
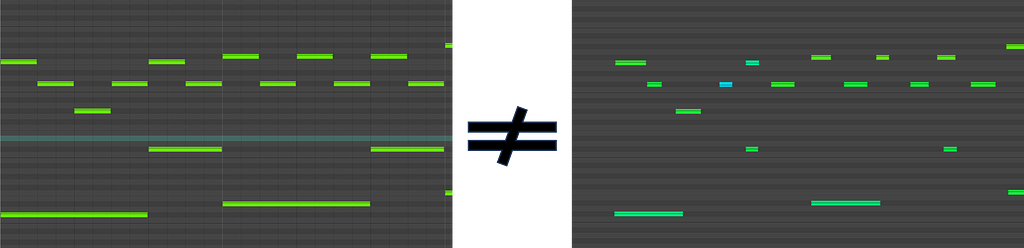
A fundamental difference: MIDI scores vs MIDI performances
Before starting any deep learning project with MIDI files, make sure you know the difference between MIDI scores and MIDI performances!
This article is for people planning or beginning to work with MIDI files. This format is widely used in the music community, and it caught the attention of computer music researchers due to the availability of datasets.
However, different types of information can be encoded in MIDI files. In particular, there is a big difference between MIDI scores and MIDI performances. Not being aware of this results in time wasted on a useless task or an incorrect choice of training data and approaches.
I will provide a basic introduction to the two formats and give hands-on examples of how to start working with them in Python.
What is MIDI?
MIDI was introduced as a real-time communication protocol between synthesizers. The main idea is to send a message every time a note is pressed (note on) on a MIDI keyboard and another message when the note is released (note off). Then the synthesizer on the receiving end will know what sound to produce.
Welcome to MIDI files!
If we collect and save all these messages (making sure to add their time position) then we have a MIDI file that we can use to reproduce a piece. Other than note-on and note-off, many other kinds of messages exist, for example specifying pedal information or other controllers.
You can think of plotting this information with a pianoroll.
Beware, this is not a MIDI file, but only a possible representation of its content! Some software (in this example Reaper) adds a small piano keyboard next to the pianoroll to make it easier to visually interpret.

How is a MIDI file created?
A MIDI file can be created mainly in two ways: 1) by playing on a MIDI instrument, 2) by manually writing into a sequencer (Reaper, Cubase, GarageBand, Logic) or a musical score editor (for example from MuseScore).
With each way of producing MIDI files comes also a different kind of file:
- playing on a MIDI instrument → MIDI performance
- manually writing the notes (sequencer or musical score) → MIDI score
We’ll now dive into each type, and then summarize their differences.
Before starting, a disclaimer: I will not focus specifically on how the information is encoded, but on what information can be extracted from the file. For example, when I say “ time is represented in seconds” it means that we can get seconds, even though the encoding itself is more complex.
MIDI performances
We can find 4 kinds of information in a MIDI performance:
- When the note start: note onset
- When the note end: note offset (or note duration computed as offset -onset)
- Which note was played: note pitch
- How “strong” was the key pressed: note velocity
Note onset and offset (and duration) are represented in seconds, corresponding to the seconds the notes were pressed and released by the person playing the MIDI instrument.
Note pitch is encoded with an integer from 0 (lowest) to 127 (highest); note that more notes can be represented than those that can be played by a piano; the piano range corresponds to 21–108.
Note velocity is also encoded with an integer from 0 (silence) to 127 (maximum intensity).
The vast majority of MIDI performances are piano performances because most MIDI instruments are MIDI keyboards. Other MIDI instruments (for example MIDI saxophones, MIDI drums, and MIDI sensors for guitar) exist, but they are not as common.
The biggest dataset of human MIDI performances (classical piano music) is the Maestro dataset by Google Magenta.
The main property of MIDI performances
A fundamental characteristic of MIDI performances is that there are never notes with exactly the same onset or duration (this is, in theory, possible but, in practice, extremely unlikely).
