Multi-Agent-as-a-Service — A Senior Engineer’s Overview
There has been much discussion about AI Agents — pivotal self-contained units capable of performing tasks autonomously, driven by specific instructions and contextual understanding. In fact, the topic has become almost as widely discussed as LLMs. In this article, I consider AI Agents and, more specifically, the concept of Multi-Agents-as-a-Service from the perspective of the lead engineers, architects, and site reliability engineers (SREs) that must deal with AI agents in production systems going forward.
Context: What Problems Can AI Agents Solve?
AI agents are adept at tasks that benefit from human-friendly interactions:
- E-Commerce: agents powered by technologies like LLM-based RAG or Text-to-SQL respond to user inquiries with accurate answers based on company policies, allowing for a more tailored shopping experience and customer journey that can revolutionize e-commerce
- Customer Service: This is another ideal application. Many of us have experienced long waits to speak with representatives for simple queries like order status updates. Some startups — Decagon for example — are making strides in addressing these inefficiencies through AI agents.
- Personalized Product and Content Creation: a prime example of this is Wix — for low-code or no-code website building, Wix developed a chatbot that, through interactive Q&A sessions, creates an initial website for customers according to their description and requirements.
Overall, LLM-based agents would work great in mimicking natural human dialogue and simple business workflows, often producing results that are both effective and impressively satisfying.
An Engineer’s View: AI Agents & Enterprise Production Environments
Considering the benefits mentioned, have you ever wondered how AI agents would function within enterprise production environments? What architecture patterns and infrastructure components best support them? What do we do when things inevitably go wrong and the agents hallucinate, crash or (arguably even worse) carry out incorrect reasoning/planning when performing a critical task?
As senior engineers, we need to carefully consider the above. Moreover, we must ask an even more important question: how do we define what a successful deployment of a multi-agent platform looks like in the first place?
To answer this question, let’s borrow a concept from another software engineering field: Service Level Objectives (SLOs) from Reliability Engineering. SLOs are a critical component in measuring the performance and reliability of services. Simply put, SLOs define the acceptable ratio of “successful” measurements to “all” measurements and their impact on the user journeys. These objectives help us determine the required and expected levels of service from our agents and the broader workflows they support.
So, how are SLOs relevant to our AI Agent discussion?
Using a simplified view, let’s consider two important objectives — “Availability” and “Accuracy” — for the agents and identify some more granular SLOs that contribute to these:
- Availability: this refers to the percentage of requests that receive some successful response (think HTTP 200 status code) from the agents or platform. Historically, the uptime and ping success of the underlying servers (i.e. temporal measures) were key correlated indicators of availability. But with the rise of Micro-services, notional uptime has become less relevant. Modern systems instead focus on the number of successful versus unsuccessful responses to user requests as a more accurate proxy for availability. Other related metrics can be thought of as Latency and Throughput.
- Accuracy: this, on the other hand, is less about how quickly and consistently the agents return responses to the clients, but rather how correctly, from a business perspective, they are able to perform their tasks and return data without a human present in the loop to verify their work. Traditional systems also track similar SLOs such as data correctness and quality.
The act of measuring the two objectives above normally occurs through submission of internal application metrics at runtime, either at set time intervals (e.g. every 10 minutes), or in response to events (user requests, upstream calls etc.). Synthetic probing, for instance, can be used to mimic user requests, trigger relevant events and monitor the numbers. The key idea to explore here is this: traditional systems are deterministic to a large extent and, therefore, it’s generally more straightforward to instrument, probe and evaluate them. On the other hand, in our beautiful yet non-deterministic world of GenAI agents, this is not necessarily the case.
Note: the focus of this post is more so on the former of our two objectives – availability. This includes determining acceptance criteria that sets up baseline cloud/environmental stability to help agents respond to user queries. For a deeper dive into accuracy (i.e. defining sensible task scope for the agents, optimizing performance of few-shot methods and evaluation frameworks), this blog post acts as a wonderful primer.
Now, back to the things engineers need to get right to ensure infrastructure reasiness when deploying agents. In order to achieve our target SLOs and provide a reliable and secure platform, senior engineers consistently take into account the following elements:
- Scalability: when number of requests increase (suddenly at times), can the system handle them efficiently?
