Discover how cutting-edge diffusion models tackle relighting, harmonization, and shadow removal in this in-depth blog on scene editing

Relighting is the task of rendering a scene under a specified target lighting condition, given an input scene. This is a crucial task in computer vision and graphics. However, it is an ill-posed problem, because the appearance of an object in a scene results from a complex interplay between factors like the light source, the geometry, and the material properties of the surface. These interactions create ambiguities. For instance, given a photograph of a scene, is a dark spot on an object due to a shadow cast by lighting or is the material itself dark in color? Distinguishing between these factors is key to effective relighting.
In this blog post we discuss how different papers are tackling the problem of relighting via diffusion models. Relighting encompases a variety of subproblems including simple lighting adjustments, image harmonization, shadow removal and intrinsic decomposition. These areas are essential for refining scene edits such as balancing color and shadow across composited images or decoupling material and lighting properties. We will first introduce the problem of relighting and briefly discuss Diffusion models and ControlNets. We will then discuss different approaches that solve the problem of relighting in different types of scenes ranging from single objects to portraits to large scenes.
Solving Relighting
The goal is to decompose the scene into its fundamental components such as geometry, material, and light interactions and model them parametrically. Once solved then we can change it according to our preference. The appearance of a point in the scene can be described by the rendering equation as follows:

Most methods aim to solve for each single component of the rendering equation. Once solved, then we can perform relighting and material editing. Since the lighting term L is on both sides, this equation cannot be evaluated analytically and is either solved via Monte Carlo methods or approximation based approaches.
An alternate approach is data-driven learning, where instead of explicitly modeling the scene properties it directly learns from data. For example, instead of fitting a parametric function, a network can learn the material properties of the surface from data. Data-driven approaches have proven to be more powerful than parametric approaches. However they require a huge amount of high quality data which is really hard to collect especially for lighting and material estimation tasks.
Datasets for lighting and material estimation are rare as they require expensive, complex setups such as light stages to capture detailed lighting interactions. These setups are accessible to only a few organizations, limiting the availability of data for training and evaluation. There are no full-body ground truth light stage datasets publicly available which further highlights this challenge.
Diffusion Models
Computer vision has experienced a significant transformation with the advent of pre-training on vast amounts of image and video data available online. This has led to the development of foundation models, which serve as powerful general-purpose models that can be fine-tuned for a wide range of specific tasks. Diffusion models work by learning to model the underlying data distribution from independent samples, gradually reversing a noise-adding process to generate realistic data. By leveraging their ability to generate high-quality samples from learned distributions, diffusion models have become essential tools for solving a diverse set of generative tasks.
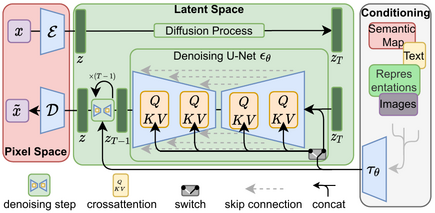
One of the most prominent examples of this is Stable Diffusion(SD), which was trained on the large-scale LAION-5B dataset that consists of 5 billion image text pairs. It has encoded a wealth of general knowledge about visual concepts making it suitable for fine-tuning for specific tasks. It has learnt fundamental relationships and associations during training such as chairs having 4 legs or recognizing structure of cars. This intrinsic understanding has allowed Stable Diffusion to generate highly coherent and realistic images and be used for fine tuning to predict other modalities. Based on this idea, the question arises if we can leverage pretrained SD to solve the problem of scene relighting.
So how do we fine-tune LDMs? A naive approach is to do transfer learning with LDMs. This would be freezing early layers (which capture general features) and fine tuning the model on the specific task. While this approach has been used by some papers such as Alchemist (for Material Transfer), it requires a large amount of paired data for the model to generalize well. Another drawback to this approach is the risk of catastrophic forgetting, where the model losses the knowledge gained during pretraining. This would limit its capability on generalizing across various conditions.
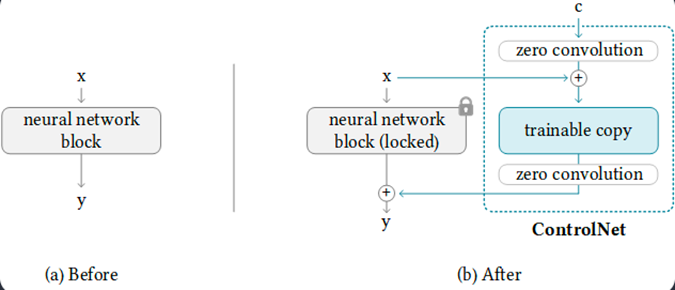
Another approach to fine-tuning such large models is by introducing a ControlNet. Here, a copy of the network is made and the weights of the original network are frozen. During training only the duplicate network weights are updated and the conditioning signal is passed as input to the duplicate network. The original network continues to leverage its pretrained knowledge.
While this increases the memory footprint, the advantage is that we dont lose the generalization capabilities acquired from training on large scale datasets. It ensures that it retains its ability to generate high-quality outputs across a wide range of prompts while learning the task specific relationships needed for the current task.
Additionally it helps the model learn robust and meaningful connections between control input and the desired output. By decoupling the control network from the core model, it avoids the risk of overfitting or catastrophic forgetting. It also needs significantly less paired data to train.
While there are other techniques for fine-tuning foundational models — such as LoRA (Low-Rank Adaptation) and others — we will focus on the two methods discussed: traditional transfer learning and ControlNet. These approaches are particularly relevant for understanding how various papers have tackled image-based relighting using diffusion models.
DiLightNet

