Common mistakes to avoid when you transition from statistical modelling to Machine Learning

My Story
Data Science, Machine Learning, and AI are undeniably buzzwords of today. My LinkedIn is flooded with data gurus sharing learning roadmaps for those eager to break into this data space.
Yet, from my personal experience, I’ve found that the journey towards Data Science isn’t as linear as merely following a fixed roadmap, especially for individuals transitioning from various professional backgrounds. Data Science requires a blend of diverse skills like programming, statistics, math, analytics, soft skills, and domain knowledge. This means that everyone picks up learning from different points depending on their prior experience/skill sets.
As someone who worked in research and analytics for years and pursued a master’s degree in analytics, I have acquired a fair amount of statistical knowledge and its applications. Even then, data science is such a broad and dynamic industry that my knowledge is still all over the place. I struggled to find resources that could effectively fill my knowledge gap between statistics and ML as well. This posed significant challenges to my learning experience.
In this article, I aim to share the technical oversights I encounter as I navigate from research & analytics to data science. Hopefully, my sharing can save you time and help you avoid these pitfalls.
Statistical Modelling Vs Machine Learning
So, you might be wondering why I am starting with a reflection on my journey instead of getting to the point. Well, the reason is simple — I have noticed that many individuals claim to be building ML models when, in reality, they are only crafting statistical models. I confess I was one of them! It’s not like one is better than the other, but I believe it is crucial to recognise the nuances between statistical modelling and ML before I talk about technicalities.
The purpose of statistical models is for making inferences, while the primary goal of Machine Learning is for predictions. Simply put, the ML model leverages statistics and math to generate predictions applicable to real-world scenarios. This is where data splitting and data leakage come into the picture, particularly in the context of supervised Machine Learning.
My initial belief was that understanding statistical analysis was sufficient for prediction tasks. However, I quickly realised that without knowledge of data preparation techniques such as proper data splitting and awareness of potential pitfalls like data leakage, even the most sophisticated statistical models fall short in predictive performance.
So, let’s get started!
Mistake 1: Improper Data Splitting
What is meant by data splitting?
Data splitting, in essence, is dividing your dataset into parts for optimal predictive performance of the model.
Consider a simple OLS regression concept that is familiar to many of us. We all have heard about it in one of the business/stats/finance, economics, or engineering lectures. It is a fundamental ML technique.
Let’s say we have a housing price dataset along with the factors that might affect housing prices.
In traditional statistical analysis, we employ the entire dataset to develop a regression model, as our goal is just to understand what factors influence housing prices. In other words, regression models can explain what degree of changes in prices are associated with the predictors.
However, in ML, the statistical part remains the same, but data splitting becomes crucial. Let me explain why — imagine we train the model on the entire set; how would we know the predictive performance of the model on unseen data?
For this very reason, we typically split the dataset into two sets: training and test sets. The idea is to train the model on one set and evaluate its performance on the other set. Essentially, the test set should serve as real-world data, meaning the model should not have access to the test data in any way throughout the training phase.
Here comes the pitfall that I wasn’t aware of before. Splitting data into two sets is not inherently wrong, but there is a risk of creating an unreliable model. Imagine you train the model on the training set, validate its accuracy on the test set, and then repeat the process to fine-tune the model. This creates a bias in model selection and defeats the whole purpose of “unseen data” because test data was seen multiple times during model development. It undermines the model’s ability to genuinely predict the unseen data, leading to overfitting issues.
