We explore novel video representations methods that are equipped with long-form reasoning capability. This is part II focusing on sparse video-text transformers. See Part I on video as graphs. And Part III provides a sneak peek into our latest and greatest explorations.
The first blog in this series was about learning explicit sparse graph-based video representation methods for “long-form” video representation learning. They are effective methods; however, they were not end-to-end trainable. We needed to rely on other CNN or transformer-based feature extractors to generate the initial node embeddings. In this blog, our focus is to devising an end-to-end methods using transformers, but with the same goal of “long-form” reasoning.
Sparse Video-Text Transformers
As an end-to-end learnable architecture, we started exploring transformers. The first question we needed an answer for is that do video-text transformers learn to model temporal relationships across frames? We oberved that despite their immense capacity and the abundance of multimodal training data, recent video models show strong tendency towards frame-based spatial representations, while temporal reasoning remains largely unsolved. For example, if we shuffle the order of video frames in the input to the video models, the output do not change much!
Upon a closer investigation, we identify a few key challenges to incorporating multi-frame reasoning in video-language models. First, limited model size implies a trade-off between spatial and temporal learning (a classic example being 2D/3D convolutions in video CNNs). For any given dataset, optimal performance requires a careful balance between the two. Second, long-term video models typically have larger model sizes and are more prone