

A few words on thresholding, the softmax activation function, introducing an extra label, and considerations regarding output activation functions.
In many real-world applications, machine learning models are not designed to make decisions in an all-or-nothing manner. Instead, there are situations where it is more beneficial for the model to flag certain predictions for human review — a process known as human-in-the-loop. This approach is particularly valuable in high-stakes scenarios such as fraud detection, where the cost of false negatives is significant. By allowing humans to intervene when a model is uncertain or encounters complex cases, businesses can ensure more nuanced and accurate decision-making.
In this article, we will explore how thresholding, a technique used to manage model uncertainty, can be implemented within a deep learning setting. Thresholding helps determine when a model is confident enough to make a decision autonomously and when it should defer to human judgment. This will be done using a real-world example to illustrate the potential.
By the end of this article, the hope is to provide both technical teams and business stakeholders with some tips and inspiration for making decisions about modelling, thresholding strategies, and the balance between automation and human oversight.
Business Case: Detecting Fraudulent Transactions with Confidence
To illustrate the value of thresholding in a real-world situation, let’s consider the case of a financial institution tasked with detecting fraudulent transactions. We’ll use the Kaggle fraud detection dataset (DbCL license), which contains anonymized transaction data with labels for fraudulent activity. The institutions process lots of transactions, making it difficult to manually review each one. We want to develop a system that accurately flags suspicious transactions while minimizing unnecessary human intervention.
The challenge lies in balancing precision and efficiency. Thresholding is a strategy used to introduce this trade-off. With this strategy we add an additional label to the sample space—unknown. This label serves as a signal from the model when it is uncertain about a particular prediction, effectively deferring the decision to human review. In situations where the model lacks enough certainty to make a reliable prediction, marking a transaction as unknown ensures that only the most confident predictions are acted upon.
Also, thresholding might come with another positive side effect. It helps overcome potential tech skepticism. When a model indicates uncertainty and defers to human judgment when needed, it can foster greater trust in the system. In previous projects, this has been of help when rolling projects out in various organisations.
Technical and analytical aspects.
We will explore the concept of thresholding in a deep learning context. However, it’s important to note that thresholding is a model agnostic technique with application across various types of situations, not just deep learning.
When implementing a thresholding step in a neural network, it is not obvious in what layer to put it. In a classification setting, an output transformation can be implemented. The sigmoid function is an option, but also a softmax function. Softmax offers a very practical transformation, making the logits adhere to certain nice statistical properties. These properties are that we are guaranteed logits will sum to one, and they will all be between zero and one.
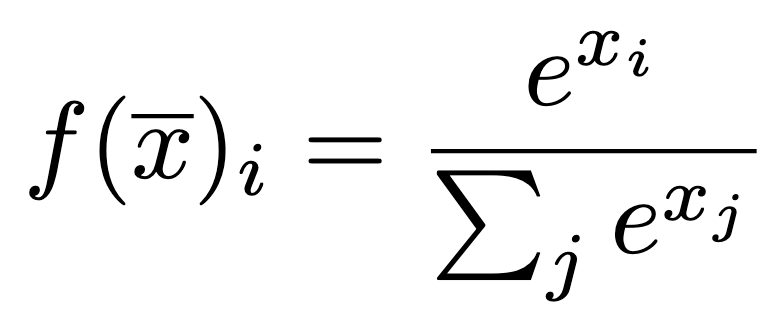
However, in this process, some information is lost. Softmax captures only the relative certainty between labels. It does not provide an absolute measure of certainty for any individual label, which in turn can lead to overconfidence in cases where the true distribution of uncertainty is more nuanced. This limitation becomes critical in applications requiring precise decision thresholds.
This article will not delve into the details of the model architecture, as these are covered in an upcoming article for those interested. The only thing being used from the model are the outcomes before and after the softmax transformation has been implemented, as the final layer. A sample of the output is depicted here.
