

This blog post will go into the architecture and findings behind Apple’s “MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training” paper
Abstraction is one of the most critical concepts in Computer Science, with some of the most powerful implications. From a simplistic point of view, abstraction is the ability to take something and apply it to multiple distinct situations. For example, if you create a way to successfully sort apples based on their size in a factory, your solution could be abstracted to also sort oranges or peaches in the same way. Thus, through abstraction a very powerful solution is able to radically impact multiple parts of the world.
While Large Language Models are exceptional at reasoning when given text as an input, recently we have been able to abstract their input so that they can reason with images and sounds.
The below blog post goes into architectural ablations in Apple’s MM1 paper and their research findings when building a Multimodal Large Language Model (MLLM).
Abstracting LLM Input
The architecture behind Large Language Models can be traced back to the 2017 paper “Attention is All You Need” where the Transformer Architecture was introduced.
This paper showed how you could transform human language into tokens that a neural network would then process (in that paper’s case, process into a different language).

As you can see from the image, we have a transformation occurring early on where we take the input and convert it into tokens (the embedding section). However, there is no inherent reason why only text data can be mapped to tokens. Consequently, the field began trying to map other kinds of data to tokens.
MM1 Architecture Base

Apple’s model had 3 key components: a visual transformer (ViT) image encoder, Vision-Language Connector, and a Large Language Model. Assuming you already have a good idea of what a LLM is and how it works, let’s dive into the image encoder and VL connector.
Image Encoders & Visual Connectors
While from an abstracted view we can imagine text and images as simply different kinds of inputs, to make this work we need to accept that we may have to treat them differently to get them into token form. At this time, we have 2 different systems that help us transform the image into tokens the LLM can reason with: image encoder and connector.
First, the image encoder is responsible for taking our image and converting it into the token representation that our transformer model can understand.
Second, a connector is the piece that takes data from the vision encoder and transforms it into the data that is passed directly to the large language model. Given the image encoder returns tokens, you may wonder why we need the connector at all. The idea appears to be that image encoders give too much information in their tokens, so to reduce costs while optimizing reasoning, we want to be selective with what we pass through.
The below image shows the data flow we’re working with here.
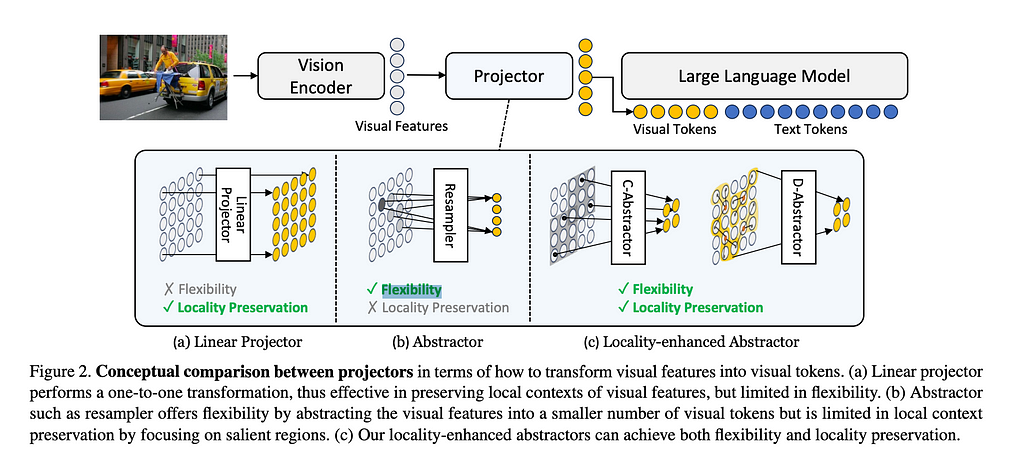
Ablations
An ablation study in Machine Learning revolves around removing and modifying certain parts of a model to see how they contribute to overall performance. Apple’s research centered around different ways of training the Image Encoder, different projectors for the VL Connector, and different pre-training data.
Let’s dive into the major findings.
Image Encoder Ablations
For the Image Encoder, they varied between CLIP and AIM models, Image resolution size, and the dataset the models were trained on. The below chart shows you the results for each ablation.
