

Build Trusted Data Platforms with Google SRE Principles
Do you have customers coming to you first with a data incident? Are your customers building their own data solutions due to un-trusted data? Does your data team spend unnecessarily long hours remediating undetected data quality issues instead of prioritising strategic work?
Data teams need to be able to paint a complete picture of their data systems health in order to gain trust with their stakeholders and have better conversations with the business as a whole.
We can combine data quality dimensions with Google’s Site Reliability Engineering principles to measure the health of our Data Systems. To do this, assess a few Data Quality Dimensions that makes sense for your data pipelines and come up with service level objectives (SLOs).
What are Service Level Objectives?
The service level terminology we will use in this article are service level indicators and service level objectives. The two are borrowed principles from Google’s SRE book.
service level indicator — a carefully defined quantitative measure of some aspect of the level of service that is provided.
The indicators we’re familiar with in the software world are throughput, latency and up time (availability). These are used to measure the reliability of an application or website.

The indicators are then turned into objectives bounded by a threshold. The health of the software application is now “measurable” in a sense that we can now communicate the state of our application with our customers.
service level objective: a target value or range of values for a service level that is measured by an SLI.
We have an intuitive understanding of the necessity of these quantitative measures and indicators in a typical user applications to reduce friction and establish trust with our customers. We need to start adopting a similar mindset when building out data pipelines in the data world.
Data Quality Dimensions Translated into Service Level Terminology
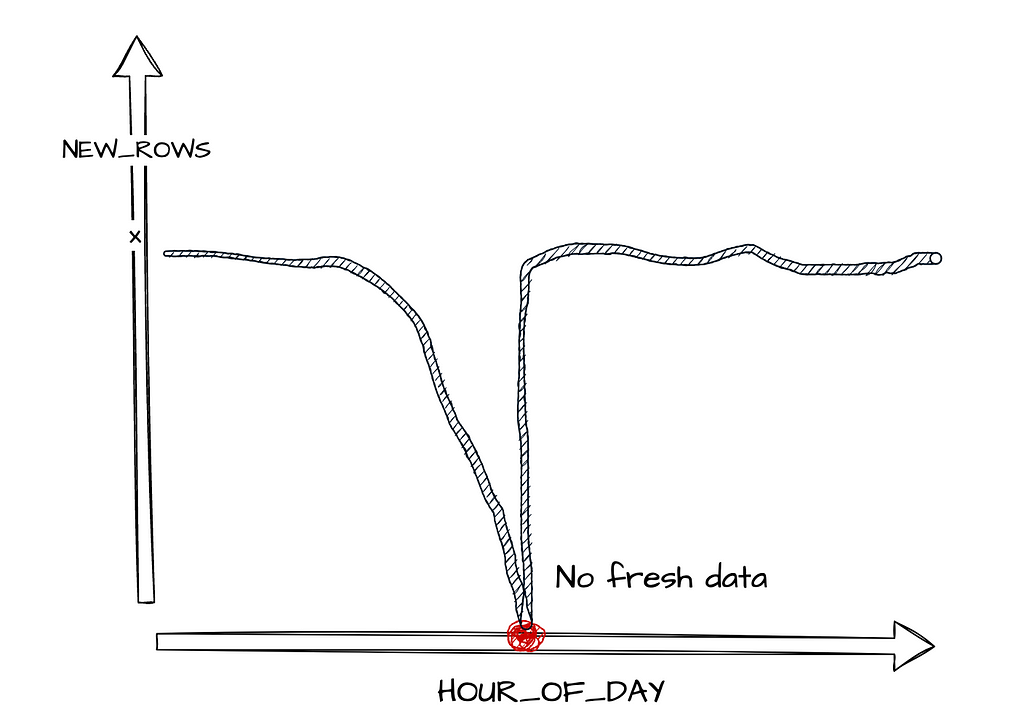
Lets say the user interacts with our application and generates X amounts of data every hour into our data warehouse, if the number of rows entering the warehouse suddenly decreases drastically, we can flag it as an issue. Then trace our timestamps from our pipelines to diagnose and treat the problem.
We want to capture enough information about the data coming into our systems so that we can detect when anomalies occur. Most data teams tend to start with Data Timeliness. Is the expected amount of data arriving at the right time?
This can be decomposed into the indicators:
- Data Availability — Has the expected amount of data arrived/been made available?
