Long-form video representation learning (Part 3: Long-form egocentric video representation learning)
We explore novel video representation learning methods that are equipped with long-form reasoning capability. This is Part III providing a sneak peek into our latest and greatest explorations for “long-form” egocentric video representation learning. See Part I on video as a graph and is Part II on sparse video-text transformers.
The first two blogs in this series described how different architectural motifs ranging from graph neural networks to sparse transformers addressed the challenges of “long-form” video representation learning. We showed how explicit graph based methods can aggregate 5-10X larger temporal context, but they were two-stage methods. Next, we explored how we can make memory and compute efficient end-to-end learnable models based on transformers and aggregate over 2X larger temporal context.
In this blog, I’ll take you to our latest and greatest explorations, especially for egocentric video understanding. As you can imagine, an egocentric or first-person video (captured usually by head-mounted cameras) is most likely coming from an always-ON camera, meaning the videos are really really long, with a lot of irrelevant visual information, specially when the camera wearer move their heads. And, this happens a lot of times with head mounted cameras. A proper analysis of such first-person videos can enable a detailed understanding of how humans interact with the environment, how they manipulate objects, and, ultimately, what are their goals and intentions. Typical applications of egocentric vision systems require algorithms able to represent and process video over temporal spans that last in the order of minutes or hours. Examples of such applications are action anticipation, video summarization, and episodic memory retrieval.
Egocentric action scene graphs:
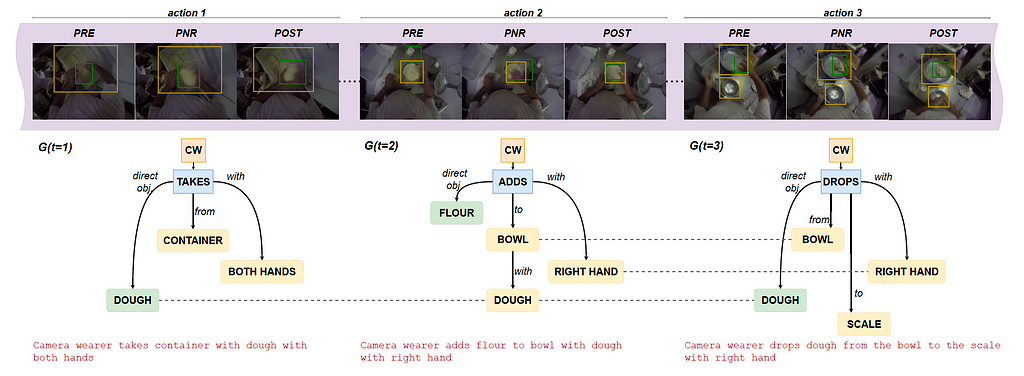
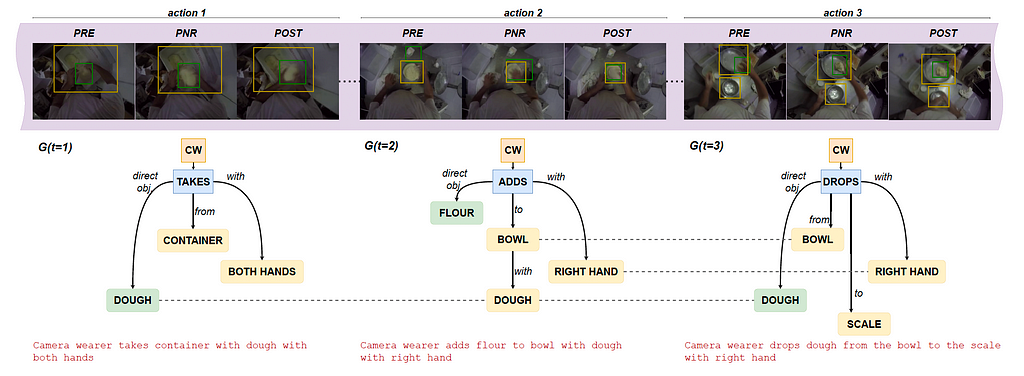
We present Egocentric Action Scene Graphs (EASGs), a new representation for long-form understanding of egocentric videos. EASGs extend standard manually-annotated representations of egocentric videos, such as verb-noun action labels, by providing a temporally evolving graph-based description of the actions performed by the camera wearer. The description also includes interacted objects, their relationships, and how actions unfold in time. Through a novel annotation procedure, we extend the Ego4D dataset adding manually labeled Egocentric Action Scene Graphs which offer a rich set of annotations for long-from egocentric video understanding.
