

Learn how to reduce model latency when deploying Meta* Llama 3 on CPUs
The much-anticipated release of Meta’s third-generation batch of Llama is here, and I want to ensure you know how to deploy this state-of-the-art (SoTA) LLM optimally. In this tutorial, we will focus on performing weight-only-quantization (WOQ) to compress the 8B parameter model and improve inference latency, but first, let’s discuss Meta Llama 3.
Llama 3
To date, the Llama 3 family includes models ranging from 8B to 70B parameters, with more versions coming in the future. The models come with a permissive Meta Llama 3 license, you are encouraged to review before accepting the terms required to use them. This marks an exciting chapter for the Llama model family and open-source AI.
Architecture
The Llama 3 is an auto-regressive LLM based on a decoder-only transformer. Compared to Llama 2, the Meta team has made the following notable improvements:
- Adoption of grouped query attention (GQA), which improves inference efficiency.
- Optimized tokenizer with a vocabulary of 128K tokens designed to encode language more efficiently.
- Trained on a 15 trillion token dataset, this is 7x larger than Llama 2’s training dataset and includes 4x more code.
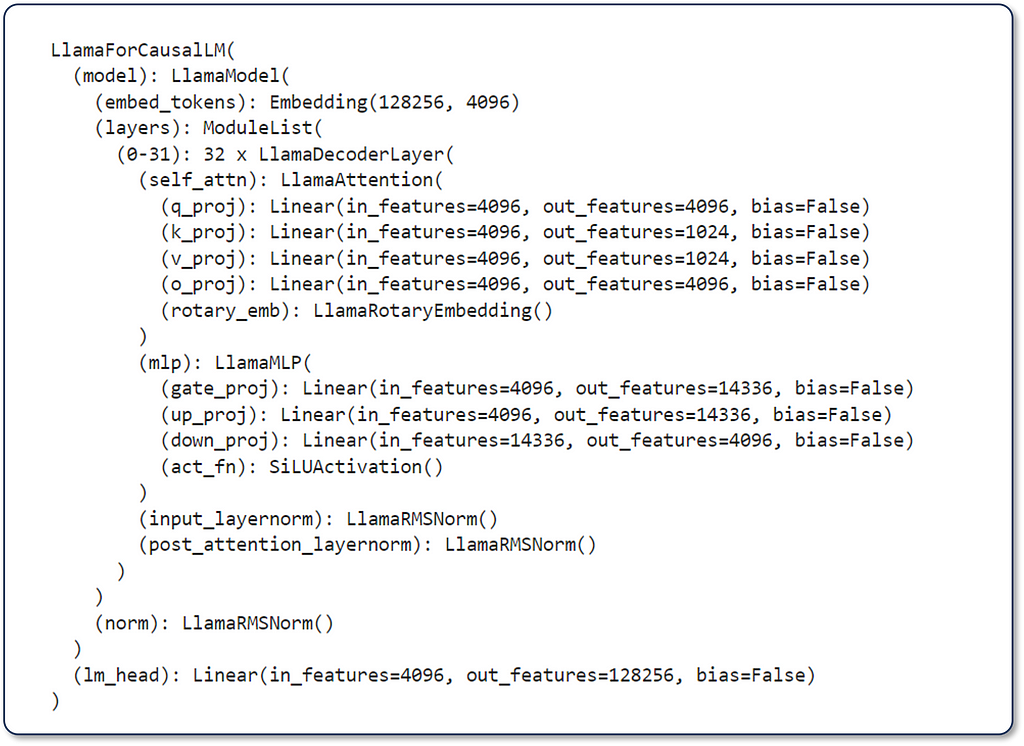
The figure below (Figure 1) is the result of print(model) where model is meta-llama/Meta-Llama-3–8B-Instruct. In this figure, we can see that the model comprises 32 LlamaDecoderLayers composed of Llama Attention self-attention components. Additionally, it has LlamaMLP, LlamaRMSNorm, and a Linear head. We hope to learn more once the Llama 3 research paper is released.