to overfitting. Hence, for long-form video models, it becomes more important to carefully allocate parameters and control model growth. Finally, even if extending the clip length improves the results, it is subject to diminishing returns since the amount of information provided by a video clip does not grow linearly with its sampling rate. If the model size is not controlled, the compute increase may not justify the gains in accuracy. This is critical for transformer-based architectures, since self-attention mechanisms have a quadratic memory and time cost with respect to input length.
In summary, model complexity should be adjusted adaptively, depending on the input videos, to achieve the best trade-off between spatial representation, temporal representation, overfitting potential, and complexity. Since existing video-text models lack this ability, they either attain a suboptimal balance between spatial and temporal modeling, or do not learn meaningful temporal representations at all.
What can be made “sparse” in video transformers ? Nodes and Edges:
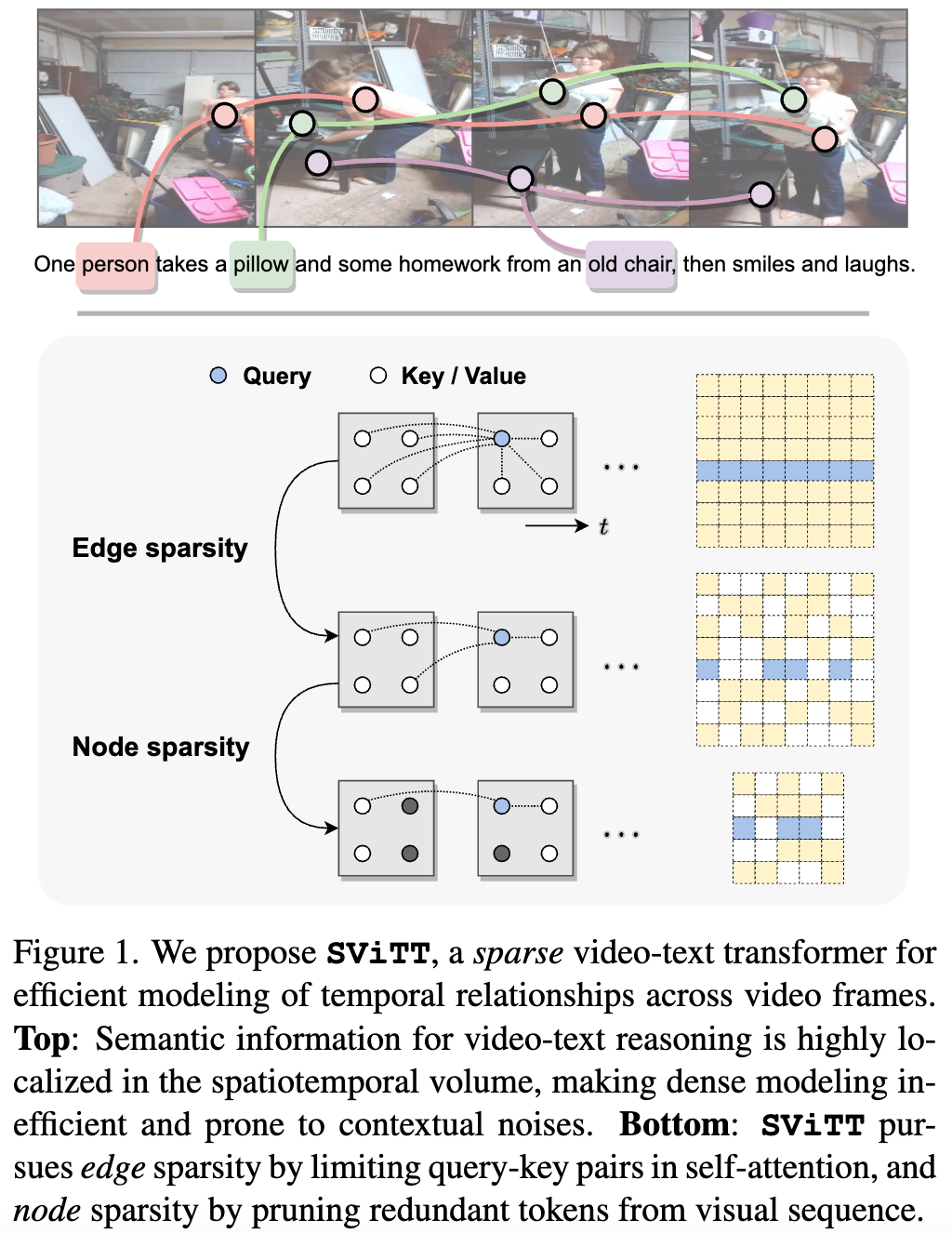
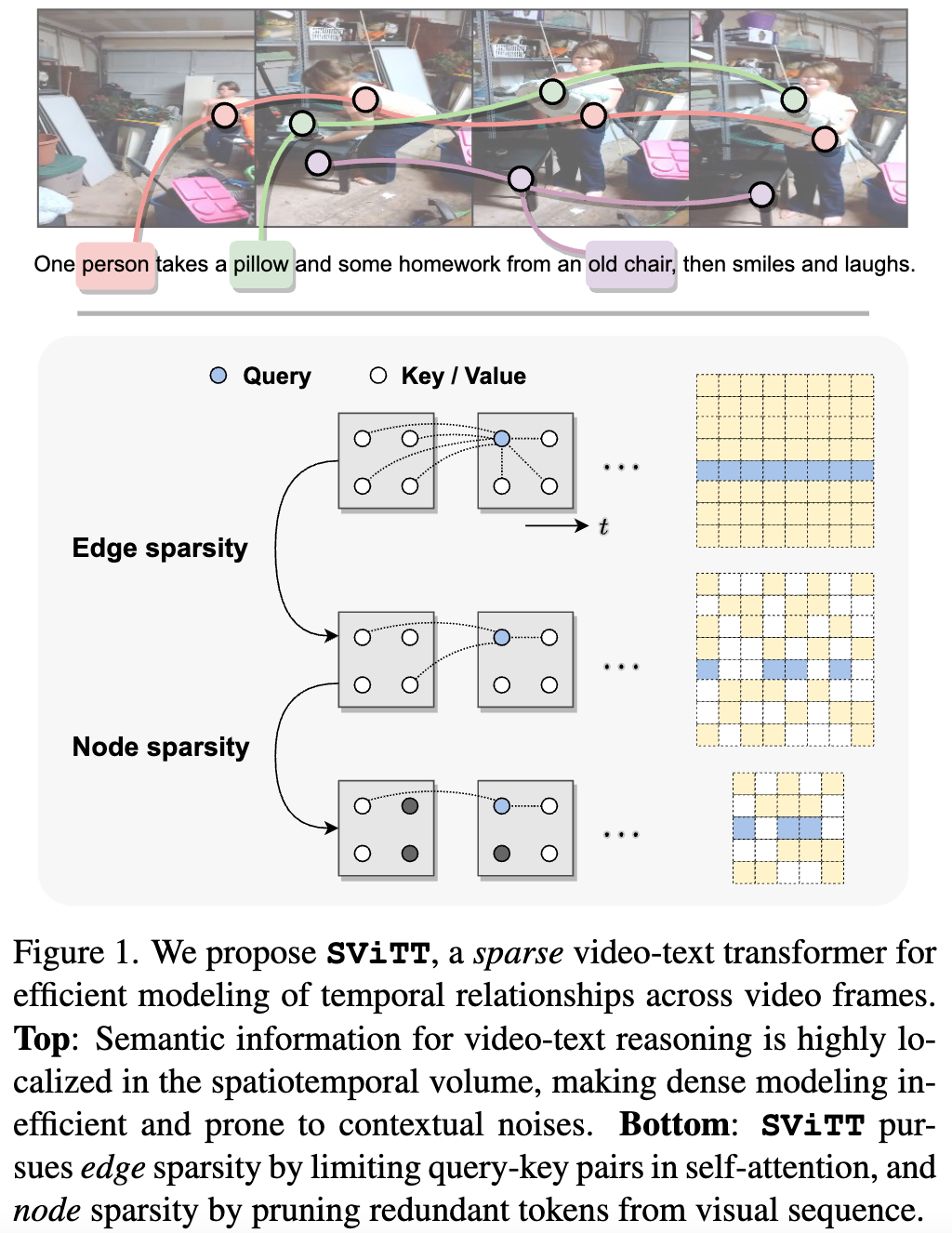
We argue that video-text models should learn to allocate modeling resources to the video data. Rather than uniformly extending the model to longer clips, the allocation of these resources to the relevant spatio-temporal locations of the video is crucial for efficient learning from long clips. For transformer models, this allocation is naturally performed by pruning redundant attention connections. We then accomplish these goals by exploring transformer sparsification techniques. This motivates the introduction of a Sparse Video-Text Transformer SViTT inspired by graph models. As illustrated in Figure 1, SViTT treats video tokens as graph vertices, and self-attention patterns as edges that connect them.
