

Seeking advice from a panel of specialists
Large Language Models (LLMs) have undoubtedly taken the tech industry by storm. Their meteoric rise was fueled by a large corpora of data from Wikipedia, web pages, books, troves of research papers and, of course, user content from our beloved social media platforms. The data and compute hungry models have been feverishly incorporating multi-modal data from audio and video libraries, and have been using 10s of thousands of Nvidia GPUs for months to train the state-of-the-art (SOTA) models. All this makes us wonder whether this exponential growth can last.
The challenges facing these LLMs are numerous but let’s investigate a few here.
- Cost and Scalability: Larger models can cost tens of millions of dollars to to train and serve, becoming a barrier to adoption by the swath of day-to-day applications. (See Cost of training GPT-4)
- Training Data Saturation: Publicly available datasets will exhaust soon enough and may need to rely on slowly generated user content. Only companies and agencies that have a steady source of new content will be able to generate improvements.
- Hallucinations: Models generating false and unsubstantiated information is going to be a deterrent with users expecting validation from authoritative sources before using for sensitive applications.
- Exploring unknowns: LLMs are now being used for applications beyond their original intent. For example LLMs have shown great ability in game play, scientific discovery and climate modeling. We will need new approaches to solve these complex situations.
Before we start getting too worried about the future, let’s examine how AI researchers are tirelessly working on ways to ensure continued progress. The Mixture-of-Experts (MoE) and Mixture-of-Agents (MoA) innovations show that hope is on the horizon.
First introduced in 2017, Mixture-of-Experts technique showed that multiple experts and a gating network that can pick a sparse set of experts can produce a vastly improved outcome with lower computational costs. The gating decision allows to turn off large pieces of the network enabling conditional computation, and specialization improves performance for language modeling and machine translational tasks.
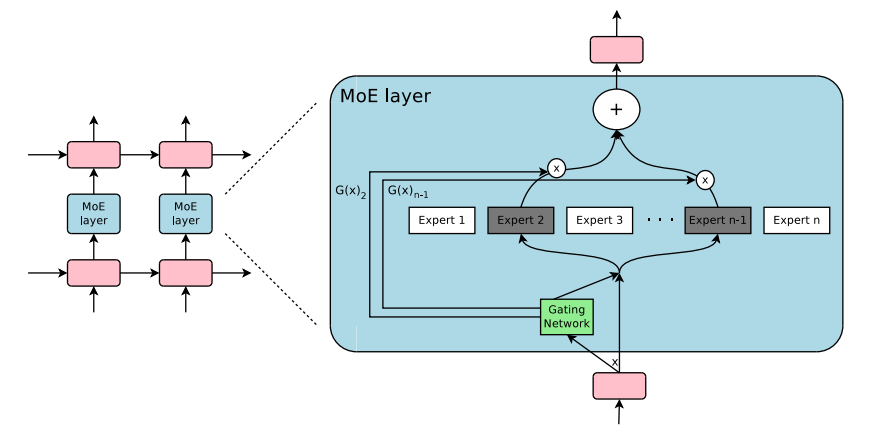
The figure above shows that a Mixture-of-Experts layer is incorporated in a recurrent neural network. The gating layer activates only two experts for the task and subsequently combines their output.
While this was demonstrated for select benchmarks, conditional computation has opened up an avenue to see continued improvements without resorting to ever growing model size.
Inspired by MOE, Mixture-of-Agents technique leverages multiple LLM to improve the outcome. The problem is routed through multiple LLMs aka agents that enhance the outcome at each stage and the authors have demonstrated that it produces a better outcome with smaller models versus the larger SOTA models.
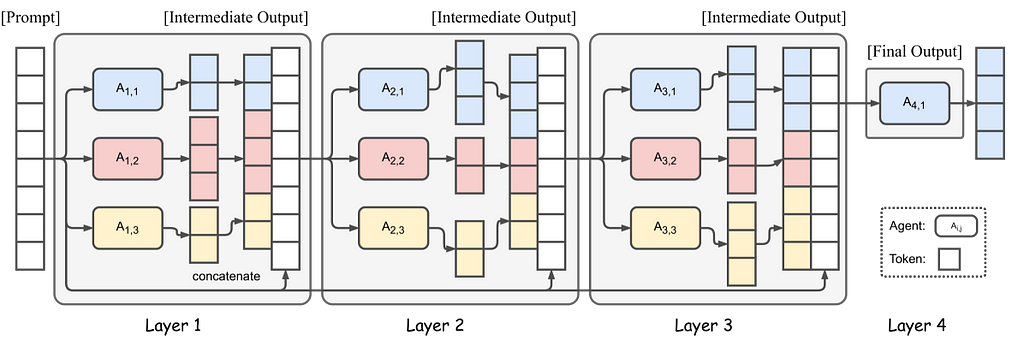
The figure shows 4 Mixture-of-Agents layers with 3 agents in each layer. Selecting appropriate LLMs for each layer is important to ensure proper collaboration and to produce high quality response. (Source)
{kind=link}
MOA relies on the fact that LLMs collaborating together produce better outputs as they can combine responses from other models. The role of LLMs is divided into proposers that generate diverse outputs and aggregators that can combine them to produce high-quality responses. The multi-stage approach will likely increase the Time to First Token (TTFT), so mitigating approaches will need to be developed to make them suitable for broad applications.
MOE and MOA have similar foundational elements but behave differently. MOE works on the concept of picking a set of experts to complete a job where the gating network has the task of picking the right set of experts. MOA works on teams building on the work of the previous teams, and improving the outcome at each stage.
Innovations for MOE and MOA have created a path of innovation where a combination of specialized components or models, collaborating and exchanging information, can continue to provide better outcomes even when linear scaling of model parameters and training datasets is no longer trivial.
While it is only with hindsight we will know whether the LLM innovations can last, I have been following the research in the field for insights. Seeing what is coming out of universities and research institutions, I am extremely bullish on what is next to come. I do feel we are just warming up for the onslaught of new capabilities and applications that will transform our lives. We don’t know what they are but we can be fairly certain that coming days will not fail to surprise us.
“We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run.”. -Amara’s Law
References
[1] Wang, J., Wang, J., Athiwaratkun, B., Zhang, C., & Zou, J. (2024). Mixture-of-Agents Enhances Large Language Model Capabilities. arXiv [Preprint]. https://arxiv.org/abs/2406.04692
[2] Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., & Dean, J. (2017). Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538.
MOE & MOA for Large Language Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.