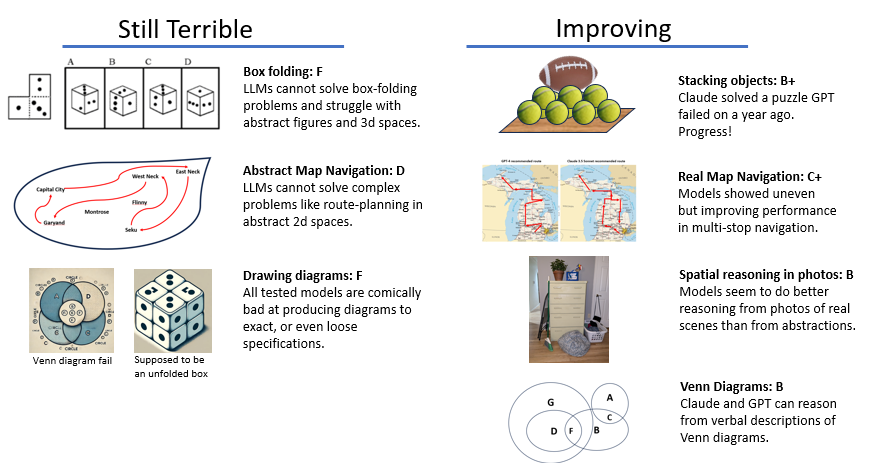
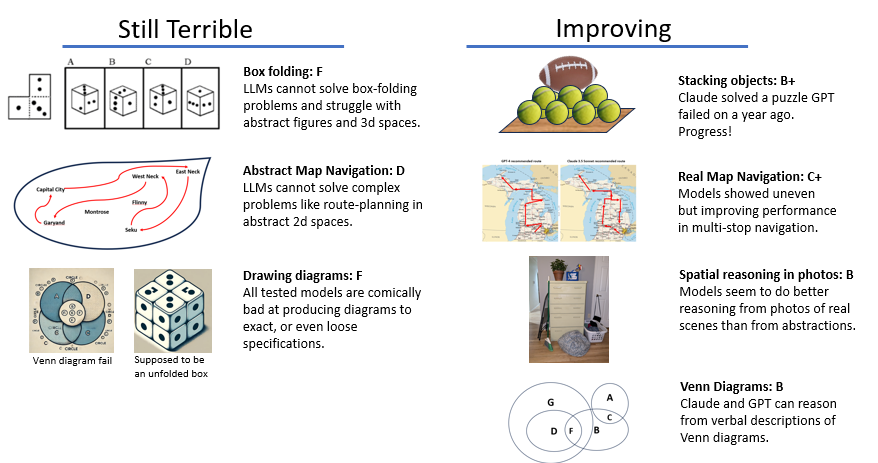
A review of capabilities as of July 2024
The Scorecard

Spatial Reasoning did not ‘emerge’ spontaneously in Large Language Models (LLMs) the way so many reasoning capabilities did. Humans have specialized, highly capable spatial reasoning capabilities that LLMs have not replicated. But every subsequent release of the major models — GPT, Claude, Gemini- promises better multimedia support, and all will accept and try to use uploaded graphics along with texts.
Spatial reasoning capabilities are being improved through specialized training on the part of the AI providers. Like a student who realizes that they just are not a ‘natural’ in some area, Language Models have had to learn to solve spatial reasoning problems the long way around, cobbling together experiences and strategies, and asking for help from other AI models. Here is my review of current capabilities. It will by turns make you proud to be a human (mental box folding champs!), inspired to try new things with your LLM (better charts and graphs!) and hopefully intrigued by this interesting problem space.
The Tests
I have been testing the large, publicly available LLM models for about a year now with a diverse collection of problems of which a few are shown here. Some problems are taken from standard spatial reasoning tests, but most other are originals to avoid the possibility of the LLMs having seen them before. The right way to do this testing would be to put together, test, and publish a large battery of questions across many iterations, perhaps ground it in recent neuroscience, and validate it with human data. For now, I will present some pilot testing — a collection of diverse problems and follow-ups with close attention to the results, especially errors, to get an understanding of the space.