- Cost-Effectiveness: LLM usage is expensive, so how can we monitor and control the cost?
- High Availability: how can we keep the system always-available and responsive to customers? Can agents self-heal and recover from errors/crashes?
- Security: How can we ensure data is secure at rest and in transit, perform security audits, vulnerability assessments, etc.?
- Compliance & Regulatory: a major topic for AI, what are the relevant data privacy regulations and other industry-specific standards to which we must adhere?
- Observability: how can we gain real-time visibility into AI agents’ activities, health, and resource utilization levels in order to identify and resolve problems before they impact the user experience?
Sound familiar? These are similar to the challenges that modern web applications, Micro-services pattern and Cloud infrastructure aim to address.
So, now what? We propose an AI Agent development and maintenance framework that adheres to best-practices developed over the years across a range of engineering and software disciplines.
Multi-Agent-as-a-Service (MAaaS)
This time, let us borrow some of best-practices for cloud-based applications to redefine how agents are designed in production systems:
- Clear Bounded Context: Each agent should have a well-defined and small scope of responsibility with clear functionality boundaries. This modular approach ensures that agents are more accurate, easier to manage and scale independently.
- RESTful and Asynchronous Inter-Service Communication: Usage of RESTful APIs for communication between users and agents, and leveraging message brokers for asynchronous communication. This decouples agents, improving scalability and fault tolerance.
- Isolated Data Storage per Agent: Each agent should have its own data storage to ensure data encapsulation and reduce dependencies. Utilize distributed data storage solutions where necessary to support scalability.
- Containerization and Orchestration: Using containers (e.g. Docker) to package and deploy agents consistently across different environments, simplifying deployment and scaling. Employ container orchestration platforms like Kubernetes to manage the deployment, scaling, and operational lifecycle of agent services.
- Testing and CI/CD: Implementing automated testing (unit, integration, contract, and end-to-end tests) to ensure the reliable change management for agents. Use CI tools to automatically build and test agents whenever code changes are committed. Establish CD pipelines to deploy changes to production seamlessly, reducing downtime and ensuring rapid iteration cycles.
- Observability: Implementing robust observability instrumentation such as metrics, tracing and logging for the agents and their supporting infrastructure to build a real-time view of the platform’s reliability (tracing could be of particular interest here if a given user request goes through multiple agents). Calculating and tracking SLO’s and error budgets for the agents and the aggregate request flow. Synthetic probing and efficient Alerting on warnings and failures to make sure agent health issues are detected before widely impacting the end users.
By applying these principles, we can create a robust framework for AI agents, transforming the concept into “Multi-Agent as a Service” (MAaaS). This approach leverages the best-practices of cloud-based applications to redefine how agents are designed, deployed, and managed.
The agent plays a critical role in business operations; however, it does not function in isolation. A robust infrastructure supports it, ensuring it meets production expectations, with some key components:
- Service-Oriented Architecture: Design agents as services that can be easily integrated into existing systems.
- API Gateway: Use an API gateway to manage and secure traffic between clients and agents.
- Elastic Infrastructure: Utilize cloud infrastructure that can elastically scale resources up or down based on demand.
- Managed Services: Take advantage of managed services for databases, vector stores, messaging, and machine learning to reduce operational overhead.
- Centralized Monitoring: Use centralized monitoring solutions (e.g., CloudWatch, Prometheus, Grafana) to track the health and performance of agents.
To highlight this, we will demo a simple multi-agent system: a debate platform.
Example: Multi-Agent Debate System
We’ve crafted a multi-agent debate system to demonstrate MAaaS in action. The debate topic is AI’s impact on the job market. The setup features three agents:
- Team A, which supports AI’s benefits for jobs
- Team B, which holds the opposing view
- The Host, which manages the debate, ending it after eight rounds or when discussions become redundant.
