All hail the return of Keras


Keras is Back!! First released in 2015 as a high-level Python library for training ML models, Keras grew in popularity due to its clean and simple APIs. Contrary to the ML frameworks of the time, with their awkward and clunky APIs, Keras lowered the entry bar for many incumbent ML developers (the author included). But somewhere along the way the use of Keras became virtually synonymous with TensorFlow development. Consequently, when developers began to turn to alternative frameworks, the relative popularity of Keras began to decline. But now, following a “complete rewrite”, Keras has returned. And with its shiny new engine and its renewed commitment to multi-backend support, it vies to return to its former glory.
In this post we will take a new look at Keras and assess its value offering in the current era of AI/ML development. We will demonstrate through example its ease of use and make note of its shortcomings. Importantly, this post is not intended to be an endorsement for or against the adoption of Keras (or any other framework, library, service, etc.). As usual, the best decision for your project development will depend on a great many details, many of which are beyond the scope of this post.
The recent release of Google’s family of open sourced NLP models known as Gemma, and the inclusion of Keras 3 as a core component of the API, offers us an opportunity to evaluate Keras’s goodness and could serve as a great opportunity for its resurgence.
Why Use Keras 3?
In our view, the most valuable feature offered by Keras 3 is its multi-framework support. This may surprise some readers who may recall Keras’s distinctiveness to be its user experience. Keras 3 advertises itself, as “simple”, “flexible”, and being “designed for human beings, not machines”. And indeed, it owes its early successes and meteoric rise in popularity to its user experience. But it is now 2024 and there are many high-level deep learning APIs offering “reduced cognitive load”. In our view, the user experience, as good as it may be, is no longer a sufficient motivator to consider Keras over its alternatives. Its multi-framework support is.
The Merits of Multi-Framework Support
Keras 3 supports multiple backends for training and running its models. At the time of this writing, these include JAX, TensorFlow, and PyTorch. The Keras 3 announcement does a pretty good job of explaining the advantages of this feature. We will expand on the documented benefits and add some of our own flavor.
Avoid the difficulty of choosing an AI/ML framework:
Choosing an AI/ML framework is probably one of the most important decisions you will need to make as an ML developer. It is also one of the hardest. There are many considerations that need to factor into this decision. These include user experience, API coverage, programmability, debuggability, the formats and types of input data that are supported, conformance with other components on the development pipeline (e.g., restrictions that may be imposed by the model deployment phase), and, perhaps most importantly, runtime performance. As we have discussed in many of our previous posts (e.g., here), AI/ML model development can be extremely expensive and the overall impact on cost of even the smallest speed-up due to the choice of framework can be dramatic. In fact, in many cases it may warrant the overhead of porting your model and code to a different framework and/or even maintaining support for multiple frameworks.
The problem is that it is extremely difficult, if not impossible, to know which framework will be most optimal for your model before you start your development. Moreover, even once you have committed to one framework, you will want to stay on top of the evolution and development of all frameworks and to continuously assess potential opportunities to improve your model and/or reduce the cost of development. The landscape of AI/ML development is extremely dynamic with optimizations and enhancements being designed and developed on a consistent basis. You will not want to fall behind.
Keras 3 solves the framework selection problem by enabling you to develop your model without committing to an underlying backend. The option to toggle between multiple framework-backends allows you to focus on the model definition and, once complete, choose the backend that best suits your needs. And even as the properties of the ML project change or the supported frameworks evolve, Keras 3 enables you to easily assess the impact of changing the backend.
Putting it colloquially, you could say that Keras 3 helps humans avoid one of the things they hate doing most — making decisions and committing to them. But humor aside, AI/ML model development using Keras 3 can certainly prevent you from choosing and being stuck with a suboptimal framework.