- Data Freshness — Has new data arrived at the expected time?

Once the system is stable it is important to maintain a good relationship with your customers in order to set the right objectives that are valuable to your stakeholders.
Concept of a Threshold…
How do we actually figure out how much data to expect and when? What is the right amount of data for all our different datasets? This is when we need to focus on the threshold concept as it does get tricky.
Assume we have an application where users mainly login to the system during the working hours. We expect around 2,000 USER_LOGIN events per hour between 9am to 5pm, and 100 events outside of those hours. If we use a single threshold value for the whole day, it would lead to the wrong conclusion. Receiving 120 events at 8pm is perfectly reasonable, but it would be concerning and should be investigated further if we only received 120 events at 2pm.
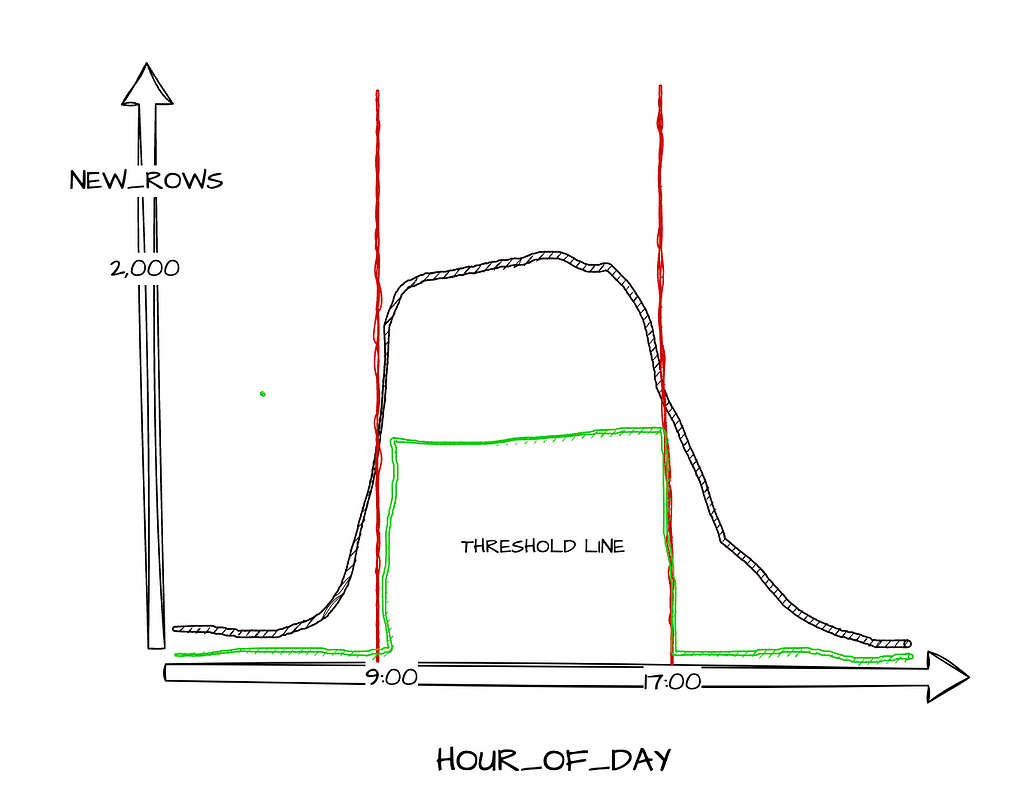
Because of this, we need to calculate a different expected value for each hour of the day for each different dataset — this is the threshold value. A metadata table would need to be defined that dynamically fetches the number of rows arrived each hour in order to get a resulting threshold that makes sense for each data source.
There are some thresholds which can be extracted using timestamps as a proxy as explained above. This can be done using statistical measures such as averages, standard deviations or percentiles to iterate over your metadata table.
Depending on how creative you want to be, you can even introduce machine learning in this part of the process to help you set the threshold. Other thresholds or expectations would need to be discussed with your stakeholders as it would stem from having specific knowledge of the business to know what to expect.
Technical Implementation in Snowflake
The very first step to getting started is picking a few business critical dataset to build on top of before implementing a data-ops solution at scale. This is the easiest way to gather momentum and feel the impact of your data observability efforts.
Many analytical warehouses already have inbuilt functionalities around this. For example, Snowflake has recently pushed out Data Metric Functions in preview for Enterprise accounts to help data teams get started quickly.