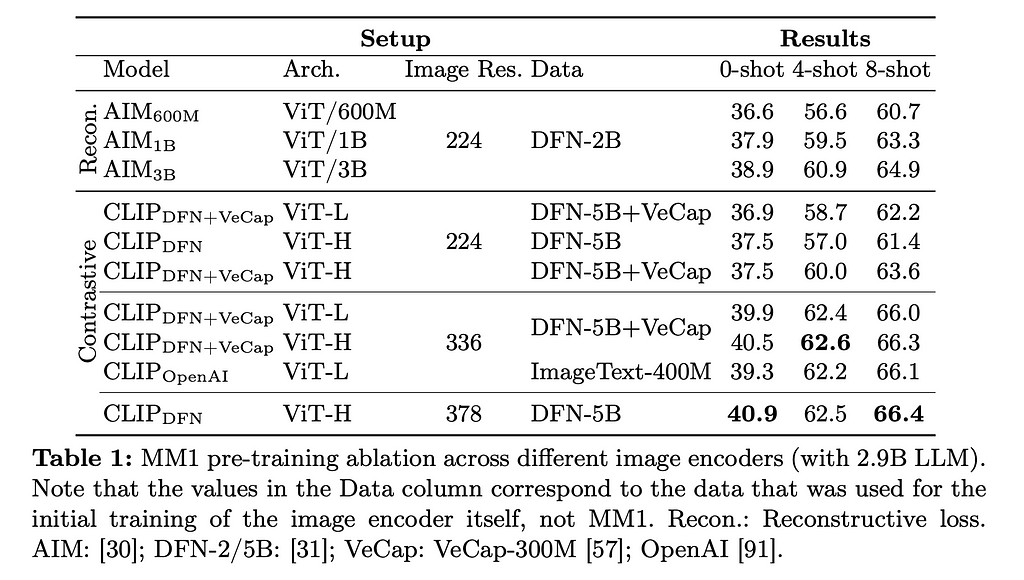
Let’s go through the major pieces above and explain what they are.
CLIP stands for Contrastive Language Image Pre-training and is meant to help your model learn visual concepts by providing names to the things that are meant to be seen as text. As the image below shows, this pairs images with text encodings so that the model will eventually connect the vision tokens (represented in the below image as I, with the text tokens T). This method is called contrastive training.
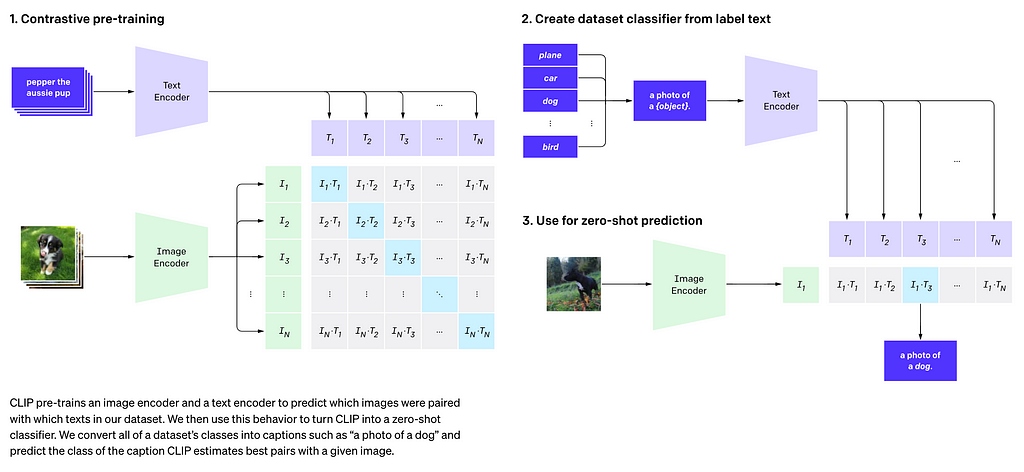
AIM stands for Autoregressive Image Model, and it is trained via a reconstructive loss optimization algorithm. The goal here is to see if the transformer can recreate (reconstruct) the image that it is given.