Introduction
This work proposes fine grained control over relighting of an input image. The input image can either be generated or given as input. Further it can also change the material of the object based on the text prompt. The objective is to exert fine-grained control on the effects of lighting.
Method

Given an input image, the following preprocessing steps are applied:
- Estimate background and depth map using off the shelf SOTA models.
- Extract mesh by triangulating the depth map
- Generate 4 different radiance cues images. Radiance cues images are created by assigning the extracted mesh different materials and rendering them under target lighting. The radiance cues images act as basis for encoding lighting effects such as specular, shadows and global illumination.

Once these images are generated, they train a ControlNet module. The input image and the mask are passed through an encoder decoder network which outputs a 12 channel feature map. This is then multiplied with the radiance cues images that are channel wise concatenated together. Thus during training, the noisy target image is denoised with this custom 12 channel image as conditioning signal.
Additionally an appearance seed is provided to procure consistent appearance under different illumination. Without it the network renders a different interpretation of light-matter interaction. Additionally one can provide more cues via text to alter the appearance such as by adding “plastic/shiny metallic” to change the material of the generated image.
Implementation
The dataset was curated using 25K synthetic objects from Objaverse. Each object was rendered from 4 unique views and lit with 12 different lighting conditions ranging from point source lighting, multiple point source, environment maps and area lights. For training, the radiance cues were rendered in blender.
The ControlNet module uses stable diffusion v2.1 as base pretrained model to refine. Training took roughly 30 hours on 8x NVIDIA V100 GPUs. Training data was rendered in Blender at 512×512 resolution.
Results

This figure shows the provisional image as reference and the corresponding target lighting under which the object is relit.

This figure shows how the text prompt can be used to change the material of the object.

This figure shows more results of AI generated provisional images that are then rendered under different input environment light conditions.

This figure shows the different solutions the network comes up to resolve light interaction if the appearance seed is not fixed.
Limitations
Due to training on synthetic objects, the method is not very good with real images and works much better with AI generated provisional images. Additionally the material light interaction might not follow the intention of the prompt. Since it relies on depth maps for generating radiance cues, it may fail to get satisfactory results. Finally generating a rotating light video may not result in consistent results.
Neural Gaffer