We design SViTT to pursue sparsity for both: Node sparsity reduces to identifying informative tokens (e.g., corresponding to moving objects or person in the foreground) and pruning background feature embeddings; edge sparsity aims at reducing query-key pairs in attention module while maintaining its global reasoning capability. And, node sparsity reduces to identifying informative tokens (e.g., corresponding to moving objects or person in the foreground) and pruning background feature embeddings. To address the diminishing returns for longer input clips, we propose to train SViTT with temporal sparse expansion, a curriculum learning strategy that increases clip length and model sparsity, in sync, at each training stage.

results: (1) Left: A training sample includes a description (sentence at the top) and a video clip (the sequence of frames of a video), (2) Middle: video encoder’s layer 10 after visual token pruning; (3) Right: Multimodal encoder’s output after token pruning.
Applications, Evaluation and Results
SViTT is evaluated on diverse video-text benchmarks from video retrieval to question answering, comparing to prior art and our own dense modeling baselines. First, we perform a series of ablation studies to understand the benefit of sparse modeling in transformers. Interestingly, we find that both nodes (tokens) and edges (attention) can be pruned drastically at inference, with a small impact on test performance. In fact, token selection using cross-modal attention improves retrieval results by 1% without re-training. Figure 2 shows that SViTT isolates informative regions from background patches to facilitate efficient temporal reasoning.
