
A study case of credit card fraud
1. Introduction
2. How does a model make predictions
3. Confusion Matrix
4. Metrics to Evaluate Model Performance
5. When to use what metrics
1. Introduction
Once we trained a supervised machine learning model to solve a classification problem, we’d be happy if this was the end of our work, and we could just throw them new data. We hope it will classify everything correctly. However, in reality, not all predictions that a model makes are correct. There is a famous quote well known in Data Science, created by a British Statistician that says:
“All models are wrong; some are useful.” CLEAR, James, 1976.
So, how do we know how good the model we have is? The short answer is that we do that by evaluating how correct the model’s predictions are. For that, there are several metrics that we could use.
2. How does a model make predictions? i.e., How does a model classify data?
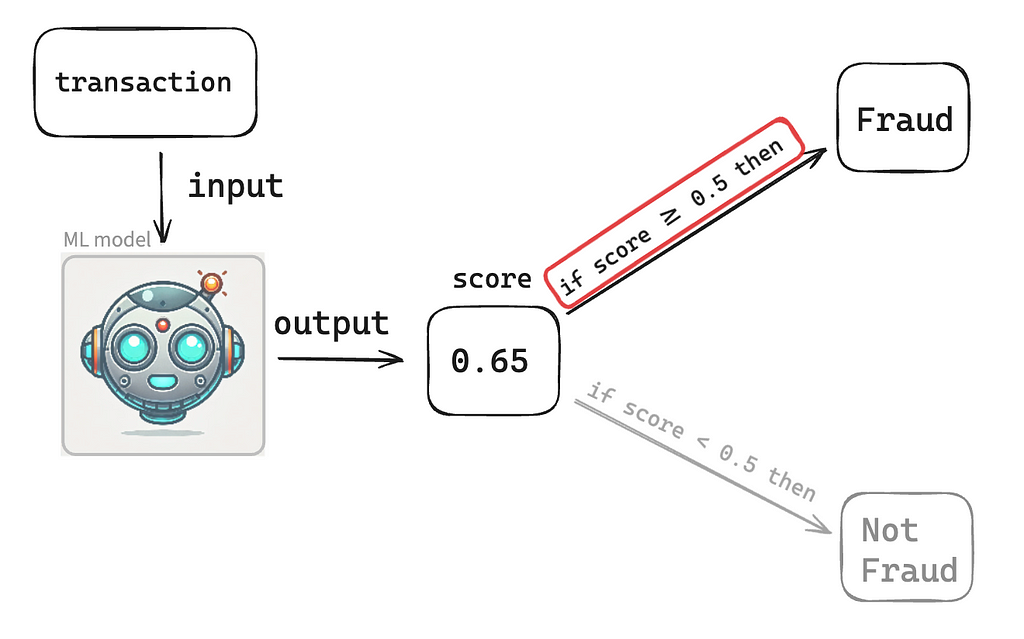
Let’s say we’ve trained a Machine Learning model to classify a credit card transaction and decide whether that particular transaction is Fraud or not Fraud. The model will consume the transaction data and give back a score that could be any number within the range of 0 to 1, e.g., 0.05, 0.24, 0.56, 0.9875. For this article, we’ll define a default threshold of 0.5, which means if the model gave a score lower than 0.5, then the model has classified that transaction as not Fraud (that’s a model prediction!). If the model gave a score greater or equal to 0.5, then the model classified that transaction as Fraud (that’s also a model prediction!).
In practice, we don’t work with the default of 0.5. We look into different thresholds to see what is more appropriate to optimize the model’s performance, but that discussion is for another day.
3. Confusion Matrix
The confusion matrix is a fundamental tool for visualizing the performance of a classification model. It helps in understanding the various outcomes of the predictions, which include:
- True Positive (TP)
- False Positive (FP)
- False Negative (FN)
- True Negative (TN)
Let’s break it down!