The Models and the State of the Art
All of the items here were tested with Claude 3.5 Sonnet and GPT-4. Many were also tried with Gemini earlier in 2024, which performed poorly overall and results are not shown. I will show only one result for most problems, because the point is to assess the state of the art rather than compare models. Results from Terrible, Improving, and Already Pretty Good are intermixed for narrative; use the headers if you want to skip around.
Terrible: LLMs cannot mentally fold boxes
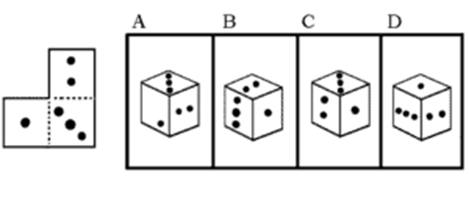
When I started testing LLM spatial reasoning I found examples of those staples of human spatial testing, mental box folding. I planned to start with some simple problems from an online spatial relations problem workbook and then move onto to harder problems as in Fibonicci’s online test.
I never got to the harder problems. All of the LLMs failed immediately on the easiest problems, and have not noticeably improved in the last year.
Below is a problem and Claude 3’s response from 7/4/2024. This response was at least as good as any I have received from GPT or Gemini, but still badly wrong. It is interesting to read the LLM response, to understand how it is trying to work through a problem that it does not have the spatial reasoning tools to understand the way a human would.
Question: When folded, what pattern is possible?
Claude Sonnet-3.5:
To solve this problem, we need to analyze how the unfolded pattern on the left could form a cube, and then compare it to the options A, B, C, and D.
Looking at the unfolded pattern:
· The top face has one dot
· The middle face has two dots
· The bottom face has three dots
Now, let’s examine each option:
A: This cube shows 3, 2, and 1 dots on visible faces. This matches our unfolded pattern.
B: This cube shows 3, 4, and 2 dots. The 4 doesn’t match our pattern.
C: This cube shows 3, 2, and 1 dots. This also matches our pattern.
D: This cube shows 4, 1, and 5 dots. This doesn’t match our pattern.
Based on this analysis, both options A and C are possible patterns when the unfolded shape is folded into a cube.
However, the question asks for a single answer. To determine which one is correct, we need to consider the exact orientation of the dots.
In the unfolded pattern:
· The single dot is in the center
· The two dots are diagonally placed
· The three dots are in an L-shape
Examining A and C more closely:
· In A, all dot placements match the unfolded pattern exactly.
· In C, the three-dot face has the dots in a straight line, which doesn’t match the L-shape in the unfolded pattern.
Therefore, the correct answer is A. When folded, the pattern in option A is possible.
Claude is trying to solve using verbal reasoning strategies, similar to what you or I might use if our visuo-spatial capabilities were somehow suppressed or disabled. Claude’s first pass is to try to eliminate possibilities based on the content of the sides, not the arrangement. Unfortunately, it gets some of the basic counting wrong on D. This may be because the dot patterns are different from a standard game dice. But this mistake is not fatal; the correct answer, C, is still in the running.
The right answer could have been determined one of two ways: simply recognizing the diagonal pattern of the three-dot side would have revealed the right answer with no mental folding needed; a better solution would recognize that the new 1 dot-/ 2-dot edge created by folding, but Claude could do neither.
GPT-4 usually tries to solve this problem by invoking some learned rules about opposite and adjacent sides. This strategy might work with a standard game dice, but this three-sided shape has no opposite sides, and GPT-4 is incapable of recognizing that.
Also Terrible: Abstract Drawings to Specifications
Throughout testing, I periodically asked GPT-4 to draw a problem or solution. The results of these were almost all terrible. This reveals the weakness of all of the art-producing AI’s that I have seen: they have no real spatial sense, and they cannot follow precise instructions.