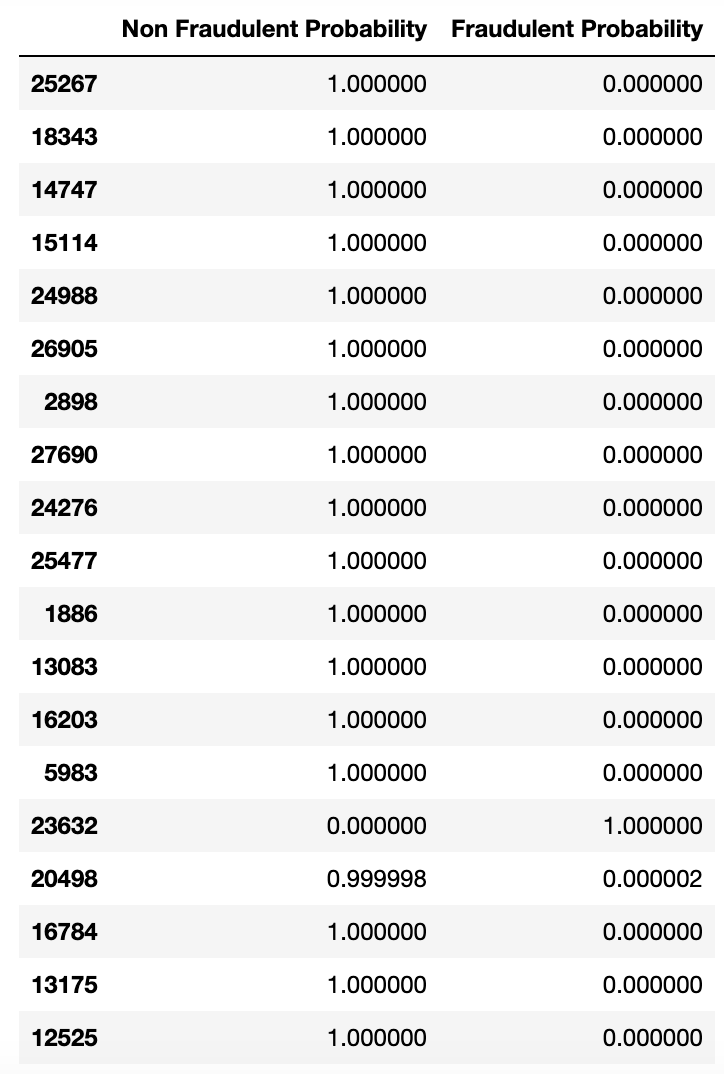
As seen, the outputs are rather homogenic. And without knowing the mechanics of the softmax, it looks as if the model is pretty certain about the classifications. But as we will see further down in the article, the strong relationship we are capturing here is not the true certainty of the labels. Rather, this is to be interpreted as one label’s predictions in comparison with the other. In our case, this means the model may capture some labels as being significantly more likely than others, but it does not reflect the overall certainty of the model.
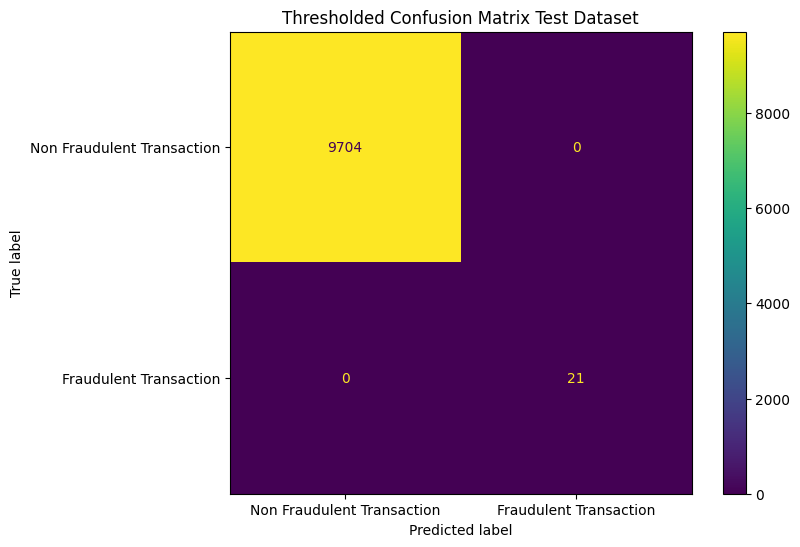
With this understanding of the interpretation of the outputs, let’s explore how the model performs in practice. Looking at the confusion matrix.
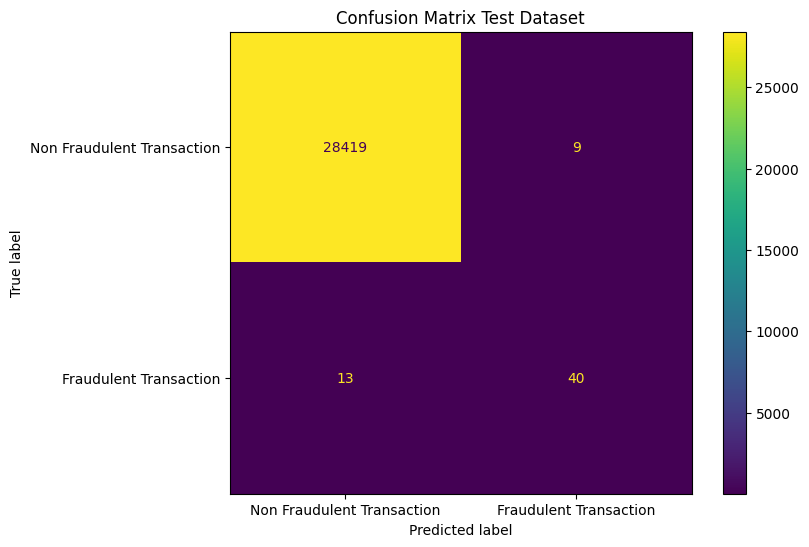
The model does not perform terribly, although it is far from perfect. With these base results at hand, we will look into implementing a threshold.
