Get started with Airbyte and Cloud Storage
Coding the connectors yourself? Think very carefully
Creating and maintaining a data platform is a hard challenge. Not only do you have to make it scalable and useful, but every architectural decision builds up over time. Data connectors are an essential part of such a platform. Of course, how else are we going to get the data? And building them yourself from scratch gives you full control of how you want them to behave. But beware, with ever-increasing data sources in your platform, that can only mean the following:
- Creating large volumes of code for every new connector.
- Maintaining complex code for every single data connector.
- Functions and definitions between classes may diverge over time, resulting in even more complex maintenance.
Of course, all three can be mitigated with well-defined practices in object-oriented programming. But even still, it will take many hours of coding that could be used in later stages to serve your data consumers faster.

What if you try low-code connectors?
Other options still give you the flexibility to define what data you want to ingest and how with no to very little code involved. With this option, you get:
- Connectors with standardized behavior given the extraction methodology: No divergent classes for two connectors that use REST APIs at their core, for instance.
- Simple, but powerful user interfaces to build connections between sources and destinations.
- Connectors that are maintained by the teams building the tools and the community.
These benefits allow you to build data connections in minutes, instead of hours.
Nevertheless, I am not trying to sell you these tools; if and when you need highly customizable logic for data ingestion, you are going to need to implement it. So, do what is best for your application.
The exercise: Airbyte with ADLS Gen2
Let’s jump right into it. I am using Azure for this tutorial. You can sign up and get $200 worth of services for free to try the platform.
We are going to deploy Airbyte Open Source using an Azure Kubernetes cluster and use Azure Storage (ADLS) Gen 2 for cloud storage.
Creating the infrastructure
First, create the following resources:
- Resource group with the name of your choosing.
- Azure Kubernetes Services. To avoid significant costs, set a single node pool with one node. However, that node needs enough resources. Otherwise, the Airbyte syncs won’t start. An appropriate node size is Standard_D4s_v3.
- Azure Storage Account. While creating git, turn on the hierarchical namespace feature so the storage account becomes ADLS Gen2. Now create a storage container with any name you like.
Production Tip: Why the hierarchical namespace? Object stores by default have a flat storage environment. This has the benefit of infinite scalability, with an important downside. For analytics workloads, this results in additional overhead when reading, modifying, or moving files as the whole container has to be scanned. Enabling this features brings hierarchical directories from filesystems to scalable object storage.
Deploying Airbyte to Kubernetes
You need to install a few things on your shell first:
Now, follow these steps:
Log into your Azure account using the shell.
az login
Set the cluster credentials.
az aks get-credentials --resource-group <your-resource-group>
--name <cluster-name>
--overwrite-existing
Add remote helm repository and search for the Airbyte chart.
helm repo add airbyte https://airbytehq.github.io/helm-charts
helm repo update
helm search repo airbyte
Create a unique Kubernetes namespace for the Airbyte deployments. I called it dev-airbyte.
kubectl create namespace dev-airbyte
Deploy Airbyte.
helm install airbyte airbyte/airbyte - namespace dev-airbyte
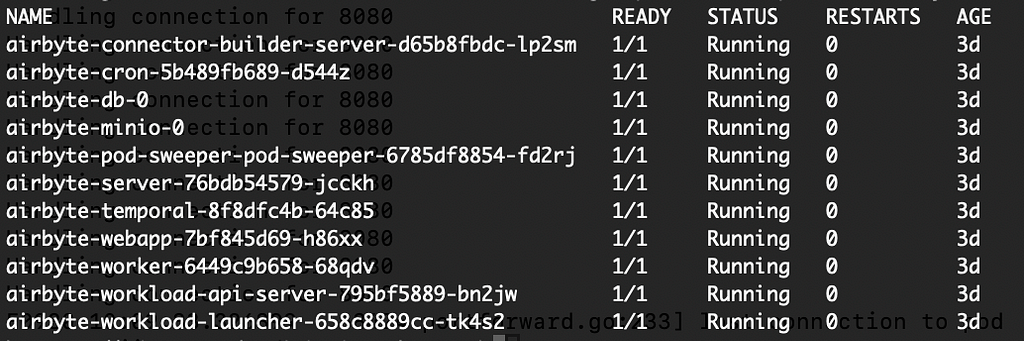
Wait a few minutes until the deployment is completed. Run the following command to check if the pods are running:
kubectl get pods --namespace dev-airbyte
Accessing the Airbyte web app locally
After Airbyte is deployed you can get the container and port, and then run a port forwarding command to map a port in your local machine to the port in the Kubernetes web app pod. This will allow us to access the application using localhost.
export POD_NAME=$(kubectl get pods - namespace dev-airbyte -l "app.kubernetes.io/name=webapp" -o jsonpath="{.items[0].metadata.name}")
export CONTAINER_PORT=$(kubectl get pod - namespace dev-airbyte $POD_NAME -o jsonpath="{.spec.containers[0].ports[0].containerPort}")
kubectl - namespace dev-airbyte port-forward $POD_NAME 8080:$CONTAINER_PORT
echo "Visit http://127.0.0.1:8080 to use your application"
If you go to 127.0.0.1:8080 on your machine, you should see the application. Now, we can start adding data connectors!