Image Resolution here refers to the number of pixels that is fed into the transformer. For example, a 378 x 378 image resolution means we will pass in a matrix of that size and then convert it into embeddings that the model will then be trained on. Training Data was split between the (DFN-2B), (DFN-5B), (DFN-5B + VeCap) and (ImageText-400M).
The authors found that image resolution was of highest importance, followed by model size and then the training data contents. Specifically, they saw that the better the image resolution, the better the model tended to perform for both zero-shot and few-shot prompting. As more compute is needed to train and run models with higher image resolution requirements, this suggests that for Vision Transformers, compute will remain of paramount importance.
VL Connection Ablations
For the VL Connector, they tested using 64 or 144 tokens for the image, tested using 224, 336, and 378 for the image resolution, and chose between a few architectures. I’ll briefly go over the architectures below.
Average Pooling is exactly what it sounds like, taking the average of all of the tokens, and then doing a linear projection of this average so that the grid was 8×8 or 12×12.
Attention Pooling makes the assumption that image tokens should be treated as samples from a fundamentally different population set than the text tokens. Here we adjust how many tokens are fed in for each image, in the paper referred to as k learnable queries. The researchers only considered k of either 64 or 144.
Convolutional Mapping is a a method from Honeybee that uses a ResNet to dynamically decide how many tokens to pass through to the LLM from the image. This is actualized in the C-Abstractor module.

As you can see from the above, the different architectures actually had very little impact. As one might guess, the higher resolution images and the more tokens passed through increased performance among all of the connectors but not dramatically so.
This finding suggests we either haven’t found a significantly better way to connect the image encoder to the LLM, or that this area is simply not where great models will differentiate themselves.
Pre-Training Data Ablations
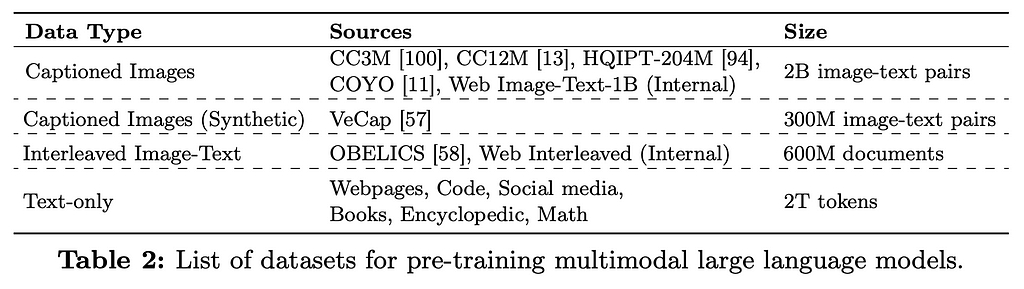
Here, the authors played with 4 different kinds of data: captioned images, synthetically captioned images, interleaved image-text data, and text-only data. They found 4 lessons, each with a graph to summarize the performance changes.
