An introduction using no-code solutions

People use large language models to perform various tasks on text data from different sources. Such tasks may include (but are not limited to) editing, summarizing, translating, or text extraction. One of the primary challenges to this workflow is ensuring your data is AI-ready. This article briefly outlines what AI-ready means and provides a few no-code solutions for getting you to this point.
What does AI-ready mean?
We are surrounded by vast collections of unstructured text data from different sources, including web pages, PDFs, e-mails, organizational documents, etc. In the era of AI, these unstructured text documents can be essential sources of information. For many people, the typical workflow for unstructured text data involves submitting a prompt with a block of text to the large language model (LLM).

While the copy-paste method is a standard strategy for working with LLMs, you will likely encounter situations where this doesn’t work. Consider the following:
- While many premium models allow documents to be uploaded and processed, file size is restricted. If the file is too large, you will need other strategies for getting the relevant text into the model.
- You may want to process only a small section of text from a larger document. Providing the entire document to the LLM can interfere with the task’s completion because of the irrelevant text.
- Some text documents and webpages, especially PDFs, contain a lot of formatting that can interfere with how the text is processed. You may not be able to use the copy-paste method because of how the document is formatted — tables and columns can be problematic.
Being AI-ready means that your data is in a format that can be easily read and processed by an LLM. For text data processing, the data is in plain text with formatting that the LLM readily interprets. The markdown file type is ideal for ensuring your data is AI-ready.
Plain text vs. markdown
Plain text is the most basic type of file on your computer. This is typically denoted as a .txt extension. Many different _editors_ can be used to create and edit plain-text files in the same way that Microsoft Word is used for creating and editing stylized documents. For example, the Notepad application on a PC or the TextEdit application on a Mac are default text editors. However, unlike Microsoft Word, plain-text files do not allow you to stylize the text (e.g., bold, underline, italics, etc.). They are files with only the raw characters in a plain-text format.
Markdown files are plain-text files with the extension .md. What makes the markdown file unique is the use of certain characters to indicate formatting. These special characters are interpreted by Markdown-aware applications to render the text with specific styles and structures. For example, surrounding text with asterisks will be italicized, while double asterisks display the text as bold. Markdown also provides simple ways to create headers, lists, links, and other standard document elements, all while maintaining the file as plain text.
The relationship between Markdown and Large Language Models (LLMs) is straightforward. Markdown files contain plain-text content that LLMs can quickly process and understand. LLMs can recognize and interpret Markdown formatting as meaningful information, enhancing text comprehension. Markdown uses hashtags for headings, which create a hierarchical structure. A single hashtag denotes a level-1 heading, two hashtags a level-2 heading, three hashtags a level-3 heading, and so on. These headings serve as contextual cues for LLMs when processing information. The models can use this structure to understand better the organization and importance of different sections within the text.
By recognizing Markdown elements, LLMs can grasp the content and its intended structure and emphasis. This leads to more accurate interpretation and generation of text. The relationship allows LLMs to extract additional meaning from the text’s structure beyond just the words themselves, enhancing their ability to understand and work with Markdown-formatted documents. In addition, LLMs typically display their output in markdown formatting. So, you can have a much more streamlined workflow working with LLMs by submitting and receiving markdown content. You will also find that many other applications allow for markdown formatting (e.g., Slack, Discord, GitHub, Google Docs)
Many Internet resources exist for learning markdown. Here are a few valuable resources. Please take some time to learn markdown formatting.
Essential Tools
This section explores essential tools for managing Markdown and integrating it with Large Language Models (LLMs). The workflow involves several key steps:
- Source Material: We start with structured text sources such as PDFs, web pages, or Word documents.
- Conversion: Using specialized tools, we convert these formatted texts into plain text, specifically Markdown format
- Storage (Optional): The converted Markdown text can be stored in its original form. This step is recommended if you reuse or reference the text later.
- LLM Processing: The Markdown text is then inputted to an LLM.
- Output Generation: The LLM processes the data and generates output text.
- Result Storage: The LLM’s output can be stored for further use or analysis.