My attempts to get GPT to create a new box-folding puzzle prompted an identity crisis between GPT-4 and its partner (presumably a version of Dall-E), which is supposed to do the actual drawing according to GPT-4’s specs. GPT-4 twice returned results and immediately acknowledged they were incorrect, although it is unclear to me how it knew. The final result, where GPT threw up its hands in resignation, is here:

This breakdown reminds me a little bit of videos of split-brain patients that many may have seen in Introduction to Psychology. This testing was done soon after GPT-4 integrated images; the rough edges have been mostly smoothed out since, making it harder to see what is happening inside GPT’s ‘Society of Mind’.
I got similarly bad results asking for navigation guides, Venn diagrams, and a number of other drawings with some abstract but precise requirements.
Improving! Claude stacks some things
There was a moment in time when it appeared that LLMs had developed something like human spatial reasoning from language-only input, which was amazing, but did not hold up. The landmark Sparks of General Intelligence paper presented some surprising successes in the spatial domain, including GPT-4 solving a problem of how to stack a set of objects that included some eggs. In an earlier blog post I explored this with some variants and the spatial abilities seemed to disappear on some slightly harder problems.
I re-administered my harder stacking problem to Claude and GPT-4 this July, and Claude 3.5 Sonnet solved the problem, although not quite as well as it might have. My intended solution was to make indentations in the piece of Styrofoam to keep the tennis balls from rolling off of the rigid stack, a solution which required some tactile sense. None of the LLMs tested have ever happened upon that, but Claude’s solution still seems viable. The shape of the egg grid it recommends (6×3) is also questionable, but I’ll give Claude the benefit of the doubt.
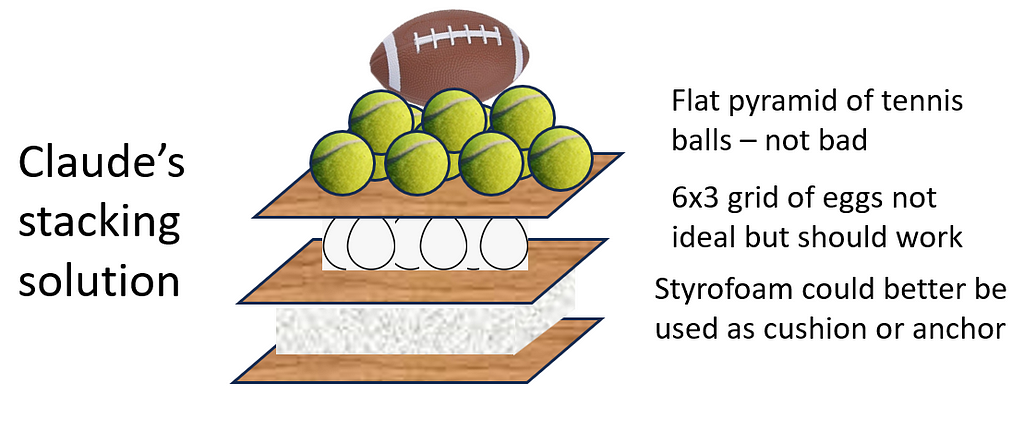
Question: The challenge is to stack some objects in a stable way, so that only the base is touching the ground. The base is a square piece of plywood, two feet long by two feet wide. There is one square piece of styrofoam, the same size and three inches thick. There are two more pieces of plywood, the same shape and size, 1/8” thick. There are eighteen chicken eggs, fifteen tennis balls, and one American football. Please tell me how to stack these objects.
Claude Sonnet-3.5:
Here’s a suggested way to stack the objects in a stable manner:
1. Place the 2ft x 2ft square piece of plywood on the ground as the base.
2. Center the 3-inch thick styrofoam square on top of the plywood base. The styrofoam will provide a cushioned, stable platform for the other objects.
3. Place one of the 1/8″ thick plywood squares on top of the styrofoam, aligning it with the edges of the styrofoam.
4. Arrange the 18 chicken eggs in a 6×3 grid pattern on the plywood square. Make sure the eggs are evenly spaced and not touching each other. The eggs should be oriented with their longer axes horizontal for better stability.
5. Carefully place the second 1/8″ plywood square on top of the eggs, aligning it with the edges of the lower plywood square. Press gently to ensure the plywood is making contact with all the eggs.