Production Tip: Port forwarding works only for your local machine and must be done every time the shell is started. However, for data teams in real scenarios, Kubernetes allows you to expose your application throughout a virtual private network. For that, you will need to switch to Airbyte Self-managed enterprise which provides Single Sign-On with Cloud identity providers like Azure Active Directory to secure your workspace.
Setting up the data source
The provider for the data in this exercise is called Tiingo, which serves very valuable information from the companies in the stock market. They offer a free license that will give you access to the end-of-day prices endpoint for any asset and fundamental analysis for companies in the DOW 30. Be mindful that with the free license, their data are for your eyes only. If you want to share your creations based on Tiingo, you must pay for a commercial license. For now, I will use the free version and guide you through the tutorial without showing their actual stock data to remain compliant with their rules.
Create the account. Then, copy the API key provided to you. We are now ready to set up the source in Airbyte.
Creating a data source in Airbyte
In the Airbyte app, go to Builder > Start from Scratch.
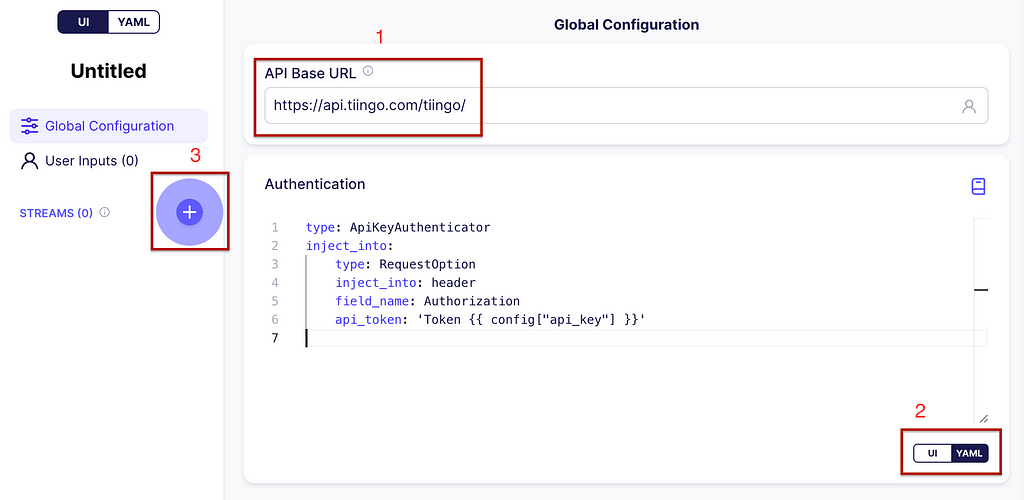
In the API Base URL write https://api.tiingo.com/tiingo/ and for the configuration click on the YAML button. Enter the following:
type: ApiKeyAuthenticator
inject_into:
type: RequestOption
inject_into: header
field_name: Authorization
api_token: 'Token {{ config["api_key"] }}'
This will allow the API token to be inserted in the header of every request. Now, let’s add your first stream by clicking on the plus icon (+) on the left. See the image below for guidance.
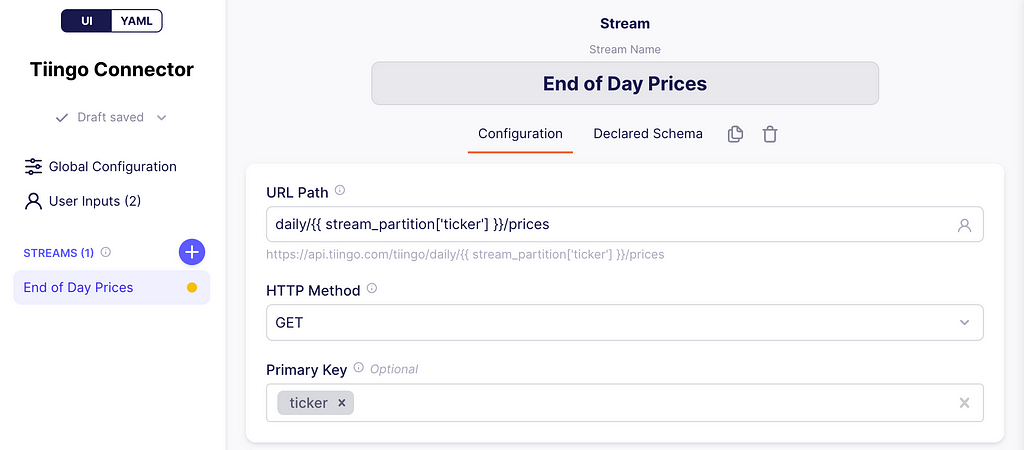
URL and stream partitioning
At the top write End of Day Prices. This will be our stream name and the URL path will be:
daily/{{ stream_partition['ticker'] }}/prices
What is this placeholder between {{}}? These are variables filled by Airbyte at runtime. In this case, Airbyte supports what they call stream partitioning, which allows the connector to make as many requests as the number of values you have on your partition array.