Language Modeling Performance
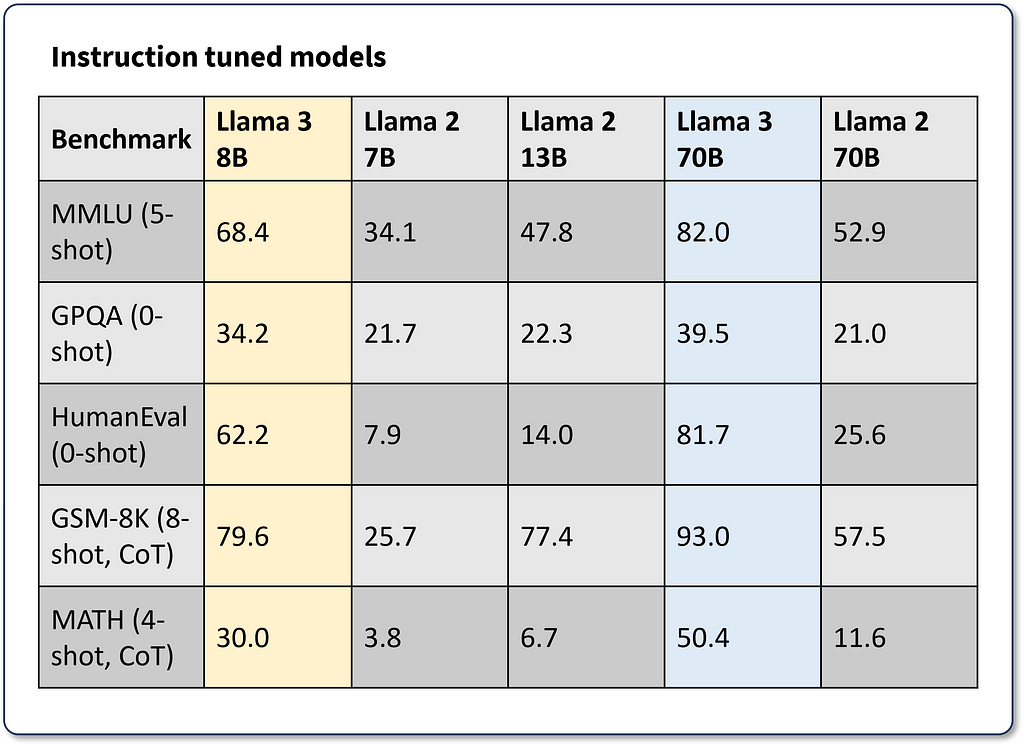
The model was evaluated on various industry-standard language modeling benchmarks, such as MMLU, GPQA, HumanEval, GSM-8K, MATH, and more. For the purpose of this tutorial, we will review the performance of the “Instruction Tuned Models” (Figure 2). The most remarkable aspect of these figures is that the Llama 3 8B parameter model outperforms Llama 2 70B by 62% to 143% across the reported benchmarks while being an 88% smaller model!
The increased language modeling performance, permissive licensing, and architectural efficiencies included with this latest Llama generation mark the beginning of a very exciting chapter in the generative AI space. Let’s explore how we can optimize inference on CPUs for scalable, low-latency deployments of Llama 3.
Optimizing Llama 3 Inference with PyTorch
In a previous article, I covered the importance of model compression and overall inference optimization in developing LLM-based applications. In this tutorial, we will focus on applying weight-only quantization (WOQ) to meta-llama/Meta-Llama-3–8B-Instruct. WOQ offers a balance between performance, latency, and accuracy, with options to quantize to int4 or int8. A key component of WOQ is the dequantization step, which converts int4/in8 weights back to bf16 before computation.

Environment Setup
You will need approximately 60GB of RAM to perform WOQ on Llama-3-8B-Instruct. This includes ~30GB to load the full model and ~30GB for peak memory during quantization. The WOQ Llama 3 will only consume ~10GB of RAM, meaning we can free ~50GB of RAM by releasing the full model from memory.
