
LangChain’s Parent Document Retriever — Revisited
Enhance retrieval with context using your vector database only
TL;DR — We achieve the same functionality as LangChains’ Parent Document Retriever (link) by utilizing metadata queries. You can explore the code here.
Introduction to RAG
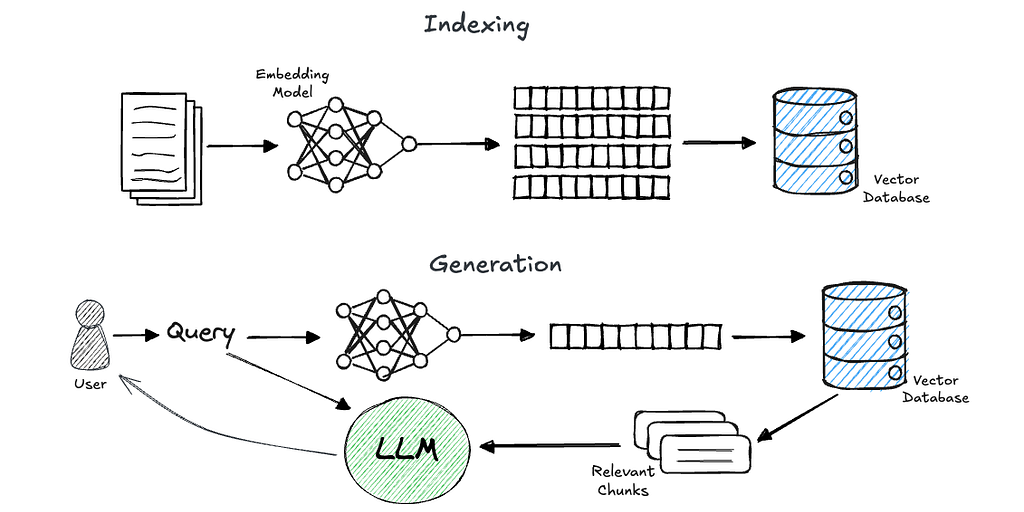
Retrieval-augmented generation (RAG) is currently one of the hottest topics in the world of LLM and AI applications.
In short, RAG is a technique for grounding a generative models’ response on chosen knowledge sources. It comprises two phases: retrieval and generation.
- In the retrieval phase, given a user’s query, we retrieve pieces of relevant information from a predefined knowledge source.
- Then, we insert the retrieved information into the prompt that is sent to an LLM, which (ideally) generates an answer to the user’s question based on the provided context.
A commonly used approach to achieve efficient and accurate retrieval is through the usage of embeddings. In this approach, we preprocess users’ data (let’s assume plain text for simplicity) by splitting the documents into chunks (such as pages, paragraphs, or sentences). We then use an embedding model to create a meaningful, numerical representation of these chunks, and store them in a vector database. Now, when a query comes in, we embed it as well and perform a similarity search using the vector database to retrieve the relevant information
If you are completely new to this concept, I’d recommend deeplearning.ai great course, LangChain: Chat with Your Data.
What is “Parent Document Retrieval”?
“Parent Document Retrieval” or “Sentence Window Retrieval” as referred by others, is a common approach to enhance the performance of retrieval methods in RAG by providing the LLM with a broader context to consider.
In essence, we divide the original documents into relatively small chunks, embed each one, and store them in a vector database. Using such small chunks (a sentence or a couple of sentences) helps the embedding models to better reflect their meaning [1].
Then, at retrieval time, we do not return the most similar chunk as found by the vector database only, but also its surrounding context (chunks) in the original document. That way, the LLM will have a broader context, which, in many cases, helps generate better answers.
LangChain supports this concept via Parent Document Retriever [2]. The Parent Document Retriever allows you to: (1) retrieve the full document a specific chunk originated from, or (2) pre-define a larger “parent” chunk, for each smaller chunk associated with that parent.
Let’s explore the example from LangChains’ docs:
# This text splitter is used to create the parent documents
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
# This text splitter is used to create the child documents
# It should create documents smaller than the parent
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(
collection_name="split_parents", embedding_function=OpenAIEmbeddings()
)
# The storage layer for the parent documents
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
retrieved_docs = retriever.invoke("justice breyer")
In my opinion, there are two disadvantages of the LangChains’ approach:
- The need to manage external storage to benefit from this useful approach, either in memory or another persistent store. Of course, for real use cases, the InMemoryStore used in the various examples will not suffice.
- The “parent” retrieval isn’t dynamic, meaning we cannot change the size of the surrounding window on the fly.
Indeed, a few questions have been raised regarding this issue [3].
Here I’ll also mention that Llama-index has its own SentenceWindowNodeParser [4], which generally has the same disadvantages.
In what follows, I’ll present another approach to achieve this useful feature that addresses the two disadvantages mentioned above. In this approach, we’ll be only using the vector store that is already in use.
Alternative Implementation
To be precise, we’ll be using a vector store that supports the option to perform metadata queries only, without any similarity search involved. Here, I’ll present an implementation for ChromaDB and Milvus. This concept can be easily adapted to any vector database with such capabilities. I’ll refer to Pinecone for example in the end of this tutorial.
The general concept
The concept is straightforward:
- Construction: Alongside each chunk, save in its metadata the document_id it was generated from and also the sequence_number of the chunk.
- Retrieval: After performing the usual similarity search (assuming for simplicity only the top 1 result), we obtain the document_id and the sequence_number of the chunk from the metadata of the retrieved chunk. Retrieve all chunks with surrounding sequence numbers that have the same document_id.
