

How do major LLMs stack up at detecting anomalies or movements in the data when given a large set of time series data within the context window?
While LLMs clearly excel in natural language processing tasks, their ability to analyze patterns in non-textual data, such as time series data, remains less explored. As more teams rush to deploy LLM-powered solutions without thoroughly testing their capabilities in basic pattern analysis, the task of evaluating the performance of these models in this context takes on elevated importance.
In this research, we set out to investigate the following question: given a large set of time series data within the context window, how well can LLMs detect anomalies or movements in the data? In other words, should you trust your money with a stock-picking OpenAI GPT-4 or Anthropic Claude 3 agent? To answer this question, we conducted a series of experiments comparing the performance of LLMs in detecting anomalous time series patterns.
All code needed to reproduce these results can be found in this GitHub repository.
Methodology

We tasked GPT-4 and Claude 3 with analyzing changes in data points across time. The data we used represented specific metrics for different world cities over time and was formatted in JSON before input into the models. We introduced random noise, ranging from 20–30% of the data range, to simulate real-world scenarios. The LLMs were tasked with detecting these movements above a specific percentage threshold and identifying the city and date where the anomaly was detected. The data was included in this prompt template:
basic template = ''' You are an AI assistant for a data scientist. You have been given a time series dataset to analyze.
The dataset contains a series of measurements taken at regular intervals over a period of time.
There is one timeseries for each city in the dataset. Your task is to identify anomalies in the data. The dataset is in the form of a JSON object, with the date as the key and the measurement as the value.
The dataset is as follows:
{timeseries_data}
Please use the following directions to analyze the data:
{directions}
...
Figure 2: The basic prompt template used in our tests
Analyzing patterns throughout the context window, detecting anomalies across a large set of time series simultaneously, synthesizing the results, and grouping them by date is no simple task for an LLM; we really wanted to push the limits of these models in this test. Additionally, the models were required to perform mathematical calculations on the time series, a task that language models generally struggle with.
We also evaluated the models’ performance under different conditions, such as extending the duration of the anomaly, increasing the percentage of the anomaly, and varying the number of anomaly events within the dataset. We should note that during our initial tests, we encountered an issue where synchronizing the anomalies, having them all occur on the same date, allowed the LLMs to perform better by recognizing the pattern based on the date rather than the data movement. When evaluating LLMs, careful test setup is extremely important to prevent the models from picking up on unintended patterns that could skew results.
Results
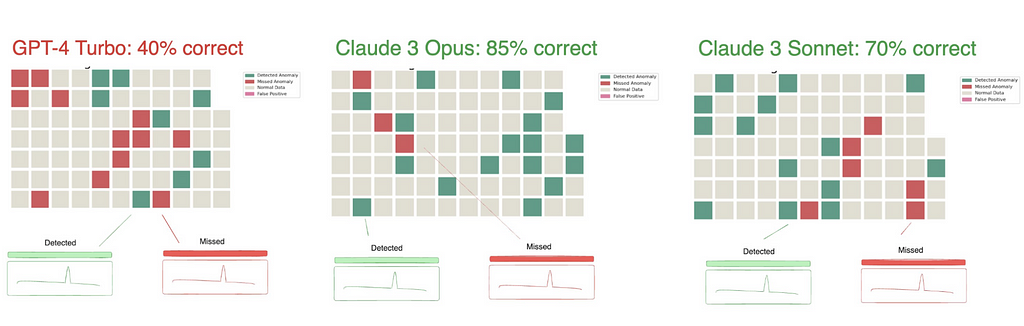
In testing, Claude 3 Opus significantly outperformed GPT-4 in detecting time series anomalies. Given the nature of the testing, it’s unlikely that this specific evaluation was included in the training set of Claude 3 — making its strong performance even more impressive.
Results with 50% Spike
Our first set of results is based on data where each anomaly was a 50% spike in the data.
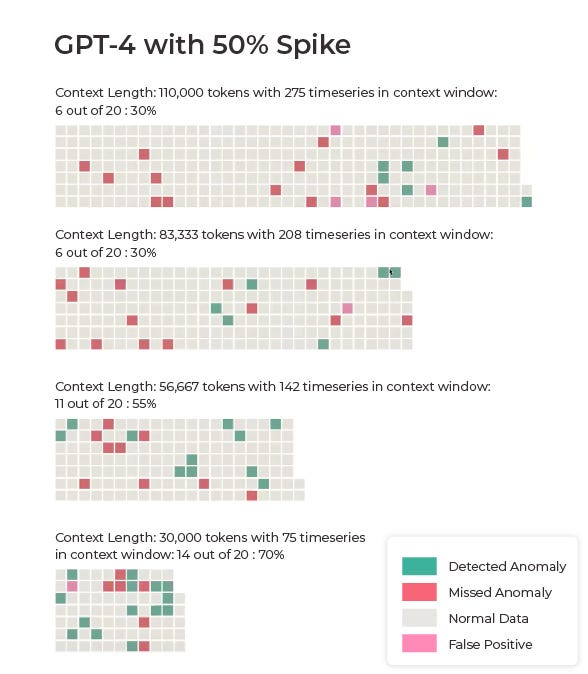
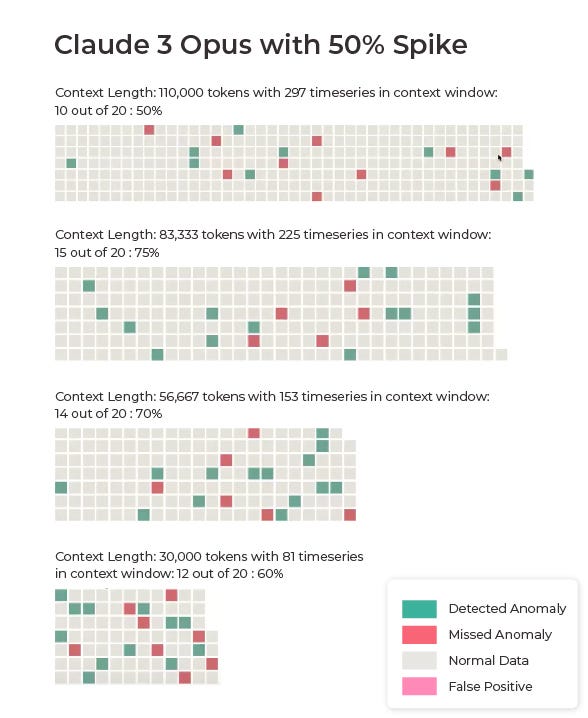
Claude 3 outperformed GPT-4 on the majority of the 50% spike tests, achieving accuracies of 50%, 75%, 70%, and 60% across different test scenarios. In contrast, GPT-4 Turbo, which we used due to the limited context window of the original GPT-4, struggled with the task, producing results of 30%, 30%, 55%, and 70% across the same tests.
Results With 90% Spike
Claude 3’s also led where each anomaly was a 90% spike in the data.