Introduction
This work proposes an end to end 2D relighting diffusion model. This model learns physical priors from synthetic dataset featuring physically based materials and HDR environment maps. It can be further used to relight multiple views and be used to create a 3D representation of the scene.
Method
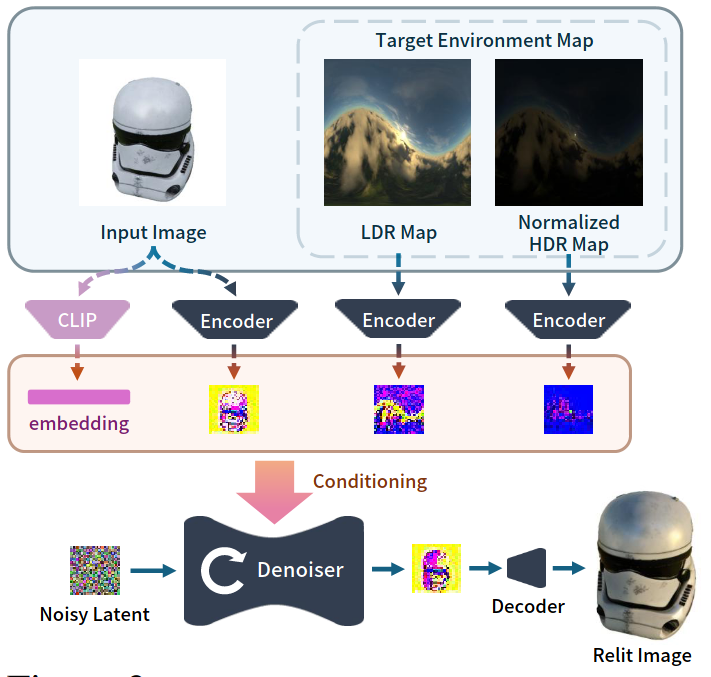
Given an image and a target HDR environment map, the goal is to learn a model that can synthesize a relit version of the image which here is a single object. This is achieved by adopting a pre-trained Zero-1-to-3 model. Zero-1-to-3 is a diffusion model that is conditioned on view direction to render novel views of an input image. They discard its novel view synthesis components. To incorporate lighting conditions, they concatenate input image and environment map encodings with the denoising latent.
The input HDR environment map E is split into two components: E_l, a tone-mapped LDR representation capturing lighting details in low-intensity regions, and E_h, a log-normalized map preserving information across the full spectrum. Together, these provide the network with a balanced representation of the energy spectrum, ensuring accurate relighting without the generated output appearing washed out due to extreme brightness.
Additionally the CLIP embedding of the input image is also passed as input. Thus the input to the model is the Input Image, LDR Image, Normalized HDR Image and CLIP embedding of Image all conditioning the denoising network. This network is then used as prior for further 3D object relighting.
Implementation
The model is trained on a custom Relit Objaverse Dataset that consists of 90K objects. For each object there are 204 images that are rendered under different lighting conditions and viewpoints. In total, the dataset consists of 18.4 M images at resolution 512×512.
The model is finetuned from Zero-1-to-3’s checkpoint and only the denoising network is finetined. The input environment map is downsampled to 256×256 resolution. The model is trained on 8 A6000 GPUs for 5 days. Further downstream tasks such as text-based relighting and object insertion can be achieved.
Results
They show comparisons with different backgrounds and comparisons with other works such as DilightNet and IC-Light.

This figure compares the relighting results of their method with IC-Light, another ControlNet based method. Their method can produce consistent lighting and color with the rotating environment map.

This figure compares the relighting results of their method with DiLightnet, another ControlNet based method. Their method can produce specular highlights and accurate colors.
Limitations
A major limitation is that it only produces low image resolution (256×256). Additionally it only works on objects and performs poorly for portrait relighting.
Relightful Harmonization

