How to fine-tune every machine learning algorithm in Python. The ultimate guide to machine learning optimization with Optuna to achieve great model performances

In machine learning, hyperparameters are settings you configure before training your model. Unlike the parameters your model learns during training, hyperparameters must be set beforehand. Finding the right hyperparameters can greatly enhance your model’s performance, making hyperparameter optimization essential.
Properly optimized hyperparameters can significantly boost a model’s accuracy and reliability. They help your model generalize well, avoiding overfitting (where the model is too tailored to the training data) and underfitting (where the model isn’t complex enough to capture the underlying patterns).
In this article, we’ll explore Optuna, a popular framework for effectively optimizing any machine learning or deep learning algorithm. We’ll dive into the math behind it and provide practical examples using XGBoost and a neural network with PyTorch. Sit tight and enjoy the ride!
Index
1: Optuna Overview
2: The Algorithm Behind Optuna
∘ Bayesian Optimization
∘ Tree-structured Parzen Estimator (TPE)
∘ Multi-Objective Optimization
3: The Math Behind Optuna
∘ Probability Density Functions (PDFs)
∘ Expected Improvement (EI)
∘ Kernel Density Estimation (KDE)
4: Optuna Application in Python
∘ XGBoostClassifier Optimization
∘ Neural-Network Optimization
Conclusion
1: Optuna Overview
Optuna was created by Preferred Networks, Inc. and became an open-source project in 2018. It was designed to tackle the challenges of hyperparameter optimization, offering a more efficient and adaptable approach than previous methods. Since its release, Optuna has gained a strong following and continues to evolve with community contributions.
Optuna offers several standout features that make it a powerful tool for hyperparameter optimization. It automates the search for the best hyperparameters, taking the guesswork out of tuning and allowing you to focus on developing your model. Optuna uses advanced algorithms like the Tree-structured Parzen Estimator (TPE) and CMA-ES to efficiently find optimal settings. It also integrates weel with popular machine learning frameworks such as TensorFlow, PyTorch, and scikit-learn.
2: The Algorithm Behind Optuna
Bayesian Optimization
Bayesian Optimization is a strategy for finding the best hyperparameters by building a probabilistic model of the objective function. It’s particularly useful when evaluating the objective function is expensive or time-consuming.
Optuna uses Bayesian Optimization to efficiently search for the optimal hyperparameters. It starts by sampling a few sets of hyperparameters and evaluating their performance. Then, it builds a model to predict which hyperparameters might perform well based on the results so far. This model helps Optuna focus on the most promising areas of the search space, making the optimization process more efficient.
A Tutorial on Bayesian Optimization
Tree-structured Parzen Estimator (TPE)
The Tree-structured Parzen Estimator (TPE) is an algorithm used by Optuna for Bayesian Optimization. Instead of using a Gaussian Process like traditional Bayesian methods, TPE models the objective function using two probability density functions: one for the good hyperparameter sets and one for the others. It then uses these distributions to sample new hyperparameter sets that are more likely to perform well.
Traditional Bayesian Optimization methods use Gaussian Processes to model the objective function, which can be computationally intensive and struggle with high-dimensional spaces. TPE, on the other hand, uses simpler and more flexible probability distributions, making it more scalable and efficient, especially for complex optimization problems.
Multi-Objective Optimization
Multi-objective optimization involves optimizing more than one objective function simultaneously. In machine learning, this could mean balancing trade-offs between different metrics, like accuracy and inference time.
Optuna extends its optimization capabilities to handle multiple objectives by maintaining a set of Pareto-optimal solutions. This means it finds a range of solutions where no single solution is strictly better than another in all objectives. Users can then choose the best solution based on their specific needs and priorities.
3: The Math Behind Optuna
Probability Density Functions (PDFs)
Think of Probability Density Functions (PDFs) as maps showing the likelihood of different outcomes for a random variable. In the TPE algorithm, PDFs help us understand which hyperparameters work well and which don’t. Imagine you’re on a treasure hunt: PDFs help you figure out where the treasure (good hyperparameters) is more likely to be hidden.
