

Navigating Slowly Changing Dimensions (SCD) and Data Restatement: A Comprehensive Guide
Strategies for efficiently managing dimension changes and data restatement in enterprise data warehousing
Imagine this, you are a data engineer working for a large retail company that utilizes the incremental load technique in data warehousing. This technique involves selectively updating or loading only the new or modified data since the last update. What could occur when the product R&D department decides to change the name or description of a current product? How would such updates impact your existing data pipeline and data warehouse? How do you plan to address challenges like these? This article provides a comprehensive guide with solutions, utilizing Slowly Changing Dimensions (SCD), to tackle potential issues during data restatement.
What are Slowly Changing Dimensions (SCD)?
Slowly changing dimensions refer to infrequent changes in dimension values, which occur sporadically and are not tied to a daily or regular time-based schedule, as dimensions typically change less frequently than transaction entries in a system. For example, a jewelry company that has its customers placing a new order on their website will become a new row in the order fact table. On the other hand, the jewelry company rarely changes their product name and their product description but that doesn’t mean it will never happen in the future.
Managing changes in these dimensions requires employing Slowly Changing Dimension (SCD) management techniques, which are categorized into defined SCD types, ranging from Type 0 through Type 6, including some combination or hybrid types. We can employ one of the following methods:
SCD Type 0: Ignore
Changes to dimension values are completely disregarded, and the values of dimensions remain unchanged from the time they were initially created in the data warehouse.
SCD Type 1: Overwrite/ Replace
This approach is applicable when the previous value of the dimension attribute is no longer relevant or important. However, historical tracking of changes is not necessary.
SCD Type 2: Create a New Dimension Row
This approach is recommended as the primary technique for addressing changing dimension values, involving the creation of a second row for the dimension with a start date, end date, and potentially a “current/expired” flag. It is suitable for our scenarios like product description or address changes, ensuring a clear partitioning of history. The new dimension row is linked to newly inserted fact rows, with each dimension record linked to a subset of fact rows based on insertion times — those before the change linked to the old dimension row, and those after linked to the new dimension row.
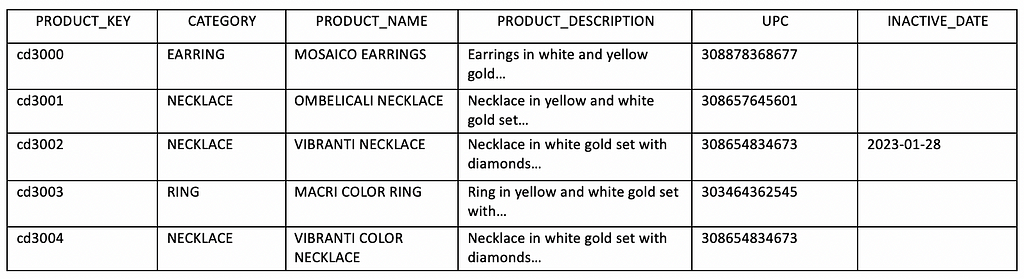
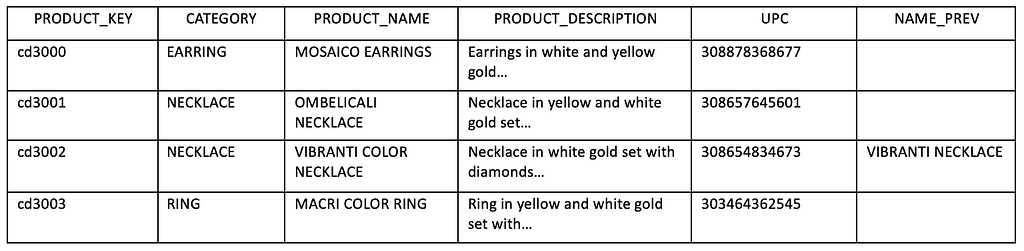
SCD Type 3: Create a “PREV” Column
This method is suitable when both the old and new values are relevant, and users may want to conduct historical analysis using either value. However, it is not practical to apply this technique to all dimension attributes, as it would involve providing two columns for each attribute in dimension tables or more if multiple “PREV” values need preservation. It should be selectively used where appropriate.