Introduction
Image Harmonization is the process of aligning the color and lighting features of the foreground subject with the background to make it a plausible composition. This work proposes a diffusion based approach to solve the task.
Method
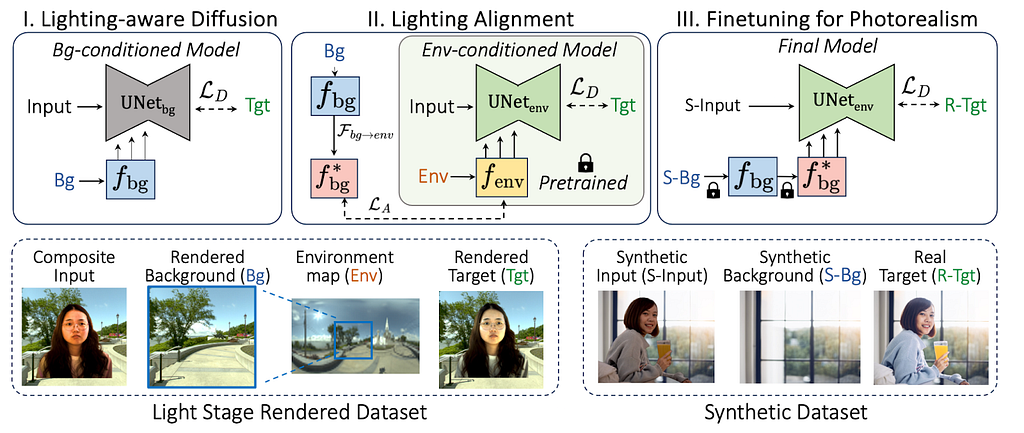
Given an input composite image, alpha mask and a target background, the goal is to predict a relit portrait image. This is achieved by training a ControlNet to predict the Harmonized image output.
In the first stage, we train a background control net model that takes the composite image and target background as input and outputs a relit portrait image. During training, the denoising network takes the noisy target image concatenated with composite image and predicts the noise. The background is provided as conditioning via the control net. Since background image by itself are LDR, they do not provide sufficient signals for relighting purposes.
In the second stage, an environment map control net model is trained. The HDR environment map provide lot more signals for relighting and this gives lot better results. However at test time, the users only provide LDR backgrounds. Thus, to bridge this gap, the 2 control net models are aligned with each other.
Finally more data is generated using the environment map ControlNet model and then the background ControlNet model is finetuned to generate more photo realistic results.
Implementation
The dataset used for training consists of 400k image pair samples that were curated using 100 lightstage. In the third stage additional 200k synthetic samples were generated for finetuning for photorealism.
The model is finetuned from InstructPix2PIx checkpoint The model is trained on 8 A100 GPUs at 512×512 resolution.
Results

This figure shows how the method neutralizes pronounced shadows in input which are usually hard to remove. On the left is input and right is relit image.


The figures show results on real world test subjects. Their method is able to remove shadows and make the composition more plausible compared to other methods.
Limitations
While this method is able to plausibly relight the subject, it is not great at identity preservation and struggles in maintaining color of the clothes or hair. Further it may struggle to eliminate shadow properly. Also it does not estimate albedo which is crucial for complex light interactions.
Multi-Illumination Synthesis