In TPE, two PDFs are constructed: l(x) for good hyperparameter values and g(x) for the rest. The algorithm samples new hyperparameters by maximizing the ratio
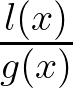
ensuring that samples are drawn from regions where good hyperparameters are more likely to be found:
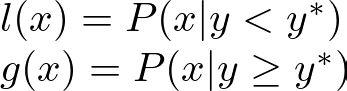
Here, y is the objective function value, and y* is a threshold for good performance.
Expected Improvement (EI)
Expected Improvement (EI) is like deciding which direction to explore next on your treasure map. It measures how much better you can expect the new hyperparameters to perform compared to your current best set. EI helps you balance between exploring new areas (places you haven’t checked yet) and exploiting known good areas (places where you’ve already found some treasure).
The EI for a new set of hyperparameters x is calculated as:
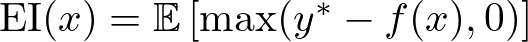
where y* is the best-observed value, and f(x) is the predicted value of the objective function at x. This can be further expanded using the properties of the normal distribution:
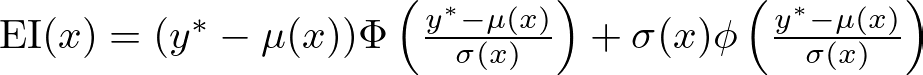
where μ(x) and σ(x) are the mean and standard deviation of the predicted objective function at x, Φ is the cumulative distribution function, and ϕ is the probability density function of the standard normal distribution.
Kernel Density Estimation (KDE)
Kernel Density Estimation (KDE) is like drawing a smooth curve over a scatter plot to show where the data points cluster. In Optuna, KDE models the PDFs for the TPE algorithm, helping to smooth out the distribution of observed data points and make continuous probability estimates.
The KDE for a set of data points x_i is given by:
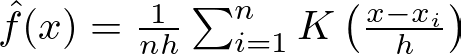
where K is the kernel function (often a Gaussian), h is the bandwidth parameter controlling the smoothness, and n is the number of data points. This formulation allows KDE to provide a smooth estimate of the probability density, which is essential for the TPE algorithm to sample new promising hyperparameters effectively.
4: Optuna Application in Python
Let’s dive into two applications of Optuna using Python. We’ll build an XGBoost classifier and a neural network, and find the best combination of hyperparameters for both models.
The recommended way to go through this example is to download this code repo, which contains the data and the notebook with all the code we will cover today plus some extra bonus:
If you want to download the data by yourself, first, you’ll need to install Optuna and Kaggle to download the dataset for this example. You can install them using pip:
pip install optuna kaggle
After installing, download the dataset by running these commands in your terminal. Make sure you’re in the same directory as your notebook file:
mkdir data
cd data
kaggle competitions download -c playground-series-s4e6
unzip "Academic Succession/playground-series-s4e6.zip"
Alternatively, you can manually download the dataset from the recent Kaggle competition “Classification with an Academic Success Dataset”. The dataset is free for commercial use.
Classification with an Academic Success Dataset
XGBoostClassifier Optimization
Let’s go through a practical example using XGBoost, but you can apply this technique to any algorithm, and in the next section, we’ll also see how it works with a neural network using PyTorch.
First, let’s load and prepare the data:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
Here, we load our training and test datasets from CSV files downloaded from Kaggle. Make sure the data is saved in a folder named “data”.
Next, we identify which columns need scaling. Scaling normalizes the range of the data, making it easier for the model to learn:
cols_to_scale = [col for col in train.columns[1:-1] if train[col].min() < -1 or train[col].max() > 1]
We’re selecting columns with values outside the range of -1 to 1. These columns will be scaled later to ensure consistent data ranges.
Now, we separate the features (X) from the target variable (y):
X, y = train.drop(columns=['id', 'Target']), train['Target'].values
test.drop(columns=['id'], inplace=True)
We drop the ‘id’ and ‘Target’ columns from the training data to get our feature set and similarly drop ‘id’ from the test data. The y variable holds the target values.
