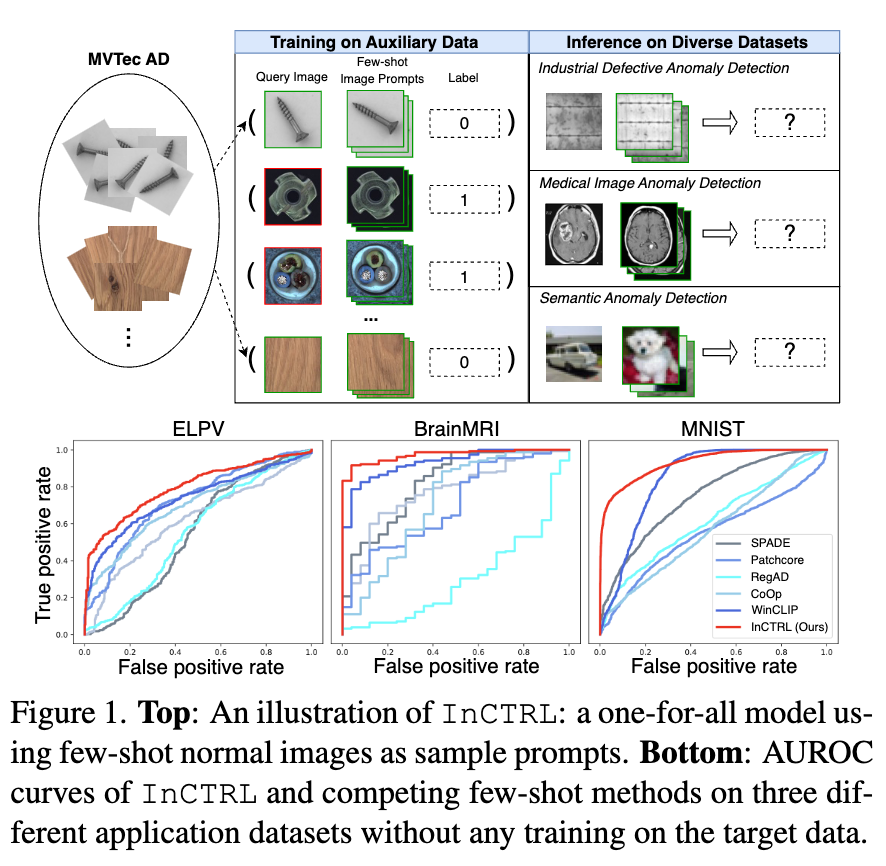
Generalist Anomaly Detection (GAD) aims to train one single detection model that can generalize to detect anomalies in diverse datasets from different application domains without any further training on the target data.
Work to be published at CVPR 2024 [1].
Overview
Some recent studies have showed that large pre-trained Visual-Language Models (VLMs) like CLIP have strong generalization capabilities on detecting industrial defects from various datasets, but their methods rely heavily on handcrafted text prompts about defects, making them difficult to generalize to anomalies in other applications, e.g., medical image anomalies or semantic anomalies in natural images.
In this work, we propose to train a GAD model with few-shot normal images as sample prompts for AD on diverse datasets on the fly. To this end, we introduce a novel approach that learns an in–context residual learning model for GAD, termed InCTRL.
It is trained on an auxiliary dataset to discriminate anomalies from normal samples based on a holistic evaluation of the residuals between query images and few-shot normal sample prompts. Regardless of the datasets, per definition of anomaly, larger residuals are expected for anomalies than normal samples, thereby enabling InCTRL to generalize across different domains without further training.
Comprehensive experiments on nine AD datasets are performed to establish a GAD benchmark that encapsulate the detection of industrial defect anomalies, medical anomalies, and semantic anomalies in both one-vs-all and multi-class setting, on which InCTRL is the best performer and significantly outperforms state-of-the-art competing methods. Code is available at https://github.com/mala-lab/InCTRL.
