

Navigating the Latest GenAI Announcements — July 2024
A guide to new models GPT-4o mini, Llama 3.1, Mistral NeMo 12B and other GenAI trends
Introduction
Since the launch of ChatGPT in November 2022, it feels like almost every week there’s a new model, novel prompting approach, innovative agent framework, or other exciting GenAI breakthrough. July 2024 is no different: this month alone we’ve seen the release of Mistral Codestral Mamba, Mistral NeMo 12B, GPT-4o mini, and Llama 3.1 amongst others. These models bring significant enhancements to areas like inference speed, reasoning ability, coding ability, and tool calling performance making them a compelling choice for business use.
In this article we’ll cover the highlights of recently released models and discuss some of the major trends in GenAI today, including increasing context window sizes and improving performance across languages and modalities.
Overview of July Release Models
Mistral Codestral Mamba
- Overview: Codestral Mamba 7B is designed for enhanced reasoning and coding capabilities using the Mamba architecture instead of the Transformer architecture used by most Language Models. This architecture enables in context retrieval for much longer sequences and has been tested for sequences up to 256K tokens. By comparison, most Transformer based models allow between 8-128K token context windows. The Mamba architecture also enables faster inference speeds than Transformer based models.
- Availability: Codestral Mamba is an open source model under the Apache 2.0 License.
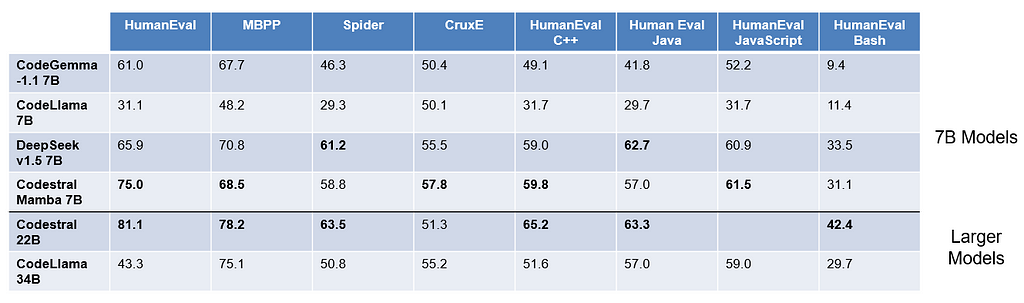
- Performance: Codestral Mamba 7B outperforms CodeGemma-1.1 7B, CodeLlama 7B, and DeepSeekv1.5 7B on the HumanEval, MBPP, CruxE, HumanEval C++, and Human Eval JavaScript benchmarks. It performs similarly to Codestral 22B across these benchmarks despite it’s smaller size.
Mistral NeMo 12B
- Overview: Mistral NeMo 12B was produced by Mistral and Nvidia to offer a competitive language model in the 12B parameter range with a far larger context window than most models of this size. Nemo 12B has a 128K token context window while similarly sized models Gemma 2 9B and Llama 3 8B offer only 8K token context windows. NeMo is designed for multilingual use cases and provides a new tokenizer, Tekken, which outperforms the Llama 3 tokenizer for compressing text across 85% of languages. The HuggingFace model card indicates NeMo should be used with lower temperatures than earlier Mistral models, they recommend setting the temperature to 0.3.
- Availability: NeMo 12B is an open source model (offering both base and instruction-tuned checkpoints) under the Apache 2.0 License.
- Performance: Mistral NeMo 12B outperforms Gemma 2 9B and Llama 3 8B across multiple zero and five shot benchmarks by as much as 10%. It also performs almost 2x better than Mistral 7B on WildBench which is designed to measure model’s performance on real world tasks requiring complex reasoning and multiple conversation turns.