Next, we encode the target variable. Our target variable has categorical values like Graduate, Dropout, and Enrolled. Encoding converts these categories into numerical values that the model can process:
encoder = OneHotEncoder(sparse=False, categories='auto')
y_ohe = encoder.fit_transform(y.reshape(-1, 1))
We use OneHotEncoder to convert the target variable into a one-hot encoded format. Each category is converted into a vector, where only one element is 1 and the rest are 0.
We then split the data into training and validation sets:
X_train, X_val, y_train, y_val = train_test_split(X, y_ohe, test_size=0.3, shuffle=True, random_state=42)
Using train_test_split, we split our dataset into training and validation sets, with 70% for training and 30% for validation. The random_state parameter ensures consistent splitting each time the code runs.
Next, we scale the features:
scaler = StandardScaler()
X_train[cols_to_scale] = scaler.fit_transform(X_train[cols_to_scale])
X_val[cols_to_scale] = scaler.transform(X_val[cols_to_scale])
test[cols_to_scale] = scaler.transform(test[cols_to_scale])
We use StandardScaler to scale the selected columns in the training, validation, and test sets. fit_transform learns the scaling parameters from the training set and applies the transformation. transform applies these parameters to the validation and test sets, ensuring consistent scaling.
The next step is to define the objective function for the Optuna study. This function trains an XGBoost model and returns the validation accuracy:
import xgboost as xgb
import numpy as np
def optimize_xgb(trial):
params = {
'objective': 'multi:softmax',
'num_class': y_train.shape[-1],
'n_estimators': 100,
'max_depth': trial.suggest_int('max_depth', 3, 10),
'learning_rate': trial.suggest_float('learning_rate', 1e-3, 1e-1),
'subsample': trial.suggest_float('subsample', 0.5, 1),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.5, 1),
'gamma': trial.suggest_float('gamma', 0, 1),
'reg_alpha': trial.suggest_float('reg_alpha', 0, 1),
'reg_lambda': trial.suggest_float('reg_lambda', 0, 1),
'min_child_weight': trial.suggest_int('min_child_weight', 1, 10),
'n_jobs': -1
}
xgb_cl = xgb.XGBClassifier(**params)
xgb_cl.fit(X_train, np.argmax(y_train, axis=1), eval_set=[(X_val, np.argmax(y_val, axis=1))], verbose=0)
y_pred = xgb_cl.predict(X_val)
acc = np.mean(y_pred == np.argmax(y_val, axis=1))
return acc
First, we define a dictionary of hyperparameters (params) for XGBoost. Each hyperparameter is suggested using Optuna’s trial.suggest_* methods, which propose values within specified ranges. This is where Bayesian Optimization comes into play, as Optuna uses the results of each trial to suggest the next set of hyperparameters.
Then, we create an instance of XGBClassifier with these parameters and fit them into the training data. We predict the validation set and calculate the accuracy, which is returned as the objective value.
Finally, we run the study with a specified number of trials (100 in our case):
study = optuna.create_study(direction='maximize', study_name='xgb_study', storage='sqlite:///xgb_study.db', load_if_exists=True)
study.optimize(optimize_xgb, n_trials=100, n_jobs=-1, show_progress_bar=True)
print(f"Best Val Accuracy: {study.best_value:.2%}")
for key, value in study.best_params.items():
print(f"{key}: {value}")
In this code, study.optimize runs the optimization process for 100 trials using multiple CPU cores (n_jobs=-1). After optimization, we print the best validation accuracy and the best hyperparameters found.
In the end, we retrain the model using the best hyperparameters found by Optuna:
best_xgb = xgb.XGBClassifier(**study.best_params, n_estimators=1000, n_jobs=-1)
best_xgb.fit(X_train, np.argmax(y_train, axis=1), eval_set=[(X_val, np.argmax(y_val, axis=1))], verbose=0)
print(f"Val Accuracy: {best_xgb.score(X_val, np.argmax(y_val, axis=1)):.2%}")
We create a new XGBClassifier with the best hyperparameters and train it on the training data. We then evaluate the model on the validation set and print the validation accuracy.
Check this previous article if you are interested in learning more about the math and code behind XGBoost:
Neural-Network Optimization
Now let’s move on to a deep learning example. We’ll optimize a neural network with PyTorch using Optuna.