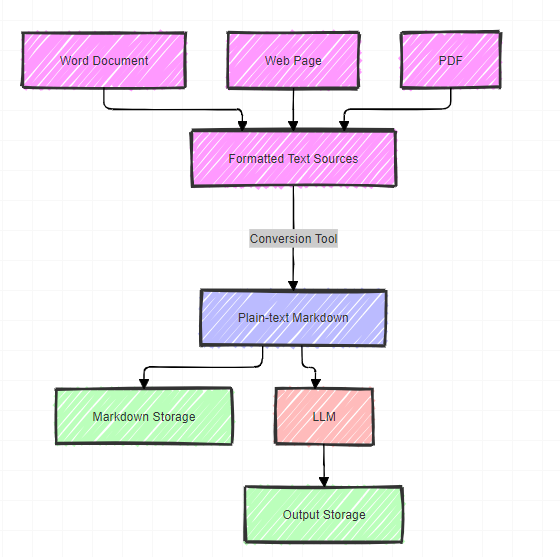
This workflow efficiently converts various document types into a format that LLMs can quickly process while maintaining the option to store both the input and output for future reference.
Obsidian: Saving and storing plain-text
Obsidian is one of the best options available for saving and storing plain-text and markdown files. When I extract plain-text content from PDFs and web pages, I typically save that content in Obsidian, a free text editor ideal for this purpose. I also use Obsidian for my other work, including taking notes and saving prompts. This is a fantastic tool that is worth learning.
Obsidian is simply a tool for saving and storing plain text content. You will likely want this part of your workflow, but it is NOT required!
Jina AI — Reader: Extract plain text from websites
Jina AI is one of my favorite AI companies. It makes a suite of tools for working with LLMs. Jina AI Reader is a remarkable tool that converts a webpage into markdown format, allowing you to grab content in plain text to be processed by an LLM. The process is very simple. Add https://r.jina.ai/ to any URL, and you will receive AI-ready content for your LLM.
For example, consider the following screenshot of large language models on Wikipedia: en.wikipedia.org/wiki/Large_language_model
Assume we just wanted to use the text about LLMs contained on this page. Extracting that information can be done using the copy-paste method, but that will be cumbersome with all the other formatting. However, we can use Jina AI-Reader by adding `https://r.jina.ai` to the beginning of the URL:
- Original URL: en.wikipedia.org/wiki/Large_language_model
- URL with Jina: https://r.jina.ai/en.wikipedia.org/wiki/Large_language_model`
This returns everything in a markdown format:
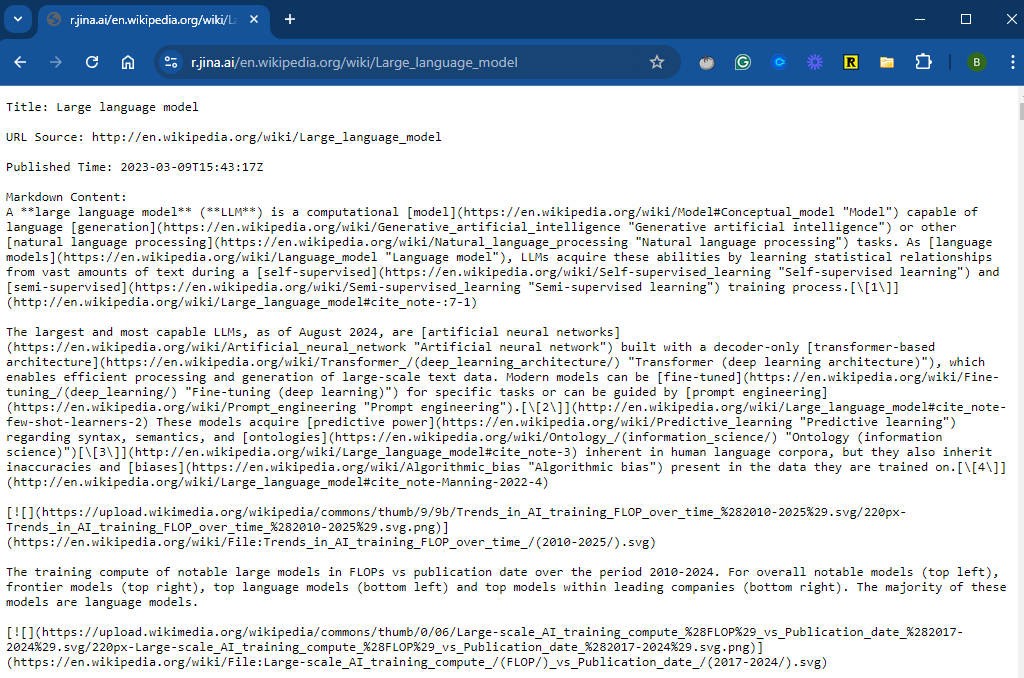
From here, we can easily copy-paste the relevant content into the LLM. Alternatively, we can save the markdown content in Obsidian, allowing it to be reused over time. While Jina AI offers premium services at a very low cost, you can use this tool for free.