Introduction
Anomaly Detection (AD) is a crucial computer vision task that aims to detect samples that substantially deviate from the majority of samples in a dataset, due to its broad real-life applications such as industrial inspection, medical imaging analysis, and scientific discovery, etc. [2–3]. Current AD paradigms are focused on individually building one model on the training data, e.g.,, a set of anomaly-free samples, of each target dataset, such as data reconstruction approach, one-class classification, and knowledge distillation approach. Although these approaches have shown remarkable detection performance on various AD benchmarks, they require the availability of large training data and the skilled detection model training per dataset. Thus, they become infeasible in application scenarios where training on the target dataset is not allowed due to either data privacy issues, e.g., arising from using those data in training the models due to machine unlearning [3], or unavailability of large-scale training data in the deployment of new applications. To tackle these challenges, this work explores the problem of learning Generalist Anomaly Detection (GAD) models, aiming to train one single detection model that can generalize to detect anomalies in diverse datasets from different application domains without any training on the target data.
Being pre-trained on web-scale image-text data, large Visual-Language Models (VLMs) like CLIP have exhibited superior generalization capabilities in recent years, achieving accurate visual recognition across different datasets without any fine-tuning or adaptation on the target data. More importantly, some very recent studies (e.g., WinCLIP [5]) show that these VLMs can also be utilized to achieve remarkable generalization on different defect detection datasets. Nevertheless, a significant limitation of these models is their dependency on a large set of manually crafted prompts specific to defects. This reliance restricts their applicability, making it challenging to extend their use to detecting anomalies in other data domains, e.g., medical image anomalies or semantic anomalies in one-vs-all or multi-class settings.
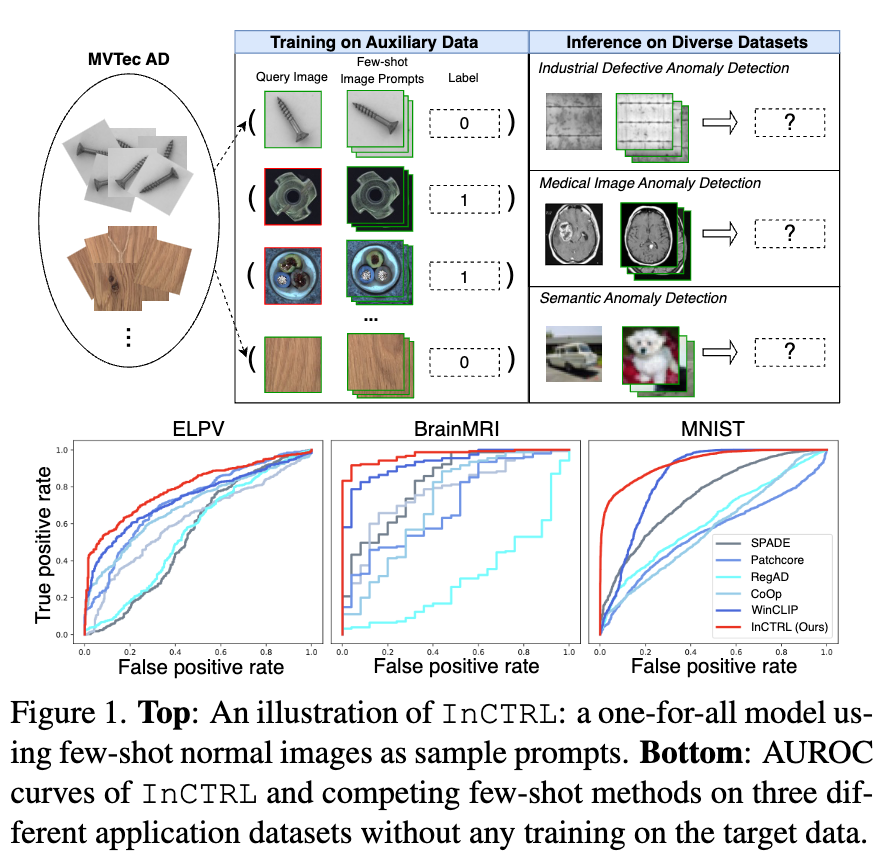
To address this problem, we propose to train a GAD model that aims to utilize few-shot normal images from any target dataset as sample prompts for supporting GAD on the fly, as illustrated in Figure 1(Top). The few-shot setting is motivated by the fact that it is often easy to obtain few-shot normal images in real-world applications. Furthermore, these few-shot samples are not used for model training/tuning; they are just used as sample prompts for enabling the anomaly scoring of test images during inference. This formulation is fundamentally different from current few-shot AD methods that use these target samples and their extensive augmented versions to train the detection model, which can lead to an overfitting of the target dataset and fail to generalize to other datasets, as shown in Figure 1(Bottom).
