We can significantly accelerate LLMs next token generation by merging consecutive pairs of tokens using SLERP, reducing the computing power needed to perform the full prediction.

TL;DR:
This article presents a novel approach to accelerating Large Language Models (LLMs) inference by merging tokens using Spherical Linear Interpolation (SLERP). By reducing the sequence length while maintaining quality, this technique offers significant speed-ups in LLM inference, addressing the computational challenges posed by longer sequences. The method is still raw but highlights a dual world for LLM with one set up for training and one for predicting.
Background:
LLMs have revolutionized natural language processing tasks by exhibiting remarkable generative abilities. However, their effectiveness comes at a cost — computational resources. As LLMs process longer sequences, the quadratic scaling of transformer computations becomes increasingly prohibitive. Traditional methods to mitigate this, such as caching and quantization, have limitations. Therefore, there is a need for innovative approaches to speed up LLM inference without compromising too much quality.
The current method to generate a token during inference is a brute force approach, essentially a transposition of the training methodology. While this methodology has proven effective for training, it may not be the most efficient for inference tasks. Thus, there is an opportunity to develop a new inference methodology dedicated specifically to generating tokens during inference, which could optimize the process and further enhance the efficiency of LLMs. This highlights the importance of exploring alternative techniques to address the computational challenges faced by LLM inference.
Recently, the mergekit library proposed to merge networks’ weights using the SLERP methods which tends to yield better results. Inspired by this work, I decided to see if could merge the tokens inside a sequence to produce a smaller sequence to process while predicting the next token.
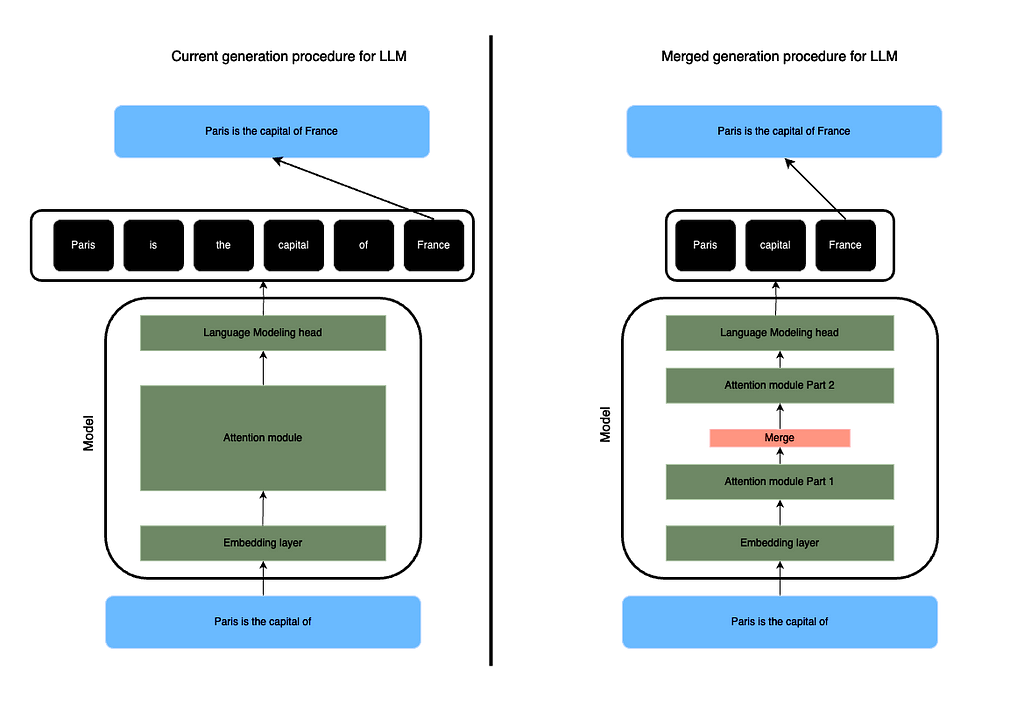
Merging Sequence with SLERP:
The proposed method involves modifying the forward pass of LLMs to merge tokens using Spherical Linear Interpolation (SLERP), a technique borrowed from computer graphics and animation. Unlike simple averaging techniques, SLERP preserves the spherical aspects of token dimensions, offering a more nuanced interpolation. The merging procedure entails several steps to efficiently condense the input sequence:
Sequence Length Adjustment:
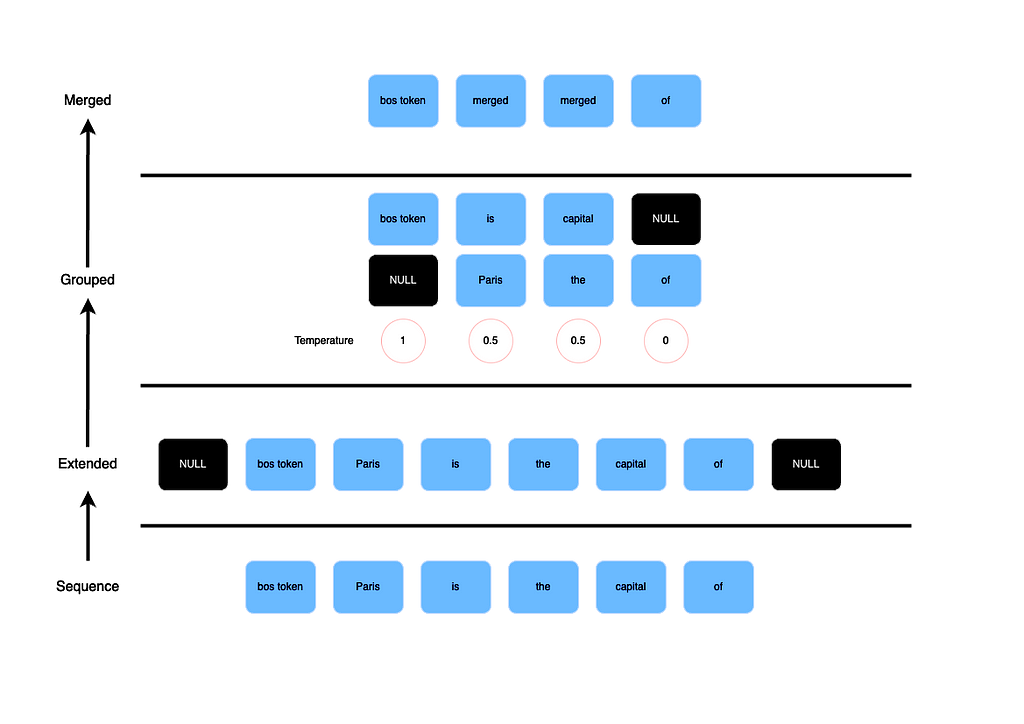