To evaluate a model’s effectiveness, we need to compare its predictions against actual outcomes. Actual outcomes are also known as “the reality.” So, a model could have classified a transaction as Fraud, and in fact, the customer asked for his money back on that same transaction, claiming that his credit card was stolen.
In that scenario, the model correctly predicted the transaction as Fraud, a True Positive (TP).
In Fraud detection contexts, the “positive” class is labeled as Fraud, and the “negative” class is labeled Non-Fraud.
A False Positive (FP), on the other hand, occurs when the model also classifies a transaction as Fraud, but in that case, the customer did not report any fraudulent activity on their credit card usage. So, in this transaction, the Machine Learning model made a mistake.
A True Negative (TN) is when the model classified the transaction as Not Fraud, and in fact, it was not Fraud. So, the model has made the correct classification.
A False Negative (FN) was when the model classified the transaction as Not Fraud. Still, it was Fraud (the customer reported fraudulent activity on their credit card related to that transaction). In this case, the Machine Learning model also made a mistake, but it’s a different type of error than a False Positive.
Let’s have a look at image 2

Let’s see a different case, maybe more relatable. A test was designed to tell whether a patient has COVID. See image 3.
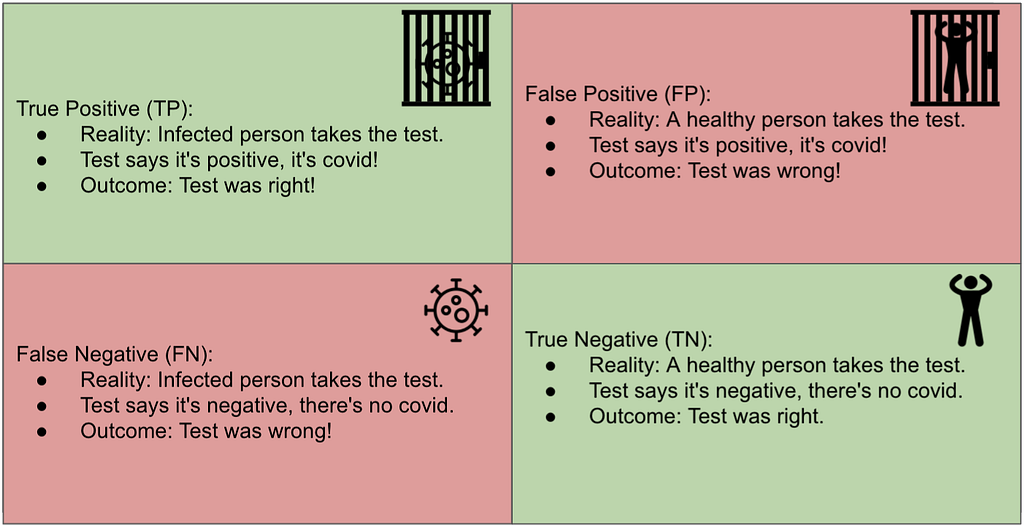
So, for every transaction, you could check whether it’s TP, FP, TN, or FN. And you could do this for thousands of millions of transactions and write the results down on a 2×2 table with all the counts of TP, FP, TN and FN. This table is also known as a Confusion Matrix.
Let’s say you compared the model predictions of 100,000 transactions against their actual outcomes and came up with the following Confusion Matrix (see image 4).

4. Metrics to Evaluate Model Performance
and what a confusion matrix is, we are ready to explore the metrics used to evaluate a classification model’s performance.
Precision = TP / (TP + FP)
It answers the question: What’s the proportion of correct predictions among all predictions? It reflects the proportion of predicted fraud cases that were Fraud.
In simple language: What’s the proportion of when the model called it Fraud, and it was Fraud?
Looking at the Confusion Matrix from image 4, we compute the Precision = 76.09% since Precision = 350 / (350 + 110).
Recall = TP / (TP + FN)
Recall is also known as True Positive Rate (TPR). It answers the question: What’s the proportion of correct predictions among all positive actual outcomes?