Enjoy the best of all worlds:
PyTorch, TensorFlow, and JAX, each have their own unique advantages and differentiating properties. JAX, for example, supports just-in-time (JIT) compilation in which the model operators are converted into an intermediate computation graph and then compiled together into machine code specifically targeted for the underlying hardware. For many models this results in a considerable boost in runtime performance. On the other hand, PyTorch, which is typically used in a manner in which the operators are executed immediately (a.k.a. “eagerly”) is often considered to: have the most Pythonic interface, be the easiest to debug, and offer the best overall user experience. By using Keras 3 you can enjoy the best of both worlds. You can set the backend to PyTorch during your initial model development and for debugging and switch to JAX for optimal performance when training in production mode.
Compatibility with the maximum number of AI accelerators and runtime environments:
As we have discussed in the past (e.g., here) our goal is to be compatible with as many AI accelerators and runtime environments as possible. This is especially important in an era of constrained capacity of AI machines in which the ability to switch between different machine types is a huge advantage. When you develop with Keras 3 and its multi-backend support, you automatically increase the number of platforms that you can potentially train and run your model on. For example, while you may be most accustomed to running in PyTorch on GPUs, by simply changing the backend to JAX you can configure your model to run on Google Cloud TPUs, as well ( — though this may depend on the details of the model).
Increase model adoption:
If you are targeting your model for use by other AI/ML teams, you will increase your potential audience by supporting multiple frameworks. For all sorts of reasons, some teams may be limited to a specific ML framework. By delivering your model in Keras you remove barriers for adoption. A great example of this is the recent release of Google’s Gemma models which we will discuss in greater detail below.
Decouple the data input pipeline from the model execution:
Some frameworks encourage the use of certain data storage formats and/or data loading practices. A classic example of this is TensorFlow’s TFRecord data format for storing a sequence of binary records that are typically stored in .tfrecord files. While TensorFlow includes native support for parsing and processing data stored TFRecord files, you might find feeding them into a PyTorch training loop to be a bit more difficult. A preferable format for PyTorch training could be WebDataset. But the creation of training data can be a long process and maintaining it in more than one format could be prohibitively expensive. Thus, the manner in which your training data is stored and maintained might discourage teams from considering alternative frameworks.
Keras 3 helps teams overcome this obstacle by completely decoupling the data input pipeline from the training loop. You can define your input data pipelines in PyTorch, TensorFlow, Numpy, Keras, and other libraries without any consideration for the backend that will be used in your training loop. With Keras 3, having your training data stored in TFRecord files is no longer a barrier to adopting PyTorch as a backend.
The Disadvantages of Multi-Framework Support
As with any other new SW solution on the market, it is important to be aware of the potential downsides of Keras 3. A general rule of thumb in SW development is that the higher up the SW stack you go, the less control you have over the behavior and performance of your application. In AI/ML, where the degree of success is often determined by precise tuning of model hyperparameters, initialization settings, appropriate environment configuration, etc., such control could be critical. Here are just a few potential drawbacks to consider:
Potential drop in runtime performance:
Working the high level Keras APIs rather than directly with the framework APIs, may pose limitations on optimizing runtime performance. In our series of posts on the topic of analyzing and optimizing the performance of PyTorch models, we demonstrated a wide range of tools and techniques for increasing the speed of training. Sometimes these require the direct, unmediated, use of PyTorch’s APIs. For example, Keras’s APIs currently include very limited support for PyTorch’s JIT compilation option (via the jit_compile setting). Another example is PyTorch’s built-in support for scaled dot product attention which is not supported at the Keras level (as of the time of this writing).
Limitations of cross-framework support:
Although Keras’s cross-framework support is extensive, you may find that it is not all-encompassing. For example, one gap in coverage (as of the time of this writing) is distributed training. Although, Keras introduces the Keras distribution API to support data and model parallelism across all backends, it is currently implemented for the JAX backend only. To run distributed training when using other backends, you will need to fall back to the standard distribution APIs of the relevant framework (e.g., PyTorch’s distributed data parallel API).