GPT-4o mini
- Overview: GPT-4o mini is a small, cost effective model that supports text and vision and offers competitive reasoning and tool calling performance. It has a 128K token context window with an impressive 16K token output length. It is the most cost effective model from OpenAI at 15 cents per million input tokens and 60 cents per million output tokens. OpenAI notes that this price is 99% cheaper than their text-davinci-003 model from 2022 indicating a trend towards cheaper, smaller, more capable models in a relatively short time frame. While GPT-4o mini does not support image, video, and audio inputs like GPT-4o does, OpenAI reports these features are coming soon. Like GPT-4o, GPT-4o mini has been trained with built-in safety measures and is the first OpenAI model that applies the instruction hierarchy method designed to make the model more resistant to prompt injections and jailbreaks. GPT-4o mini leverages the same tokenizer as GPT-4o which enables improved performance on non-English text.
- Availability: GPT-4o mini is a closed source model available through OpenAI’s Assistants API, Chat Completions API, and Batch API. It is also available through Azure AI.
- Performance: GPT-4o mini outperforms Gemini Flash and Claude Haiku, models of similar size, on multiple benchmarks including MMLU (Massive Multitask Language Understanding) which is designed to measure reasoning ability, MGSM (Multilingual Grade School Math) which measures mathematical reasoning, HumanEval which measures coding ability, and MMMU (Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark) which measures multimodal reasoning.

Llama 3.1
- Overview: Llama 3.1 introduces a 128K token context window, a significant jump from the 8K token context window for Llama 3, which was released only three months ago in April. Llama 3.1 is available in three sizes: 405B, 70B, and 8B. It offers improved reasoning, tool-calling, and multilingual performance. Meta’s Llama 3.1 announcement calls Llama 3.1 405B the “first frontier-level open source AI model”. This demonstrates a huge stride forward for the open source community and demonstrates Meta’s commitment to making AI accessible, Mark Zuckerberg discusses this in more detail in his article “Open Source AI is the Path Forward”. The Llama 3.1 announcement also includes guidance on enabling common use cases like real-time and batch inference, fine-tuning, RAG, continued pre-training, synthetic data generation, and distillation. Meta also released the Llama Reference System to support developers working on agentic based use cases with Llama 3.1 and additional AI safety tools including Llama Guard 3 to moderate inputs and outputs in multiple languages, Prompt Guard to mitigate prompt injections, and CyberSecEval 3 to reduce GenAI security risks.
- Availability: Llama 3.1 is an open source model. Meta has changed their license to allow developers to use the outputs from Llama models to train and improve other models. Models are available through HuggingFace, llama.meta.com, and through other partner platforms like Azure AI.
- Performance: Each of the Llama 3.1 models outperform other models in their size class across nearly all the common language model benchmarks for reasoning, coding, math, tool use, long context, and multilingual performance.

Trends in GenAI Models
Overall, there is a trend towards increasingly capable models of all sizes with longer context windows, longer token output lengths, and lower price points. The push towards improved reasoning, tool calling, and coding abilities reflect the increasing demand for agentic systems capable of taking complex actions on behalf of users. To create effective agent systems, models need to understand how to break down a problem, how to use the tools available to them, and how to reconcile lots of information at one time.
The recent announcements from OpenAI and Meta reflect the growing discussion around AI safety with both companies demonstrating different ways to approach the same challenge. OpenAI has taken a closed source approach and improved model safety through applying feedback from experts in social psychology and misinformation and implementing new training methods. In contrast, Meta has doubled down on their open source initiatives and released new tools focused on helping developers mitigate AI safety concerns.

Conclusion
In the future, I think we’ll continue to see advancements in generalist and specialist models with frontier models like GPT-4o and Llama 3.1 getting better and better at breaking down problems and performing a variety of tasks across modalities, while specialist models like Codestral Mamba will excel in their domain and become more adept at handling longer contexts and nuanced tasks within their area of expertise. Additionally, I expect we’ll see new benchmarks focused on models’ ability to follow multiple directions at once within a single turn and a proliferation of AI systems that leverage generalist and specialist models to perform tasks as a team.
Furthermore, while model performance is typically measured based on standard benchmarks, what ultimately matters is how humans perceive the performance and how effectively models can further human goals. The Llama 3.1 announcement includes an interesting graphic demonstrating how people rated responses from Llama 3.1 compared to GPT-4o, GPT-4, and Claude 3.5. The results show that Llama 3.1 received a tie from humans in over 50% of the examples with the remaining win rates roughly split between Llama 3.1 and it’s challenger. This is significant because it suggests that open source models can now readily compete in a league that was previously dominated by closed source models.
Interested in discussing further or collaborating? Reach out on LinkedIn!
Navigating the Latest GenAI Model Announcements — July 2024 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Navigating the Latest GenAI Model Announcements — July 2024
Go Here to Read this Fast! Navigating the Latest GenAI Model Announcements — July 2024