In simple language, what’s the proportion of times that the model caught the fraudster correctly in all actual fraud cases?
Using the Confusion Matrix from image 4, the Recall = 74.47%, since Recall = 350 / (350 + 120).
Alert Rate = (TP + FP) / (TP + FP + TN + FN)
Also known as Block Rate, this metric helps answer the question: What’s the proportion of positive predictions over all predictions?
In simple language: What proportion of times the model predicted something was Fraud?
Using the Confusion Matrix from image 4, the Alert Rate = 0.46%, since Alert Rate = (350 + 110) / (350 + 110 + 120 + 99420).
F1 Score = 2x (Precision x Recall) / (Precision + Recall)
The F1 Score is a harmonic mean of Precision and Recall. It is a balanced measure between Precision and Recall, providing a single score to assess the model.
Using the Confusion Matrix from image 4, the F1-Score = 75.27%, since F1-Score = 2*(76.09% * 74.47%) / (76.09% + 74.47%).
Accuracy = TP + TN / (TP + TN + FP + FN)
Accuracy helps answer this question: What’s the proportion of correctly classified transactions over all transactions?
Using the Confusion Matrix from image 4, the Accuracy = 99.77%, since Accuracy = (350 + 120) / (350 + 110 + 120 + 99420).

5. When to use what metric
Accuracy is a go-to metric for evaluating many classification machine learning models. However, accuracy does not work well for cases where the target variable is imbalanced. In the case of Fraud detection, there is usually a tiny percentage of the data that is fraudulent; for example, in credit card fraud, it’s usually less than 1% of fraudulent transactions. So even if the model says that all transactions are fraudulent, which would be very incorrect, or that all transactions are not fraudulent, which would also be very wrong, the model’s accuracy would still be above 99%.
So what to do in those cases? Precision, Recall, and Alert Rate. Those are usually the metrics that give a good perspective on the model performance, even if the data is imbalanced. Which one exactly to use might depend on your stakeholders. I worked with stakeholders that said, whatever you do, please keep a Precision of at least 80%. So in that case, the stakeholder was very concerned about the user experience because if the Precision is very low, that means there will be a lot of False Positives, meaning that the model would incorrectly block good customers thinking they are placing fraudulent credit card transactions.
On the other hand, there is a trade-off between Precision and Recall: the higher the Precision, the lower the Recall. So, if the model has a very high Precision, it won’t be great at finding all the fraud cases. In some sense, it also depends on how much a fraud case costs the business (financial loss, compliance problems, fines, etc.) vs. how many false positive cases cost the business (customer lifetime, which impacts business profitability).
So, in cases where the financial decision between Precision and Recall is unclear, a good metric to use is F1-Score, which helps provide a balance between Precision and Recall and optimizes for both of them.
Last but not least, the Alert Rate is also a critical metric to consider because it gives an intuition about the number of transactions the Machine Learning model is planning to block. If the Alert Rate is very high, like 15%, that means that from all the orders placed by customers, 15% will be blocked, and only 85% will be accepted. So if you have a business with 1,000,000 orders daily, the machine learning model would block 150,000 of them thinking they’re fraudulent transactions. That’s a massive amount of orders blocked, and it’s important to have an instinct about the percentage of fraud cases. If fraud cases are about 1% or less, then a model blocking 15% is not only making a lot of mistakes but also blocking a big part of the business revenue.
6. Conclusion
Understanding these metrics allows data scientists and analysts to interpret the results of classification models better and enhance their performance. Precision and Recall offer more insights into the effectiveness of a model than mere accuracy, not only, but especially in fields like fraud detection where the class distribution is heavily skewed.
*Images: Unless otherwise noted, all images are by the author. Image 1’s robot face was created by DALL-E, and it’s for public use.
Metrics to Evaluate a Classification Machine Learning Model was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Metrics to Evaluate a Classification Machine Learning Model
Go Here to Read this Fast! Metrics to Evaluate a Classification Machine Learning Model