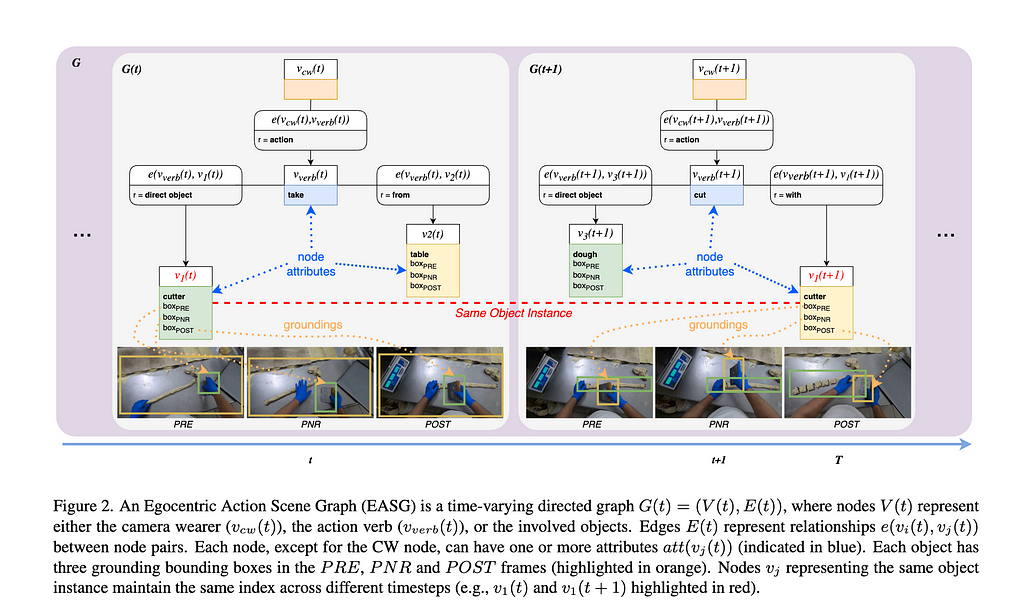
EASGs provide annotations for a video clip in the form of a dynamic graph. We formalize an EASG as a time-varying directed graph G(t) = (V (t), E(t)), where V (t) is the set of nodes at time t and E(t) is the set of edges between such nodes (Figure 2). Each temporal realization of the graph G(t) corresponds to an egocentric action spanning over a set of three frames defined as in [Ego4D]: the precondition (PRE), the point of no return (PNR) and the postcondition (POST) frames. The graph G(t) is hence effectively associated to three frames: F(t) = {PREₜ, PNRₜ, POSTₜ}, as shown in figure 1 below.
Egocentric scene graph generation:
Figure 2 shows an example of an annotated graph in details.
We obtain an initial EASG leveraging existing annotations from Ego4D, with initialization and refinement procedure. e.g. we begin with adding the camera wearer node, verb node and and the default action edge from camera wearer node to the verb node. The annotation pipeline is shown in figure 3 below.
