

How to improve accuracy, speed, and token usage of AI agents
Introduction
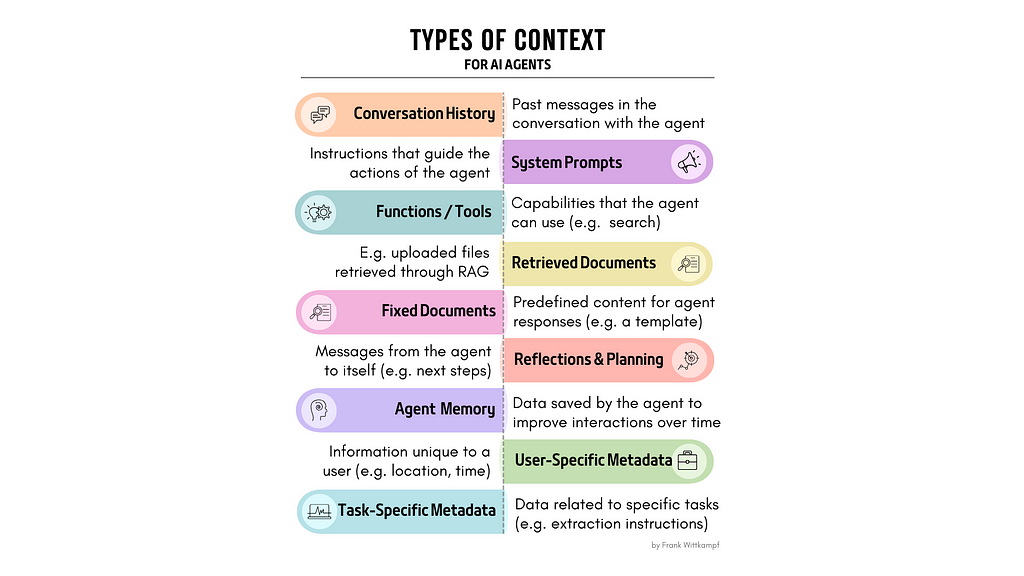
The behavior of an AI agent is defined by two things: (1) the model it runs on and (2) the context that you provide to the model. How you provide this context determines the quality of the output of the agent. You can even say that the behavior that distinguishes two AI agents running on the same model is fully defined by their context. So, what do we mean with context for an agent? See the Types of Context (image) below for examples.
This article delves into more advanced methods to enhance AI agent efficiency and accuracy by selectively tailoring context according to the needs of an agent. First I will describe 5 tactics, and then some additional implementation tips. The learnings in the article come from extensive experience in working with multi-agent teams in a production environment, but are just as applicable to single agent systems.
Understanding Contextual Needs
Most online examples and tutorials simplify their approach to context (e.g. applying a fixed cutoff length). Real AI applications need a more sophisticated approach.
Different agents have different contextual needs depending on the task at hand. Some agents may only require just the prior message, while other agents might need extensive historical data to respond accurately. These differences suggest that a tailored approach to context management for each agent is needed.
Consider the following example of an ongoing conversation between a user and 2 agents (a SW developer and a SW reviewer):
1 User: “Please improve the sorting function I wrote from the uploaded file”
2 System_prompt_for_coder: “You are a SW developer, you help the user to
develop …”
3 Coding_agent: “read_file_function”
4 Function_response: “coding snippet: ```some returned code```”
5 System_prompt_for_coder: “You are a SW developer, you help the user to
develop …”
6 Coding_agent: “I’ve improved your code by adding … and … to your code,
here is the new function …”
7 System_prompt_for_reviewer: “you are a SW code reviewer, you …”
8 Code_reviewer_agent: “After reviewing the improved code, there
are a few more things that I would add to the code …"
9 System_prompt_for_coder: “you are a SW developer, you help the user to
develop …”
10 Coding_agent: “ … ”
The context, as defined in this example is obviously repetitive and inefficient. Many lines are repeated (e.g. the system prompts), and each agent is getting more context than it needs. Let’s review a few ways to improve the context handling.
Tactic 1: Message Labeling
Message labeling is a critical tool for managing and optimizing the interaction between AI agents and their tasks. By assigning metadata to each message in the conversation, we can smartly select the information that is most relevant to the agent’s task at hand. This tactic involves several key strategies:
Relevance Labeling: Each message should be tagged with labels that reflect its relevance to ongoing and future interactions. This process involves analyzing the content of the message and determining its potential utility for the agent’s decision-making processes. For example, messages that contain questions, decisions or insights should be marked as highly relevant.
Permanence Labeling: It is vital to categorize messages based on their longevity and usefulness over time. Some messages, such as those containing foundational decisions or milestone communications, hold long-term value and should be retained across sessions. In contrast, system messages might only be needed once in a specific moment. These should be excluded from the agent’s memory once their immediate relevance has passed.
Source and Association Labeling: This involves identifying the origin of each message, whether it be from a specific agent, a user, function, or other process. This labeling helps in constructing a structured and easily navigable history that allows agents to efficiently retrieve and reference information based on source or task relevance.