6. Arrange 10 tennis balls in a triangle pattern on top of the second plywood square. Start with a row of 4 balls, then 3 balls, 2 balls, and finally 1 ball at the top. Make sure the balls are evenly spaced and not touching each other.
7. Place the remaining 5 tennis balls on top of the triangle pattern, filling in the gaps to create a tighter, more stable arrangement.
8. Finally, balance the American football at the very top, with its long axis aligned vertically. Nestle it into the center of the tennis balls for added stability.
This stacking arrangement should create a stable structure with only the plywood base touching the ground. The styrofoam provides a cushioned platform, the eggs are evenly distributed and supported by the plywood, the tennis balls are arranged in a stable triangle pattern, and the football serves as a top ornament. However, please note that this structure may still be fragile and prone to tipping if disturbed, so it should be handled with care.
Improving! Spatial Sense in Photos
I was sure the LLMs were going to fail this next one. Claude and GPT-4 both surprised me by doing fairly well deciding what objects in the picture could fit in the dresser drawer. It appears from limited testing that the LLMs are much better at reasoning from photos than from abstract drawings. There has been an enormous amount of money and time spent getting AI to reason about objects in photos for applications like autonomous vehicles navigation and analyzing satellite imagery. I contrived a simple problem requiring some spatial sense that is different from the types I have seen in existing test datasets:
Question: Here is a photo that shows a set of dresser drawers with 1) a folding chair, 2) a broom, 3) a plant, 4) a blue basket, 5) two spray bottles, 6) a bean bag and 7) a laundry basket. Of these seven objects, which would fit in the bottom drawer, and which would not?

Claude 3.5 Sonnet:
Let’s consider each object and whether it would likely fit in the bottom drawer of the dresser:
Folding chair: Would not fit. It’s too large and rigid to fit in a drawer.
Broom: Would not fit. It’s too long to fit in a drawer.
Plant: Would not fit. The pot is too wide and the plant too delicate to be stored in a drawer.
Blue basket: Might fit, depending on its size. From the image, it looks small enough to potentially fit.
Spray bottles: Would fit. These are small enough to easily fit in the drawer.
Bean bag: Might fit, but it’s a close call. It looks large, but being soft and flexible, it could potentially be squeezed in.
Laundry basket: Would not fit. It’s too large for the drawer.
This is mostly correct. The bean bag does in fact fit. GPT-4 thought it “would not fit due to its bulky and stuffed nature.” Textures are one of the most difficult things for an LLM. Both models said the plant would not fit, which I would count as an error due to the reasoning. It would fit laying sideways, and the pot is definitely not “too wide”.
Terrible: Navigating Abstract Maps
All the LLMs tested have done badly on every form of 2d navigation I have given, be they abstracted maps like below, street maps, or complex grids. Claude had some limited success navigating a grid, where counting heuristics work, but still failed most tests. The drawing of Claude’s solution is mine based on verbal instructions given.
The test map, uploaded to GPT-4 / Claude 3.5 Sonnet:
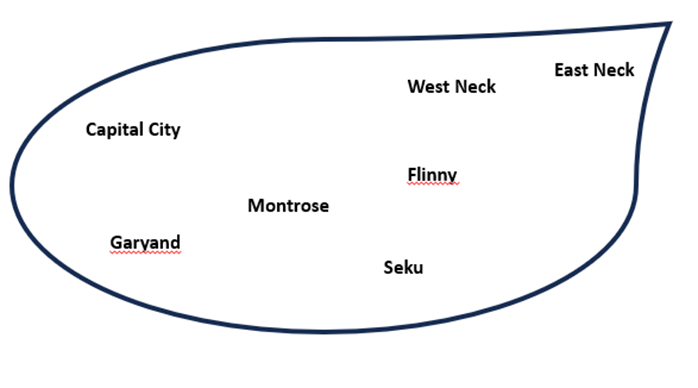
Question: This is a map of a fictional county, with some cities labeled in their relative locations. Please plan an efficient route that starts at Capital City and visits East Neck, Seku, West Neck and Garyand.