Overhead of maintaining cross-framework compatibility:
Keras 3 supports a wide variety of pre-built models that you can reuse (e.g., here). However, inevitably, you may want to introduce your own customizations. While Keras 3 supports customization of the model layers, metrics, training loop and more, you will need to take care not to break your cross-framework compatibility. For example, if you create a custom layer using Keras’s backend-agnostic APIs (keras.ops), you can rest assured that multi-backend support is retained. However, sometimes you may choose to rely on framework-specific operations. In such cases maintaining cross-framework compatibility will require a dedicated implementation for each framework and appropriate conditional programming based on the backend in use. The current methods for customizing a training step and a training loop are framework-specific, meaning that they too would require dedicated implementations for each backend to retain cross-framework compatibility. Thus, as your model grows in complexity, so might the overhead required to maintain this unique capability.
We have noted just a few potential disadvantages to Keras 3 and its multi-backend support. You may very well likely come across others. While the multi-framework offering is certainly compelling, its adoption is not necessarily free of cost. Borrowing the name of a well-known theorem in the field of statistical inference, one could say that when it comes to choosing an AI/ML development methodology, there are “no free lunches”.
Keras 3 in Practice — A Toy Example
As in many of our recent posts, the toy model we will define will be a Vision Transformer (ViT) backed classification model. We will rely on the reference implementation located in this Keras tutorial. We have configured our model according to the ViT-Base architecture (~86 million parameters), set the mixed_precision policy to use bfloat16, and defined a PyTorch dataloader with random input data.
The following block includes the configuration settings followed by definitions of the core ViT model components:
import os
# choose backend
backend = 'jax' # 'torch'
os.environ["KERAS_BACKEND"] = backend
import keras
from keras import layers
from keras import ops
# set mixed precision policy
keras.mixed_precision.set_global_policy('mixed_bfloat16')
# use ViT Base settings
num_classes = 1000
image_size = 224
input_shape = (image_size, image_size, 3)
patch_size = 16 # Size of the patches to be extract from the input images
num_patches = (image_size // patch_size) ** 2
projection_dim = 768
num_heads = 12
transformer_units = [
projection_dim * 4,
projection_dim,
] # Size of the transformer layers
transformer_layers = 12
# set training hyperparams
batch_size = 128
multi_worker = False # toggle to use multiple data loader workers
preproc_workers = 0 if 'jax' else 16
# ViT model components:
# ---------------------
def mlp(x, hidden_units, dropout_rate):
for units in hidden_units:
x = layers.Dense(units, activation=keras.activations.gelu)(x)
x = layers.Dropout(dropout_rate)(x)
return x
class Patches(layers.Layer):
def __init__(self, patch_size):
super().__init__()
self.patch_size = patch_size
def call(self, images):
input_shape = ops.shape(images)
batch_size = input_shape[0]
height = input_shape[1]
width = input_shape[2]
channels = input_shape[3]
num_patches_h = height // self.patch_size
num_patches_w = width // self.patch_size
patches = keras.ops.image.extract_patches(images, size=self.patch_size)
patches = ops.reshape(
patches,
(
batch_size,
num_patches_h * num_patches_w,
self.patch_size * self.patch_size * channels,
),
)
return patches
class PatchEncoder(layers.Layer):
def __init__(self, num_patches, projection_dim):
super().__init__()
self.num_patches = num_patches
self.projection = layers.Dense(units=projection_dim)
self.position_embedding = layers.Embedding(
input_dim=num_patches, output_dim=projection_dim
)
def call(self, patch):
positions = ops.expand_dims(
ops.arange(start=0, stop=self.num_patches, step=1), axis=0
)
projected_patches = self.projection(patch)
encoded = projected_patches + self.position_embedding(positions)
return encoded
Using the core components, we define a ViT-backed Keras model:
# the attention layer we will use in our ViT classifier
attention_layer = layers.MultiHeadAttention
def create_vit_classifier():
inputs = keras.Input(shape=input_shape)
# Create patches.
patches = Patches(patch_size)(inputs)
# Encode patches.
encoded_patches = PatchEncoder(num_patches, projection_dim)(patches)
# Create multiple layers of the Transformer block.
for _ in range(transformer_layers):
# Layer normalization 1.
x1 = layers.LayerNormalization(epsilon=1e-6)(encoded_patches)
