

lintsampler is a pure Python package that can easily and efficiently generate random samples from any probability distribution.
Full disclosure: I am one of the authors of lintsampler.
Why you need lintsampler
We often find ourselves in situations where we have a probability distribution (PDF) and we need to draw random samples it. For example, we might want to estimate some summary statistics or to create a population of particles for a simulation.
If the probability distribution is a standard one, such as a uniform distribution or a Gaussian (normal) distribution, then the numpy/scipy ecosystem provides us with some easy ways to draw these samples, via the numpy.random or scipy.stats modules.
However, out in the wild, we often encounter probability distributions that are not Gaussian. Sometimes, they are very not Gaussian. For example:
How would we draw samples from this distribution?
There are a few widely-used techniques to draw samples from arbitrary distributions like this, such as rejection sampling or Markov chain Monte Carlo (MCMC). These are excellent and reliable methods, with some handy Python implementations. For example, emcee is an MCMC sampler widely used in scientific applications.
The problem with these existing techniques is that they require a fair amount of setup and tuning. With rejection sampling, one has to choose a proposal distribution, and a poor choice can make the procedure very inefficient. With MCMC one has to worry about whether the samples are converged, which typically requires some post-hoc testing to gauge.
Enter lintsampler. It’s as easy as:
from lintsampler import LintSampler
import numpy as np
x = np.linspace(xmin, xmax, ngrid)
y = np.linspace(ymin, ymax, ngrid)
sampler = LintSampler((x, y), pdf)
pts = sampler.sample(N=100000)
In this code snippet, we constructed 1D arrays along each of the two dimensions, then we fed them to the LintSampler object (imported from the lintsampler package) along with a pdf function representing the probability distribution we want to draw samples from. We didn’t spell out the pdf function in this snippet, but there are some fully self-contained examples in the docs.
Now, pts is an array containing 100000 samples from the PDF. Here they are in a scatter plot:

The point of this example was to demonstrate how easy it is to set up and use lintsampler. In certain cases, it is also much faster and more efficient than MCMC and/or rejection sampling. If you’re interested to find out how lintsampler works under the hood, read on. Otherwise, visit the docs, where there are instructions describing how to install and use lintsampler, including example notebooks with 1D, 2D, and 3D use cases, as well as descriptions of some of lintsampler’s additional features: quasi Monte Carlo sampling (a.k.a. low discrepancy sequencing), and sampling on an adaptive tree structure. There is also a paper published in the Journal of Open Source Software (JOSS) describing lintsampler.
How lintsampler works
Underlying lintsampler is an algorithm we call linear interpolant sampling. The theory section of the docs gives a more detailed and more mathematical description of how the algorithm works, but here it is in short.
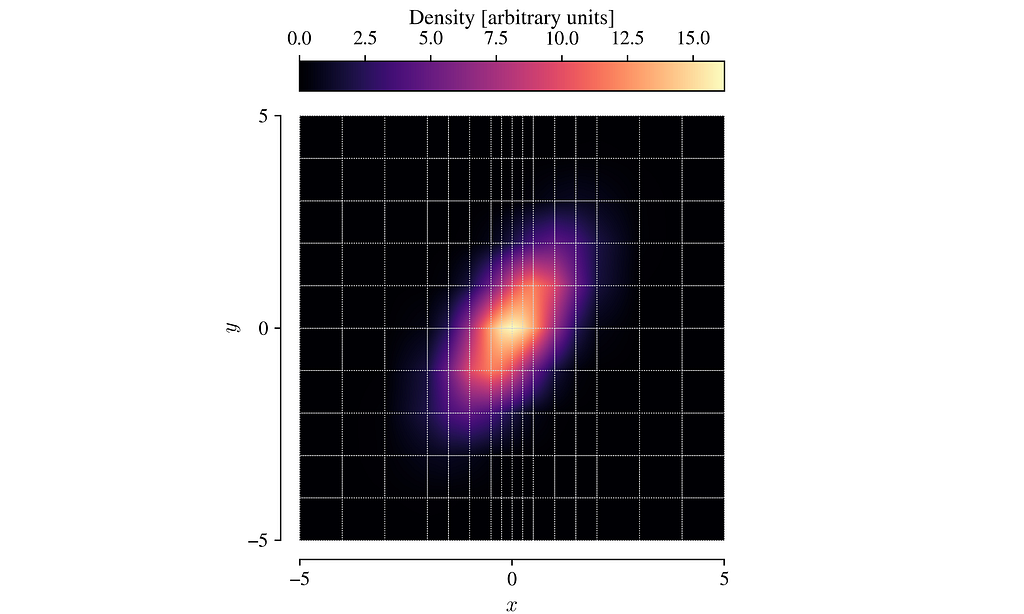
The example below illustrates what happens under the hood in lintsampler when you feed a PDF and a grid to the LintSampler class. We’ll take an easy example of a 2D Gaussian, but this methodology applies in any number of dimensions, and with much less friendly PDFs.
- First, the PDF gets evaluated on the grid. In the example below, the grid has uneven spacings, just for fun.