Indeed, even if they really try, players won’t be able to press two (or more) notes exactly at the same time, since there is a limit to the precision humans can obtain. The same is true for note durations. Moreover, this is not even a priority for most musicians, since time deviation can help to produce a more expressive or groovy feeling. Finally, consecutive notes will have some silence in between or partially overlap.
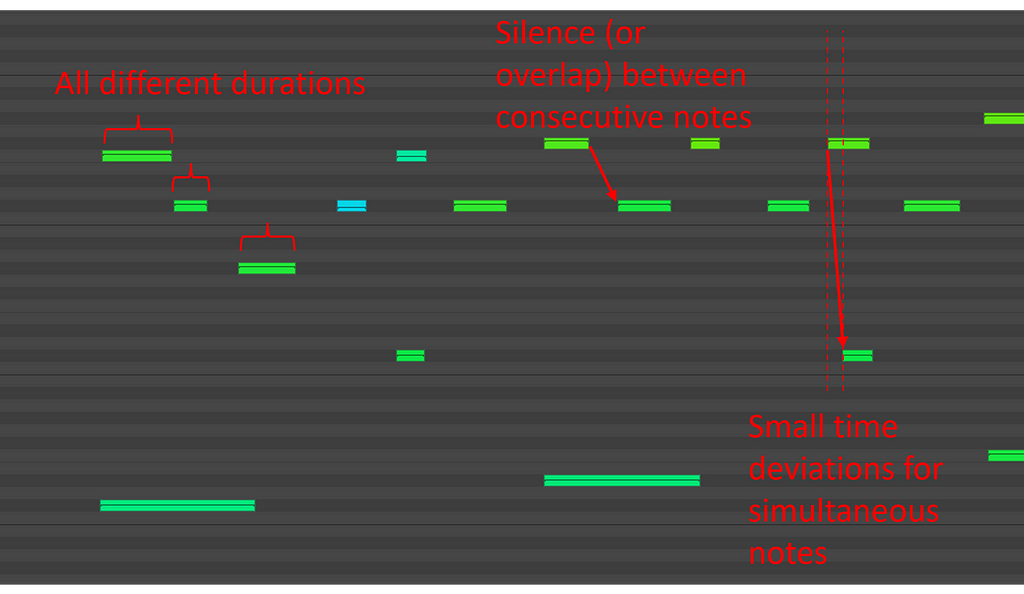
For this reason, MIDI performances are sometimes also called unquantized MIDI. Temporal positions are spread on a continuous time scale, and not quantized to discrete positions (for digital encoding reasons, it is technically a discrete scale, but extremely fine, thus we can consider it continuous).
Hands-on example
Let us look at a MIDI performance. We will use the ASAP dataset, available on GitHub.
In your favorite terminal (I’m using PowerShell on Windows), go to a convenient location and clone the repository.
git clone https://github.com/fosfrancesco/asap-dataset
We will also use the Python library Partitura to open the MIDI files, so you can install it in your Python environment.
pip install partitura
Now that everything is set, let’s open the MIDI file, and print the first 10 notes. Since this is a MIDI performance, we will use the load_midi_performance function.