Claude’s circuitous path:
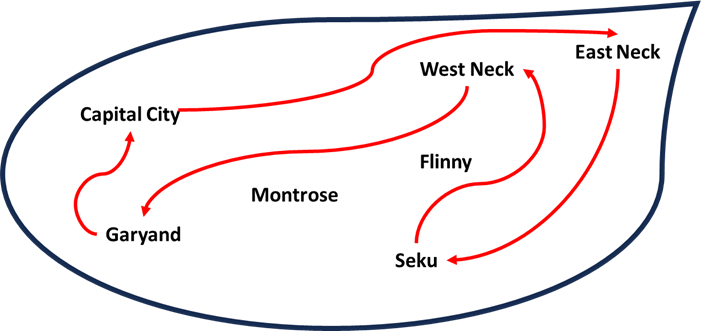
Claude Sonnet-3.5:
To plan an efficient route starting from Capital City and visiting East Neck, Seku, West Neck and Garyand:
1. Start at Capital City
2. Go east to East Neck
3. From East Neck, head south to Seku
4. From Seku, travel west to West Neck
5. From West Neck, go north to Garyand
6. Finally, from Garyand you can return east to Capital City to complete the circuit
This route allows you to visit all the specified cities while minimizing backtracking. By going in a roughly counterclockwise loop, you can cover the eastern, southern, western and northern parts of the map efficiently before returning to your starting point in Capital City.
Claude recommended a general strategy, “going in a roughly counterclockwise loop”, that is not a bad approach. It might help a human solve the problem but did not help Claude.
Improving! Navigating real maps
A year ago GPT and Gemini failed every multi-city navigation test I gave. Gemini appeared to enlist help from Google Maps and got some accurate distance and highway information, but the route was almost always wrong.
This time around GPT was considerably better, and got the example problem right, although it still makes mistakes. Claude seemed overall more error-prone. In the example below Claude’s verbal explanations were good: it knew that going from the lower to the upper peninsula would involve crossing the Mackinac bridge, and acknowledged that the recommended route involved backtracking, but the route was still quite wrong.
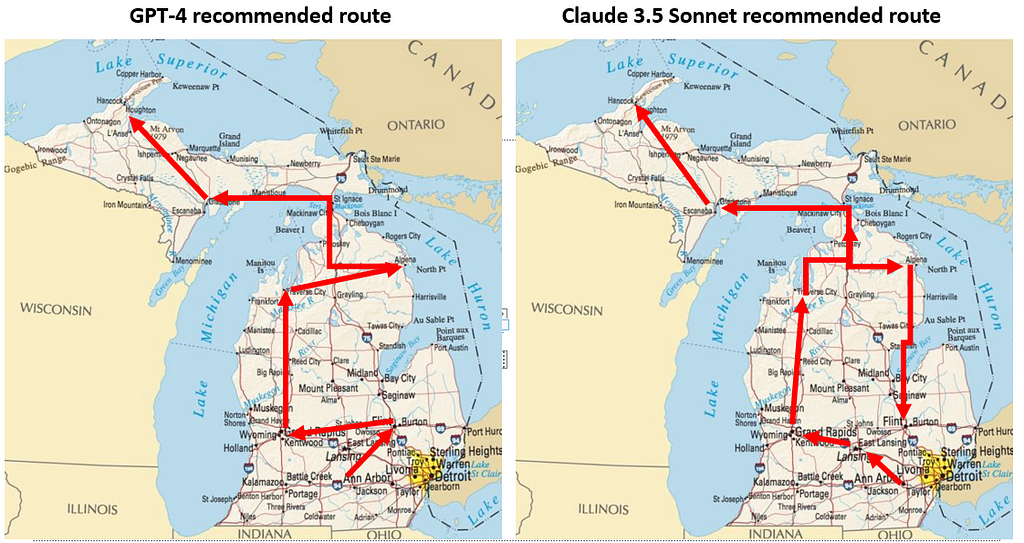
Question: Here is a map of Michigan. Please plan an efficient route that starts in Ann Arbor and visits all of these cities: Grand Rapids, Houghton, Flint, Lansing, Escanaba, Alpena, Traverse City. This route does not need to return to the starting point.