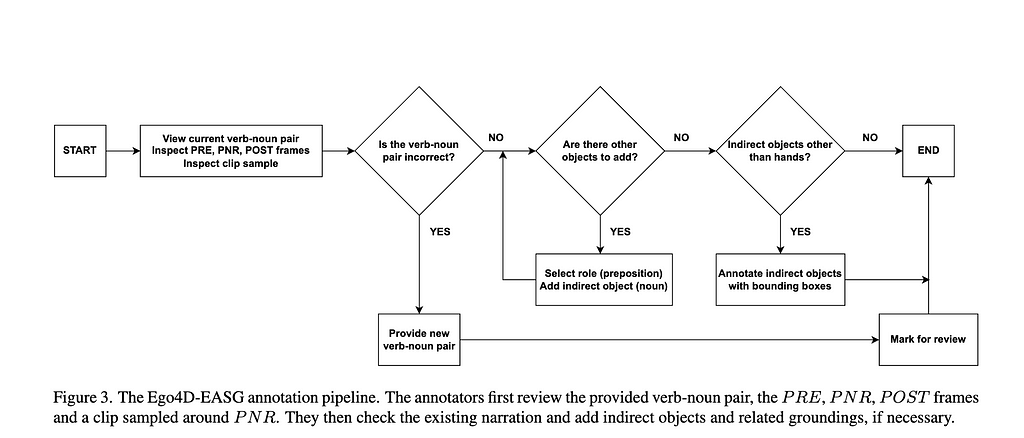
Next, we do the graph refinement via inputs from 3 annotators. The validation stage aggregates the data received from three annotators and ensures the quality of the final annotations as shown below.

the labels provided in the annotation stage.
As it can be noted, the EASG dataset is unique in its labels. And, in the table below you can see how this new dataset compares with other video datasets with visual relations, in terms of labels and size.

After the creation of this unique dataset, we will now describe different tasks that are evaluated on this dataset. The first set of tasks is about generating action scene graphs which stems from the image scene graph generation literature. In other words we aim to learn EASG representations in a supervised way and measure its performance in standard Recall metrics used in scene graph literature. We devise baselines and compare the EASG generation performance of different baselines on this dataset.

Long-from understanding tasks with EASG:
We show the potential of the EASG representation in the downstream tasks of action anticipation and activity summarization. Both tasks require to perform long-form reasoning over the egocentric video, processing long video sequences spanning over different time-steps. Following recent results showing the flexibility of Large Language Models (LLMs) as symbolic reasoning machines, we perform these experiments with LLMs accessed via the OpenAI API. The experiments aim to examine the expressive power of the EASG representation and its usefulness for downstream applications. We show that EASG offers an expressive way of modeling long-form activities, in comparison with the gold-standard verb-noun action encoding, extensively adopted in egocentric video community.
Action anticipation with EASGs:
For the action anticipation task, we use the GPT3 text-davinci-003 model. We prompt the model to predict the future action from a sequence of length T ∈ {5, 20}. We compare two types of representations — EASG and sequences of verb-noun pairs. Below table shows the results of this experiment.

Even short EASG sequences (T =5) tend to outperform long V-N sequences (T = 20), highlighting the higher representation power of EASG, when compared to standard verb-noun representations. EASG representations achieve the best results for long sequences (T = 20).
Long-form activity summarization with EASGs:
We select a subset of 147 Ego4D-EASG clips containing human-annotated summaries describing the activities performed within the clip in 1–2 sentences from Ego4D. We construct three types of input sequences: sequences of graphs S-EASG = [G(1), G(2), …, G(Tmax)], sequences of verb-noun pairs svn = [s-vn(1), s-vn(2), …, s-vn(Tmax)], and sequences of original Ego4D narrations, matched with the EASG sequence. This last input is reported for reference, as we expect summarization from narrations to bring the best performance, given the natural bias of language models towards this representation.
Results reported in the below table indicate strong improvement in CIDEr score over the sequence of verb-noun inputs, showing that models which process EASG inputs capturing detailed object action relationships, will generate more specific, informative sentences that align well with reference descriptions.

We believe that these contributions mark a step forward in long-form egocentric video understanding.
Highlights:
- We introduce Egocentric Action Scene Graphs, a novel representation for long-form understanding of egocentric videos;
- We extend Ego4D with manually annotated EASG labels, which are gathered through a novel annotation procedure;
- We propose a EASG generation baseline and provide initial baseline results;
- We present experiments that highlight the effectiveness of the EASG representation for long-form egocentric video understanding. We will release the dataset and the code to replicate data annotation and the
experiments; - We will present this work at CVPR 2024, next month.