How to prevent it:
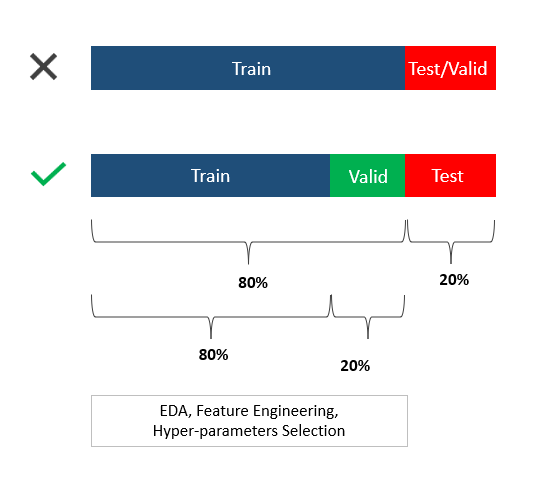
Ideally, the dataset should be divided into two blocks (three distinct splits):
- ( Training set + Validation set) → 1st block
- Test set → 2nd block
The model can be trained and validated on the 1st block. The 2nd block (the test set) should not be involved in any of the model training processes. Think of the test set as a danger zone!
How you want to split the data is dependent on the size of the dataset. The industry standard is 60% — 80 % for the training set (1st block) and 20% — 40% for the test set. The validation set is normally curved out of the 1st block so the actual training set would be 70% — 90% out of the 1st block , and the rest is for the validation set.
The best way to grasp this concept is through a visual:
There is more than one data-splitting technique other than LOOV (in the picture):
- K-fold Cross-validation, which divides the data into a number of ‘K’ folds and iterates the training processes accordingly
- Rolling Window Cross-validation (for time-series data)
- Blocked Cross-validation (for time-series data)
- Stratified Sampling Splitting for imbalanced classes
Note: Time series data needs extra caution when splitting data due to its temporal order. Randomly splitting the dataset can mess up its time order. (I learnt it the hard way)
The most important thing is regardless of the techniques you use, the “test set” should be kept separate and untouched until the model selection.
Mistake 2: Data Leakage
“In Machine learning, Data Leakage refers to a mistake that is made by the creator of a machine learning model in which they accidentally share the information between the test and training data sets.” — Analytics Vidhya
This is connected to my first point about test data being contaminated by training data. It’s one example of data leakage. However, having a validation set alone can’t avoid data leakage.
In order to prevent data leakage, we need to be careful with the data handling process — from Exploratory Data Analysis (EDA) to Feature Engineering. Any procedure that allows the training data to interact with the test data could potentially lead to leakage.
There are two main types of leakage:
- Train-test-contamination
A common mistake I made involved applying a standardisation/pre-processing procedure to the entire set before data splitting. For example, using mean imputation to handle missing values/ outliers on the whole dataset. This makes the training data incorporate information from the test data. As a result, the model’s accuracy is inflated compared to its real-life performance.
2. Target leakage
If the features (predictors) have some dependency on the variable that we want to predict (target), or if the features data will not be available at the time of prediction, this can result in target leakage.
Let’s look at the data I worked on as an example. Here, I was trying to predict sales performance based on advertising campaigns. I tried to include the conversion rates. I overlooked the fact that conversion rates are only known post-campaign. In other words, I won’t have this information at the time of forecasting. Plus, because conversion rates are tied to sales data, this introduces a classic case of target leakage. Including conversion rates would lead the model to learn from data that would not be normally accessible, resulting in overly optimistic predictions.

How to prevent data leakage:
In summary, keep these points in mind to address data leakage issues:
- Proper Data Preprocessing
- Cross-validation with care
- Careful Feature Selection
Closing Thoughts
That’s about it! Thanks for sticking with me till the end! I hope this article clarifies the common misconceptions around data splitting and sheds light on the best practices in building efficient ML models.
This is not just for documenting my learning journey but also for mutual learning. So, if you spot a gap in my technical know-how or have any insights to share, feel free to drop me a message!
References:
Daniel Lee Datainterview.com LinkedIn Post
Kaggle — Data Leakage Explanation
Analytics Vidhya — Data Leakage And Its Effect On The Performance of An ML Model
Forecasting: Principles and Practice
Lessons From My ML Journey: Data Splitting and Data Leakage was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Lessons From My ML Journey: Data Splitting and Data Leakage
Go Here to Read this Fast! Lessons From My ML Journey: Data Splitting and Data Leakage