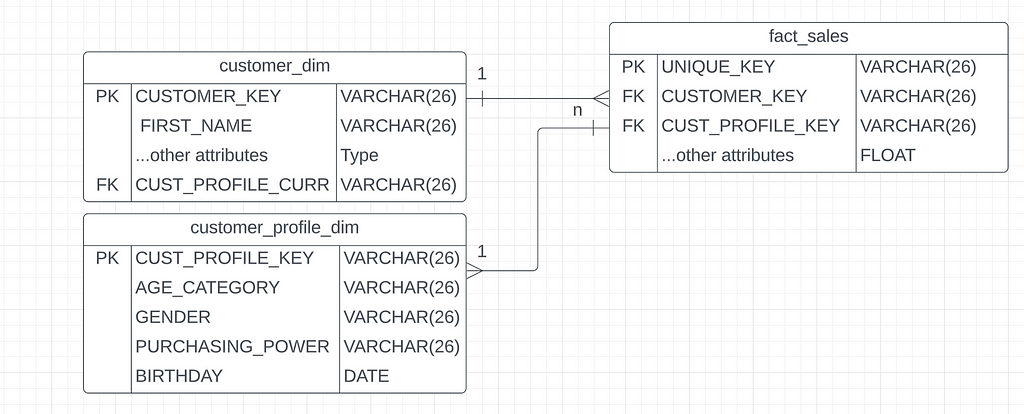
SCD Type 4: Rapidly Changing Large Dimensions
What if in a scenario you need to capture every change to every dimension attribute for a very large dimension of retail, say a million plus customers of your huge jewelry company? Using type 2 above will very quickly explode the number of rows in the customer dimension table to tens or even hundreds of millions of rows and using type 3 is not viable.
A more effective solution for rapidly changing and large volume dimension tables is to categorize attributes (e.g., customer age category, gender, purchasing power, birthday, etc.) and separate them into a secondary dimension, like a customer profile dimension. This table, acting as a “full coverage” dimension table all potential values for every category of dimension attributes preloaded into the table, which can better manage the granularity of changes while avoiding excessive row expansion in the main customer dimension.
For example, if we have 8 age categories, 3 different genders, 6 purchasing power categories, and 366 possible birthdays. Our “full coverage” dimension table for customer profiles that contains all the above combinations will be 8 x 3 x 6 x 366 combinations or 52704 rows.
We’ll need to generate surrogate_key for this dimension table and establish a connection to a new foreign key in the fact table. When a modification occurs in one of these dimension categories, there’s no necessity to add another row to the customer dimension. Instead, we generate a new fact row and associate it with both the customer dimension and the new customer profile dimension.
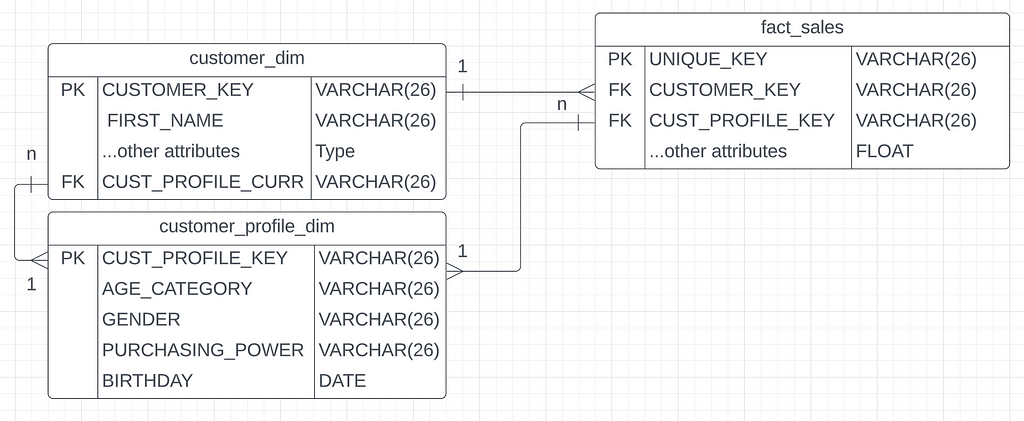
SCD Type 5: An Extension to Type 4
To enhance the Type 4 approach mentioned earlier, we can establish a connection between the customer dimension and the customer profile dimension. This linkage enables the tracking of the “current” customer profile for a specific customer. The key facilitates the connection of the customer with the latest customer profile, which allows seamless traversal from the customer dimension to the most recent customer profile dimension without the need to link through the fact table.
SCD Type 6: A Hybrid Technique
With this approach, you integrate both Type 2 (new row) and Type 3 (“PREV” column). This blended approach offers the advantages of both methodologies. You can retrieve facts using the “ PREV “ column, which provides historical values and presents facts associated with the product category at that specific time. Simultaneously, querying by the “new” column provides all facts for both the current and all preceding values of the product category.