Introduction
This work proposes a 2D relighting diffusion model that is further used to relight a radiance field of a scene. It first trains a ControlNet model to predict the scene under novel light directions. Then this model is used to generate more data which is eventually used to fit a relightable radiance field. We discuss the 2D relighting model in this section.
Method
Given a set of images X_i with corresponding depth map D (that is calculated via off the shelf methods), and light direction l_i the goal is to predict the scene under light direction l_j. During training, the input to the denoising network is X_i under random illumination, depth map D concatenated with noisy target image X_j. The light direction is encoded with 4th order SH and conditioned via ControlNet model.
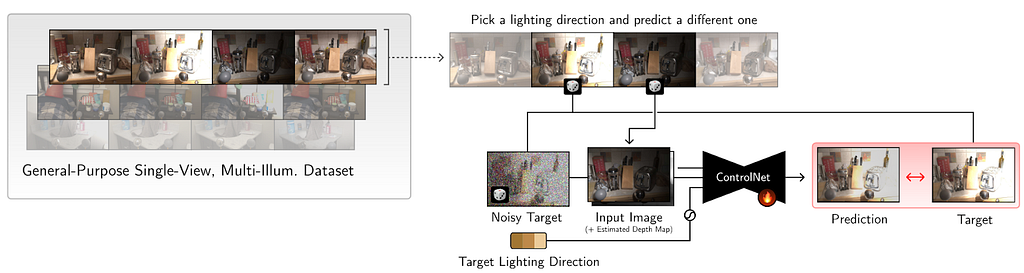
Although this leads to decent results, there are some significant problems. It is unable to preserve colors and leads to loss in contrast. Additionally it produces distorted edges. To resolve this, they color-match the predictions to input image to compensate for color difference. This is done by converting the image to LAB space and then channel normalization. The loss is then taken between ground-truth and denoised output. To preserve edges, the decoder was pretrained on image inpainting tasks which was useful in preserving edges. This network is then used to create corresponding scene under novel light directions which is further used to create a relightable radiance field representation.
Implementation
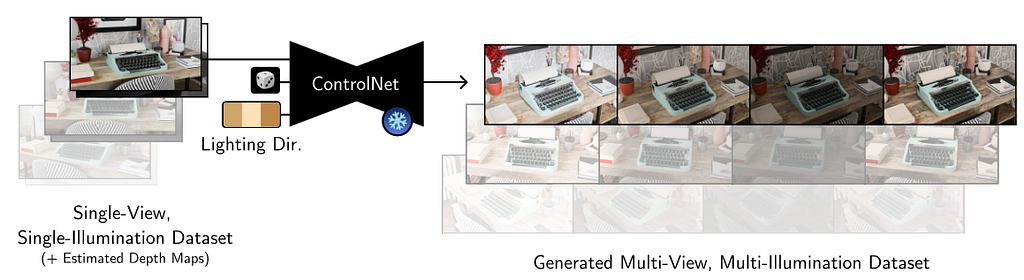
The method was developed upon Multi-Illumination dataset. It consists of 1000 real scenes of indoor scenes captured under 25 lighting directions. The images also consist of a diffuse and a metallic sphere ball that is useful for obtaining the light direction in world coordinates. Additionally some more scenes were rendered in Blender. The network was trained on images at resolution 1536×1024 and training consisted of 18 non-front facing light directions on 1015 indoor scenes.
The ControlNet module was trained using Stable Diffusion v2.1 model as backbone. It was trained on multiple A6000 GPUs for 150K iterations.
Results

Here the diffuse spheres show the test time light directions. As can be seen, the method can render plausible relighting results

This figure shows how with the changing light direction, the specular highlights and shadows are moving as evident on the shiny highlight on the kettle.

This figure compares results with other relightable radiance field methods. Their method clearly preserves color and contrast much better compared to other methods.
Limitations
The method does not enforce physical accuracy and can produce incorrect shadows. Additionally it also struggles to completely remove shadows in a fully accurate way. Also it does work reasonably for out of distribution scenes where the variance in lighting is not much.
LightIt

Introduction
This work proposes a single view shading estimation method to generate a paired image and its corresponding direct light shading. This shading can then be used to guide the generation of the scene and relight a scene. They approach the problem as an intrinsic decomposition problem where the scene can be split into Reflectance and Shading. We will discuss the relighting component here.
Method
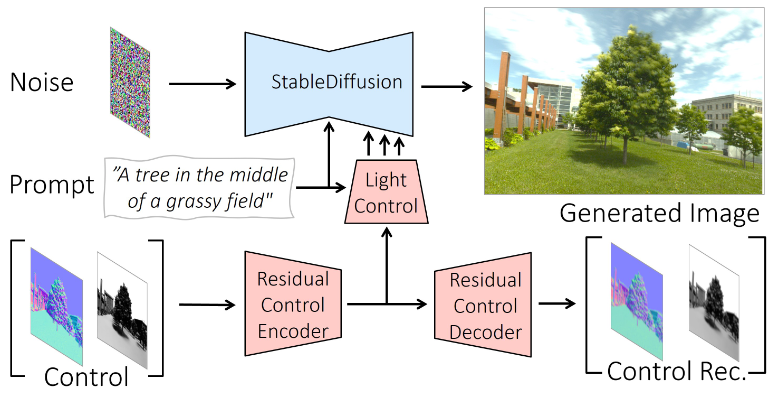
Given an input image, its corresponding surface normal, text conditioning and a target direct shading image, they generate a relit stylized image. This is achieved by training a ControlNet module.
During training, the noisy target image is passed to the denoising network along with text conditioning. The normal and target direct shading image are concatenated and passed through a Residual Control Encoder. The feature map is then used to condition the network. Additionally its also reconstructed back via Residual Control Decoder to regularize the training
Implementation