Applying smart labels to the metadata of a message allows you to use smart selection. Keep reading for some examples.
Tactic 2: Agent-specific context requirements
Different agents have different requirements. Some agents can operate on very little information, while others need a lot of context to operate correctly. This tactic builds on the labeling we just discussed.
Critical Context Identification: It is crucial to identify which messages are critical for each specific agent and focus on these to streamline processing and enhance response accuracy. Let’s look at line 8 in the context above. The code reviewer only needs a limited amount of context to be able to accurately do its work. We can even say with some certainty that it will produce a worse answer if we give it more than the necessary context.
So what context does it need? Take a quick look, and you’ll infer that the code reviewer only needs its own system prompt, and it needs the last agent message before it, containing the latest iteration of the code (line 6).
Therefore, each agent should be configured such that it selects only the history that it needs. The code reviewer only looks at the last 2 messages, while the code writer needs a longer history.
Tactic 3: Optimization of System Prompts
Placement: When you do a quick search on agents and system prompts, it’s clear that placement of a system prompt for an agent matters. Should it be the first message in the chain, the last message? Opinions and results vary, depending on the use case. For example, which gives a better result?
1) user: "I visited dr. Fauci on Thursday, and got diagnosed with …"
2) system: "Extract all medically relevant info from the user prompt"
Or
1) system: "Extract all medically relevant info from the user prompt"
2) user: "I visited dr. Fauci on Thursday, and got diagnosed with …"
If you test this with a larger and more complex history, you’ll find that different placement of the same instruction produces different results. What is clear is that system prompts should be intentionally placed in a specific position, and that this depends on the agent and use case.
Note: in my experience it depends on the LLM to know if the system prompt should be the last message in the chain. Often putting it as the last message is a good choice (with definite exceptions, e.g. information extraction).
Permanence: Secondly, in addition to placement of system prompts, in most use cases you should ensure that a system prompt is labeled as “fleeting”. What I mean with a fleeting message, is that it does not remain in the chat history after it has been used.
For example, agent1 might get a prompt that it should step back and reflect on the problem. One turn later, agent1 is asked to use its reflection to find a solution to the problem. In that second turn, the initial prompt (to reflect) will only confuse the agent and result in a worse answer. It would have been better if that initial system prompt was not permanent, and would not have been provided to the agent again. In the example below, this means that line #2 should be removed when you make your second LLM call to the agent.
#1 User:
"What is the meaning of the universe?"
#2 System:
"You're a philosopher; before you answer, step back and
reflect on what the user's question implies."
#3 Agent_philo:
"Reflecting on this question, one can consider the universe
through various philosophical lenses - existentialism views
it as a canvas for creating personal meaning, while cosmology
sees it as a playground for understanding physical laws. This
interplay between human perception and scientific exploration
is central to understanding our query."
#4 System:
"You're a philosopher, and you just reflected deeply on the
question posed by the user. Use that insightful reflection to
craft a comprehensive answer."
#5 Agent_philo:
"From an existentialist perspective, the meaning of the universe
is a personal journey, where each individual constructs their own
meaning through choices and life experiences. In contrast, from a
cosmological viewpoint, it is about exploring and understanding
the vast, intricate laws that govern the cosmos. These perspectives
help us grasp the multifaceted nature of our universe, blending our
existential quests with scientific inquiry."
This approach ensures that any old system prompt is removed from the chain, and that each prompt is positioned optimally. Now we have an uncluttered conversation history, allowing for more precise and predictable interactions.
Tactic 4: Reducing redundancy in your RAG
We could dedicate a dozen articles to optimizing your agent by improving how you do RAG, but will keep it contained to a few paragraphs here. The sheer volume of tokens that can come from using RAG is so large that we have to mention a few techniques on how to manage it. If you haven’t already, this is a topic you should spend considerable time researching.
Basic tutorials on RAG mostly assume that the documents that you or your user uploads are simple and straightforward. However, in practice most documents are complex and unpredictable. My experience is that a lot of documents have repetitive information. For example, the same information is often repeated in the intro, body, and conclusion of a PDF article. Or a medical file will have repetitive doctor updates with (almost) the same information. Or logs are repeated over and over. Also, especially in production environments, when dealing with retrieval across a large body of files, the content returned by a standard RAG process can be extremely repetitive.
Dealing with Duplicates: A first step to optimize your RAG context, is to identify and remove exact and near duplicates within the retrieved document snippets to prevent redundancy. Exact duplicates are easy to identify. Near duplicates can be detected by semantic similarity, by looking at diversity of vector embeddings (diverse snippets have vectors that have a larger distance from each other), and many other techniques. How you do this will be extremely dependent on your use case. Here are a few examples (by perplexity)
Diversity in Responses: Another way to ensure diversity of RAG responses by smartly grouping content from various files. A very simple, but effective approach is to not just take the top N documents by similarity, but to use a GROUP BY in your retrieval query. Again, if you employ this depends highly on your use case. Here’s an example (by perplexity)
Dynamic Retrieval: So, given that this article is about dynamic context, how do you introduce that philosophy into your RAG process? Most RAG processes retrieve the top N results, e.g. the top 10 most similar document snippets. However, this is not how a human would retrieve results. When you search for information, you go to something like google, and you search until you find the right answer. This could be in the 1st or 2nd search result, or this could be in the 20th. Of course, depending on your luck and stamina ;-). You can model your RAG the same way. We can allow the agent to do a more selective retrieval, only giving it the top few results, and have the agent decide if it wants more information.