We then introduce an GAD approach, the first of its kind, that learns an in–context residual learning model based on CLIP, termed InCTRL. It trains an GAD model to discriminate anomalies from normal samples by learning to identify the residuals/discrepancies between query images and a set of few-shot normal images from auxiliary data. The few-shot normal images, namely in-context sample prompts, serve as prototypes of normal patterns. When comparing with the features of these normal patterns, per definition of anomaly, a larger residual is typically expected for anomalies than normal samples in datasets of different domains, so the learned in-context residual model can generalize to detect diverse types of anomalies across the domains. To capture the residuals better, InCTRL models the in-context residuals at both the image and patch levels, gaining an in-depth in-context understanding of what constitutes an anomaly. Further, our in-context residual learning can also enable a seamless incorporation of normal/abnormal text prompt-guided prior knowledge into the detection model, providing an additional strength for the detection from the text-image-aligned semantic space.
Extensive experiments on nine AD datasets are performed to establish a GAD benchmark that encapsulates three types of popular AD tasks, including industrial defect anomaly detection, medical image anomaly detection, and semantic anomaly detection under both one-vs-all and multi-class settings. Our results show that InCTRL significantly surpasses existing state-of-the-art methods.
Approach
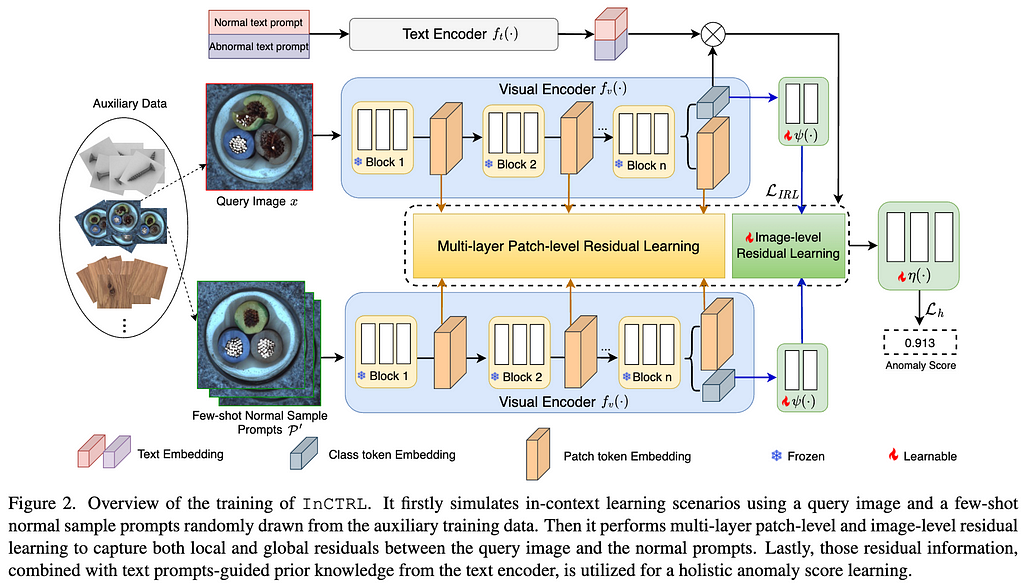
Our approach InCTRL is designed to effectively model the in-context residual between a query image and a set of few-shot normal images as sample prompts, utilizing the generalization capabilities of CLIP to detect unusual residuals for anomalies from different application domains.
CLIP is a VLM consisting of a text encoder and a visual encoder, with the image and text representations from these encoders well aligned by pre-training on web-scale text-image data. InCTRL is optimized using auxiliary data via an in-context residual learning in the image encoder, with the learning augmented by text prompt-guided prior knowledge from the text encoder.
To be more specific, as illustrated in Fig.2, we first simulate an in-context learning example that contains one query image x and a set of few-shot normal sample prompts P’, both of which are randomly sampled from the auxiliary data. Through the visual encoder, we then perform multi-layer patch-level and image-level residual learning to respectively capture local and global discrepancies between the query and few-shot normal sample prompts. Further, our model allows a seamless incorporation of normal and abnormal text prompts-guided prior knowledge from the text encoder based on the similarity between these textual prompt embeddings and the query images . The training of InCTRL is to optimize a few projection/adaptation layers attached to the visual encoder to learn a larger anomaly score for anomaly samples than normal samples in the training data, with the original parameters in both encoders frozen; during inference, a test image, together with the few-shot normal image prompts from the target dataset and the text prompts, is put forward through our adapted CLIP-based GAD network, whose output is the anomaly score for the test image.