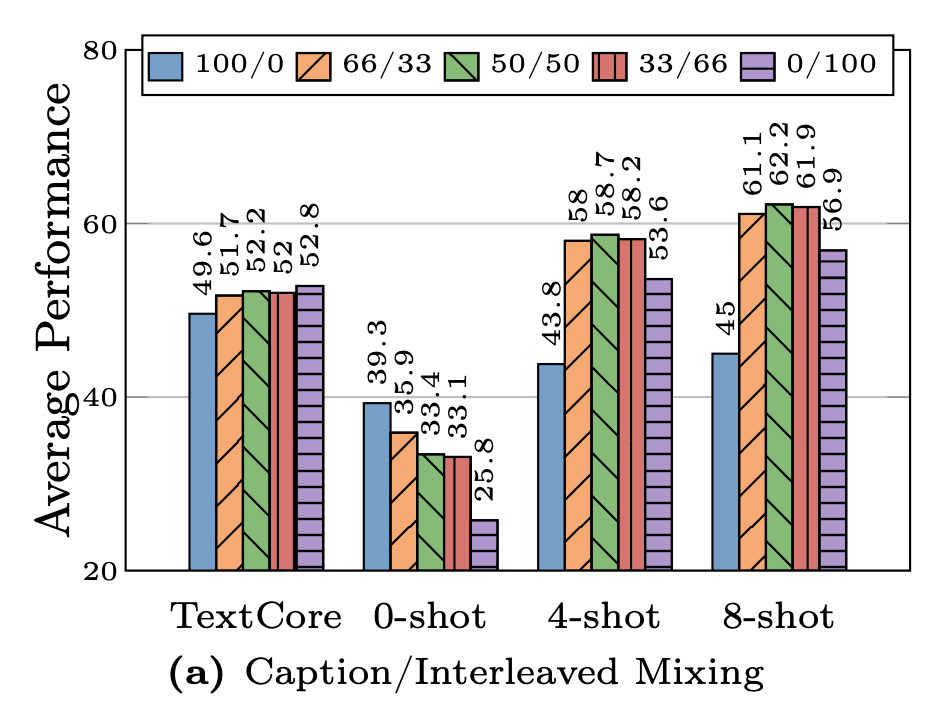
First, interleaving data helps with few-shot and text-only performance, while captioned data helps with zero-shot performance. The researchers varied how much interleaving they did, with the graph below showing the results. As you can see, few-shot prompts performed noticeably better on models trained with interleaved data than the models trained with all or nothing.
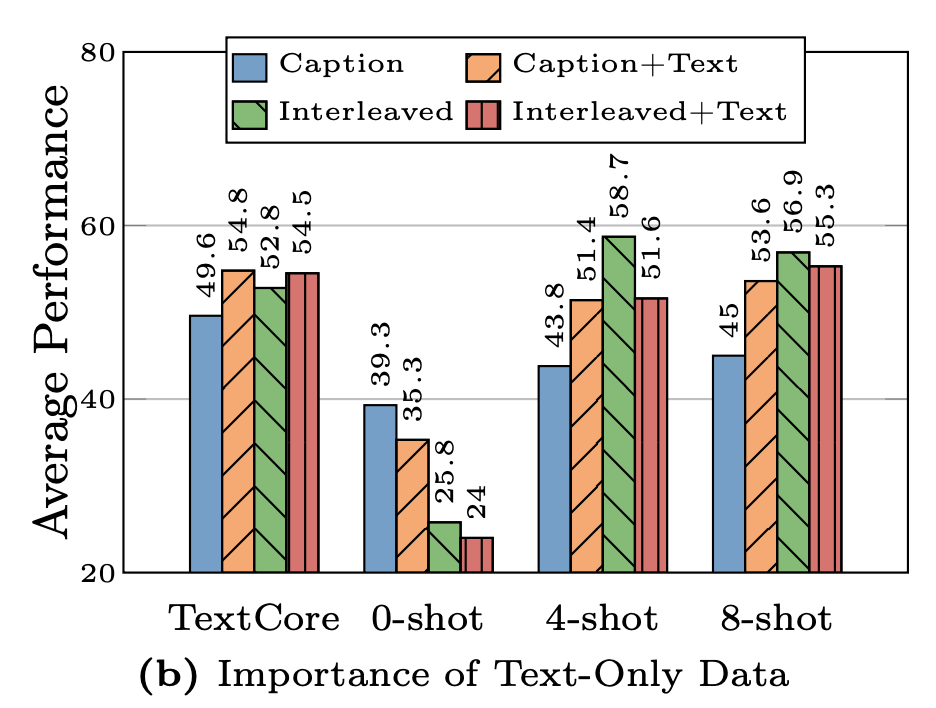
Second, Text-only data helps with few-shot reasoning. Text-only in this context means that the training data includes image examples and text-only examples. This was done to ensure that the model understands human language as well as images. Comparing the caption-only to caption-with-text shows a marked improvement for all but the 0-shot reasoning, however, interleaved-only performs better than interleaved-plus-text for all but the TextCore test.

Third, if you get the mixture right between image and text you can get really strong performance. The above graph shows different ratios of interleaved + captioned data to text-only data. As the goal is to have a multi-modal model, they never tested the performance if you do not have any image data. The authors here point out that the 91/9 ratio produced the most consistently good results.