The dataset consists of Outdoor Laval Dataset which consist of outdoor real world HDR panoramas. From these images, 250 512×512 images are cropped and various camera effects are applied. The dataset consists of 51250 samples of LDR images and text prompts along with estimated normal and shading maps. The normals maps were estimated from depth maps that were estimated using off the shelf estimators.
The ControlNet module was finetuned from stable diffusion v1.5. The network was trained for two epochs. Other training details are not shared.
Results

This figure shows that the generated images feature consistent lighting aligned with target shading for custom stylized text prompts. This is different from other papers discussed whose sole focus is on photorealism.
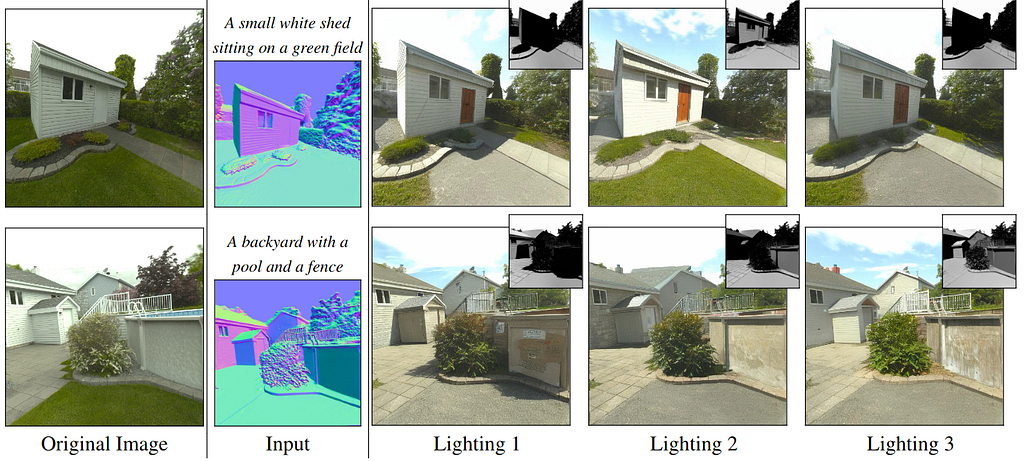
This figure shows identity preservation under different lighting conditions.

This figure shows results on different styles and scenes under changing lighting conditions.

This figure compares relighting with another method. Utilizing the diffusion prior helps with generalization and resolving shading disambiguation.
Limitations
Since this method assumes directional lighting, it enables tracing rays in arbitrary direction. It requires shading cues to generate images which are non trivial to obtain. Further their method does not work for portraits and indoor scenes.
Takeaways
We have discussed a non-exhaustive list of papers that leverage 2D diffusion models for relighting purposes. We explored different ways to condition Diffusion models for relighting ranging from radiance cues, direct shading images, light directions and environment maps. Most of these methods show results on synthetic datasets and dont generalize well to out of distribution datasets. There are more papers coming everyday and the base models are also improving. Recently IC-Light2 was released which is a ControlNet model based upon Flux models. It will be interesting which direction it takes as maintaining identities is tricky.
References:
- GitHub — lllyasviel/IC-Light: More relighting!
- IllumiNeRF — 3D Relighting without Inverse Rendering
- Neural Gaffer
- DiLightNet: Fine-grained Lighting Control for Diffusion-based Image Generation
- Relightful Harmonization
- A Diffusion Approach to Radiance Field Relighting using Multi-Illumination Synthesis
- How diffusion models work: the math from scratch | AI Summer
- Tutorial on Diffusion Models for Imaging and Vision
- Diffusion models from scratch in PyTorch
- Diffusion Models — Live Coding Tutorial
- Diffusion Models | Paper Explanation | Math Explained
- How I Understand Diffusion Models by Prof Jia Bin Huang
- Denoising Diffusion Probabilistic Models | DDPM Explained Good intuition of math of diffusion models
Let There Be Light! Diffusion Models and the Future of Relighting was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Let There Be Light! Diffusion Models and the Future of Relighting
Go Here to Read this Fast! Let There Be Light! Diffusion Models and the Future of Relighting