We next perform full pre-training with the sparse models and evaluate their downstream performance. We observe that SViTT scales well to longer input clips, where the accuracy of dense transformers drop due to optimization difficulties. On all video-text benchmarks, SViTT reports comparable or better performance than their dense counterparts with lower computational cost, outperforming prior arts including those trained with additional image-text corpora.
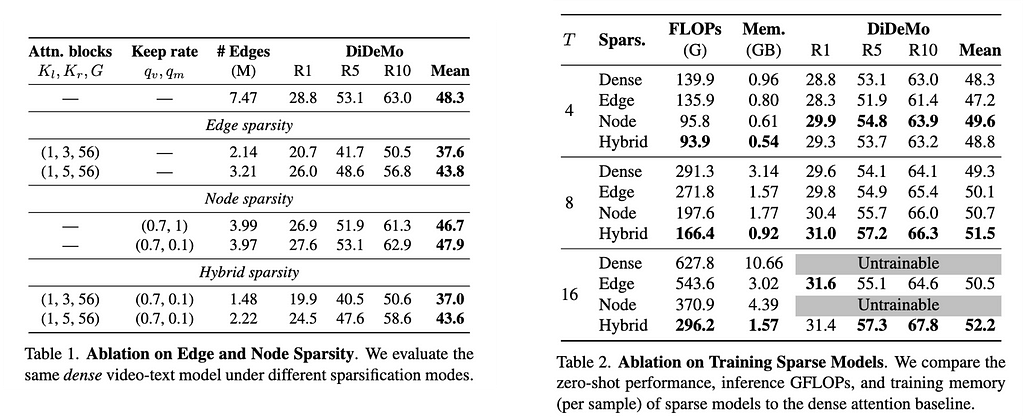
We can see from the above tables, with sparsification, immediate temporal context aggregation could be made 2X longer (table 2). Also see how sparsification maintains the final task accuracies (table 1), rather improves them.
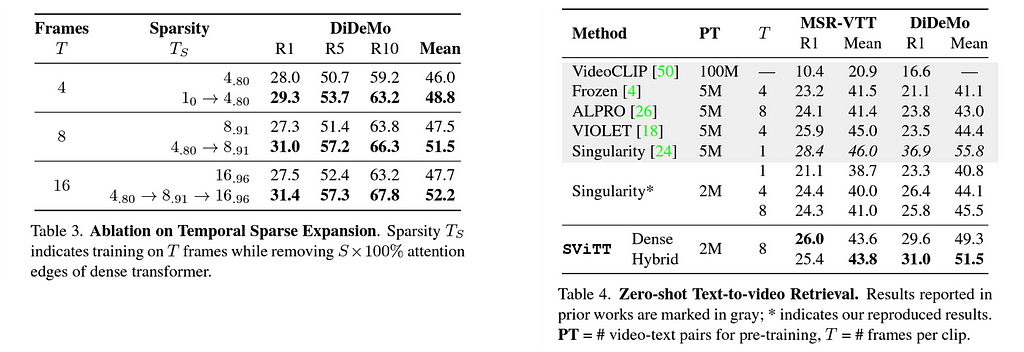
In the above table, we show how our proposed training paradigm helps improve task performance with respect to the different levels of sparsity. In table 4, you can see the zero-shot performance on text-to-video retrieval task on two standard benchmarks.
