Causal AI, exploring the integration of causal reasoning into machine learning

What is this series of articles about?
Welcome to my series on Causal AI, where we will explore the integration of causal reasoning into machine learning models. Expect to explore a number of practical applications across different business contexts.
In the last article we covered optimising non-linear treatment effects in pricing and promotions. This time round we will cover measuring the intrinsic causal influence of your marketing campaigns.
If you missed the last article on non-linear treatment effects in pricing and promotions, check it out here:
Optimising Non-Linear Treatment Effects in Pricing and Promotions
Introduction
In this article I will help you understand how you can measure the intrinsic causal influence of your marketing campaigns.
The following aspects will be covered:
- What are the challenges when it comes to marketing measurement?
- What is intrinsic causal influence and how does it work?
- A worked case study in Python showcasing how we can use intrinsic causal influence to give marketing campaigns the credit they deserve.
The full notebook can be found here:
What are the challenges when it comes to marketing measurement?
What are the different types of marketing campaigns?
Organisations use marketing to grow their business by acquiring new customers and retaining existing ones. Marketing campaigns are often split into 3 main categories:
- Brand
- Performance
- Retention
Each one has it’s own unique challenges when it comes to measurement — Understanding these challenges is crucial.
Brand campaigns
The aim of brand campaigns is to raise awareness of your brand in new audiences. They are often run across TV and social media, with the latter often in the format of a video. They don’t usually have a direct call-to-action e.g. “our product will last you a lifetime”.
The challenge with measuring TV is immediately obvious — We can’t track who has seen a TV ad! But we also have similar challenges when it’s comes to social media — If I watch a video on Facebook and then organically visit the website and purchase the product the next day it is very unlikely we will be able to tie these two events together.
There is also a secondary challenge of a delayed effect. When raising awareness in new audiences, it might take days/weeks/months for them to get to the point where they consider purchasing your product.
There is a debatable argument that brand campaigns do all the hard work — However, when it comes to marketing measurement, they often get undervalued because of some of the challenges we highlighted above.
Performance campaigns
In general performance campaigns are aimed at customers in-market for your product. They run across paid search, social and affiliate channels. They usually have a call-to-action e.g. “click now to get 5% off your first purchase”.
When it comes to performance campaigns it isn’t immediately obvious why they are challenging to measure. It’s very likely that we will be able to link the event of a customer clicking on a performance campaign and that customer purchasing that day.
But would they have clicked if they weren’t already familiar with the brand? How did they get familiar with the brand? If we hadn’t of shown them the campaign, would they have purchased organically anyway? These are tough questions to answer from a data science perspective!
Retention campaigns
The other category of campaigns is retention. This is marketing aimed at retaining existing customers. We can usually run AB tests to measure these campaigns.
Acquisition marketing graph
It is common to refer to brand and performance campaigns as acquisition marketing. As I mentioned earlier, it is challenging to measure brand and performance campaigns — We often undervalue brand campaigns and overvalue performance campaigns.
The graph below is a motivating (but simplified) example of how acquisition marketing works:

How can we (fairly) estimate how much each node contributed to revenue? This is where intrinsic causal influence comes into the picture — Lets’ dive into what it is in the next section!
What is intrinsic causal influence and how does it work?
Where does the concept come from?
The concept was originally proposed in a paper back in 2020:
Quantifying intrinsic causal contributions via structure preserving interventions
It is implemented in the GCM module within the python package DoWhy:
Quantifying Intrinsic Causal Influence – DoWhy documentation
I personally found the concept quite hard to grasp initially, so in the next section let’s break it down step by step.
Recap on causal graphs
Before we try and understand intrinsic causal influence, it is important to have an understanding of causal graphs, structural causal models (SCM) and additive noise models (ANM). My article earlier in the series should help bring you up to speed:
Using Causal Graphs to answer causal questions
As a reminder, each node in a causal graph can be seen as the target in a model where it’s direct parents are used as features. It is common to use an additive noise model for each non-root node:
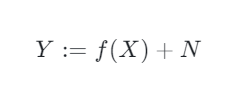
What really is intrinsic causal influence?
Now we have recapped causal graphs, let’s start to understand what intrinsic causal influence really is…
The dictionary definition of intrinsic is “belonging naturally”. In my head I think of a funnel, and the stuff at the top of the funnel are doing the heavy lifting — We want to attribute them the causal influence that they deserve.