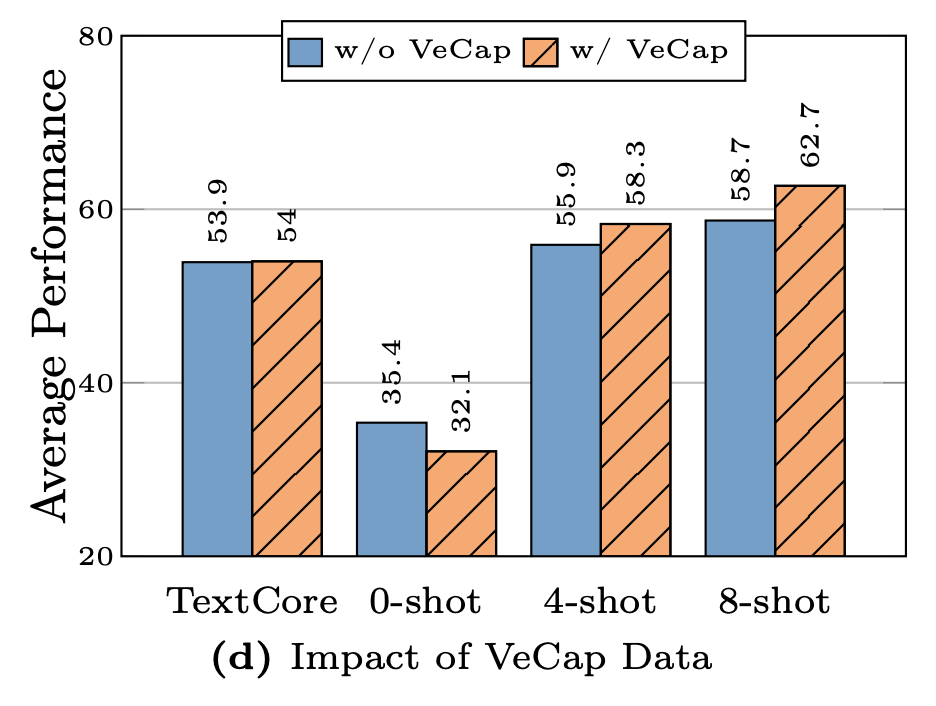
Fourth, synthetic data helps with few-shot learning. VeCap stands for Visual-enriched Caption, which is a way of creating captions so that they are sure to describe key visual pieces of the image. For the reverse, imagine a caption that may explain the meaning behind a photo but doesn’t explain any of the elements in the photo. You would typically do this if your data-scraper found images with poor alt-text data.
The authors here concluded that VeCap gives a “non-trivial” boost in few-shot reasoning, but has a relatively small increase in quality. This raises questions about the cost-effectiveness of VeCap.
Results
Using the results from their ablations, the authors created a Transformer in two-forms: Mixture-of-Expert and regular. Both models had an encoder with a 378 x 378 image, pre-trained with DFN-5B dataset only. They had a mix of 45% captioned data, 45% interleaved data, and 10% text-only data (approximating the 91:9 ratio of image to text data). The VL Connector had 144 tokens and they chose a C Abstractor, though they point out that this was a somewhat arbitrary choice. For the LLM itself, they created a 3B, 7B, and 30B parameter model (with the MoE model only going up to 7B). The graph below shows how the these models performed.
