

Large Language Models, GPT-2 — Language Models Are Unsupervised Multitask Learners
Acing GPT capabilities by turning it into a powerful multitask zero-shot model
Introduction
GPT is a well-known series of models whose last versions are currently dominating in various NLP tasks. The first GPT version was a significant milestone: being trained on enormous 120M parameters, this model demonstrated state-of-the-art performance on top benchmarks. Starting from this point, researchers tried to improve the base version.
In 2019, researchers from OpenAI officially released GPT-2. It was 10 times bigger than GPT-1 which allowed it to improve performance even further. Apart from that, the authors conjectured in their work that LLMs are multitask learners meaning that they can learn to perform several tasks at the same time. This important statement made it possible to further develop LLMs in a much more efficient framework.
In this article, we will refer to the official GPT-2 paper by going through its main aspects and improvements over GPT-1 and understand a novel approach for building LLMs.
Note. This article assumes that you are already familiar with the first version of GPT. If not, check out this article.
Large Language Models, GPT-1 — Generative Pre-Trained Transformer
The importance of understanding the GPT evolution
It is no secret that with the recent introduction of powerful models like ChatGPT or GPT-4, the first GPT versions no longer attract that much attention and appear obsolete.
Nevertheless, the following reasons explain the important motivation behind studying the GPT evolution.
- The first GPT versions introduced language learning concepts that are still used by the most recent models. The best example is GPT-2 innovating the multitask learning technique. Thanks to this concept, the modern GPT models can accurately solve a large variety of NLP tasks.
- From the algorithmic perspective, most LLMs already use many advanced techniques and it becomes harder to innovate new efficient methods. That is why NLP researchers focus more on scraping and feeding more high-quality data to models. This detail explains why there is not so much difference between internal working mechanisms in first GPT models, in comparison to ChatGPT-3.5 or GPT-4. As a result, the most principled differences are usually the amount of data fed to them and the complexity of a neural network. By understanding how first GPT models work, you can automatically recognize the working concepts of more advanced models.
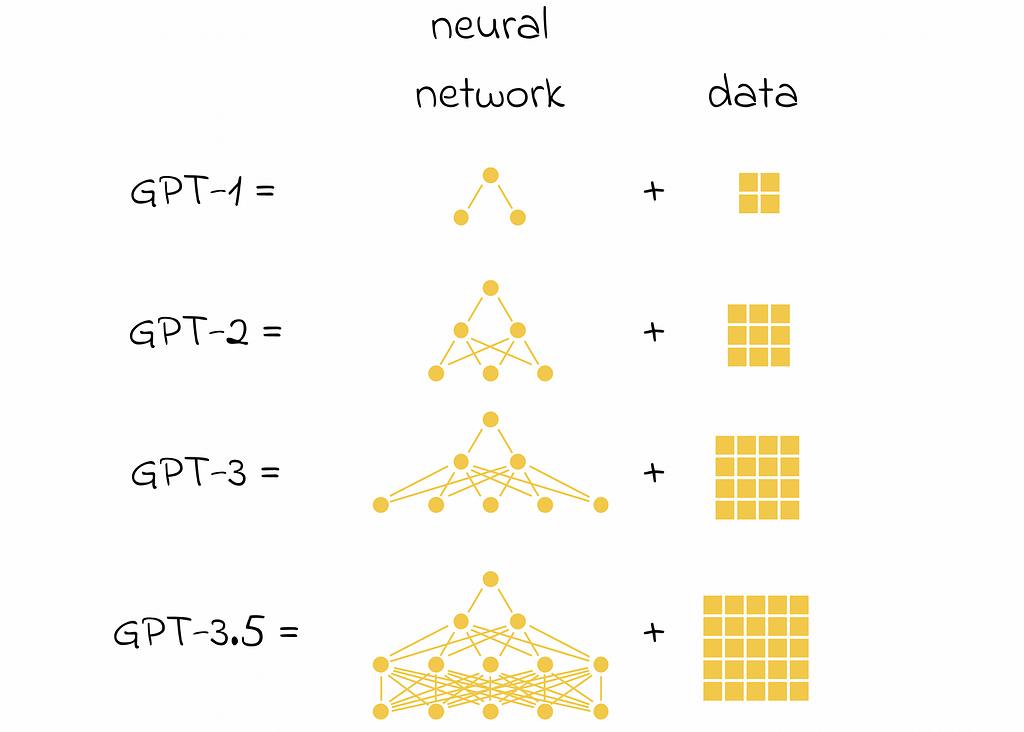
Multitask learning
GPT-2 is built on top of GPT-1 meaning that it has the same architecture. During training, GPT-1 uses the standard log-likelihood language modeling objective:
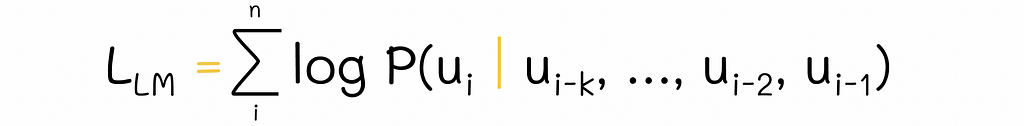
This expression can be thought of as an optimization of conditional probability distribution p(output | input) for a given task (in the case of GPT-1, the task consists of predicting the next token). While this approach works well for individual tasks, the model is still not able to learn to perform multiple tasks. For instance, a model trained with the aforementioned objective to predict the next token in the sequence will perform poorly on a sentiment analysis problem without proper fine-tuning.
The GPT-2 authors proposed a novel approach for replacing the common pre-training + fine-tuning framework that would allow a trained model to perform well across different tasks. The idea consists of not modeling the standard probability p(output | input) but including task conditioning p(output | input, task) instead. There exist several approaches to incorporating task type into the model. Most of the previous methods considered this information by making changes on the architecture level. Though this approach worked well in the past, it turned out that there would be no need to modify the model’s architecture for task-type incorporation.
The ultimate idea is that task information can be easily incorporated into the input sequence. For example:
- If a sentence in language A needs to be translated into the language B, then the input sequence in the dataset will be written as:

- If an answer should be given to a question in a provided context, then the input sequence will take the following form:
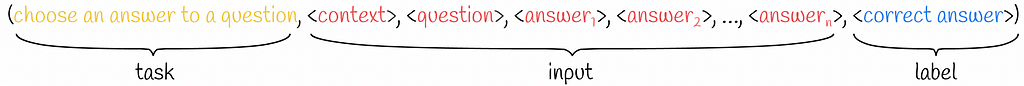
Surprisingly the described approach was already proven to be competitive in previous works (e.g. MQAN model)! The only main disadvantage is its slow learning speed.
Zero-shot learning is a popular term and designates the ability of a model to perform a certain task without having explicitly received any training examples for it. GPT-2 is an example of a model having this ability.
Dataset
To use the idea of multitask learning from the previous section, for training, we would normally need a dataset whose objects contain task descriptions, text inputs and labels. However, in reality, the authors developed a robust framework which turns this supervised problem into an unsupervised one and does not even need task descriptions!
The researchers conjectured that if a model was trained on a large and diverse dataset, then there would probably be a lot of language demonstration tasks in different domains that would definitely help the model to fully understand them. To validate this hypothesis, the authors designed a web scraping algorithm that collected human responses on Reddit which received at least 3 likes. Collecting all possible Reddit responses would likely have led to data quality issues and also have been too large for a model. As a result, the final dataset version includes 8M documents containing 40GB of text data in total.


Since the collected dataset is very diverse, to better account for rare words and characters, the authors incorporated a slightly modified version of Byte-Pair Encoding (BPE) for input representations.
Model
According to the paper, GPT-2 has the same architecture as GPT-1 except for several changes:
- Layer normalization was moved to the input of each Transformer block and was added to the final self-attention block.
- Weights of residual layers are divided by √N at initialization where (N is the number of residual layers).
- Context size is increased from 512 to 1024.
- Batch size is augmented from 64 to 512.
- Vocabulary size is expanded from 40,000 tokens to 50,257.
Conclusion
By turning a supervised problem into the unsupervised format, multitask learning helps GPT-2 to ace the performance on various downstream tasks (except for text summarization) without explicit fine-tuning. In fact, after several years, this learning framework is still constantly gaining popularity in machine learning.
When a training dataset is sufficiently large and diverse, it allows gigantic models to enrich linguistic knowledge by simply optimizing the log-likelihood language objective. Finally, GPT-2 has become a perfect example of such a model.
Resources
All images are by the author unless noted otherwise.
Large Language Models, GPT-2 — Language Models are Unsupervised Multitask Learners was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Large Language Models, GPT-2 — Language Models are Unsupervised Multitask Learners