Let’s take the example graph below to help us start to unpick intrinsic causal influence further:
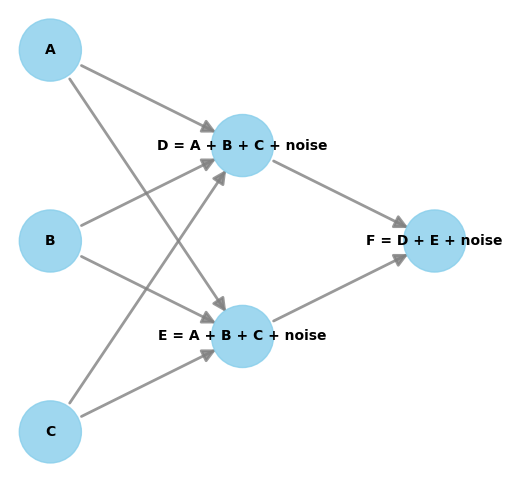
- A, B and C are root nodes.
- D is a non-root node, which we can model using it’s direct parents (A, B, C) and a noise term.
- E is a non-root node, which similar to D, we can model using it’s direct parents (A, B, C) and a noise term.
- F is our target node, which we can model using it’s direct parents (D, E) and a noise term.
Let’s focus on node D. It inherits some of it’s influence on node F from node A, B and C. The intrinsic part of it’s influence on node F comes from the noise term. Therefore we are saying that each nodes noise term can be used to estimate the intrinsic causal influence on a target node. It’s worth noting that root nodes are just made up of noise.
In the case study, we will delve deeper into exactly how to calculate intrinsic causal influence.
How can it help us measure our marketing campaigns?
Hopefully you can already see the link between the acquisition marketing example and intrinsic causal influence — Can intrinsic causal infleunce help us stop undervaluing brand campaigns and stop overvaluing performance campaigns? Let’s find out in the case study!
Case study
Background
It’s coming towards the end of the year and the Director of Marketing is coming under pressure from the Finance team to justify why she plans to spend so much on marketing next year. The Finance team use a last click model in which revenue is attributed to the last thing a customer clicked on. They question why they even need to spend anything on TV when everyone comes through organic or social channels!
The Data Science team are tasked with estimating the intrinsic causal influence of each marketing channel.
Setting up the Graph (DAG)
We start by setting up a DAG using expert domain knowledge, re-using the marketing acquisition example from earlier:
# Create node lookup for channels
node_lookup = {0: 'Demand',
1: 'TV spend',
2: 'Social spend',
3: 'Organic clicks',
4: 'Social clicks',
5: 'Revenue'
}
total_nodes = len(node_lookup)
# Create adjacency matrix - this is the base for our graph
graph_actual = np.zeros((total_nodes, total_nodes))
# Create graph using expert domain knowledge
graph_actual[0, 3] = 1.0 # Demand -> Organic clicks
graph_actual[0, 4] = 1.0 # Demand -> Social clicks
graph_actual[1, 3] = 1.0 # Brand spend -> Organic clicks
graph_actual[2, 3] = 1.0 # Social spend -> Organic clicks
graph_actual[1, 4] = 1.0 # Brand spend -> Social clicks
graph_actual[2, 4] = 1.0 # Social spend -> Social clicks
graph_actual[3, 5] = 1.0 # Organic clicks -> Revenue
graph_actual[4, 5] = 1.0 # Social clicks -> Revenue
In essence, the last click model which the finance team are using only uses the direct parents of revenue to measure marketing.
Data generating process
We create some samples of data following the data generating process of the DAG:
- 3 root nodes made up of noise terms; Demand, Brand spend and Social spend.
- 2 non-root nodes, both inheriting influence from the 3 root nodes plus some noise terms; Organic clicks, Social clicks.