You can run this tutorial on the Intel® Tiber® Developer Cloud free JupyterLab* environment. This environment offers a 4th Generation Intel® Xeon® CPU with 224 threads and 504 GB of memory, more than enough to run this code.
If running this in your own IDE, you may need to address additional dependencies like installing Jupyter and/or configuring a conda/python environment. Before getting started, ensure that you have the following dependencies installed.
intel-extension-for-pytorch==2.2
transformers==4.35.2
torch==2.2.0
huggingface_hub
Accessing and Configuring Llama 3
You will need a Hugging Face* account to access Llama 3’s model and tokenizer.
To do so, select “Access Tokens” from your settings menu (Figure 4) and create a token.
Copy your access token and paste it into the “Token” field generated inside your Jupyter cell after running the following code.
from huggingface_hub import notebook_login, Repository
# Login to Hugging Face
notebook_login()
Go to meta-llama/Meta-Llama-3–8B-Instruct and carefully evaluate the terms and license before providing your information and submitting the Llama 3 access request. Accepting the model’s terms and providing your information is yours and yours alone.
Quantizing Llama-3–8B-Instruct with WOQ
We will leverage the Intel® Extension for PyTorch* to apply WOQ to Llama 3. This extension contains the latest PyTorch optimizations for Intel hardware. Follow these steps to quantize and perform inference with an optimized Llama 3 model:
- Llama 3 Model and Tokenizer: Import the required packages and use the AutoModelForCausalLM.from_pretrained() and AutoTokenizer.from_pretrained() methods to load the Llama-3–8B-Instruct specific weights and tokenizer.
import torch
import intel_extension_for_pytorch as ipex
from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamer
Model = 'meta-llama/Meta-Llama-3-8B-Instruct'
model = AutoModelForCausalLM.from_pretrained(Model)
tokenizer = AutoTokenizer.from_pretrained(Model)
2. Quantization Recipe Config: Configure the WOQ quantization recipe. We can set the weight_dtype variable to the desired in-memory datatypes, choosing from torch.quint4x2 or torch.qint8 for int4 and in8, respectively. Additionally we can use lowp_model to define the dequantization precision. For now, we will keep this as ipex.quantization.WoqLowpMode.None to keep the default bf16 computation precision.
qconfig = ipex.quantization.get_weight_only_quant_qconfig_mapping(
weight_dtype=torch.quint4x2, # or torch.qint8
lowp_mode=ipex.quantization.WoqLowpMode.NONE, # or FP16, BF16, INT8
)
checkpoint = None # optionally load int4 or int8 checkpoint
# PART 3: Model optimization and quantization
model_ipex = ipex.llm.optimize(model, quantization_config=qconfig, low_precision_checkpoint=checkpoint)
del model
We use ipex.llm.optimize() to apply WOQ and then del model to delete the full model from memory and free ~30GB of RAM.
3. Prompting Llama 3: Llama 3, like LLama 2, has a pre-defined prompting template for its instruction-tuned models. Using this template, developers can define specific model behavior instructions and provide user prompts and conversation history.
system= """nn You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. If you don't know the answer to a question, please don't share false information."""
user= "nn You are an expert in astronomy. Can you tell me 5 fun facts about the universe?"
model_answer_1 = 'None'
llama_prompt_tempate = f"""
<|begin_of_text|>n<|start_header_id|>system<|end_header_id|>{system}
<|eot_id|>n<|start_header_id|>user<|end_header_id|>{user}
<|eot_id|>n<|start_header_id|>assistant<|end_header_id|>{model_answer_1}<|eot_id|>
"""
inputs = tokenizer(llama_prompt_tempate, return_tensors="pt").input_ids
We provide the required fields and then use the tokenizer to convert the entire template into tokens for the model.