Bonus and Conclusion
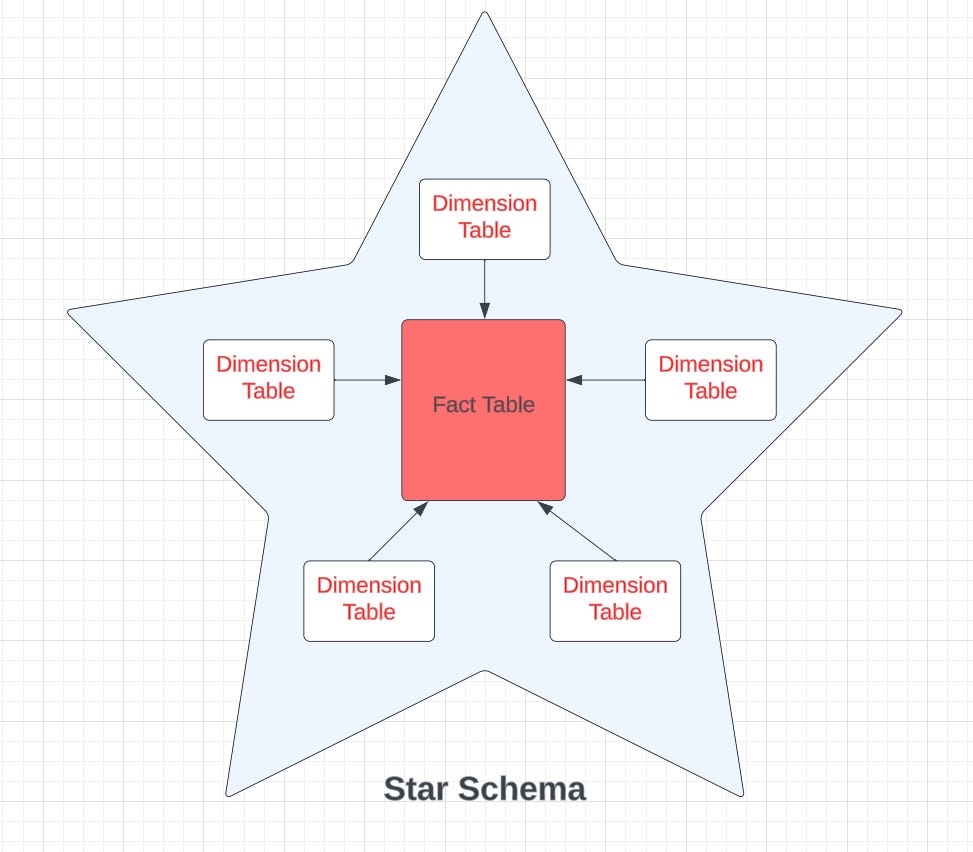
Normally, data extraction comes in STAR schema, which includes one fact table and multiple dimension tables in an enterprise. While the dimension tables store all the descriptive data and primary keys, the fact table contains numeric and additive data that references the primary keys of each dimension around it.
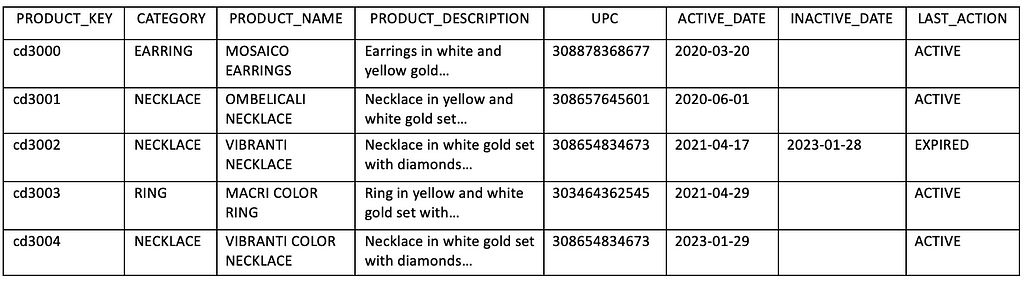
However, if your marketing sales data extract is provided as a single denormalized table without distinct dimension tables and lacks the primary key for its descriptive data, future updates to product names may pose challenges. Handling such scenarios in your existing pipeline can be more complicated.
The absence of primary keys in the descriptive data can lead to issues during data restatement, especially when you are dealing with large datasets. For instance, if a product name is updated in the restatement extract without a unique product_key, the incremental load pipeline may treat it as a new product, impacting the historical data in your consumption layer. To address this, creating surrogate_key for the product dimension and a mapping table to link original and restated product names is necessary for maintaining data integrity.
In conclusion, every aspect of data warehouse design should be carefully considered, taking into account potential edge cases.
Navigating Slowly Changing Dimensions (SCD) and Data Reinstatement: A Comprehensive Guide was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Navigating Slowly Changing Dimensions (SCD) and Data Reinstatement: A Comprehensive Guide