Empirical Results
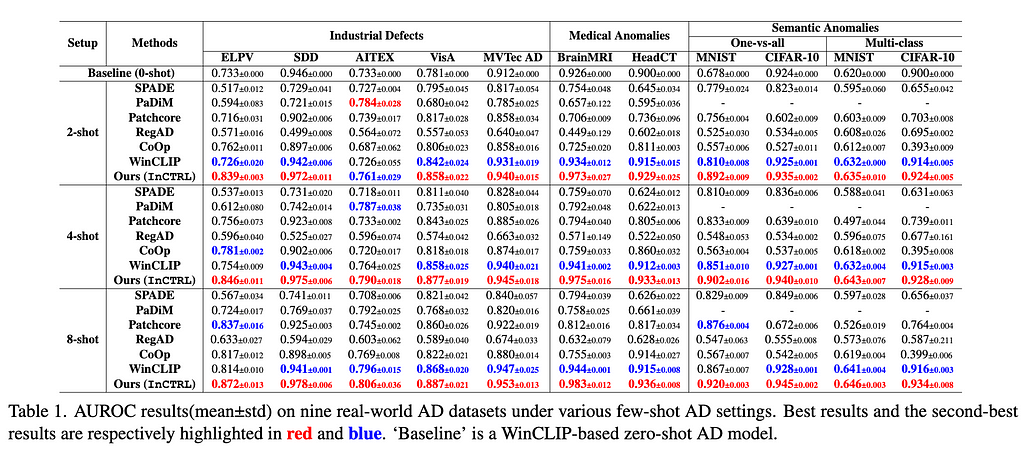
Datasets and Evaluation Metrics. To verify the efficiency of our method, we conduct comprehensive experiments across nine real-world AD datasets, including five industrial defect inspection dataset (MVTec AD, VisA, AITEX, ELPV, SDD), two medical image datasets (BrainMRI, HeadCT), and two semantic anomaly detection datasets: MNIST and CIFAR-10 under both one-vs-all and multi-class protocols. Under the one-vs-all protocol, one class is used as normal, with the other classes treated as abnormal; while under the multi-class protocol, images of even-number classes from MNIST and animal-related classes from CIFAR-10 are treated as normal, with the images of the other classes are considered as anomalies.
To assess the GAD performance, MVTec AD, the combination of its training and test sets, is used as the auxiliary training data, on which GAD models are trained, and they are subsequently evaluated on the test set of the other eight datasets without any further training. We train the model on VisA when evaluating the performance on MVTec AD.
The few-shot normal prompts for the target data are randomly sampled from the training set of target datasets and remain the same for all models for fair comparison. We evaluate the performance with the number of few-shot normal prompt set to K = 2, 4, 8. The reported results are averaged over three independent runs with different random seeds.
As for evaluation metrics, we use two popular metrics AUROC (Area Under the Receiver Operating Characteristic) and AUPRC (Area Under the Precision-Recall Curve) to evaluate the AD performance.
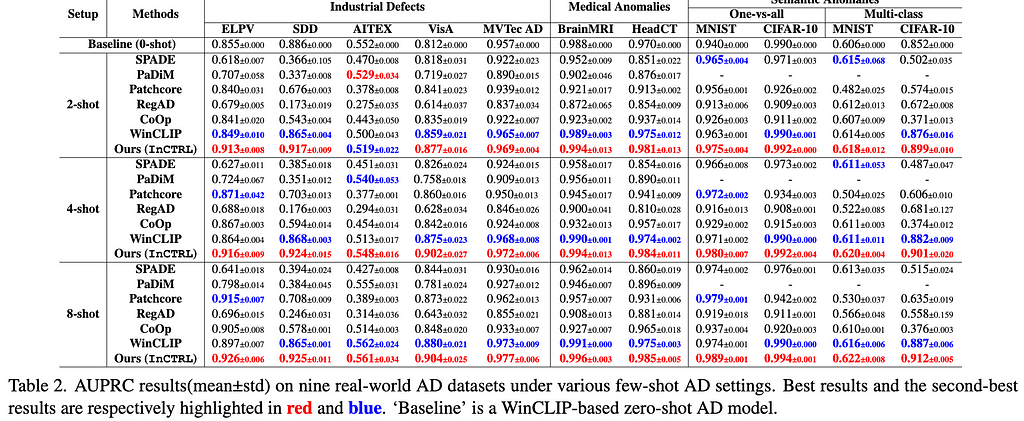
Results. The main results are reporeted in Tables 1 and 2. For the 11 industrial defect AD datasets, InCTRL significantly outperforms all competing models on almost all cases across the three few-shot settings in both AUROC and AUPRC. With more few-shot image prompts, the performance of all methods generally gets better. InCTRL can utilize the increasing few-shot samples well and remain the superiority over the competing methods.