We will be starting out going one layer into the network — examining the values right before the final activation function. This renders the following logits.
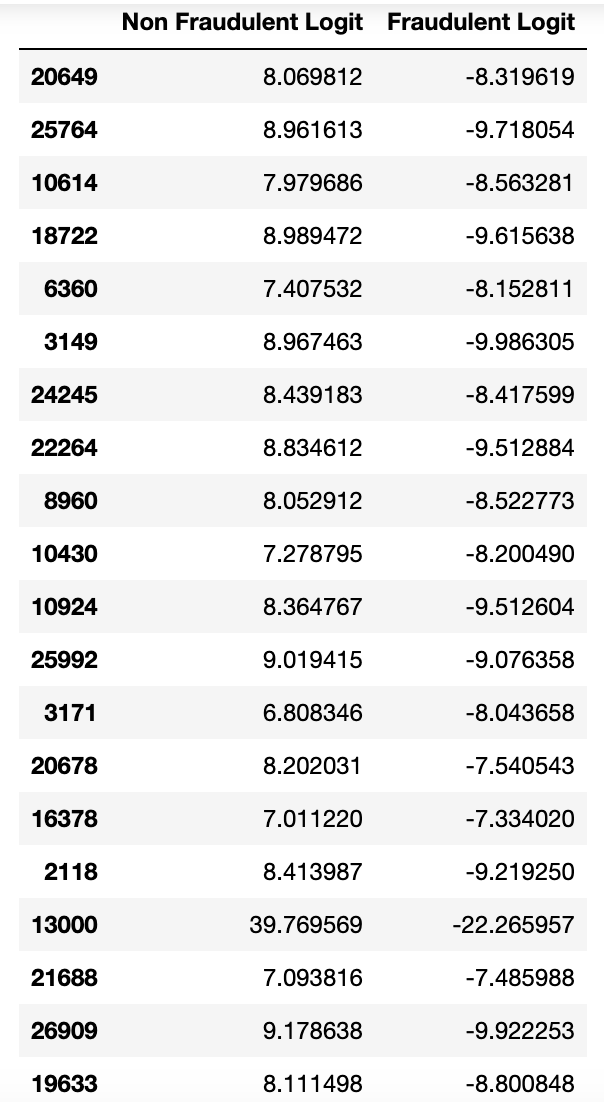
Here we see a larger variety of values. This layer provides a more detailed view of the model’s uncertainty in its predictions and it is here where the threshold layer is inserted.
By introducing an upper and lower confidence threshold, the model only labels approximately 34% of the dataset, focusing on the most certain predictions. But in turn, the results are more certain, depicted in the following confusion matrix. It’s important to note that thresholding does not have to be uniform. For example, some labels may be more difficult to predict than others, and label imbalance can also affect the thresholding strategy.
Metrics.
In this scenario, we have only touched upon the two edge cases in thresholding; the ones letting all predictions through (base case) and the ones that removed all faulty predictions.
Based on practical experience, deciding whether to label fewer data points with high certainty (which might reduce the total number of flagged transactions) or label more data points with lower certainty is quite a complex trade-off. This decision can impact operational efficiency and could be informed by business priorities, such as risk tolerance or operational constraints. Discussing this together with subject matter experts is a perfectly viable way of figuring out the thresholds. Another, is if you are able to optimise this in conjunction with a known or approximated metric. This can be done by aligning thresholds with specific business metrics, such as cost per false negative or operational capacity.
Summarization.
In conclusion, the goal is not to discard the softmax transformation, as it provides valuable statistical properties. Rather, we suggest introducing an intermediate threshold layer to filter out uncertain predictions and leave room for an unknown label when necessary.
The exact way to implement this I believe comes down to the project at hand. The fraud example also highlights the importance of understanding the business need aimed to solve. Here, we showed an example where we had thresholded away all faulty predictions, but this is not at all necessary in all use cases. In many cases, the optimal solution lies in finding a balance between accuracy and coverage.
Thank you for taking the time to explore this topic.
I hope you found this article useful and/or inspiring. If you have any comments or questions, please reach out. You can also connect with me on LinkedIn.
Mastering Model Uncertainty: Thresholding Techniques in Deep Learning was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Mastering Model Uncertainty: Thresholding Techniques in Deep Learning
Go Here to Read this Fast! Mastering Model Uncertainty: Thresholding Techniques in Deep Learning