Initially, the input sequence undergoes adjustments based on its length:
- Sequences with a length less than 3 remain unchanged.
- For odd-length sequences, two null tokens are added, one at the beginning and one at the end
- Even-length sequences receive an additional null token, positioned at the penultimate position.
By doing so, we ensure that the first and last token in the context are preserved.
Pair Formation:
The adjusted sequence is then formatted into pairs of consecutive tokens. This process prepares the data for aggregation.
Aggregation with SLERP:
Each pair of tokens undergoes aggregation using SLERP, effectively reducing the sequence length by half (not exactly as we add and preserve some extra tokens). SLERP interpolates between the two vectors representing consecutive tokens. This creates a new vector.
To do so efficiently, I recreated all the SLERP functions in native pytorch. However, the code might be under optimized.
Layer Cutoff and Prompt Preservation:
The merging process can occur at different levels of the model architecture, referred to as “layer cutoff.” Additionally, to preserve the integrity of prompts, a portion of the sequence at the beginning and/or end can be designated to remain unchanged. This is particularly useful for Instruct-based Models where the starting part of the prompt should always be remembered.
This innovative approach offers a nuanced solution to the computational challenges associated with LLM inference, promising significant speed-ups without sacrificing quality or accuracy.
What it means ?
Concretely, in a LLM, the forward call takes as input a sequence of token of shape (batch_size, sequence length). The embedding layer creates a sequence of shape (batch size, sequence length, dimension). Each attention module takes this sequence as input. At a given attention layer, you can merge the tokens creating a sequence of shape (batch size, k, dimension) where k is the compressed sequence length. The choice of the layer where to apply this is the “layer cutoff”.
The next attention modules will no longer need to compute a (sequence length, sequence length) attention matrix but a smaller one as k is strictly inferior to the original sequence length.
Hence, the merging could occur at different level of the model architecture. This parameter is referred as “layer cutoff”. Also, to ensure that a prompt is not completely merged, you can define a part of the sequence at the beginning and/or at the end to be kept unchanged. It is more efficient for Instruct-based Models where the starting part of the prompt should be always reminded.