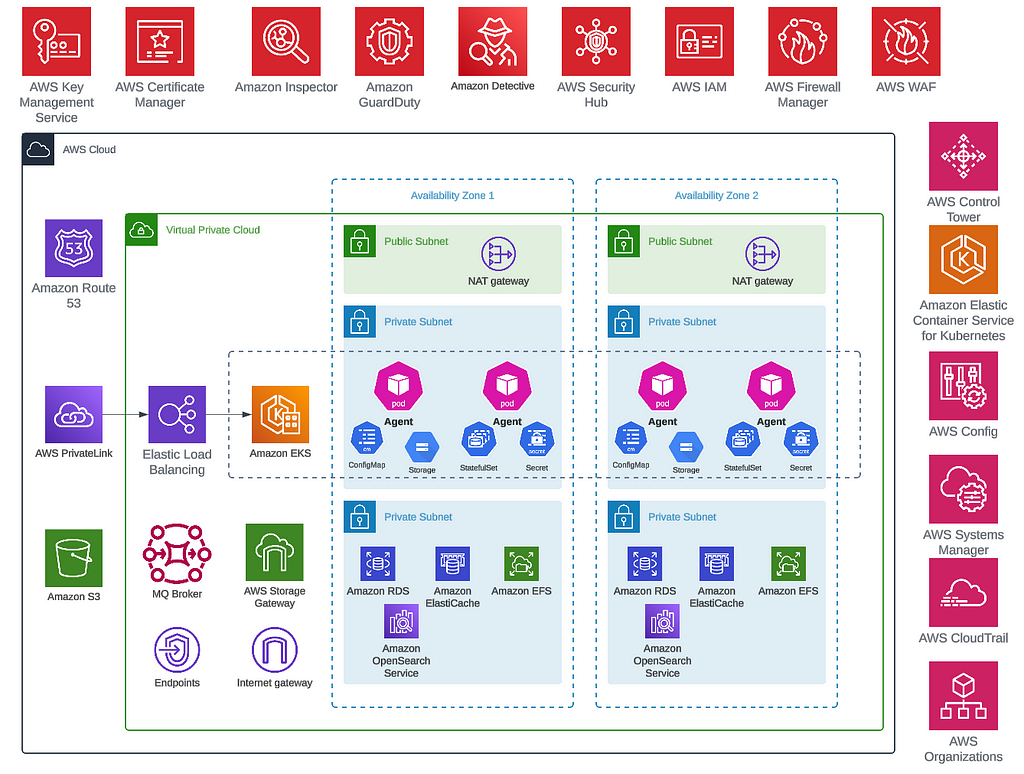
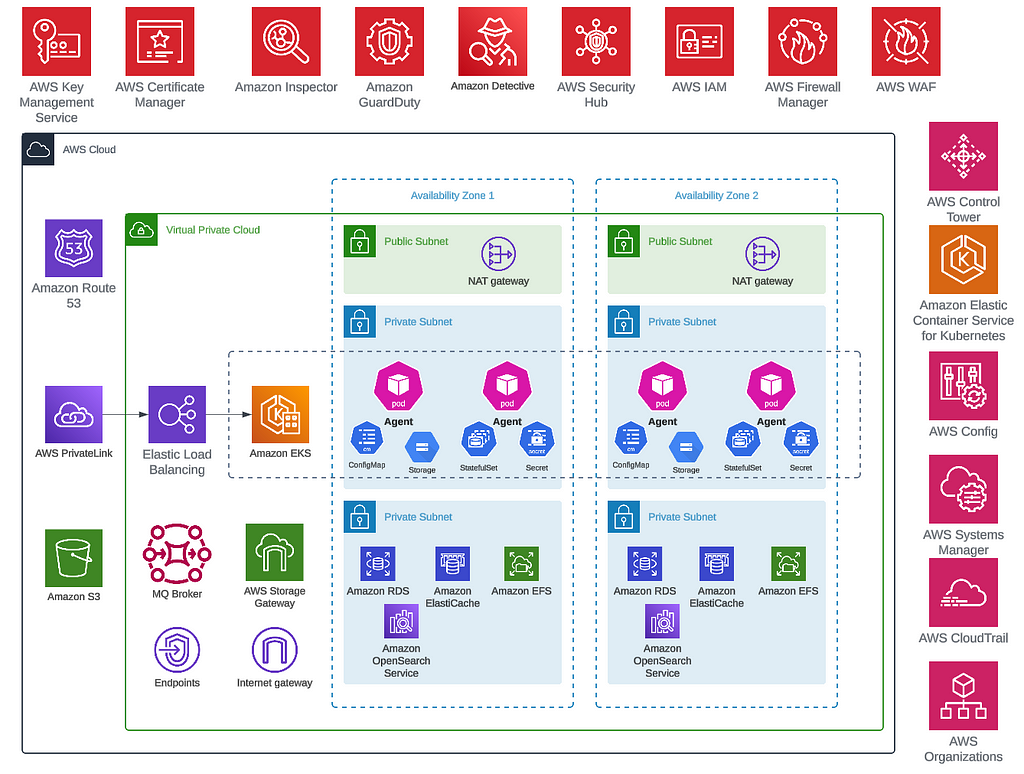
Focusing on system architecture, we use PhiData to create the agents, deploying them via AWS Elastic Kubernetes Service (EKS) for high availability. Agent activities are monitored with AWS CloudWatch, and EKS’s service discovery ensures agents communicate seamlessly. Crucially, conversation histories are stored in a database, allowing any backup agent to continue discussions without interruption in case of failures. This resilience is bolstered by a message queue that ensures data integrity by processing messages only when fully consumed. To maintain dialogue flow, each agent is limited to a single replica for now, though Kubernetes would ensure that desired state is always maintained in case of the pod going down.
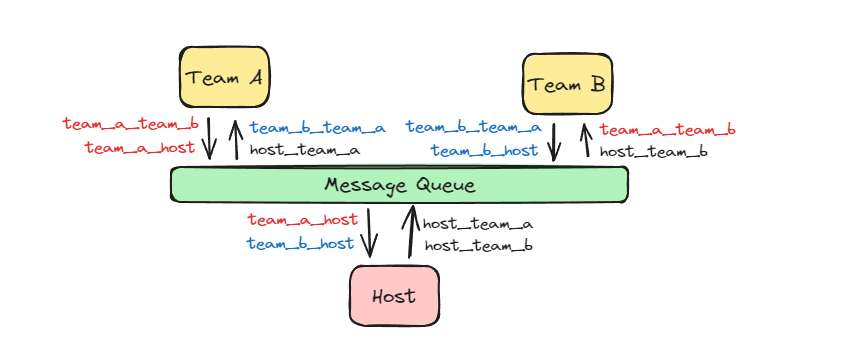
To enable users to try the system locally, we’ve created a MiniKube deployment YAML. In this simplified version, we’ve eliminated the postgres database. Instead, each agent will temporarily store its conversation history in memory. This adjustment keeps the system lightweight and more accessible for local deployment, while still showcasing the essential functionalities. You would need to install MiniKube, Ollama and kubectl on your system first.
Save the above in a file called deploy.ymland run:
$ minikube start
$ ollama run llama3
$ kubectl apply -f deploy.yml