# Create a multi-head attention layer.
attention_output = attention_layer(
num_heads=num_heads, key_dim=projection_dim//num_heads, dropout=0.1
)(x1, x1)
# Skip connection 1.
x2 = layers.Add()([attention_output, encoded_patches])
# Layer normalization 2.
x3 = layers.LayerNormalization(epsilon=1e-6)(x2)
# MLP.
x3 = mlp(x3, hidden_units=transformer_units, dropout_rate=0.1)
# Skip connection 2.
encoded_patches = layers.Add()([x3, x2])
# Create a [batch_size, projection_dim] tensor.
representation = layers.LayerNormalization(epsilon=1e-6)(encoded_patches)
representation = layers.GlobalAveragePooling1D()(representation)
representation = layers.Dropout(0.5)(representation)
# Classify outputs.
logits = layers.Dense(num_classes)(representation)
# Create the Keras model.
model = keras.Model(inputs=inputs, outputs=logits)
return model
# create the ViT model
model = create_vit_classifier()
model.summary()
In the next block we define the optimizer, loss, and dataset.
model.compile(
optimizer=keras.optimizers.SGD(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
)
def get_data_loader(batch_size):
import torch
from torch.utils.data import Dataset, DataLoader
# create dataset of random image and label data
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([224, 224, 3], dtype=torch.float32)
label = torch.tensor(data=[index % 1000], dtype=torch.int64)
return rand_image, label
ds = FakeDataset()
dl = DataLoader(
ds,
batch_size=batch_size,
num_workers=preproc_workers if multi_worker else 0,
pin_memory=True
)
return dl
dl = get_data_loader(batch_size)
Finally, we start the training using Keras’s Model.fit() function:
model.fit(
dl,
batch_size=batch_size,
epochs=1
)
We ran the script above on a Google Cloud Platform (GCP) g2-standard-16 VM (with a single NVIDIA L4 GPU) with a dedicated deep learning VM image (common-cu121-v20240514-ubuntu-2204-py310) and installations of PyTorch (2.3.0), JAX (0.4.28), Keras (3.3.3), and KerasCV (0.9.0). Please see the official Keras documentation for full installation instructions. Note that we manually modified the format of step time reported by the Keras progress bar:
formatted += f" {time_per_unit:.3f}s/{unit_name}"
Using the backend flag we were able to easily toggle between the backends supported by Keras and compare the runtime performance of each. For example, when configuring PyTorch dataloader with 0 workers, we found that JAX backend to outperform PyTorch by ~24%. When setting the number of workers to 16 this drops to ~12%.
Custom Attention Layer
We now define a custom attention layer that replaces Keras’s default attention computation with PyTorch’s flash attention implementation. Note that this will only work when the backend is set to torch.
class MyAttention(layers.MultiHeadAttention):
def _compute_attention(
self, query, key, value, attention_mask=None, training=None
):
from torch.nn.functional import scaled_dot_product_attention
query = ops.multiply(
query, ops.cast(self._inverse_sqrt_key_dim, query.dtype))
return scaled_dot_product_attention(
query.transpose(1,2),
key.transpose(1,2),
value.transpose(1,2),
dropout_p=self._dropout if training else 0.
).transpose(1,2), None
attention_layer = MyAttention
The results of our experiments are summarized in the table below. Keep in mind that the relative performance results are likely to vary greatly based on the details of the model and the runtime environment.
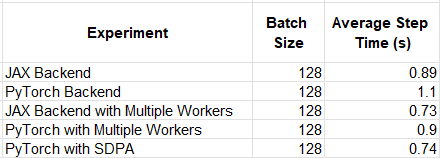
When using our custom attention layer, the gap between the JAX and PyTorch backends virtually disappears. This highlights how the use of a multi-backend solution could come at the expense of optimizations uniquely supported by any of the individual frameworks (in our example, PyTorch SDPA).