First, let’s prepare the data. We’ll use the same dataset, preprocessing, and normalization as before:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
BATCH_SIZE = 64
train_dataset = TensorDataset(torch.tensor(X_train.values).float(), torch.tensor(y_train).float())
val_dataset = TensorDataset(torch.tensor(X_val.values).float(), torch.tensor(y_val).float())
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE)
We create PyTorch datasets from the training and validation data and use DataLoader to load the data in batches, which is essential for efficient training.
Next, we define our neural network:
class NeuralNet(nn.Module):
def __init__(self, input_size: int, hidden_size: int, output_size: int, n_hidden_layers: int, batchnorm: bool, dropout: float):
super(NeuralNet, self).__init__()
layers = [nn.Linear(input_size, hidden_size), nn.ReLU(), nn.Dropout(dropout)]
for _ in range(n_hidden_layers):
layers.extend([nn.Linear(hidden_size, hidden_size), nn.ReLU(), nn.Dropout(dropout)])
layers.append(nn.Linear(hidden_size, output_size))
layers.append(nn.Softmax(dim=1))
if batchnorm:
for i in range(1, len(layers), 4):
layers.insert(i, nn.BatchNorm1d(hidden_size))
self.network = nn.Sequential(*layers)
def forward(self, x):
return self.network(x)
The NeuralNet class inherits from nn.Module, which is the base class for all neural network modules in PyTorch. The __init__ method initializes the network with several parameters:
- input_size: the number of input features.
- hidden_size: the number of neurons in each hidden layer.
- output_size: the number of output neurons, which corresponds to the number of classes for classification tasks.
- n_hidden_layers: the number of hidden layers in the network.
- batchnorm: a boolean indicating whether to use batch normalization.
- dropout: the dropout rate, which is used to prevent overfitting by randomly setting a fraction of the input units to zero during training.
Inside the __init__ method, the super function is called to initialize the parent nn.Module class. This is necessary to properly set up the internal state of the module.
The layers list is initialized with the first layer consisting of a linear transformation, followed by a ReLU activation function and a dropout layer:
layers = [nn.Linear(input_size, hidden_size), nn.ReLU(), nn.Dropout(dropout)]
Here, nn.Linear(input_size, hidden_size) defines a fully connected layer with input_size inputs and hidden_size outputs. The linear transformation of the input data is represented mathematically as
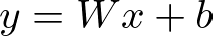
where W is the weight matrix and b is the bias vector. This transformation maps the input features to the hidden layer’s neurons.
Then, the ReLU activation function is applied to introduce non-linearity, allowing the network to learn complex patterns. The ReLU function is defined as
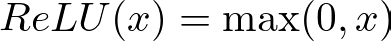
It introduces non-linearity into the model, enabling it to learn complex patterns. Without activation functions, the network would essentially be a linear model, regardless of the number of layers.
Lastly, Dropout is applied to prevent overfitting by randomly setting a fraction of the input units to zero during training. Dropout is a regularization technique that randomly sets a fraction of the input units to zero during training. Mathematically, if p is the dropout rate, each input unit is set to zero with a probability of p and scaled by
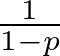
during testing to maintain the expected sum of the inputs.
Then, the for-loop is then used to add the hidden layers:
for _ in range(n_hidden_layers):
layers.extend([nn.Linear(hidden_size, hidden_size), nn.ReLU(), nn.Dropout(dropout)])
In each iteration, a fully connected layer with hidden_size inputs and outputs are added, followed by a ReLU activation and dropout layer. This structure ensures that each hidden layer has the same number of neurons and applies the same activation and dropout functions.
The final layers include a linear transformation from hidden_size to output_size and a softmax activation function:
layers.append(nn.Linear(hidden_size, output_size))
layers.append(nn.Softmax(dim=1))
The softmax function converts the output scores into probabilities, which is essential for multi-class classification tasks. The dim=1 argument specifies that the softmax should be applied along the feature dimension. For an output vector z with components z_i, the softmax function is defined as
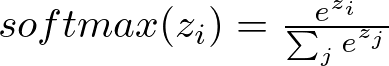
This ensures that the output probabilities sum to one, making them interpretable as class probabilities.