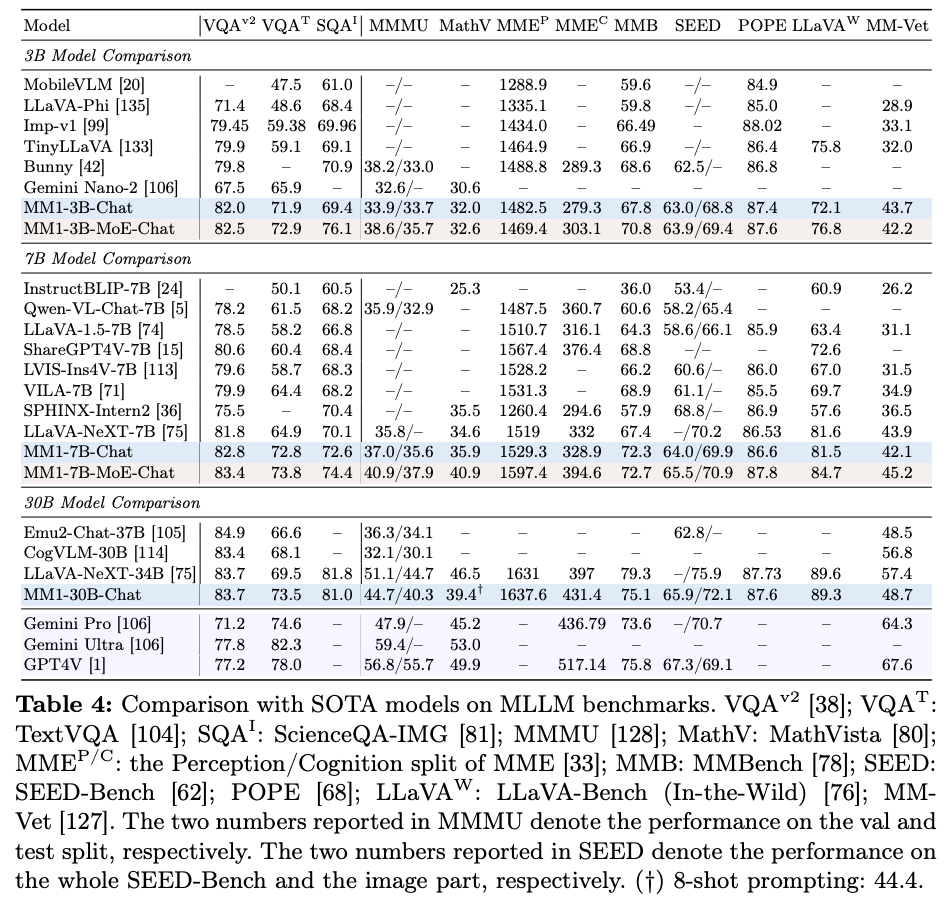
Interestingly, the 30B parameter model performs on par with other models which have billions more parameters than it (LLaVA-NeXT-34B, etc.), suggesting that there may be some quantum relationship between parameter size and performance here.
Closing Thoughts
Multi-modal LLMs are an incredibly exciting part of the field. As we find better ways to transmit different data types into tokens, we may unlock even greater applications for these transformers. As we look to the future, it is not unreasonable now to consider how other senses could be inputed outside of a text description, such as sound, smell, or even touch. Data quality is likely to only become more valuable.
As the authors concluded that the different language connectors don’t make a major difference, it will be interesting to see if this means research should focus on the image encoder, or rather if we simply haven’t found a true breakthrough way to use the VL connector.
Outside of this specific paper, one of the big questions that arises is how these MLLMs will perform outside of benchmarks. As LLMs have proliferated, one common criticism revolves around the use of benchmarks to compare them. Often times these benchmarks use a consistent dataset to compare, allowing one model to do better simply by overfitting, even if unintentionally. Using methodologies like ELO, the chess rating algorithm, in the LLM Arena from lmsys may give a better true comparison of model performance.
In closing, as more inputs are able to be connected to LLMs, one can expect that the number of applications they can be applied to will increase. Only time will tell how useful we can make this technology.
[1] McKinzie, B., et al. “MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training” (2024), arXiv
[2] Cha, J., et al. “Honeybee: Locality-enhanced Projector for Multimodal LLM” (2023), arXiv
[3] Antoniadis, P., et al. “Machine Learning: What Is Ablation Study?” (2024), arXiv
[4] Radford, A., et al. “Learning Transferable Visual Models From Natural Language Supervision” (2021), arXiv
[5] El-Nouby, Al., et al. “Scalable Pre-training of Large Autoregressive Image Models” (2024), arXiv
[6] Vaswani, A., et al., “Attention Is All You Need” (2017), arXiv
[7] Lai, Z., et al., “VeCLIP: Improving CLIP Training via Visual-enriched Captions” (2023), arXiv
Multimodal Large Language Models & Apple’s MM1 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.