LlamaParse: Extracting plain text from documents
Highly formatted PDFs and other stylized documents present another common challenge. When working with Large Language Models (LLMs), we often must strip away formatting to focus on the content. Consider a scenario where you want to use only specific sections of a PDF report. The document’s complex styling makes simple copy-pasting impractical. Additionally, if you upload the entire document to an LLM, it may struggle to pinpoint and process only the desired sections. This situation calls for a tool that can separate content from formatting. LlamaParse by LlamaIndex addresses this need by effectively decoupling text from its stylistic elements.
To access LlamaParse, you can log into LlamaCloud: https://cloud.llamaindex.ai/login. After logging into LlamaCloud, go to LlamaParse on the left-hand side of the screen:
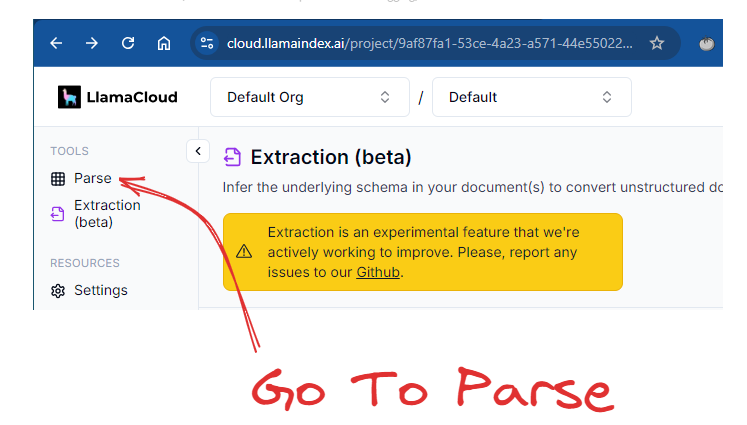
After you have accessed the Parsing feature, you can extract the content by following these steps. First, change the mode to “Accurate,” which creates output in markdown format. Second, drag and drop your document. You can parse many different types of documents, but my experience is that you will typically need to parse PDFs, Word files, and PowerPoints. Just keep in mind that you can process many different file types. In this example, I use a publicly available report by the American Social Work Board. This is a highly stylized report that is 94 pages long.

Now, you can copy and paste the markdown content or you can export the entire file in markdown.
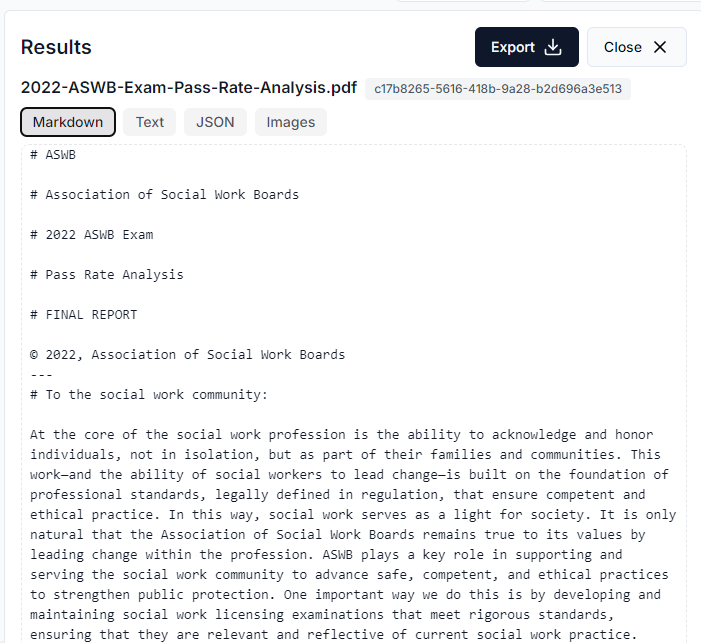
On the free plan, you can parse 1,000 pages per day. LlamaParse has many other features that are worth exploring.
Final thoughts
Preparing text data for AI analysis involves several strategies. While using these techniques may initially seem challenging, practice will help you become more familiar with the tools and workflows. Over time, you’ll learn to apply them efficiently to your specific tasks.
Making Text Data AI-Ready was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Making Text Data AI-Ready