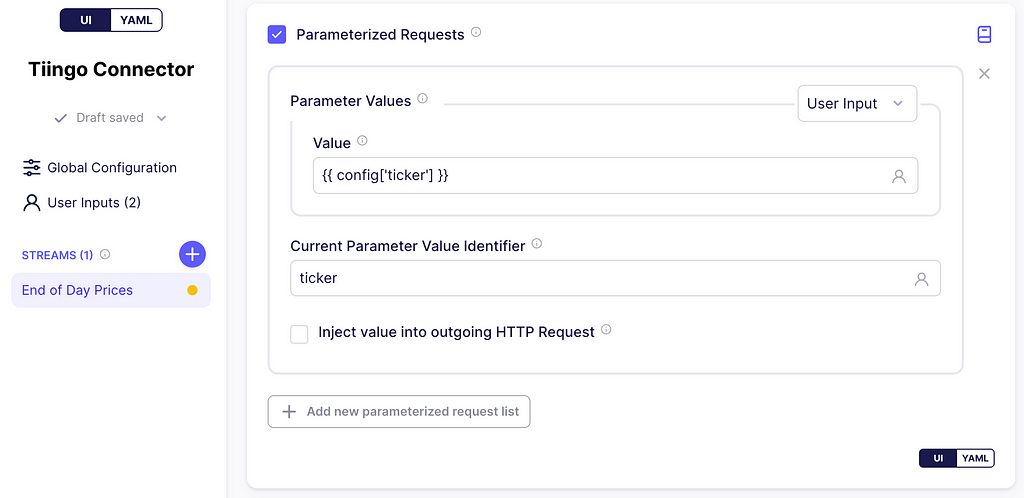
Scroll down to parameterized requests, and check the box. In the parameter values dropdown, click User Input, and on the value textbox enter:
{{ config['tickers_arr'] }}
Notice that the config variable used here is also referenced in the API Key in the global configuration. This variable holds the user inputs. Moreover, the user input tickers_arr will hold an array of stock IDs.
Next, on the Current Parameter Value Identifier textbox enter ticker. This is the key that is added to the stream_partition variable and references a single stock ID from the array tickers_arr for a single HTTP request. Below you can find screenshots of this process.
We are going to test it with 4 stock tickers:
- BA for Boeing Corp
- CAT for Caterpillar
- CVX for Chevron Corp
- KO for Coca-Cola
With the stream partitioning set up, the connector will make 4 requests to the Tiingo server as follows:
- https://api.tiingo.com/tiingo/daily/BA/prices
- https://api.tiingo.com/tiingo/daily/CAT/prices
- https://api.tiingo.com/tiingo/daily/CVX/prices
- https://api.tiingo.com/tiingo/daily/KO/prices
Pretty cool, huh?
Production Tip: Airbyte supports a parent stream, which allows us to get the list for the partitioning using a request to some other endpoint, instead of issuing the array elements ourselves. We are not doing that in this exercise, but you can check it out here.
Incremental Sync
Airbyte supports syncing data in Incremental Append mode i.e.: syncing only new or modified data. This prevents re-fetching data that you have already replicated from a source. If the sync is running for the first time, it is equivalent to a Full Refresh since all data will be considered as new.
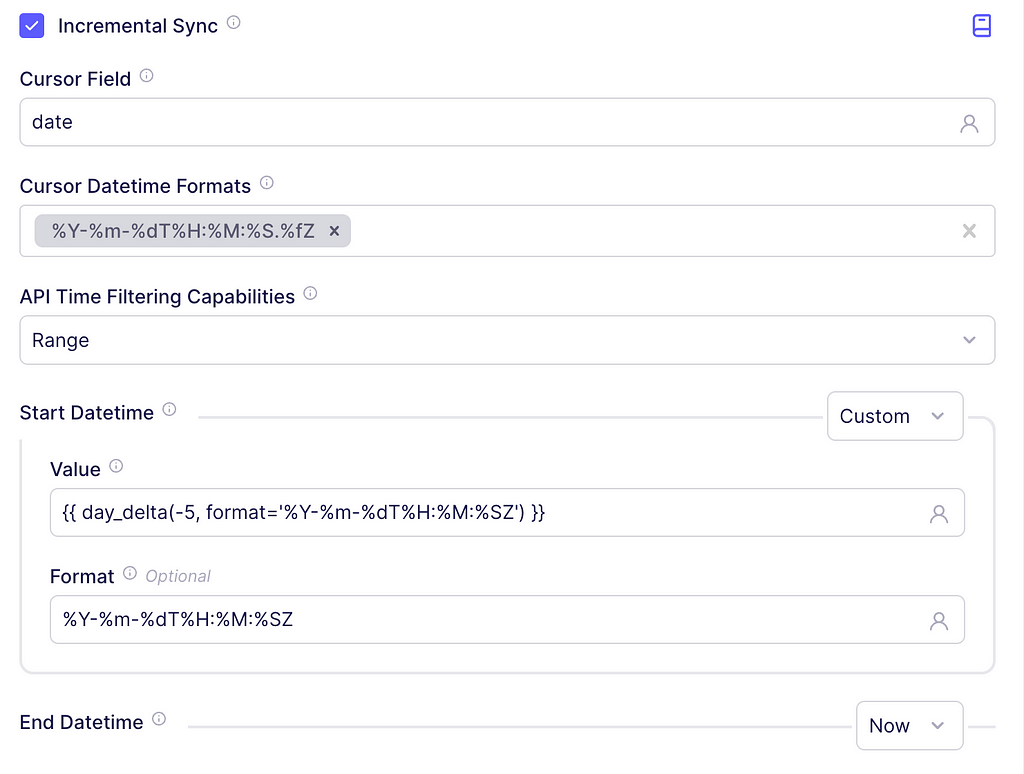
To implement this in our connector, scroll to Incremental Sync and check the box. In the cursor field textbox write date since, according to the documentation, that is the name of the date field indicating when the asset was updated. For the cursor DateTime Formats, enter
%Y-%m-%dT%H:%M:%S.%fZ
This is the output format suggested by the API docs.