Here’s a suggested approach. Don’t just define one similarity cutoff, define a high, medium and low cutoff point. For example, the results of your search could be 11 very similar, 5 medium, and 20 somewhat similar docs. If we say the agent gets 5 docs at a time, now you let the agent itself decide if it wants more or not. You tell the agent that it has seen 5 of the 11 very similar docs, and that there are 25 more beyond that. With some prompt engineering, your agent will quickly start acting much more rationally when looking for data.
Tactic 5: Advanced Strategies for Context Processing
I’ll touch upon a few strategies to take dynamic context even a step further.
Instant Metadata: As described in tactic 1, adding metadata to messages can help you to preselect the history that a specific agent needs. For most situations, a simple one word text label should be sufficient. Knowing that something comes from a given function, or a specific agent, or user allows you to add a simple label to the message, but if you deal with very large AI responses and have a need for more optimization, then there is a more advanced way to add metadata to your messages: with AI.
A few examples of this are:
- A simple way to label a history message, is to make a separate AI call (to a cheaper model), which generates a label for the message. However, now you’re making 2 AI calls each time, and you’re introducing additional complexity in your flow.
A more elegant way to generate a label is to have the original author of a message generate a label at the same time as it writes its response.
- Have the agent give you a response in JSON, where one element is its normal response, and the other element is a label of the content.
- Use multi-function calling, and provide the agent a function that it’s required to call, which defines the message label.
- In any function call that the agent makes, reserve a required parameter which contains a label.
In this way, you instantly generate a label for the function contents.
Another advanced strategy to optimize context dynamically is to pre-process your RAG..
Dual processing for RAG: To optimize your RAG flow, you might consider using a cheaper (and faster) LLM to condense your RAG results before they are provided into your standard LLM. The trick when using this approach, is to use a very simple and non-disruptive prompt that condenses or simplifies the original RAG results into a more digestible form.
For example, you might use a cheaper model to strip out specific information, to reduce duplication, or to only select parts of the document that are relevant to the task at hand. This does require that you know what the strengths and weaknesses of the cheaper model are. This approach can save you a lot of cost (and speed) when used in combination with a more powerful model.
Implementation
OK, so does all the above mean that each of my agents needs pages and pages of custom code to optimize its performance? How do I generalize these concepts and extend them?
Agent Architecture: The answer to these questions is that there are clean ways to set this up. It just requires some foresight and planning. Building a platform that can properly run a variety of agents requires that you have an Agent Architecture. If you start with a set of clear design principles, then it’s not very complicated to make use of dynamic context and have your agents be faster, cheaper, and better. All at the same time.
Dynamic Context Configuration is one of the elements of your Agent Architecture.
Dynamic Context Configuration: As discussed in this article, each agent has unique context needs. And managing these needs can come down to managing a lot of variation across all possible agent contexts (see the image at the top of the article). However, the good news is that these variations can easily be encoded into a few simple dimensions. Let me give you an example that brings together most of the concepts in this article.
Let’s imagine an agent who is a SW developer who first plans their actions, and then executes that plan. The context configuration for this agent might be:
- Retain the initial user question
- Retain the plan
- Forget all history except for the last code revision and the last message in the chain
- Use RAG (on uploaded code files) without RAG condensation
- Always set system prompt as last message
This configuration is saved in the context configuration of this agent. So now your definition of an AI agent is that it is more than a set of prompt instructions. Your agent also a has a specific context configuration.
You’ll see that across agents, these configurations can be very meaningful and different, and that they allow for a great abstraction of code that otherwise would be very custom.
Rounding up
Properly managing Dynamic context not only enhances the performance of your AI agents but also greatly improves accuracy, speed, and token usage… Your agents are now faster, better, and cheaper, all at the same time.
Your agent should not only be defined by its prompt instructions, it should also have its own context configuration. Using simple dimensions that encode a different configuration for each agent, will greatly enhance what you can achieve with your agents.
Dynamic Context is just one element of your Agent Architecture. Invite me to discuss if you want to learn more. Hit me up in the comments section with questions or other insights, and of course, give me a few clicks on the claps or follow me if you got something useful from this article.
Happy coding!
Next-Level Agents: Unlocking the Power of Dynamic Context was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Next-Level Agents: Unlocking the Power of Dynamic Context
Go Here to Read this Fast! Next-Level Agents: Unlocking the Power of Dynamic Context