If batchnorm is True, batch normalization layers are inserted into the network:
if batchnorm:
for i in range(1, len(layers), 4):
layers.insert(i, nn.BatchNorm1d(hidden_size))
Batch normalization normalizes the input of each layer to have a mean of zero and a variance of one. This can stabilize and accelerate the training process. Here, a batch normalization layer is inserted after every linear layer. This is represented as
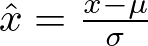
where μ and σ are the mean and standard deviation of the input batch, respectively. This normalization helps in stabilizing the learning process and can lead to faster convergence.
The list of layers is then converted into a sequential container:
self.network = nn.Sequential(*layers)
nn.Sequential creates a module that passes the input through each layer in sequence, simplifying the forward pass.
Finally, the forward method defines the forward pass of the network:
def forward(self, x):
return self.network(x)
This method takes an input tensor x and passes it through the sequential network. The output is the result of the softmax function, providing class probabilities for classification.
Let’s move on to the core part of this section, creating an Optuna study that will optimize our Neural Network:
def optimize(trial):
hidden_size = trial.suggest_int("hidden_size", 32, 128, 32)
n_hidden_layers = trial.suggest_int("n_hidden_layers", 1, 5)
batchnorm = trial.suggest_categorical("batchnorm", [True, False])
dropout = trial.suggest_float("dropout", 0.1, 0.5)
lr = trial.suggest_float("lr", 1e-3, 1e-1)
net = NeuralNet(input_size=X_train.shape[-1], hidden_size=hidden_size, output_size=y_train.shape[-1], n_hidden_layers=n_hidden_layers, batchnorm=batchnorm, dropout=dropout)
optimizer = optim.Adam(net.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
for _ in range 50:
net.train()
for X_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = net(X_batch)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
net.eval()
with torch.no_grad():
outputs = net(torch.tensor(X_val.values).float())
val_acc = (outputs.argmax(dim=1) == torch.tensor(y_val).argmax(dim=1)).float().mean().item()
return val_acc
The optimize function is the heart of the hyperparameter optimization process using Optuna. This function defines how to train the model, evaluate its performance, and determine the optimal set of hyperparameters. Let’s dive into its code:
def optimize(trial):
hidden_size = trial.suggest_int("hidden_size", 32, 128, 32)
n_hidden_layers = trial.suggest_int("n_hidden_layers", 1, 5)
batchnorm = trial.suggest_categorical("batchnorm", [True, False])
dropout = trial.suggest_float("dropout", 0.1, 0.5)
lr = trial.suggest_float("lr", 1e-3, 1e-1)
optimize begins by suggesting hyperparameters for the neural network. Optuna’s trial.suggest_* methods are used here:
- hidden_size = trial.suggest_int(“hidden_size”, 32, 128, 32): This line suggests an integer value for the number of neurons in the hidden layers, between 32 and 128, in step 32.
- n_hidden_layers = trial.suggest_int(“n_hidden_layers”, 1, 5): This suggests an integer value for the number of hidden layers, between 1 and 5.
- batchnorm = trial.suggest_categorical(“batchnorm”, [True, False]): This suggests a categorical value, either True or False, for whether batch normalization should be applied.
- dropout = trial.suggest_float(“dropout”, 0.1, 0.5): This suggests a floating-point value for the dropout rate, between 0.1 and 0.5.
- lr = trial.suggest_float(“lr”, 1e-3, 1e-1): This suggests a floating-point value for the learning rate, between 0.001 and 0.1.
net = NeuralNet(input_size=X_train.shape[-1], hidden_size=hidden_size, output_size=y_train.shape[-1], n_hidden_layers=n_hidden_layers, batchnorm=batchnorm, dropout=dropout)
optimizer = optim.Adam(net.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
Here, we instantiate the NeuralNet class using the suggested hyperparameters. The input_size is set to the number of features in the training data, hidden_size, output_size, n_hidden_layers, batchnorm, and dropout are set to the values suggested by Optuna.