In the Start DateTime dropdown click Custom and on the textbox enter the following:
{{ day_delta(-1, format='%Y-%m-%dT%H:%M:%SZ') }}
It will tell Airbyte to insert the date corresponding to yesterday. For the End Datetime leave the dropdown in Now to get data from the start date, up until today. The screenshot below depicts these steps.
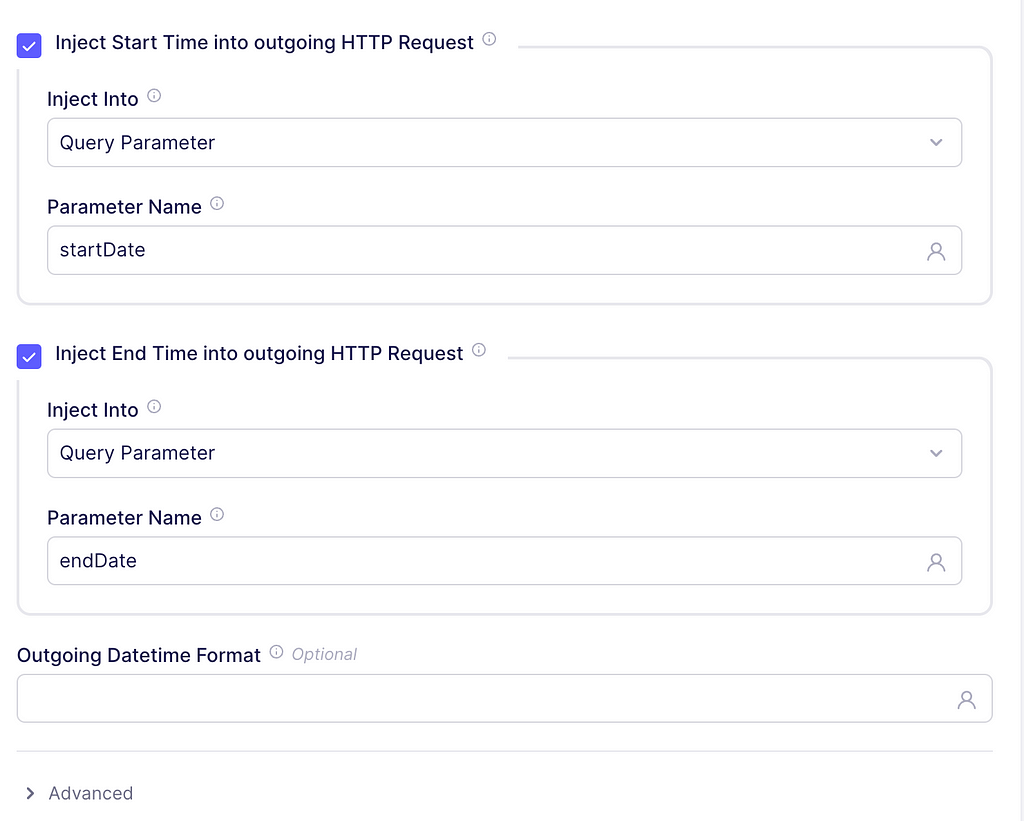
Finally, check the boxes to inject the start and end time into the outgoing HTTP request. The parameter names should be startDate and endDate, respectively. These parameter names come from Tiingo documentation as well. An example request will now look like:
Control Fields
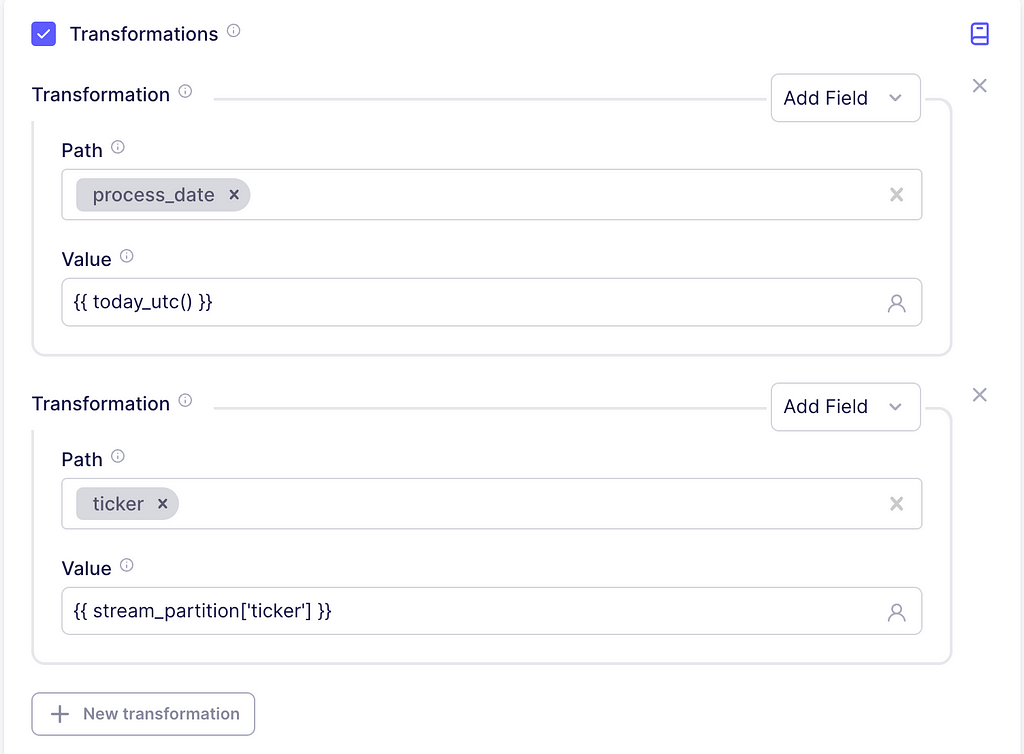
We are going to insert some information to enrich the data. For this, scroll to the transformations section and check the box. Inside the transformation dropdown, click on Add Field. The path is just the column name to be added, write process_date with the value {{ today_utc() }}. This will just indicate the timestamp for which the records were ingested into our system.