Keras 3 in Gemma
Gemma is a family of lightweight, open source models recently released by Google. Keras 3 plays a prominent role in the Gemma release (e.g., see here) and its multi-framework support makes Gemma automatically accessible to AI/ML developers of all persuasions — PyTorch, TensorFlow, and Jax. Please see the official documentation in KerasNLP for more details on the Gemma API offering.
The following code is loosely based on the official Gemma fine-tuning tutorial. In order to run the script, please follow the necessary setup instructions.
import os
backend = 'jax' #'torch'
os.environ["KERAS_BACKEND"] = backend
num_batches = 1000
batch_size = 4 if backend == 'jax' else 2
# Avoid memory fragmentation on JAX backend.
os.environ["XLA_PYTHON_CLIENT_MEM_FRACTION"]="1.00"
os.environ["KAGGLE_USERNAME"]="chaimrand"
os.environ["KAGGLE_KEY"]="29abebb28f899a81ca48bec1fb97faf1"
import keras
import keras_nlp
keras.mixed_precision.set_global_policy('mixed_bfloat16')
import json
data = []
with open("databricks-dolly-15k.jsonl") as file:
for line in file:
features = json.loads(line)
# Filter out examples with context, to keep it simple.
if features["context"]:
continue
# Format the entire example as a single string.
template = "Instruction:n{instruction}nnResponse:n{response}"
data.append(template.format(**features))
# Only use 1000 training batches, to keep it fast.
data = data[:num_batches*batch_size]
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_2b_en")
# Enable LoRA for the model and set the LoRA rank to 4.
gemma_lm.backbone.enable_lora(rank=4)
gemma_lm.summary()
# Limit the input sequence length to 512 (to control memory usage).
gemma_lm.preprocessor.sequence_length = 512
gemma_lm.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.SGD(learning_rate=5e-5),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
gemma_lm.fit(data, epochs=1, batch_size=batch_size)
When running the script in the same GCP environment described above, we see a significant (and surprising) discrepancy between the runtime performance when using the JAX backend (6.87 samples per second) and the runtime performance when using the PyTorch backend (3.01 samples per second). This is due, in part, to the fact that the JAX backend allows for doubling the training batch size. A deep dive into the causes of this discrepancy is beyond the scope of this post.
As in our previous example, we demonstrate one way of optimizing the PyTorch runtime by prepending the following configuration of the matrix multiplication operations to the top of our script:
import torch
torch.set_float32_matmul_precision('high')
This simple change results in a 29% performance boost when running with the PyTorch backend. Once again, we can see the impact of applying framework-specific optimizations. The experiment results are summarized in the table below.

Conclusion
Our demonstrations have indicated that sticking with the backend agnostic Keras code could imply a meaningful runtime performance penalty. In each example, we have seen how a simple, framework-specific optimization had a significant impact on the relative performance of our chosen backends. At the same time, the arguments we have discussed for multi-framework AI/ML development are rather compelling.
If you do choose to adopt Keras as a development framework, you may want to consider designing your code in a manner that includes mechanisms for applying and assessing framework-specific optimizations. You might also consider designing your development process in a way that utilizes Keras during the early stages of the project and, as the project matures, optimizes for the one backend that is revealed to be the most appropriate.
Summary
In this post we have explored the new and revised Keras 3 release. No longer an appendage to TensorFlow, Keras 3 offers the ability of framework-agnostic AI/ML model development. As we discussed, this capability has several significant advantages. However, as is often the case in the field of AI development, “there are no free lunches” — the added level of abstraction could mean a reduced level of control over the inner workings of our code which could imply slower training speed and higher costs. The best solution might be one that combines the use of Keras and its multi-framework support with dedicated mechanisms for incorporating framework-specific modifications.
Importantly, the applicability of Keras 3 to your project and the cost-best analysis of the investment required, will depend greatly on a wide variety of factors including: the target audience, the model deployment process, project timelines, and more. Please view this post as a mere introduction into your detailed exploration.
Multi-Framework AI/ML Development with Keras 3 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Multi-Framework AI/ML Development with Keras 3
Go Here to Read this Fast! Multi-Framework AI/ML Development with Keras 3