We use the Adam optimizer to minimize the loss function. The learning rate (lr) is one of the hyperparameters being optimized.
The loss function used is cross-entropy loss, which is standard for multi-class classification problems. It measures the difference between the predicted probability distribution and the true distribution.
for _ in range 50:
for X_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = net(X_batch)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
The training loop runs for 50 epochs. For each epoch for X_batch, y_batch in train_loader iterates over batches of data from the training DataLoader.
optimizer.zero_grad() clears the gradients of all optimized tensors. This is important because gradients by default add up; we need to zero them before backpropagation.
outputs = net(X_batch) feeds a batch of input data through the network.
loss = criterion(outputs, y_batch) computes the loss between the predicted outputs and the true labels. loss.backward() computes the gradient of the loss for the network’s parameters.
optimizer.step() updates the network’s parameters based on the gradients.
net.eval()
with torch.no_grad():
outputs = net(torch.tensor(X_val.values).float())
val_acc = (outputs.argmax(dim=1) == torch.tensor(y_val).argmax(dim=1)).float().mean().item()
After training, we switch the network to evaluation mode using net.eval(). This turns off certain layers that behave differently during training, such as dropout layers. Inside the with torch.no_grad() block, we feed the validation data through the network to get the outputs.
We use outputs.argmax(dim=1) to get the predicted class for each sample by selecting the index with the highest probability. Then, we compare these predictions with the true labels (torch.tensor(y_val).argmax(dim=1)). Lastly, we calculate the validation accuracy by averaging the number of correct predictions.
The function returns the validation accuracy, which Optuna uses to evaluate the quality of the hyperparameter set. Optuna’s Bayesian optimization algorithm then uses this information to suggest new hyperparameters for the next trial, aiming to maximize the validation accuracy.
study = optuna.create_study(direction='maximize')
study.optimize(optimize, n_trials=20, n_jobs=-1, show_progress_bar=True)
print(f"Best Val Accuracy: {study.best_value:.2%}")
for key, value in study.best_params.items():
print(f"{key}: {value}")
Now, it’s time to create and run the Optuna study as before. After optimization, we print the best validation accuracy and the best hyperparameters found.
For a further deep dive on Neural-Networks I suggest you to go through the following articles:
Conclusion
By the end of this guide, you should have a solid grasp of how to use Optuna for hyperparameter optimization. Whether you’re working with machine learning algorithms like XGBoost or deep learning models in PyTorch, Optuna’s powerful tools and techniques can help you fine-tune your models for better performance. This knowledge will enable you to systematically explore and optimize your models, leading to more accurate and reliable predictions.
References
- Akiba, T., Sano, S., Yanase, T., Ohta, T., & Koyama, M. (2019). Optuna: A Next-generation Hyperparameter Optimization Framework. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ‘19), 2623–2631. https://doi.org/10.1145/3292500.3330701
- Bergstra, J., Yamins, D., & Cox, D. D. (2013). Making a Science of Model Search: Hyperparameter Optimization in Hundreds of Dimensions for Vision Architectures. Proceedings of the 30th International Conference on Machine Learning (ICML’13), 115–123. http://proceedings.mlr.press/v28/bergstra13.pdf
- Snoek, J., Larochelle, H., & Adams, R. P. (2012). Practical Bayesian Optimization of Machine Learning Algorithms. Advances in Neural Information Processing Systems 25 (NIPS 2012), 2951–2959. https://proceedings.neurips.cc/paper/2012/file/05311655a15b75fab86956663e1819cd-Paper.pdf
- Shahriari, B., Swersky, K., Wang, Z., Adams, R. P., & de Freitas, N. (2016). Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proceedings of the IEEE, 104(1), 148–175. https://doi.org/10.1109/JPROC.2015.2494218
You made it to the end. Congrats! I hope you enjoyed this article, if so consider leaving a like and following me, as I will regularly post similar articles. My goal is to recreate all the most popular algorithms from scratch and make machine learning accessible to everyone.
Machine Learning Optimization with Optuna was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Machine Learning Optimization with Optuna
Go Here to Read this Fast! Machine Learning Optimization with Optuna