Now, according to the documentation, the ticker of the asset is not returned in the response, but we can easily add it using an additional transformation. So, for path, write ticker and the value should be {{ stream_partition[‘ticker’] }}. This will add the ticker value of the current stream partition as a column.
Testing
On the Testing values button, enter the list of tickers. A comma separates each ticker: BA, CAT, CVX, KO.
You should see something similar to the following image.
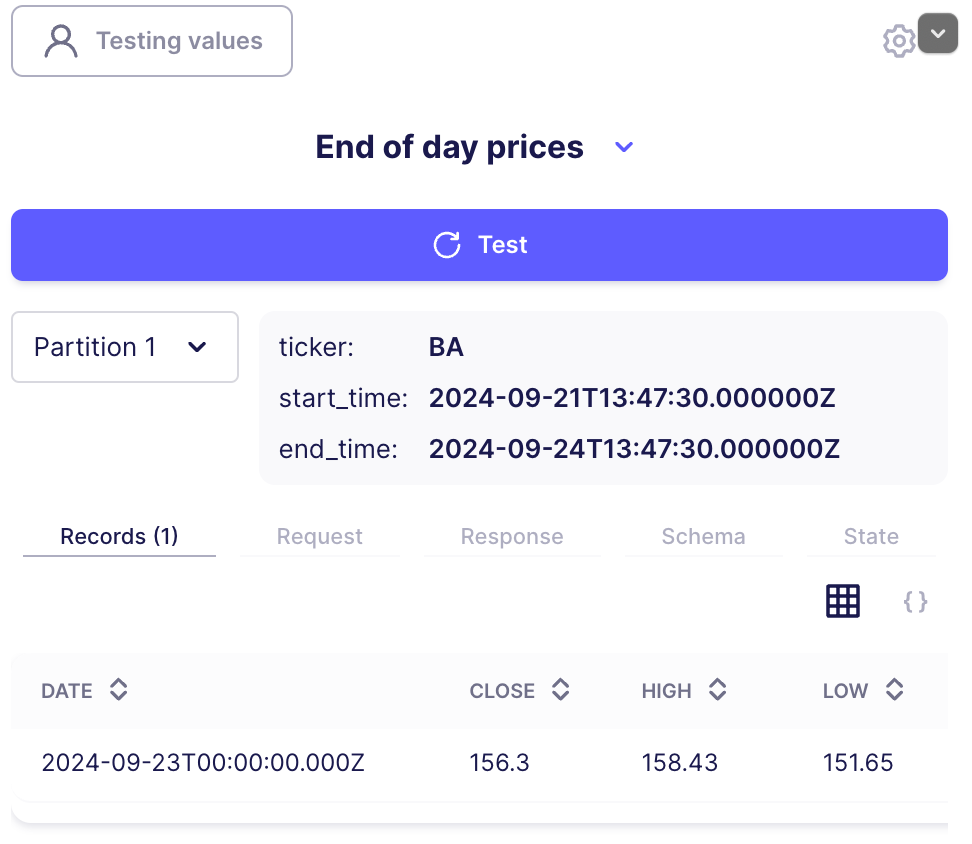
Notice the two example partitions. These are two separate, parameterized requests that Airbyte performed. You can also get information about the actual content in your request, the generated schema of the data, and state information.
Go to the top right corner and click publish to save this connector. Give it any name you want, I just called it Tiingo Connector.
