitions to date. I had no work/internship experience as a data scientist prior to starting Kaggle.
In one year, I have made (I believe) significant progress in my Kaggle journey, including winning 2 gold competition medals, one of which I won 1st place and rising to the top 116 in the Competitions category, while barely missing a day of activity.
Now, let’s dive into 3 key learnings from my Kaggle journey to date.
- Your team cannot solely rely on public notebooks to succeed in Competitions
A standard Kaggle competition only awards Gold medals to the top 10 + floor(NumTeams / 500) teams! For example, in a competition with 2500 teams, only 15 teams win gold. This is mandatory for one to progress to the Master tier in competitions, and you need five (including one solo) to progress to the Grandmaster tier.
It is very unlikely that your team could just briefly modify public work (such as ensembling public notebooks) and earn a spot in the gold zone. Your team will be competing against top-notch data scientists and grandmasters who have lots of creative ideas to approach the problem.
Briefly modifying public work is something even beginners to ML can do and it is unlikely your team’s solution stands out using this. Most likely, a small enhancement of a public notebook gets a bronze medal, or if lucky, a silver medal.
In the 2 competitions which my team won gold:
- 1/2048 (Champion) PII Detection: We used a wide variety of Deberta architectures and postprocessing strategies, most of which are not shared in the public forums. No public models were used in our final ensemble
- 14/4436 Optiver — Trading At The Close: We used online training to make sure the model is fitted with the latest data before making the prediction. It was not easy to write an online training pipeline that worked on the private LB, and such an idea was not shared in the public forums, as far as I know. We did not use the popular public training approach as we felt it was overfitting to the train data, despite its great public LB score
In contrast, here is a competition in which my team won bronze:
- 185/2664 LLM Science Exam: We briefly modified a public training pipeline and a public inference pipeline, such as changing the embedding model, hyperparameters and ensembling. There was no creative ideas in our final solution
Summary: In my opinion, it is better to spend more time analyzing the baseline, and research to think of enhancements. It may be a good idea to start with a small model (deberta-v3-xsmall for example) to evaluate ideas quickly. Aim to establish a robust cross-validation strategy from the very beginning.
2. You learn much more from the Competitions category compared to Datasets/Notebooks/Discussions
Some of the real-world skills I learnt
- I was the team leader for most of the competitions I participated in, including both of them which my team won the gold medal. It has drastically improved my communication and leadership skills.
- Collaborating with other data scientists/engineers from different countries and timezones, and learning good practices from them
- Using Wandb to track and log experiments
- Customizing architectures of transformer models
- Generating use-case specific synthetic datasets using LLMs
- How to model a real-world use case in a data science perspective
- Writing clean code that is easily understandable
- How to utilize multi-GPU training
- Better time management
- Evaluating and mitigating model mistakes
In contrast, it is much easier to progress in datasets/notebooks/discussions without learning much about data science. In discussions, a user can earn gold discussion medals by posting his/her accomplishments on the Kaggle forum. I doubt I would learn most of the skills above without doing competitions. In my opinion, progress on datasets/notebooks/discussions does not necessarily tell that one is passionate about data science.
3. Playground Competitions is a great way to start for beginners
The playground series simulate the featured competitions, except that it is more beginner-friendly and do not award medals/prizes. In playgrounds, you make predictions on a tabular dataset, which allows you to learn the basics of coding an ML pipeline. Plenty of notebooks are shared in playgrounds, both tabular and NN (neural network) approaches, so if you are stuck, those public notebooks are a good reference.
Each playground series competition is about 1 month long.
Based on my experience, the playground competitions taught me:
- How to build a robust cross-validation strategy and not overfit the public LB
- How to select submissions for evaluation
- How to perform feature engineering and feature selection
- How to style a Jupyter Notebook
- (More on the data engineering side of things) How to use Polars. This is a much faster dataframe library than Pandas and is better suited for big data use cases
In conclusion, I feel the most rewarding part from doing Kaggle is the hands-on experience in competitions and the opportunity to collaborate with data professionals from around the globe. I get to solve a wide variety of problems ranging from tabular to more advanced NLP tasks. Looking forward to more as I continue to improve myself in the field of data science!
One Year of Consistent Kaggling: What Did It Teach Me? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
One Year of Consistent Kaggling: What Did It Teach Me?
Go Here to Read this Fast! One Year of Consistent Kaggling: What Did It Teach Me?