- 1 target nodes, inheriting influence from the 2 non-root nodes plus a noise term; Revenue
# Create dataframe with 1 column per code
df = pd.DataFrame(columns=node_lookup.values())
# Setup data generating process
df[node_lookup[0]] = np.random.normal(100000, 25000, size=(20000)) # Demand
df[node_lookup[1]] = np.random.normal(100000, 20000, size=(20000)) # Brand spend
df[node_lookup[2]] = np.random.normal(100000, 25000, size=(20000)) # Social spend
df[node_lookup[3]] = 0.75 * df[node_lookup[0]] + 0.50 * df[node_lookup[1]] + 0.25 * df[node_lookup[2]] + np.random.normal(loc=0, scale=2000, size=20000) # Organic clicks
df[node_lookup[4]] = 0.30 * df[node_lookup[0]] + 0.50 * df[node_lookup[1]] + 0.70 * df[node_lookup[2]] + np.random.normal(100000, 25000, size=(20000)) # Social clicks
df[node_lookup[5]] = df[node_lookup[3]] + df[node_lookup[4]] + np.random.normal(loc=0, scale=2000, size=20000) # Revenue
Training the SCM
Now we can train the SCM using the GCM module from the python package DoWhy. We setup the data generating process with linear relationships therefore we can use ridge regression as the causal mechanism for each non-root node:
# Setup graph
graph = nx.from_numpy_array(graph_actual, create_using=nx.DiGraph)
graph = nx.relabel_nodes(graph, node_lookup)
# Create SCM
causal_model = gcm.InvertibleStructuralCausalModel(graph)
causal_model.set_causal_mechanism('Demand', gcm.EmpiricalDistribution()) # Deamnd
causal_model.set_causal_mechanism('TV spend', gcm.EmpiricalDistribution()) # Brand spend
causal_model.set_causal_mechanism('Social spend', gcm.EmpiricalDistribution()) # Social spend
causal_model.set_causal_mechanism('Organic clicks', gcm.AdditiveNoiseModel(gcm.ml.create_ridge_regressor())) # Organic clicks
causal_model.set_causal_mechanism('Social clicks', gcm.AdditiveNoiseModel(gcm.ml.create_ridge_regressor())) # Social clicks
causal_model.set_causal_mechanism('Revenue', gcm.AdditiveNoiseModel(gcm.ml.create_ridge_regressor())) # Revenue
gcm.fit(causal_model, df)
Intrinsic causal influence
We can easily compute the intrinsic causal influence using the GCM module. We do so and convert the contributions to percentages:
# calculate intrinsic causal influence
ici = gcm.intrinsic_causal_influence(causal_model, target_node='Revenue')
def convert_to_percentage(value_dictionary):
total_absolute_sum = np.sum([abs(v) for v in value_dictionary.values()])
return {k: round(abs(v) / total_absolute_sum * 100, 1) for k, v in value_dictionary.items()}
convert_to_percentage(ici)

Let’s show these on a bar chart:
# Convert dictionary to DataFrame
df = pd.DataFrame(list(ici.items()), columns=['Node', 'Intrinsic Causal Influence'])
# Create a bar plot
plt.figure(figsize=(10, 6))
sns.barplot(x='Node', y='Intrinsic Causal Influence', data=df)
# Rotate x labels for better readability
plt.xticks(rotation=45)
plt.title('Bar Plot from Dictionary Data')
plt.show()

Are our results intuitive? If you take a look back at the data generating process code you will see they are! Pay close attention to what each non-root node is inheriting and what additional noise is being added.
The intrinsic causal influence module is really easy to use, but it doesn’t help us understand the method behind it — To finish off, let’s explore the inner working of intrinsic causal influence!
Intrinsic causal influence — How does it work?
We want to estimate how much the noise term of each node contributes to the target node:
- It is worth remembering that root nodes are just made up of a noise term.
- In the non-root nodes, we separate the noise term from the what was inherited from parents.
- We also include the noise term from the target node – This could be interpreted as the contribution of unobserved confounders (although it could also be down the model mis-specification).
- The noise terms are then used to explain the variance in the target node – This can be seen as a model with noise terms as features and the target node as the outcome.
- The model is used to estimate the conditional distribution of the target node given subsets of noise variables.
- Shapley is then used to estimate the contribution of each noise term – If changing the noise term has little impact on the target, then the intrinsic causal influence will be very small.
Closing thoughts
Today we covered how you can estimate the intrinsic causal influence of your marketing campaigns. Here are some closing thoughts:
- Intrinsic causal influence is a powerful concept that could be applied across different use cases, not just marketing.
- Understanding the inner workings will help you apply it more effectively.
- Identifying the DAG and estimating the graph accurately is key to getting reasonable intrinsic causal influence estimates.
- In the marketing acquisition example, you may want to think about adding lagged effects for brand marketing.
Follow me if you want to continue this journey into Causal AI — In the next article we will explore how we can validate and calibrate our causal models using Synthetic Controls.
Measuring The Intrinsic Causal Influence Of Your Marketing Campaigns was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Measuring The Intrinsic Causal Influence Of Your Marketing Campaigns
Go Here to Read this Fast! Measuring The Intrinsic Causal Influence Of Your Marketing Campaigns