from pathlib import Path
import partitura as pt
# set the path to the asap dataset (change it to your local path!)
asap_basepath = Path('../asap-dataset/')
# select a performance, here we use Bach Prelude BWV 848 in C#
performance_path = Path("Bach/Prelude/bwv_848/Denisova06M.mid")
print("Loading midi file: ", asap_basepath/performance_path)
# load the performance
performance = pt.load_performance_midi(asap_basepath/performance_path)
# extract the note array
note_array = performance.note_array()
# print the dtype of the note array (helpful to know how to interpret it)
print("Numpy dtype:")
print(note_array.dtype)
# print the first 10 notes in the note array
print("First 10 notes:")
print(performance.note_array()[:10])
The output of this Python program should look like this:
Numpy dtype:
[('onset_sec', '<f4'), ('duration_sec', '<f4'), ('onset_tick', '<i4'), ('duration_tick', '<i4'), ('pitch', '<i4'), ('velocity', '<i4'), ('track', '<i4'), ('channel', '<i4'), ('id', '<U256')]
First 10 notes:
[(1.0286459, 0.21354167, 790, 164, 49, 53, 0, 0, 'n0')
(1.03125 , 0.09765625, 792, 75, 77, 69, 0, 0, 'n1')
(1.1302084, 0.046875 , 868, 36, 73, 64, 0, 0, 'n2')
(1.21875 , 0.07942709, 936, 61, 68, 66, 0, 0, 'n3')
(1.3541666, 0.04166667, 1040, 32, 73, 34, 0, 0, 'n4')
(1.4361979, 0.0390625 , 1103, 30, 61, 62, 0, 0, 'n5')
(1.4361979, 0.04296875, 1103, 33, 77, 48, 0, 0, 'n6')
(1.5143229, 0.07421875, 1163, 57, 73, 69, 0, 0, 'n7')
(1.6380209, 0.06380209, 1258, 49, 78, 75, 0, 0, 'n8')
(1.6393229, 0.21484375, 1259, 165, 51, 54, 0, 0, 'n9')]
You can see that we have the onset and durations in seconds, pitch and velocity. Other fields are not so relevant for MIDI performances.
Onsets and durations are also represented in ticks. This is closer to the actual way this information is encoded in a MIDI file: a very short temporal duration (= 1 tick) is chosen, and all temporal information is encoded as a multiple of this duration. When you deal with music performances, you can typically ignore this information and use directly the information in seconds.
You can verify that there are never two notes with exactly the same onset or the same duration!
MIDI scores
Midi scores use a much richer set of MIDI messages to encode information such as time signature, key signature, bar, and beat positions.
For this reason, they resemble musical scores (sheet music), even though they still miss some vital information, for example, pitch spelling, ties, dots, rests, beams, etc…
The temporal information is not encoded in seconds but in more musically abstract units, like quarter notes.
The main property of MIDI scores
A fundamental characteristic of MIDI score is that all note onsets are aligned to a quantized grid, defined first by bar positions and then by recursive integer divisions (mainly by 2 and 3, but other divisions such as 5,7,11, etc…) are used for tuplets.
Hands-on example
We are now going to look at the score from Bach Prelude BWV 848 in C#, which is the score of the performance we loaded before. Partitura has a dedicated load_score_midi function.
from pathlib import Path
import partitura as pt
# set the path to the asap dataset (change it to your local path!)
asap_basepath = Path('../asap-dataset/')
# select a score, here we use Bach Prelude BWV 848 in C#
score_path = Path("Bach/Prelude/bwv_848/midi_score.mid")
print("Loading midi file: ", asap_basepath/score_path)
# load the score
score = pt.load_score_midi(asap_basepath/score_path)
# extract the note array
note_array = score.note_array()
# print the dtype of the note array (helpful to know how to interpret it)
print("Numpy dtype:")
print(note_array.dtype)
# print the first 10 notes in the note array
print("First 10 notes:")
print(score.note_array()[:10])
The output of this Python program should look like this:
Numpy dtype:
[('onset_beat', '<f4'), ('duration_beat', '<f4'), ('onset_quarter', '<f4'), ('duration_quarter', '<f4'), ('onset_div', '<i4'), ('duration_div', '<i4'), ('pitch', '<i4'), ('voice', '<i4'), ('id', '<U256'), ('divs_pq', '<i4')]
First 10 notes:
[(0. , 1.9958333 , 0. , 0.99791664, 0, 479, 49, 1, 'P01_n425', 480)
(0. , 0.49583334, 0. , 0.24791667, 0, 119, 77, 1, 'P00_n0', 480)
(0.5, 0.49583334, 0.25, 0.24791667, 120, 119, 73, 1, 'P00_n1', 480)
(1. , 0.49583334, 0.5 , 0.24791667, 240, 119, 68, 1, 'P00_n2', 480)
(1.5, 0.49583334, 0.75, 0.24791667, 360, 119, 73, 1, 'P00_n3', 480)
(2. , 0.99583334, 1. , 0.49791667, 480, 239, 61, 1, 'P01_n426', 480)
(2. , 0.49583334, 1. , 0.24791667, 480, 119, 77, 1, 'P00_n4', 480)
(2.5, 0.49583334, 1.25, 0.24791667, 600, 119, 73, 1, 'P00_n5', 480)
(3. , 1.9958333 , 1.5 , 0.99791664, 720, 479, 51, 1, 'P01_n427', 480)
(3. , 0.49583334, 1.5 , 0.24791667, 720, 119, 78, 1, 'P00_n6', 480)]
You can see that the onsets of the notes are all falling exactly on a grid. If we consider onset_quarter (the 3rd column) we can see that 16th notes fall every 0.25 quarters, as expected.