One downside of this methodology is that it strongly relies on the underlying forward pass of the used model, requiring you to carefully rewrite the “merged” process depending on the chosen model. Another downside is the necessity of recomputing attention masks and possibly positional embeddings at each step.
Results:
Experiments conducted on a Mistral 7B Instruct V0.2 model demonstrate promising outcomes. By comparing predictions between the base model and various merged models at different layer cutoffs, it was observed that merging tokens did not significantly impact prediction quality. Moreover, the merged models exhibited notable speed-ups in inference time, particularly at shallower layers. The technique also showcased its effectiveness in handling longer sequences, making it applicable across a wide range of use cases.
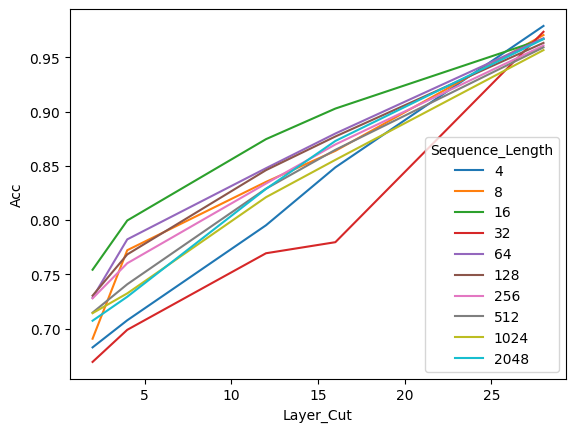
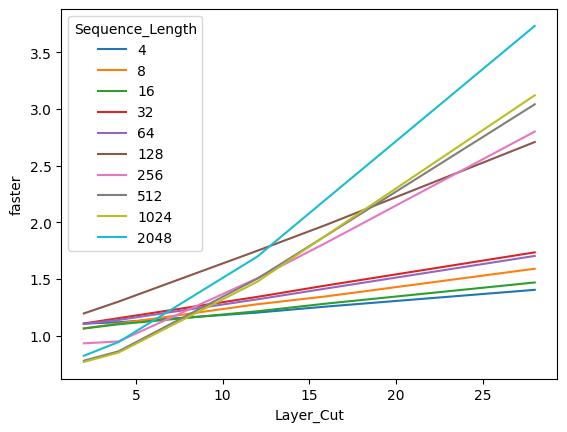
One downside is that I did not succeed at making the forward call the most optimized. Hence, there are probably many optimizations to find by rethinking the process.
I also tested a merged version of Mistral Instruct v0.2 on the AlpacaEval dataset. I apply the merging at the 20th attention module. The results are really encouraging as the models outperforms Falcon 7B, Gemma 7B and nous-hermes-13b. It shows that merging without rethinking the positional encodings returns a model that speaks more with an increase of 600 tokens generated on average. I tried to reimplement the positional encoding procedure but failed.

In summary, merging tokens with SLERP is a strong candidate solution to the computational challenges associated with LLM inference. By striking a balance between speed and quality, this approach is just about rewriting the forward loop.
Using it:
I prepared a repo with a simple notebook to play with it here : https://github.com/samchaineau/llm_slerp_generation
Using a new class where the foraward call is adapted, you can easily pass the LLM to a generation pipeline and use it on your dataset. So far my experiments are limited to a Mistral 7B model but I would like to extend it to other architectures to see whether the performances maintain.
All of the resources are in and you can reach out to me if you would like to test it on another LLM.
Conclusion:
The merging tokens with SLERP technique should be explored for accelerating LLM inference. With further optimization and exploration, it holds the potential to improve the efficiency and scalability of natural language processing tasks.
If you work in the AI field and are willing to bring this to the next level : reach out to me !
Github link : https://github.com/samchaineau/llm_slerp_generation
HuggingFace profile : https://huggingface.co/samchain
Works that are related and inspiring :
– Token Merging Stable Diffusion (paper) : https://arxiv.org/abs/2303.17604
– Token Merging Stable Diffusion (library) : https://huggingface.co/docs/diffusers/optimization/tome
– Token Merging NLP (paper) : https://llm-random.github.io/posts/mixture_of_tokens/
Unless otherwise noted, all images are by the author.
Merging tokens to accelerate LLM inference with SLERP was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Merging tokens to accelerate LLM inference with SLERP
Go Here to Read this Fast! Merging tokens to accelerate LLM inference with SLERP