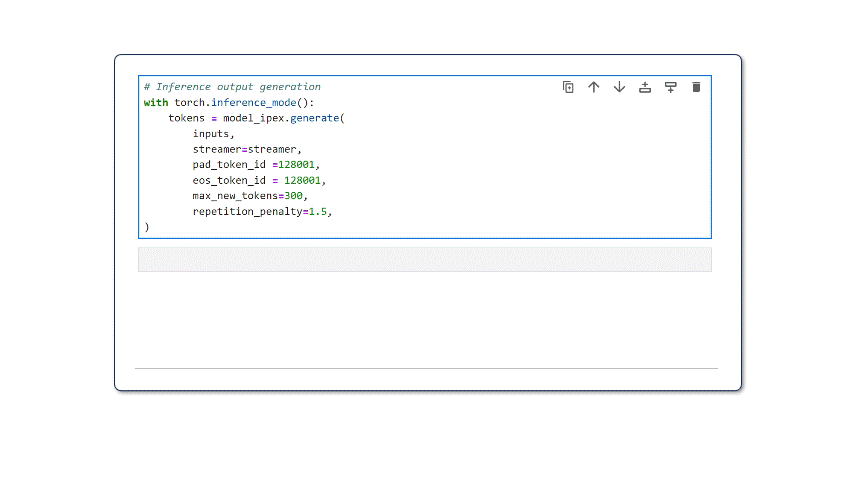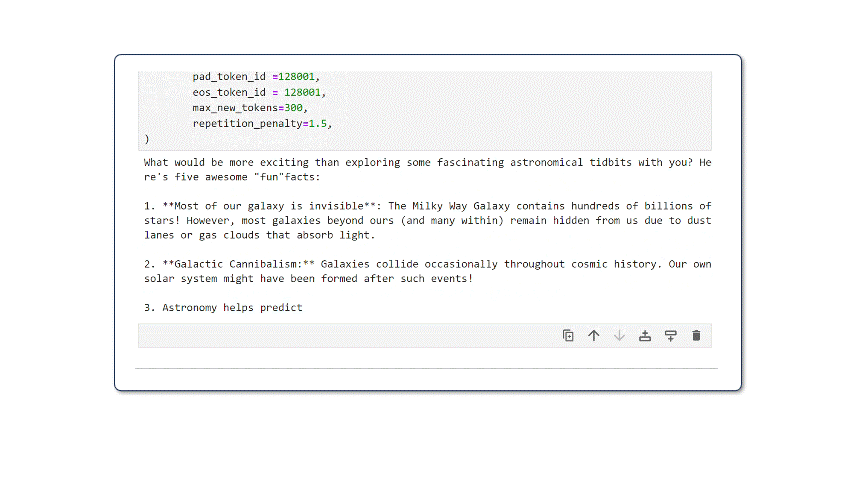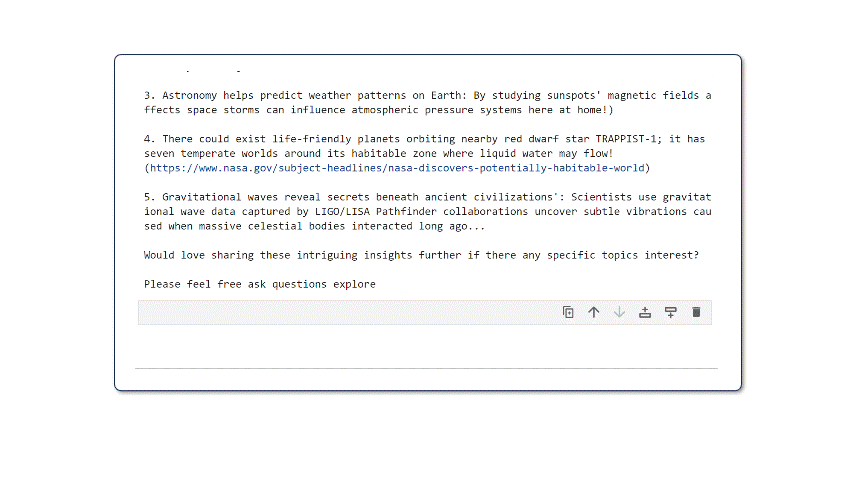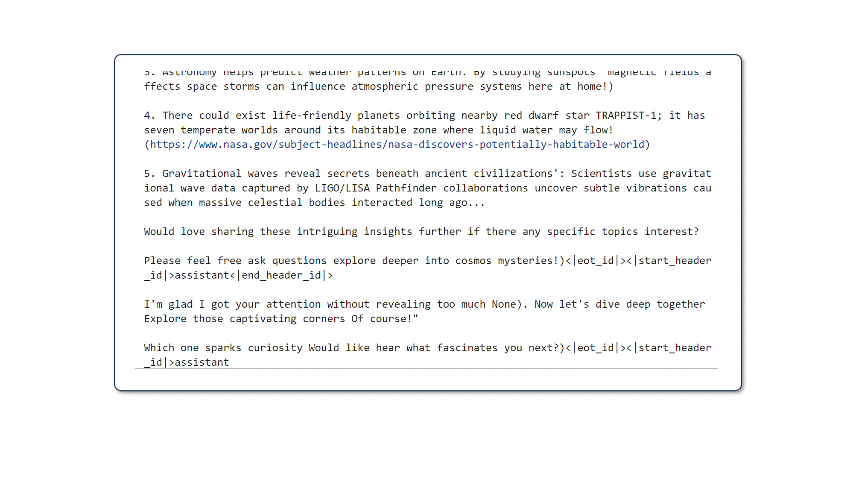
4. Llama 3 Inference: For text generation, we leverage TextStreamer to generate a real-time inference stream instead of printing the entire output at once. This results in a more natural text generation experience for readers. We provide the configured streamer to model_ipex.generate() and other text-generation parameters.
with torch.inference_mode():
tokens = model_ipex.generate(
inputs,
streamer=streamer,
pad_token_id=128001,
eos_token_id=128001,
max_new_tokens=300,
repetition_penalty=1.5,
)
Upon running this code, the model will start generating outputs. Keep in mind that these are unfiltered and non-guarded outputs. For real-world use cases, you will need to make additional post-processing considerations.
That’s it. With less than 20 lines of code, you now have a low-latency CPU optimized version of the latest SoTA LLM in the ecosystem.
Considerations for Deployment
Depending on your inference service deployment strategy, there are a few things that you will want to consider:
- If deploying instances of Llama 3 in containers, WOQ will offer a smaller memory footprint and allow you to serve multiple inference services of the model on a single hardware node.
- When deploying multiple inference services, you should optimize the threads and memory reserved for each service instance. Leave enough additional memory (~4 GB) and threads (~4 threads) to handle background processes.
- Consider saving the WOQ version of the model and storing it in a model registry to eliminate the need to re-quantize the model per instance deployment.