Data Metrics Functions is a wrapper around some of the queries we might write to get insights into our data systems. We can start with the system DMFs.

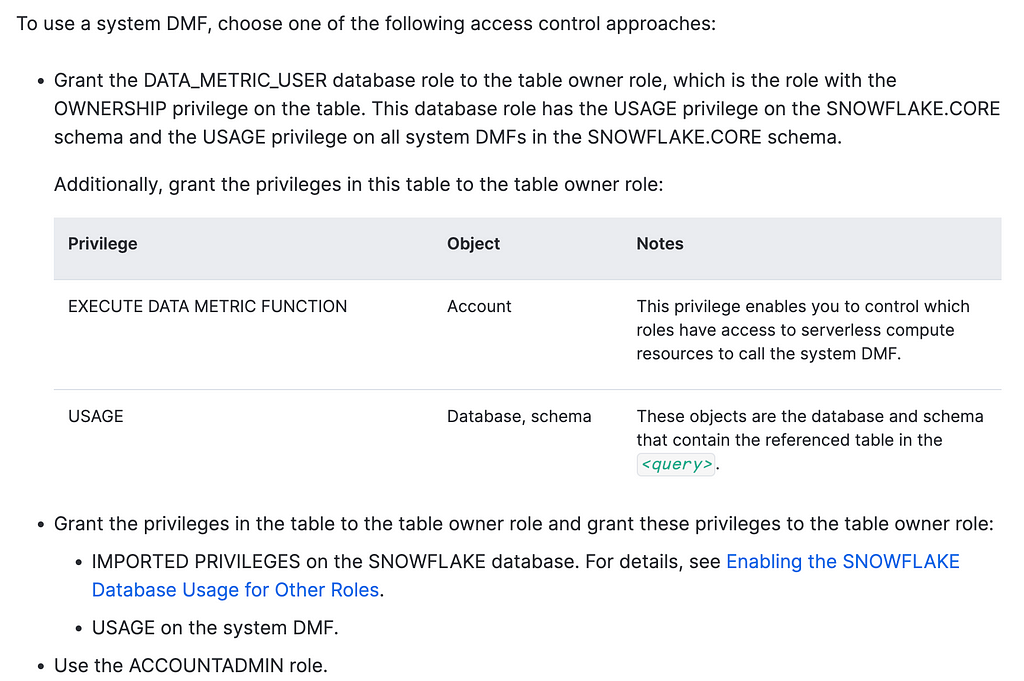
We first need to sort out a few privileges…
USE ROLE ACCOUNTADMIN;
GRANT database role DATA_METRIC_USER TO role jess_zhang;
GRANT EXECUTE data metric FUNCTION ON account TO role jess_zhang;
## Useful queries once the above succeeds
SHOW DATA METRIC FUNCTIONS IN ACCOUNT;
DESC FUNCTION snowflake.core.NULL_COUNT(TABLE(VARCHAR));
DATA_METRIC_USER is a database role which may catch a few people out. It’s important to revisit the docs if you’re running into issues. The most likely reason is probably due to permissions.
Then, simply choose a DMF …
-- Uniqueness
SELECT SNOWFLAKE.CORE.NULL_COUNT(
SELECT customer_id
FROM jzhang_test.product.fct_subscriptions
);
-- Freshness
SELECT SNOWFLAKE.CORE.FRESHNESS(
SELECT
_loaded_at_utc
FROM jzhang_test.product.fct_subscriptions
) < 60;
-- replace 60 with your calculated threshold value
You can schedule your DMFs to run using Data Metric Schedule — an object parameter or your usual orchestration tool. The hard-work would still need to be done to determine your own thresholds in order to set the right SLOs for your pipelines.
In Summary…
Data teams need to engage with stakeholders to set better expectations about the data by using service level indicators and objectives. Introducing these metrics will help data teams move from reactively firefighting to a more proactive approach in preventing data incidents. This would allow energy to be refocused towards delivering business value as well as building a trusted data platform.
Unless otherwise noted, all images are by the author.
Monitor Data Pipelines Using Snowflake’s Data Metric Functions was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Monitor Data Pipelines Using Snowflake’s Data Metric Functions
Go Here to Read this Fast! Monitor Data Pipelines Using Snowflake’s Data Metric Functions