Claude 3.5 Sonnet:
To plan an efficient route visiting all the specified cities starting from Ann Arbor, I’ll organize them in a logical order based on their locations on the map. Here’s a proposed route:
Ann Arbor (starting point)
Lansing (west of Ann Arbor)
Grand Rapids (further west)
Traverse City (north)
Escanaba (in the Upper Peninsula)
Houghton (northernmost point in the UP)
Alpena (back in the Lower Peninsula, northeast)
Flint (south, ending point)
This route minimizes backtracking and covers the cities in a generally clockwise direction. It starts by heading west, then north into the Upper Peninsula, before coming back down the eastern side of the state.
The journey would involve significant driving, especially between Traverse City and Escanaba (crossing the Mackinac Bridge), and between Houghton and Alpena (requiring a return crossing of the Mackinac Bridge). However, this order seems to be the most efficient way to visit all the specified cities without returning to the starting point.
Would you like me to break down the route into more detailed segments or provide estimated distances between these cities?
Improving! Venn Diagrams
I’ve tested a variety of Venn diagram questions over the last year, both verbal and supported with drawings. Both Claude and GPT seem to be steadily improving. The example here is verbal-only, no drawing was provided. Arguably, the verbal problem could be solved without true spatial reasoning, but I’ll give the LLMs credit for progress here. Here is my drawing of the problem presented verbally:
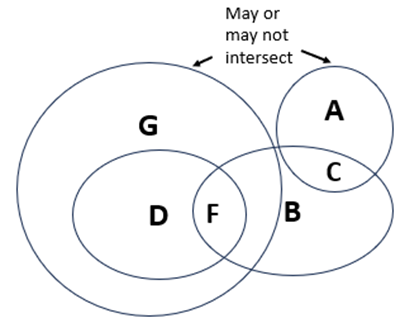
Question: In a Venn diagram, G encompasses F, A and B overlap to make area C, B and D overlap to form F. Does G intersect with A? (No visual provided)
Claude Sonnet-3.5
To answer this question, let’s break down the information given and think through it step by step:
1. G encompasses F
2. A and B overlap to make area C
3. B and D overlap to form F
4. We need to determine if G intersects with A
Let’s think about this logically:
· G encompasses F, which means F is entirely within G
· F is formed by the overlap of B and D
· A overlaps with B to form C
Since G encompasses F, and F is formed by B and D, we know that G must at least partially cover B. However, we don’t have direct information about G’s relationship with A.
The key here is that we don’t have enough information to definitively say whether G intersects with A or not. It’s possible that:
1. G could be large enough to encompass or intersect with A, or
2. G could be limited to just covering F (and possibly parts of B and D) without touching A
Without more specific information about the size and placement of G in relation to A, we cannot determine for certain whether G intersects with A.
Therefore, the answer is: We don’t have enough information to determine if G intersects with A.
Would you like me to elaborate on any part of this explanation?
Claude’s answer is correct: G and A could intersect, but do not have to given the information provided. GPT-4 also gave an answer that was not wrong, but less clearly stated.
Drawing Venn diagrams is still quite out of reach for both models, however. Below are Claude and GPT’s attempts to draw the Venn diagram described.
Already Quite Good: Data Figures
LLMs are good at writing computer code. This capability did seem to ‘emerge’, i.e. LLMs taught themselves the skill to a surprising level of initial proficiency through their base training. This valuable skill has been improved through feedback and fine-tuning since. I always use an LLM assistant now when I produce figures, charts or graphs in either Python or R. The major models, and even some of the smaller ones are great with the finicky details like axis labels, colors, etc. in packages like GGPlot, Matplotlib, Seaborn, and many others. The models can respond to requests where you know exactly what you want, e.g. “change the y-axis to a log scale”, but also do well when you just have a visual sense of what you want but not the details e.g. “Jitter the data points a little bit, but not too much, and make the whole thing more compact”.
Does the above require spatial reasoning? Arguably not. To push further I decided to test the models by giving it just a dataset and a visual message that I wanted to convey with the data, and no instructions about what type of visualization to choose or how to show it. GPT-4 and Claude 3.5 Sonnet both did pretty well. GPT-4 initially misinterpreted the data so required a couple of iterations; Claude’s solution worked right away and got better with some tweaking. Final code with a link to the data are in this Google Colab notebook on Github. The dataset, taken from Wikipedia, is also there.