Ablation Study. We examine the contribution of three key components of our approach on the generalization: text prompt-guided features (T), patch-level residuals (P), and image-level residuals (I), as well as their combinations. The results are reported in Table 3. The experiment results indicate that for industrial defect AD datasets, visual residual features play a more significant role compared to text prompt-based features, particularly on datasets like ELPV, SDD, and AITEX. On the medical image AD datasets, both visual residuals and textual knowledge contribute substantially to performance enhancement, exhibiting a complementary relation. On semantic AD datasets, the results are dominantly influenced by patch-level residuals and/or text prompt-based features. Importantly, our three components are generally mutually complementary, resulting in the superior detection generalization across the datasets.
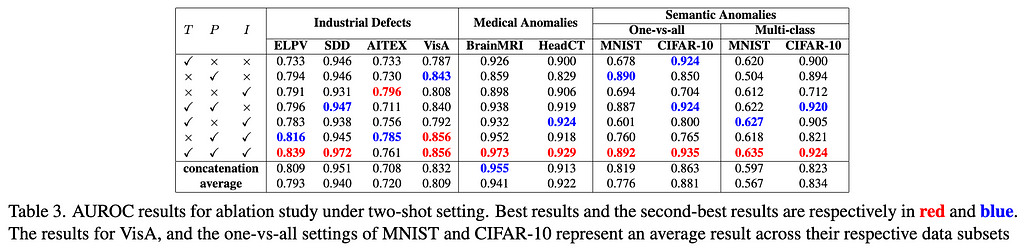
Significance of In-context Residual Learning. To assess the importance of learning the residuals in InCTRL, we experiment with two alternative operations in both multi-layer patch-level and image-level residual learning: replacing the residual operation with 1) a concatenation operation and 2) an average operation, with all the other components of InCTRL fixed. As shown in Table 3, the in-context residual learning generalizes much better than the other two alternative ways, significantly enhancing the model’s performance in GAD across three distinct domains.
Conclusion
In this work we introduce a GAD task to evaluate the generalization capability of AD methods in identifying anomalies across various scenarios without any training on the target datasets. This is the first study dedicated to a generalist approach to anomaly detection, encompassing industrial defects, medical anomalies, and semantic anomalies. Then we propose an approach, called InCTRL, to addressing this problem under a few-shot setting. InCTRL achieves a superior GAD generalization by holistic in-context residual learning. Extensive experiments are performed on nine AD datasets to establish a GAD evaluation benchmark for the aforementioned three popular AD tasks, on which InCTRL significantly and consistently outperforms SotA competing models across multiple few-shot settings.
Please check out the full paper [1] for more details of the approach and the experiments. Code is publicly available at https://github.com/mala-lab/InCTRL.
References
[1] Zhu, Jiawen, and Guansong Pang. “Toward Generalist Anomaly Detection via In-context Residual Learning with Few-shot Sample Prompts.” arXiv preprint arXiv:2403.06495 (2024).
[2] Pang, Guansong, et al. “Deep learning for anomaly detection: A review.” ACM computing surveys (CSUR) 54.2 (2021): 1–38.
[3] Cao, Yunkang, et al. “A Survey on Visual Anomaly Detection: Challenge, Approach, and Prospect.” arXiv preprint arXiv:2401.16402 (2024).
[4] Xu, Jie, et al. “Machine unlearning: Solutions and challenges.” IEEE Transactions on Emerging Topics in Computational Intelligence (2024).
[5] Jeong, Jongheon, et al. “Winclip: Zero-/few-shot anomaly classification and segmentation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
Learning Generalist Models for Anomaly Detection was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Learning Generalist Models for Anomaly Detection
Go Here to Read this Fast! Learning Generalist Models for Anomaly Detection