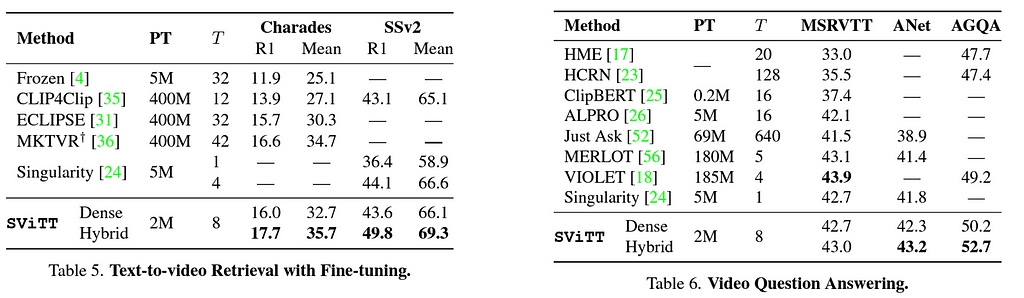
Finally, we show the results on different benchmarks on multimodal retrieval and video question-answering. SViTT outperforms all existing methods, and even required less number of pre-training pairs.
More details on SViTT can be found here . To summarize, Compared to original transformers, SViTT is 6–7 times more efficient, capable of 2X more context aggregation. Pre-training with SViTT improves accuracy SoTA on 5 benchmarks : retrieval, VideoQ&A.
SViTT-Ego for egocentric videos:
Pretraining egocentric vision-language models has become essential to improving downstream egocentric video-text tasks. These egocentric foundation models commonly use the transformer architecture. The memory footprint of these models during pretraining can be substantial. Therefore, we pre-train our own sparse video-text transformer model, SViTT-Ego, the first sparse egocentric video-text transformer model integrating edge and node sparsification. We pretrain on the EgoClip dataset and incorporate the egocentric-friendly objective EgoNCE, instead of the frequently used InfoNCE. Most notably, SViTT-Ego, obtains a 2.8% gain on EgoMCQ (intra-video) accuracy compared to the current SOTA, with no additional data augmentation techniques other than standard image augmentations, yet pre-trainable on memory-limited devices. One such visual example is shown below. We are preparing to participate in the EgoVis workshop at CVPR with our SViTT-ego.

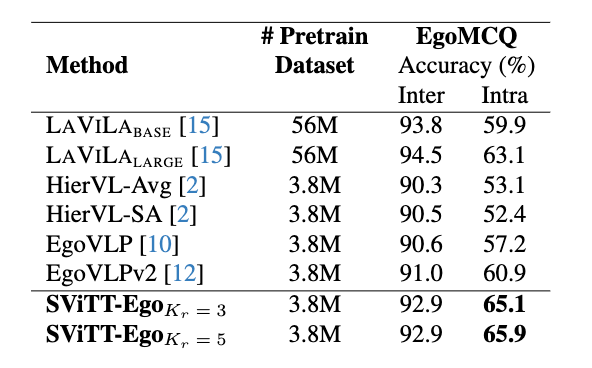
intra-video accuracy. When considering models trained solely on
3.8M samples without narration augmentations, SViTT-Ego out-
performs all models in inter-video and intra-video accuracy

results with the vision encoder: row 1, shows 4 frame input; row
2, shows video encoder’s layer 4 after visual token pruning; row 3,
shows video encoder’s layer 7 after visual token pruning; and row
4, shows video encoder’s layer 10 after visual token pruning. We
follow SViTT to prune visual tokens
Highlights:
We propose, SViTT, a video-text architecture that unifies edge and node sparsity; We show its temporal modeling efficacy on video-language tasks. Compared to original transformers, SViTT is 6–7 times more efficient, capable of 2X more context aggregation. Pre-training with SViTT improves accuracy over SoTA on 5 benchmarks : retrieval, VideoQ&A. Our video-text sparse transformer work was first published at CVPR 2023.
Next, we show how we are leveraging such sparse transformer for egocentric video understanding applications. We show our SViTT-Ego (built atop SViTT) outperforms dense transformer baselines on the EgoMCQ task with significantly lower peak memory and compute requirements thanks to the inherent sparsity. This shows that sparse architectures such as SViTT-Ego is a potential foundation model choice, especially for pretraining on memory-bound devices. Watch out for exciting news in the near future!
Long-form video representation learning (Part 2: Video as sparse transformers) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Long-form video representation learning (Part 2: Video as sparse transformers)