For example, assuming you’ve indexed a document named example.pdf in 80 chunks. Then, for some query, you find that the closest vector is the one with the following metadata:
{document_id: "example.pdf", sequence_number: 20}
You can easily get all vectors from the same document with sequence numbers from 15 to 25.
Let’s see the code.
Here, I’m using:
chromadb==0.4.24
langchain==0.2.8
pymilvus==2.4.4
langchain-community==0.2.7
langchain-milvus==0.1.2
The only interesting thing to notice below is the metadata associated with each chunk, which will allow us to perform the search.
from langchain_community.document_loaders import PyPDFLoader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
document_id = "example.pdf"
def preprocess_file(file_path: str) -> list[Document]:
"""Load pdf file, chunk and build appropriate metadata"""
loader = PyPDFLoader(file_path=file_path)
pdf_docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=0,
)
docs = text_splitter.split_documents(documents=pdf_docs)
chunks_metadata = [
{"document_id": file_path, "sequence_number": i} for i, _ in enumerate(docs)
]
for chunk, metadata in zip(docs, chunks_metadata):
chunk.metadata = metadata
return docs
Now, lets implement the actual retrieval in Milvus and Chroma. Note that I’ll use the LangChains’ objects and not the native clients. I do this because I assume developers might want to keep LangChains’ useful abstraction. On the other hand, it will require us to perform some minor hacks to bypass these abstractions in a database-specific way, so you should take that into consideration. Anyway, the concept remains the same.
Again, let’s assume for simplicity we want only the most similar vector (“top 1”). Next, we’ll extract the associated document_id and its sequence number. This will allow us to retrieve the surrounding window.
from langchain_community.vectorstores import Milvus, Chroma
from langchain_community.embeddings import DeterministicFakeEmbedding
embedding = DeterministicFakeEmbedding(size=384) # Just for the demo :)
def parent_document_retrieval(
query: str, client: Milvus | Chroma, window_size: int = 4
):
top_1 = client.similarity_search(query=query, k=1)[0]
doc_id = top_1.metadata["document_id"]
seq_num = top_1.metadata["sequence_number"]
ids_window = [seq_num + i for i in range(-window_size, window_size, 1)]
# ...
Now, for the window/parent retrieval, we’ll dig under the Langchain abstraction, in a database-specific way.
For Milvus:
if isinstance(client, Milvus):
expr = f"document_id LIKE '{doc_id}' && sequence_number in {ids_window}"
res = client.col.query(
expr=expr, output_fields=["sequence_number", "text"], limit=len(ids_window)
) # This is Milvus specific
docs_to_return = [
Document(
page_content=d["text"],
metadata={
"sequence_number": d["sequence_number"],
"document_id": doc_id,
},
)
for d in res
]
# ...
For Chroma:
elif isinstance(client, Chroma):
expr = {
"$and": [
{"document_id": {"$eq": doc_id}},
{"sequence_number": {"$gte": ids_window[0]}},
{"sequence_number": {"$lte": ids_window[-1]}},
]
}
res = client.get(where=expr) # This is Chroma specific
texts, metadatas = res["documents"], res["metadatas"]
docs_to_return = [
Document(
page_content=t,
metadata={
"sequence_number": m["sequence_number"],
"document_id": doc_id,
},
)
for t, m in zip(texts, metadatas)
]
and don’t forget to sort it by the sequence number:
docs_to_return.sort(key=lambda x: x.metadata["sequence_number"])
return docs_to_return
For your convenience, you can explore the full code here.
Pinecone (and others)
As far as I know, there’s no native way to perform such a metadata query in Pinecone, but you can natively fetch vectors by their ID (https://docs.pinecone.io/guides/data/fetch-data).
Hence, we can do the following: each chunk will get a unique ID, which is essentially a concatenation of the document_id and the sequence number. Then, given a vector retrieved in the similarity search, you can dynamically create a list of the IDs of the surrounding chunks and achieve the same result.
Limitations
It’s worth mentioning that vector databases were not designed to perform “regular” database operations and usually not optimized for that, and each database will perform differently. Milvus, for example, will support building indices over scalar fields (“metadata”) which can optimize these kinds of queries.
Also, note that it requires additional query to the vector database. First we retrieved the most similar vector, and then we performed additional query to get the surrounding chunks in the original document.
And of course, as seen from the code examples above, the implementation is vector database-specific and is not supported natively by the LangChains’ abstraction.
Conclusion
In this blog we introduced an implementation to achieve sentence-window retrieval, which is a useful retrieval technique used in many RAG applications. In this implementation we’ve used only the vector database which is already in use anyway, and also support the option to modify dynamically the the size of the surrounding window retrieved.
References
[1] ARAGOG: Advanced RAG Output Grading, https://arxiv.org/pdf/2404.01037, section 4.2.2
[2] https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/parent_document_retriever/
[3] Some related issues:
– https://github.com/langchain-ai/langchain/issues/14267
– https://github.com/langchain-ai/langchain/issues/20315
– https://stackoverflow.com/questions/77385587/persist-parentdocumentretriever-of-langchain
[4] https://docs.llamaindex.ai/en/stable/api_reference/node_parsers/sentence_window/
LangChain’s Parent Document Retriever — Revisited was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
LangChain’s Parent Document Retriever — Revisited
Go Here to Read this Fast! LangChain’s Parent Document Retriever — Revisited