Question: I am interested in the way that different visualizations from the same underlying data can be used to support different conclusions. The Michigan-Ohio State football rivalry is one of the great rivalries in sports. Each program has had success over the years and each team has gone through periods of domination. A dataset with records of all games played, ‘Michigan Ohio State games.csv’ is attached.
•What is a visualization that could be used to support the case that Michigan is the superior program? Please provide Python code.
•What is a visualization that could be used to support the case that Ohio State is the superior program? Please provide Python code.
Both models produced very similar cumulative wins graphs for Michigan. This could be based on existing graphs; as we Michigan fans like to frequently remind everyone, UM is ‘the winningest team in college football’.
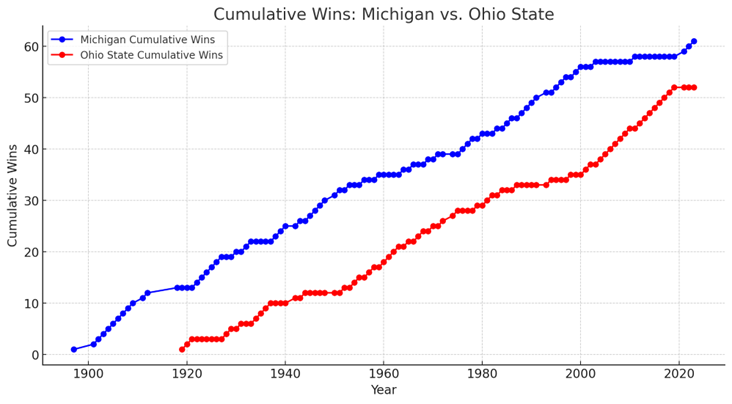
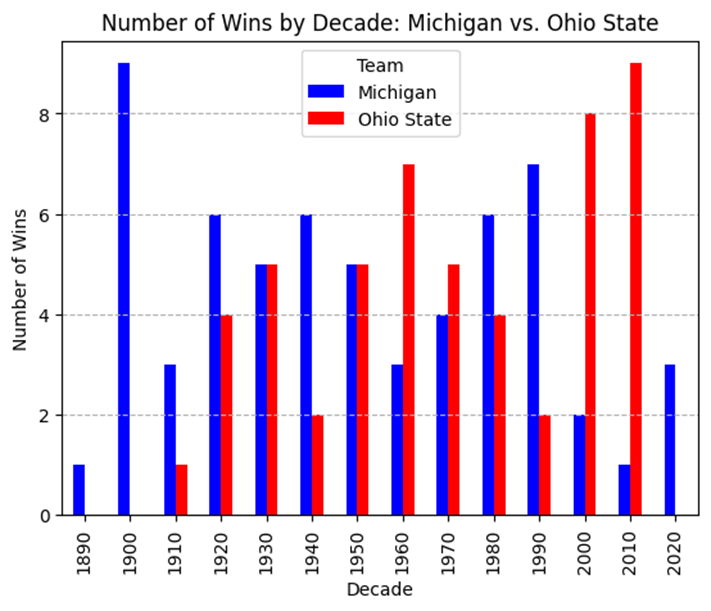
To support Ohio State’s case, GPT followed the ‘How to lie with statistics’ playbook and narrowed the y-axis to a range where OSU had a distinct win advantage, the last 30 years. (See Colab notebook.) Claude went a different route, showing a decade-by-decade plot that was also effective. Whatever.