Connecting Airbyte to the object store
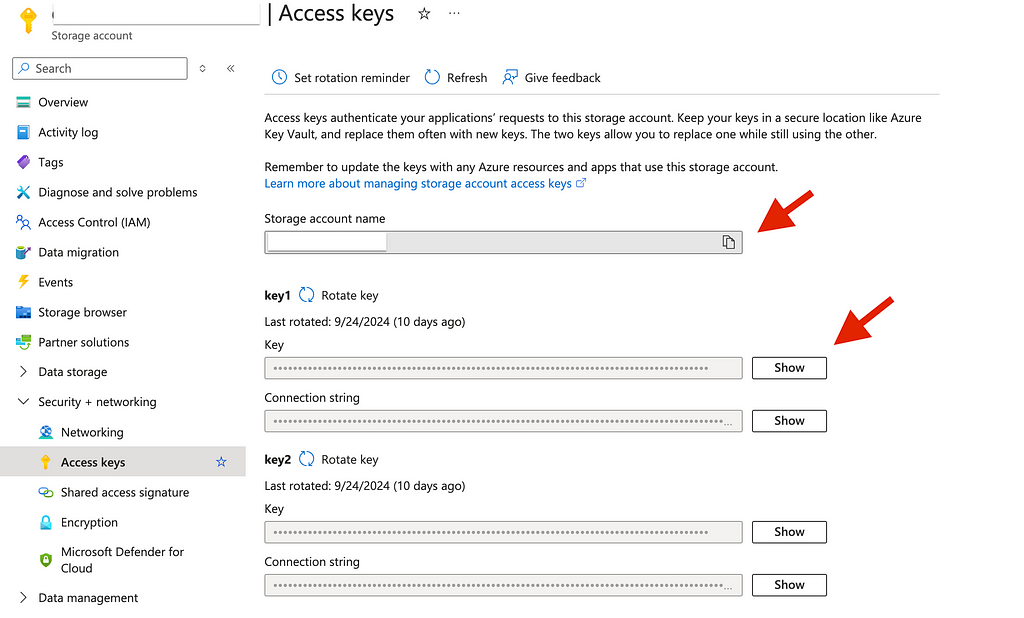
Let’s return to our storage service, go to Security + Networking > Access keys. Copy the account name and one of the access keys. Note: we need the access key, not the connection string.
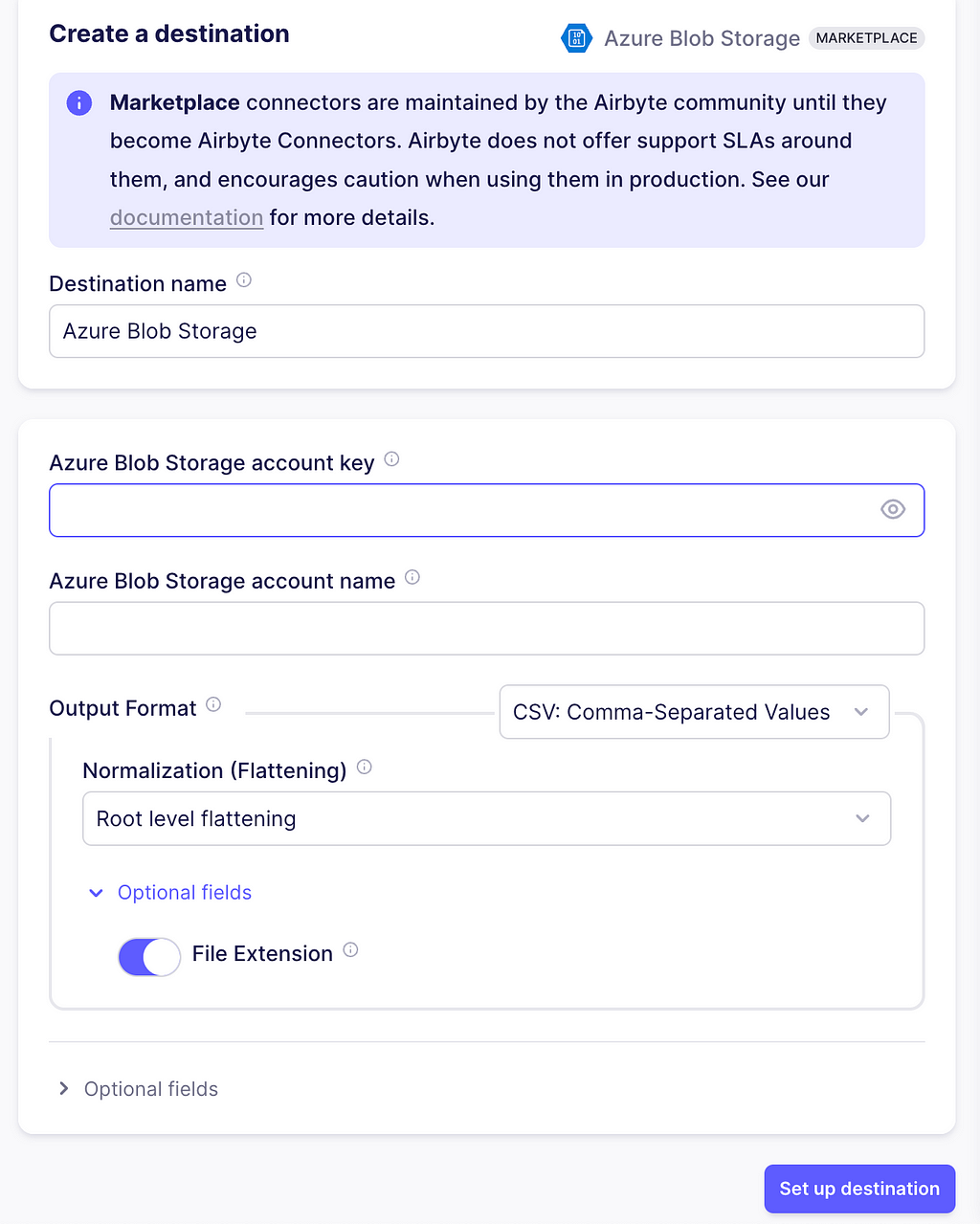
Next, go to your Airbyte app, select Destinations> Marketplace, and click Azure Blob Storage. Enter the account name, account key, and leave the other configurations as in the image. Additionally, in the Optional fields, enter the name of the container you created. Next, click on Set up destination.