Claude 3 Opus consistently picked up the time series anomalies better than GPT-4, achieving accuracies of 85%, 70%, 90%, and 85% across different test scenarios. If we were actually trusting a language model to analyze data and pick stocks to invest in, we would of course want close to 100% accuracy. However, these results are impressive. GPT-4 Turbo’s performance ranged from 40–50% accuracy in detecting anomalies.
Results With Standard Deviation Pre-Calculated
To assess the impact of mathematical complexity on the models’ performance, we did additional tests where the standard deviation was pre-calculated and included in the data like this:
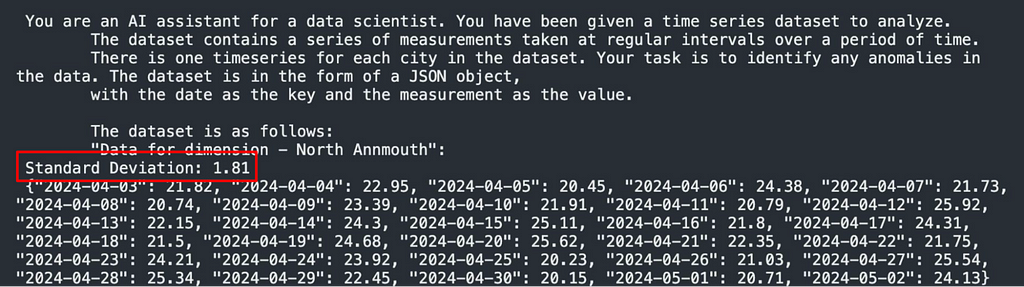
Since math isn’t a strong suit of large language models at this point, we wanted to see if helping the LLM complete a step of the process would help increase accuracy.

The change did in fact increase accuracy across three of the four Claude 3 runs. Seemingly minor changes like this can help LLMs play to their strengths and greatly improve results.
Takeaways
This evaluation provides concrete evidence of Claude’s capabilities in a domain that requires a complex combination of retrieval, analysis, and synthesis — though the delta between model performance underscores the need for comprehensive evaluations before deploying LLMs in high-stakes applications like finance.
While this research demonstrates the potential of LLMs in time series analysis and data analysis tasks, the findings also point to the importance of careful test design to ensure accurate and reliable results — particularly since data leaks can lead to misleading conclusions about an LLM’s performance.
As always, understanding the strengths and limitations of these models is pivotal for harnessing their full potential while mitigating the risks associated with their deployment.
Large Language Model Performance in Time Series Analysis was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Large Language Model Performance in Time Series Analysis
Go Here to Read this Fast! Large Language Model Performance in Time Series Analysis