As a follow-up I asked Claude to provide a few more Michigan-centric visualizations that highlighted the recent winning streak and 2023 national championship. The results were OK, none blew me away, and the one below shows the limits of the models’ visual reasoning:
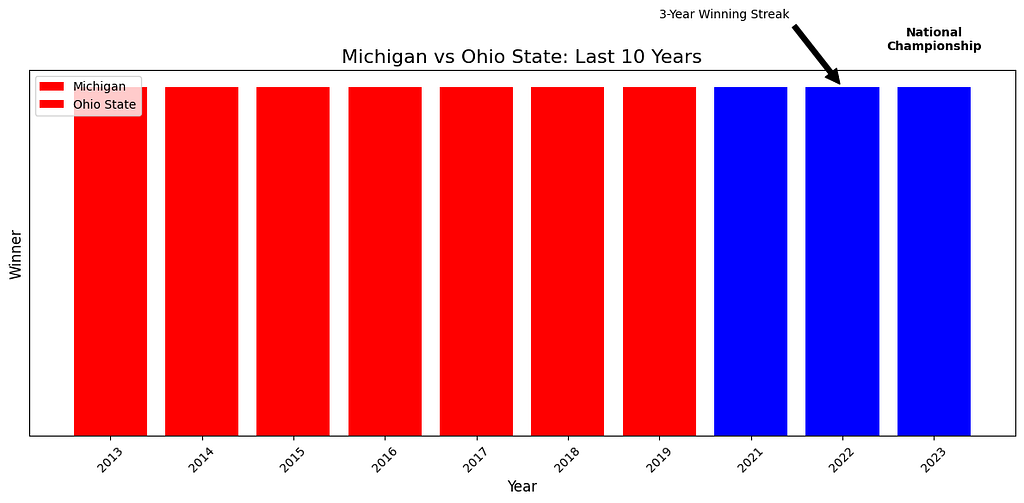
The main approach Claude took here was to highlights the things I wanted with text labels. LLMs are still very language-centric. The overall result was not effective, however. The LLM could not ‘see’ that the block of red on the left side is much more visually prominent than the small labels on the right.
Already Quite Good: Object Recognition
As noted, there has been a lot of research on AI use of photo imagery, and LLMs are being paired with models specializing in things like object recognition. There is an enormous amount of research in this area already so I did not do much exploration, but did create one sample problem to show the capability.
Question: Please name the objects in this photo and what kind of things each would be good for.

GPT-4:
The photo shows several tools. Here’s a brief description of each and their typical uses:
1. **Bolt Cutters (top left)**: These are typically used for cutting through heavy materials such as chains, padlocks, bolts, and wire mesh. They have long handles and a pair of sharp blades designed to apply significant force to cut through tough materials.
2. **Utility Knife (top right)**: This knife is versatile and can be used for cutting various materials, such as cardboard, plastic, and other light to medium-density materials. It usually has a retractable blade for safety.
3. **Locking Pliers/Vice Grips (middle)**: These pliers are used for gripping objects tightly. They can be locked into place, allowing for hands-free operation. They’re useful for holding materials securely, turning objects, or even as a makeshift clamp.
4. **Diagonal Cutters/Wire Cutters (middle left)**: These pliers are used for cutting wires and small pins in areas that are hard to reach. The cutting edges are offset by about 15 degrees, which allows for precision cuts.
5. **Tin Snips (bottom right)**: These are used for cutting sheet metal and other tough materials. The yellow handles often indicate that they are designed for straight cuts. They’re ideal for cutting through aluminum, steel, and other metal sheets.
These tools are essential in various trades and DIY projects, providing functionality from cutting and gripping to clamping and precise material manipulation.
These are all correct and this level of information would be helpful to a non-expert DIY practitioner like myself.
Conclusions
Major LLM models are improving on a range of spatial problems, but even with help are a long ways from human-level spatial reasoning capabilities. I would expect most further progress to involve integration of more specialized models as partners, with the attendant challenge of integrating these with language/reasoning specialists like LLMs.
Understanding current capabilities should help expert users know what to delegate and what to closely supervise for effective Human-Machine teaming.
References:
Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y. T., Li, Y., Lundberg, S., Nori, H., Palangi, H., Ribeiro, M. T., & Zhang, Y. (2023). Sparks of Artificial General Intelligence: Early experiments with GPT-4 (arXiv:2303.12712). arXiv. http://arxiv.org/abs/2303.12712
Language Models and Spatial Reasoning: What’s Good, What Is Still Terrible, and What Is Improving was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Language Models and Spatial Reasoning: What’s Good, What Is Still Terrible, and What Is Improving