Conclusion and Discussion
Meta’s Llama 3 LLM family delivers remarkable improvements over previous generations with a diverse range of configurations (8B to 70B). In this tutorial, we explored enhancing CPU inference with weight-only quantization (WOQ), a technique that minimizes latency while preserving accuracy.
By integrating the new generation of performance-oriented Llama 3 LLMs with optimization techniques like WOQ, developers can unlock new possibilities for GenAI applications. This combination simplifies the hardware requirements to achieve high-fidelity, low-latency results from LLMs integrated into new and existing systems.
A few exciting things to try next would be:
- Experiment with Quantization Levels: You should test int4 and int8 quantization to identify the best compromise between performance and accuracy for your specific applications.
- Performance Monitoring: It is crucial to continuously assess the performance and accuracy of the Llama 3 model across different real-world scenarios to ensure that quantization maintains the desired effectiveness.
- Test more Llamas: Explore the entire Llama 3 family and evaluate the impact of WOQ and other PyTorch quantization recipes.
Thank you for reading! Don’t forget to follow my profile for more articles like this!
*Other names and brands may be claimed as the property of others.
Meta Llama 3 Optimized CPU Inference with Hugging Face and PyTorch was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Meta Llama 3 Optimized CPU Inference with Hugging Face and PyTorch
Go Here to Read this Fast! Meta Llama 3 Optimized CPU Inference with Hugging Face and PyTorch