Temporal grounding for episodic tasks:
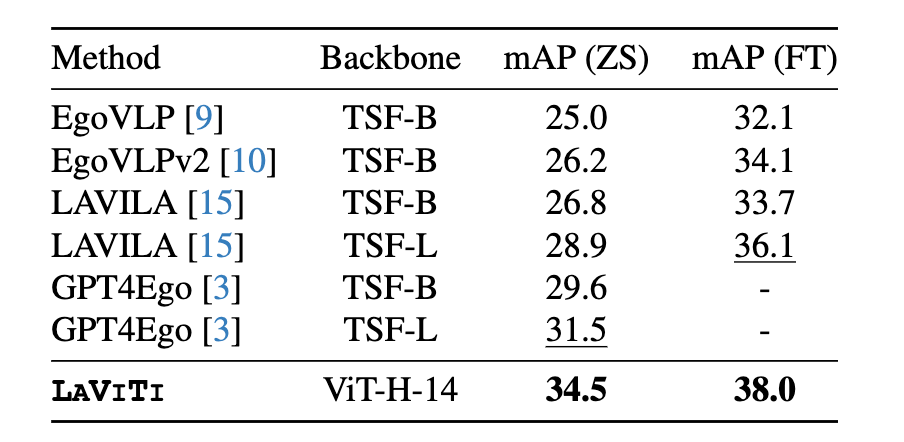
In recent years, egocentric video-language pre-training (VLP) has been adopted significantly in academia and in industry. A line of works such as EgoVLP, EgoVLPv2 learn transferable spatial-temporal representations from large-scale video-text datasets. Recently, LaViLa showed that VLP can benefit from the dense narrations generated by Large Language Models (LLMs). However, all such methods do hit the memory and compute bottleneck while processing video sequences, each consisting of a small number of frames (e.g. 8 or 16 frame models), leading to limited temporal context aggregation capability. On the contrary, our model, called LAVITI, is equipped with long-form reasoning capability (1,000 frames vs 16 frames) and is not limited to a small number of input frames.
In this ongoing work, we devised a novel approach to learning language, video, and temporal representations in long-form videos via contrastive learning. Unlike existing methods, this new approach aims to align language, video, and temporal features by extracting meaningful moments in untrimmed videos by formulating it as a direct set prediction problem. LAVITI outperforms existing state-of-the-art methods by a significant margin on egocentric action recognition, yet is trainable on memory and compute-bound systems. Our method can be trained on the Ego4D dataset with only 8 NVIDIA RTX-3090 GPUs in a day.
As our model is capable of long-form video understanding with explicit temporal alignment, the Ego4D Natural Language Query (NLQ) task is a natural fit with the pre-training targets. We can directly predict intervals which are aligned with language query given a video; therefore, LAVITI can
perform the NLQ task under the zero-shot setting (without modifications of the architecture and re-training on NLQ annotations).
In the near future, we plan on assessing its potential to learn improved representations for episodic memory tasks including NLQ and Moment Query (MQ). To summarize, we are leveraging existing foundation models (essentially “short-term”) for creating “long-form” reasoning module aiming at 20X-50X larger context aggregation.
Highlights:
We devised exciting new ways for egocentric video understanding. Our contributions are manifold.
- Pre-training objective aligns language, video, and temporal features jointly by extracting meaningful moments in untrimmed videos;
- formulating the video, language and temporal alignment as a direct set prediction problem;
- enabling long-form reasoning over potentially thousands of frames of a video in a memory-compute efficient way;
- demonstrating the efficacy of LAVITI by its superior performance on CharadesEgo action recognition;
- Enabling zero-shot natural language query (NLQ) task without needing to train additional subnetworks or NLQ annotations.
Watch out for more exciting results with this new paradigm of “long-form” video representation learning!
Long-form video representation learning (Part 3: Long-form egocentric video representation… was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Long-form video representation learning (Part 3: Long-form egocentric video representation…