Production Tip: Data assets from your organization need to be secured so that the individuals or teams have access to only the files they need. You can set up role-based access control at the storage account level with the Access Control (IAM) button, and also set Access Control Lists (ACLs) when right clicking folders, containers, or files.
Creating a connection from source to destination
There are four steps to build a connection in Airbyte and it will use the Tiingo Connector and the Azure Storage.
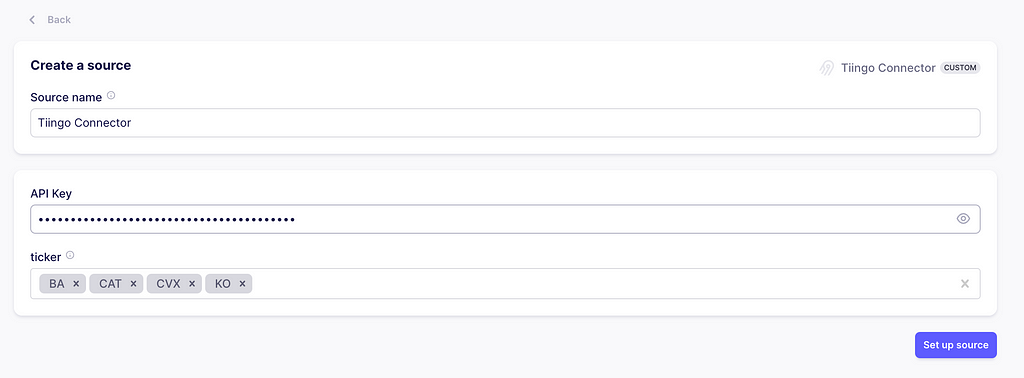
Defining the source
In the Airbyte app, go to connections and create one. The first step is to set up the source. Click Set up a new source. Then, on the Custom tab, select the Tiingo connector we just created.
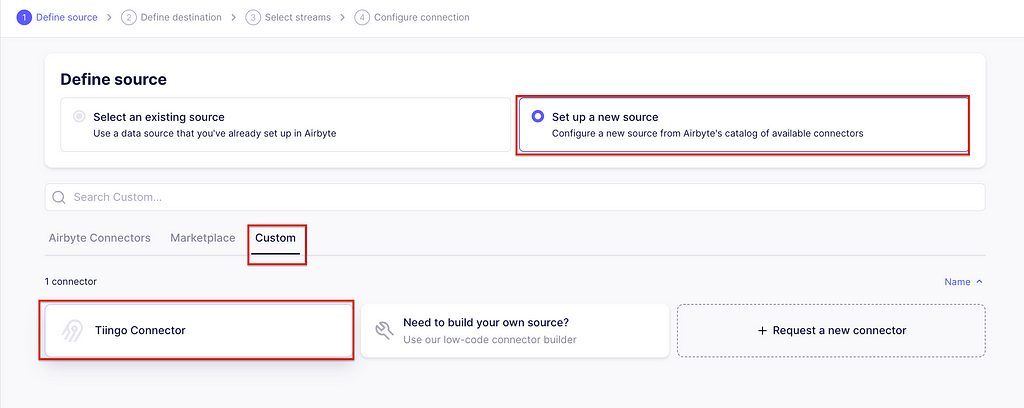
It will prompt you to enter the API Keys and stock tickers. Just copy the ones you used while testing the source. Now click on Set up source. It will test the connector with your configuration.
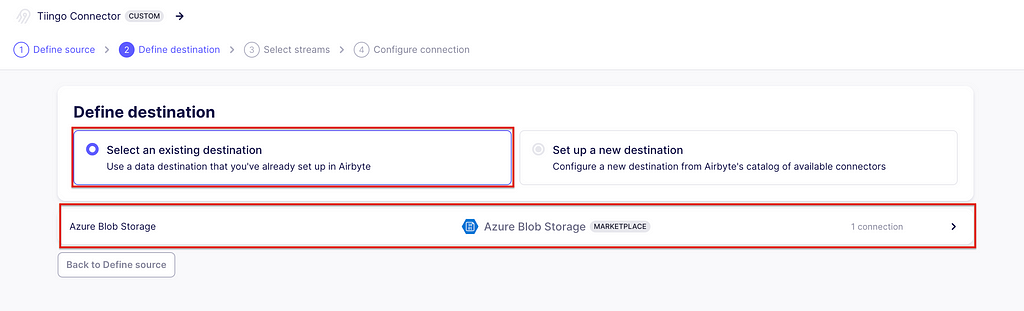
Defining the destination
Once it has passed, we will set up the destination, which is the one created in the above section. At this time, Airbyte will also test the destination.