The duration is a bit more problematic. For example, in this score, a 16th note should have a quarter_duration of 0.25. However, we can see from the Python output that the duration is actually 0.24791667. What happened is that MuseScore, which was used to generate this MIDI file, shortened a bit each note. Why? Just to make the audio rendition of this MIDI file sound a bit better. And it does indeed, at the cost of causing many problems to the people using these files for Computer Music research. Similar problems also exist in widely used datasets, such as the Lakh MIDI Dataset.
MIDI scores vs MIDI performances
Given the differences between MIDI scores and MIDI performances we’ve seen, let me give you some generic guidelines that can help in correctly setting up your deep learning system.
Prefer MIDI scores for music generation systems, since the quantized note positions can be represented with a pretty small vocabulary, and other simplifications are possible, like only considering monophonic melodies.
Use MIDI performance for systems that target the way humans play and perceive music, for example, beat tracking systems, tempo estimators, and emotion recognition systems (focusing on expressive playing).
Use both kinds of data for tasks like score-following (input: performance, output: score) and expressive performance generation (input: score, output: performance).
Extra problems
I have presented the main differences between MIDI scores and MIDI performances. However, as often happens, things may be more complex.
For example, some datasets, like the AMAPS datasets, are originally MIDI scores, but the authors introduced time changes at every note, to simulate the time deviation of real human players (note that this only happens between notes at different time positions; all notes in a chord will still be perfectly simultaneous).
Moreover, some MIDI exports, like the one from MuseScore, will also try to make the MIDI score more similar to a MIDI performance, again by changing tempo indication if the piece changes tempo, by inserting a very small silence between consecutive notes (we saw this in the example before), and by playing grace notes as a very short note slightly before the reference note onset.
Indeed, grace notes constitute a very annoying problem in MIDI scores. Their duration is unspecified in musical terms, we just generically know that they should be “short”. And their onset is in the score the same one of the reference note, but this would sound very weird if we listed to an audio rendition of the MIDI file. Should we then shorten the previous note, or the next note to make space for the grace note?
Other embellishments are also problematic since there are no unique rules on how to play them, for example, how many notes should a trill contains? Should a mordent start from the actual note or the upper note?
Conclusion
MIDI files are great, because they explicitly provide information about the pitch, onset, and duration of every note. This means for example that, compared to audio files, models targeting MIDI data can be smaller and be trained with smaller datasets.
This comes at a cost: MIDI files, and symbolically encoded music in general, are complex formats to use since they encode so many kinds of information in many different ways.
To properly use MIDI data as training data, it is important to be aware of the kind of data that are encoded. I hope this article gave you a good starting point to learn more about this topic!
[All figures are from the author.]
MIDI Files as Training Data was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
MIDI Files as Training Data