- Having evaluated the PDF on the grid in this way, we can estimate the total probability of each grid cell according to the trapezium rule (i.e., volume of the cell multiplied by the average of its corner densities).
- Within each grid cell, we can approximate the PDF with the bilinear interpolant between the cell corners:
- This linear approximation to the PDF can then be sampled very efficiently. Drawing a single sample is a two step process, illustrated in the figure below. First, choose a random cell from the probability-weighted list of cells (left-hand panel). Next, sample a point within the cell via inverse transform sampling (right-hand panel).
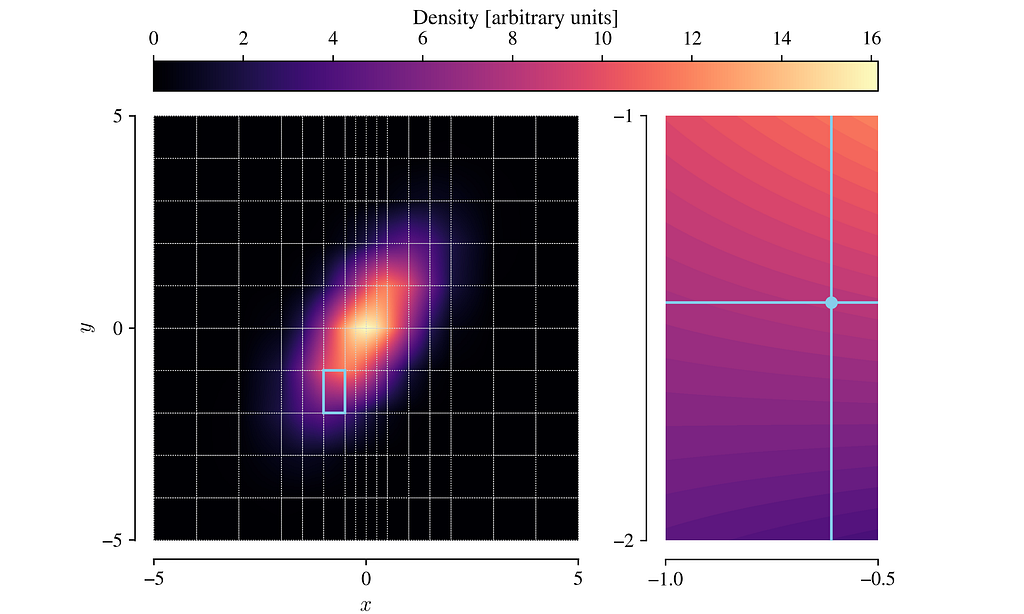
It is worth understanding that the key step here is the linear approximation: we describe this, as well as more details of the inverse transform sampling process, in the lintsampler docs. Approximating the PDF to a linear function within grid each cell means it has a closed, analytic form for its quantile function (i.e., its inverse CDF), which means doing inverse transform sampling essentially boils down to drawing uniform samples and applying an algebraic function to them.
The main thing the user needs to worry about is getting a decent grid resolution, so that the linear approximation is sufficient. What a good resolution is will vary from use case to use case, as demonstrated in some of the example notebooks in the lintsampler docs.
Happy sampling!
lintsampler: a new way to quickly get random samples from any distribution was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
lintsampler: a new way to quickly get random samples from any distribution