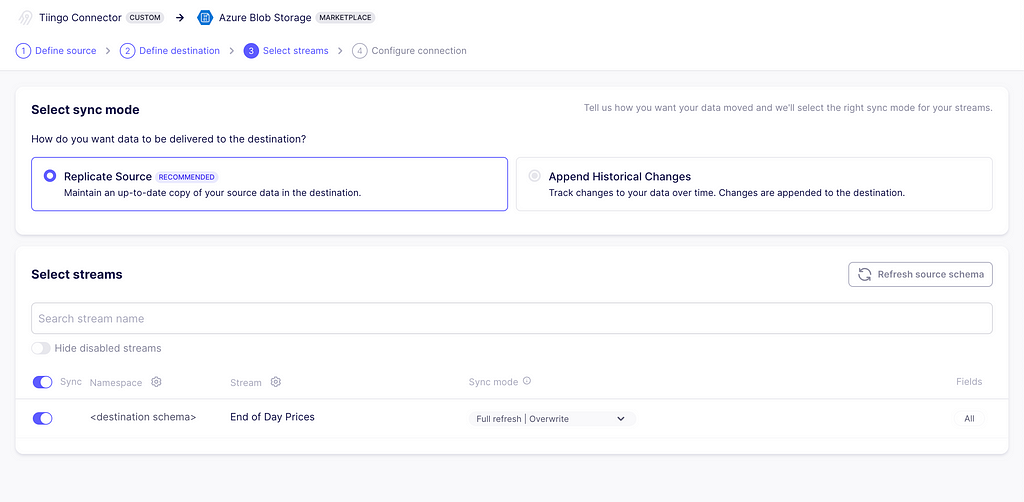
Defining streams
The third step is to select the streams and the sync mode. As we only defined one stream called End of Day Prices, this is the only one available. As for the sync modes, these are the options available for this exercise:
- Full Refresh | Overwrite: This mode will retrieve all the data and replace any existing data in the destination.
- Full Refresh | Append: This mode will also retrieve all of the data, but it will append the new data to the destination. You must deduplicate or transform your data properly to suit your needs afterward.
- Incremental | Append: This mode requests data given the incremental conditions we defined while building the connector. Then, it will append the data to the destination.
You can read more about synch modes here. For now, choose Incremental | Append.
Final connection configurations
Here you can define the schedule you want, plus other additional settings. Click finish and sync to prompt your first data extraction and ingestion.
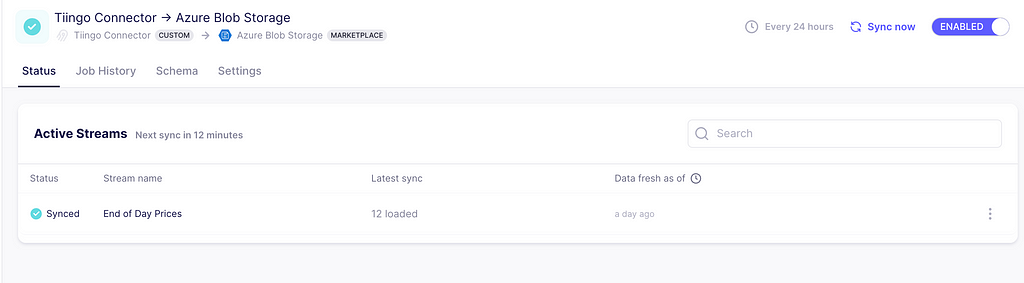
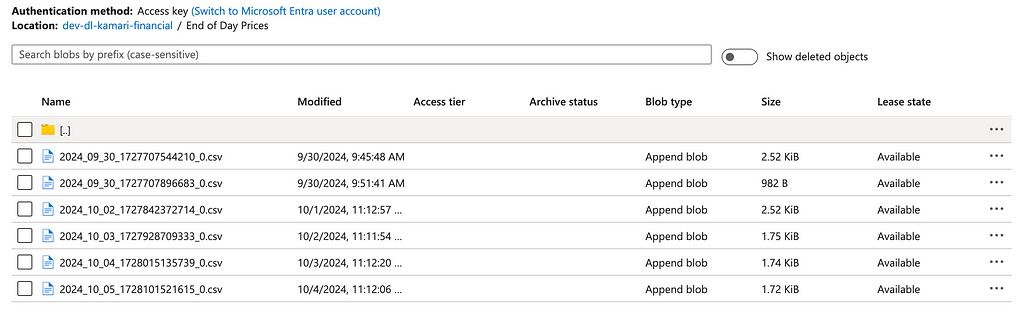
And that’s it! The data is now ingested. Head back to the storage container and you will see a new folder with one CSV file. With the append mode chosen, whenever a sync is triggered, a new file appears in the folder.
Conclusion
You can clearly see the power of these kinds of tools. In this case, Airbyte allows you to get started with ingesting critical data in a matter of minutes with production-grade connectors, without the need to maintain large amounts of code. In addition, it allows incremental and full refresh modes with append or overwrite capabilities. In this exercise, only the Rest API sources were demonstrated, but there are many other source types, such as traditional databases, data warehouses, object stores, and many other platforms. Finally, it also offers a variety of destinations where your data can land and be analyzed further, greatly speeding up the development process and allowing you to take your products to market faster!
Thank you for reading this article! If you enjoyed it, please give it a clap and share. I do my best to write about the things I learn in the data world as an appreciation for this community that has taught me so much.
Till the next time!
Low-Code Data Connectors and Destinations was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Low-Code Data Connectors and Destinations
Go Here to Read this Fast! Low-Code Data Connectors and Destinations