To start debate (minikube behaves slightly differently on Linux-based vs. Windows systems):
$ kubectl get pods
$ kubectl exec <host-pod-name> -- curl -X GET 'http://localhost:8080/agent/start_debate'
To get the debate history:
$ kubectl exec <host-pod-name> -- curl -X GET 'http://localhost:8080/agent/chat-history'
To tear down the resource:
$ kubectl delete -f .minikube-deploy.yml
The agents proceed to have an outstanding debate (see debate output in the appendix below).
Conclusion
The interest in multi-agent systems opens up numerous possibilities for innovation and efficiency. By leveraging cloud-native principles and best practices, we can create scalable, cost-effective, secure, and highly available multi agent systems. The MAaaS paradigm not only aligns with modern software engineering principles but also paves the way for more sophisticated and production-ready AI applications. As we continue to explore and refine these concepts, the potential for multi agent system to revolutionize various industries becomes increasingly promising.
Note: this article was written as a collaboration between Sam Rajaei and Guanyi Li.
Appendix: Debate Output
Thank you for your attention, till next time!

Multi-Agent-as-a-Service — A Senior Engineer’s Overview was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Multi-Agent-as-a-Service — A Senior Engineer’s Overview
Go Here to Read this Fast! Multi-Agent-as-a-Service — A Senior Engineer’s Overview